Ökonomeetria kordamisküsimused (4)
Varia - Need luuletused on nii erilised, et neid ei saa kuidagi kategoriseerida
Esitatud küsimused
- Mis juhtub heteroskedastiivsuse korral?
- Mis juhtub funktsiooniga kui argument suureneb 500 kg võrra lehma kohta?
Ökonomeetria mõiste ja ülesanded. Ökonomeetria komponendid.
MÕISTE:
Ökonomeetria on teadus ja kunst kasutada statistilisi tehnikaid ja
majandusteooriaid majanduslike andmete analüüsimisel.
ÜLESANDED:
Majanduslike nähtuste vaheliste seoste kvantitatiivne kirjeldamine
Majandusteoreetiliste hüpoteeside kontrollimine
Majandusnäitajate ja majandusarengu prognoosimine
KOMPONENDID:
Ökonomeetrilise mudeli olemus, mudeli komponendid. Ökonomeetrilise modelleerimise etapid.
MUDELI
OLEMUS:
- Mudel on lihtsustatud ettekujutus reaalsest objektist, protsessist või nähtusest
- Mudel on tegelikkuse abstraktsioon, üldistus
- Mudel peab peegeldama ainult olulist, jätma teatud probleemi käsitlemisel kõrvale mitteolulise
ÖKONOMEETRILISE
MUDELI OLEMUS:
Ökonomeetriline
mudel on matemaatilise mudeli eriliik, mis koosneb üldjuhul
algebralistest võrranditest või võrrandisüsteemidest ning
sisaldab juhuslikku komponenti.
ÖKONOMEETRILISE
MUDELI KOMPONENDID:
- modelleeritavad näitajad: endogeensed ehk sõltuvad muutujad (Y)
- modelleeritavat nähtust mõjutavad näitajad: eksogeensed ehk sõltumatud muutujad (X)
- matemaatiliste ja statistiliste meetoditega hinnatavad mudeli parameetrid
- juhuslik komponent (ɛ)
ÖKONOMEETRILISE
MODELLEERIMISE ETAPID:
teooria ja sellel baseeruva verbaalse mudeli formuleerimine
2.
andmebaasi korraldamine
3.
ökonomeetrilise (matemaatilise) mudeli valik
4.
ökonomeetrilise mudeli parameetrite hindamine
5.
parameetrite usaldatavuse kontrollimine
6.
mudeli omaduste parandamine
7.
järelduste tegemine
8.
prognooside koostamine
Lihtne regressioon , regressioonivõrrandi põhikuju. Determineeritud regressioonivõrrand.
Lineaarse
regressiooni korral kirjeldatakse seost uuritavate muutujate
väärtuste vahel sirge abil võrrandiga
Y
= a0+a1X
Eesmärgiks
on leida punktiparvega antud X ja Y vahelist seost iseloomustava parima
sirge
võrrand
Lineaarse
kahe muutujaga determineeritud regressioonimudeli korral eeldatakse,
et juhusliku suuruse Y tingliku keskväärtuse ja sõltumatu muutuja X vahel on seos
E(YX
) = α0+ α1X
Determineeritud
regressioonivõrrand kirjeldab seost endogeense ehk sõltuva muutuja
Y keskväärtuse ja eksogeensete ehk sõltumatute muutujate Xi vahel.
Võrrandi vasakul pool on tinglikud keskväärtused, mis ei sõltu
juhusest
Stohhastiline regressioonivõrrand. Juhuslik komponent (regressioonijääk). Visualiseerimine (joonis).
Stohhastiline
regressioonivõrrand sisaldab juhuslikku liiget εi
Juhuslik
liige εi kirjeldab juhuslikke hälbeid endogeense (sõltuva)
muutuja keskväärtusest
Yi=
E(YXi) + εi ehk Yi= α0+ α1Xi+ εi
Vähimruutude meetod, olemus, visualiseerimine.
Vähimruutude
meetod on regressioonimudeli parameetrite hindamise enamkasutatav
meetod.
Eesmärgiks
on leida regressioonimudeli parameetrid (a0ja a1) selliselt , et
juhusliku suuruse Y mõõdetud väärtuste Yi ja regressioonimudeli
abil määratud hinnangute Ŷi hälvete (jääkliikmete) ruutude summa oleks minimaalne
OLEMUS:
- Et funktsioon S saavutaks miinimumi, peavad tema osatuletised parameetrite a0 ja a1 suhtes võrduma nulliga
- Leida kahe muutuja funktsiooni miinimum
- Osatuletised a0 ja a1järgi peavad võrduma nulliga
Vähimruutude meetodil leitud parameetrite hinnangute omadused.
Vähimruutude
meetodil leitud hinnangute algebralised omadused on järgmised:
1. Regressioonisirge läbib alati punkti, mille koordinaatideks on
sõltuva muutuja ja
sõltumatu
muutuja aritmeetilised keskmised X ja Y.
Regressioonijääkide ei aritmeetiline keskmine (e katusega ) on võrdne nulliga, st
3.
Sõltuva muutuja arvutuslike väärtuste Ŷi
aritmeetiline keskmine võrdub sõltuva muutuja aritmeetilise
keskmisega Y katusega , st
4.
Regressioonijäägid ei
ei ole korreleeritud sõltuva muutuja arvutuslike väärtustega Ŷ , st
5.
Regressioonijäägid ei
ei ole korreleeritud sõltumatu muutuja väärtustega Xi, st
Statistilise seose tugevus: determinatsioonikordaja ( hajuvuse (RSS, TSS, ESS) mõõtmine (joonised)), korrelatsioonikordaja , jääkstandardhälve, kovariatsioon, ( eespool toodud näitajate olemus, selgitus joonise abil). Kordajate omavahelised seosed.
JÄÄKHAJUVUS
Vahet
Yi – Ŷi nimetatakse jäägiks. Jääkide ruutude summa on
jääkhajuvus.
RSS
= ∑ei2=∑(Yi-
Ŷi)2
Lineaarse
regressioonisirge puhul on jääkhajuvus vähim. Mistahes teise sirge
puhul on jääkhajuvus suurem kui jääkhajuvus regressioonisirge
puhul.
REGRESSIOONHAJUVUS
Regressioonimudeli
poolt kirjeldatud hajuvus ( selgitatud varieeruvus)
ESS
= ∑(Ŷi- Y)2
on lineaarse
regressioonimudeli
järgi arvutatud väärtus
KOGUHAJUVUS
Regressioonimudeli
sõltuva muutuja Y koguhajuvus TSS = ∑(Yi-Y)2
TSS
(SST) mõõdab Yi koguhajuvust (varieeruvust) sõltuva muutuja Y
keskväärtuse (aritmeetilise keskmise) ümber ehk hälvete ruutude summat
Regressioonimudeli
sõltuva muutuja Y koguhajuvus TSS koosneb regressioonimudeliga
kirjeldatud hajuvusest ESS ja jääkhajuvusest (selgitamata
varieeruvus) RSS
TSS
= ∑(Yi-Y)2 koguvarieeruvus
ESS
= ∑(Ŷi- Y)2
selgitatud varieeruvus
RSS
= ∑ei2=∑(Yi-
Ŷi)2
jääkhajuvus (selgitamata varieeruvus)
Determinatsioonikordaja
alusel saab hinnata, kui palju sõltuva muutuja hajuvusest on
kirjeldatud regressioonimudeli poolt. Determinatsioonikordaja mõõdab,
kui hästi regressioonisirge lähendab vaatlusandmeid .
Determinatsioonikordaja
väljendab regressioonimudeli poolt kirjeldatud hajuvuse (ESS) suhet
modelleeritava näitaja (endogeense - sõltuva muutuja) koguhajuvusse
(TSS).
KOVARIATSIOONIKORDAJA
Kahe
muutuja vahelise seose tugevuse ja suuna kirjeldamiseks võib
kasutada
kovariatsioonikordajat:
- muutujate X ja Y hälvete korrutiste keskväärtus
- andmepaaride hälvete keskmine (murrujoone pealne osa on jagatud n-ga) iseloomustab tunnuse ühismuutuvuse (kovariatsiooni) astet
Kovariatsiooni
väljendav juhuslik suurus cov(X,Y) võib olla vahemikus (-∞, ∞)
Kovariatsioon
on :
- positiivne, kui muutujate X ja Y keskmine hajumine ümber nende keskväärtuste toimub samas suunas;
- negatiivne kui vastassuunas ;
- cov (X, Y)= 0, kui juhuslikud suurused on sõltumatud.
Kui
cov(X, Y) ≠ 0, siis nimetatakse muutujaid X ja Y korreleeruvateks,
vastupidisel juhul aga mittekorreleeruvateks.
KOVARIATSIOONI
SUURUS
- Hälvete korrutis on positiivne, kui koos esinevad X ja Y suured väärtused ning X ja Y väikesed väärtused. Summas esinevad siis positiivsed liikmed ja saadakse kovariatsioonikordaja suur positiivne väärtus.
- Hälvete korrutis on negatiivne, kui hälbed on erineva märgiga, s.t. koos esinevad ühe muutuja suured ja teise muutuja väikesed väärtused. Sel juhul on summa liikmed valdavalt negatiivsed ja kovariatsioonikordajal on suur negatiivne väärtus.
- Kui summas esinevad vaheldumisi negatiivsed ja positiivsed väärtused (X ja Y suurte ja väikeste väärtuste vastavus on juhuslikku laadi ), siis summeerimisel nad kompenseeruvad ja saadakse nullilähedanekovariatsioonikordaja väärtus.
Kovariatsioonikordajat
võib kasutada seose tihedust iseloomustava näitajana, kuid selle
näitaja puuduseks on asjaolu, et see sõltub sõltuva muutuja Y ja
sõltumatu muutuja X mõõtühikutest.
Jagades kovariatsioonikordaja avaldise sõltuva muutuja Y ja sõltumatu
muutuja X
standardhälvetega saame uue seose tihedust iseloomustava näitaja
korrelatsioonikordaja rx
KORRELATSIOONIKORDAJA
- Üks sagedamini kasutatav lineaarse seose rangust (tihedust, tugevust) kirjeldav suurus on korrelatsioonikoefitsient ehk korrelatsioonikordaja
- Võimalik leida ruutjuurena determinatsioonikordajast
Omadused:
- Korrelatsioonikordaja väärtused asuvad –1 ja 1 vahel, -1≤ r ≤
- Kui muutujate vahel on funktsionaalne seos Y = a0+a1X, siis korrelatsioonikordaja absoluutväärtus on võrdne ühega, |r|=1
- Kui muutujad on sõltumatud, siis korrelatsioonikordaja väärtus null, r=0
JÄÄKSTANDARDHÄLVE
Ruutjuurt
jääkdispersioonist nimetatakse regressioonimudeli
jääkstandardhälbeks
ehk
prognoosivekas ehk regressioonimudeli standardveaks
FUNKTSIONAALNE
SEOS
- Tunnuste väärtuste vaheline sõltuvus võib olla kas funktsionaalne või korrelatiivne.
- Kahe nähtuse vahel on funktsionaalne seos ehk täielik seos siis, kui ühe nähtuse mingile arvväärtusele vastab ainult üks arvväärtus teise nähtuse väärtuste hulgast.
- Selliste seoste korral eeldatakse tavaliselt põhjuslikkust, st eeldatakse, et ühe nähtuse muutumine toob kaasa teise nähtuse kindla muutumise kindlas ja muutumatus koguses ja suunas.
KORRELATIIVNE
SEOS
- Statistilist tõenäosuslikku seost, mis ei ole rangelt funktsionaalne, nimetatakse korrelatiivseks seoseks.
- Korrelatiivne ehk mittetäielik seos valitseb nähtuste vahel siis, kui ühe suuruse igale arvväärtusele vastab teise suuruse hulk arvväärtusi, mis jaotuvad selliselt, et igaüks neist võib esineda teatud tõenäosusega
- Korrelatiivset seost iseloomustavat joont, mille geomeetriline koht korrelatsiooniväljal leitakse vähimruutude meetodil, nimetatakse regressioonijooneks
Lihtsa regressioonimudeli
headuse hindamine;
Determinatsioonikordaja
D = R2 võimaldab hinnata, kui palju sõltuva muutuja (Y) hajuvusest
on regressioonimudeliga kirjeldatud (valitud x korral).
usaldatavuse kontrollimine;
Regressioonimudeli
olulisuse hindamine eksimise tõenäosuse p abil (significance F).
Kui
p F-kriteeriumi
abil kontrollitakse regressioonimudeli kui terviku statistilist
olulisust. Fkriitilise leidmiseks kasutada funktsiooni FINV. Kui F
emp > F krit, siis on regressioonimudle kui tervik stat
usaldusväärne
mudeli parameetrite statistilise olulisuse kontrollimine; usalduspiiride leidmine;
t-statistiku
abil hinnatakse parameetri ( regressioonikordaja usaldusväärsust).
t- kriitilise leidmiseks kasutada funktsiooni TINV.
Usaldusvahemiku
alumine ja ülemine piir (Lower 95% ja Upper 95%) määravad
vahemiku, millesse jääb 95% tõenäosusega regressioonikordaja.
eespool toodud näitajate leidmine ja seoste analüüs Exceli regressioonanalüüsi tabeli põhjal.
Vaata
moodles regressiooni selgitused.
Mitmene regressioon. Klassikalise regressioonanalüüsi põhieeldused. Gauss- Markovi teoreemi olemus. Parim hinnang. Nihutamata hinnang. Efektiivne hinnang.
MITMENE
REGRESSIOON
Mitmese
regressioonimudeli korral uuritakse seost endogeense (sõltuva )
muutuja Y ning eksogeensete (sõltumatute) muutujate vahel
- Eeldatakse, et sõltuvat muutujat Y mõjutavad mitu sõltumatut muutujat X1, X2,…, Xn ning nende mõju sõltuvale muutujale on lineaarne.
- Selline olukord on majanduslikke protsesside analüüsimisel tüüpiline, sest tegelikus elus mistahes majanduslik nähtus või protsess sõltub alati suurest hulgast teguritest i (sõltumatutest muutujatest).
KLASSIKALISE
REGRESSIOONIANALÜÜSI PÕHIEELDUSED
1. Regressioonimudel on korrektne , lineaarne parameetrite suhtes.
2.
Regressioonijääkide (jääkliikmete) tinglikud keskväärtused on
võrdsed nulliga.
3.
Regressioonijäägid ei korreleeru sõltumatute muutujatega.
4.
Jääkliikmete dispersioonid on konstantsed (ei esine
heteroskedastiivsust).
5.
Regressioonijäägid ei korreleeru omavahel (ei esine
autokorrelatsiooni).
6.
Sõltumatud muutujad ei tohi olla täpses lineaarses sõltuvuses
( multikollineaarsus ).
7.
Sõltumatud muutujad omavad küllaldast varieeruvust
8.
Regressioonijäägid on normaaljaotusega.
GAUSS
MARKOVI TEOREEMI OLEMUS
GAUSS
MARKOVI TEOREEM: kui on täidetud
klassikalise regressioonmudeli eeldused, siis vähimruutude meetodil
leitud parameetrite hinnangud on parimad, lineaarsed , nihutamata .
Lineaarne – lineaarsed funktsioonid sõltumatust muutujast Y; parameeter peab olema esimeses astmes , et saaks kasutada vähimruutude
meetodit. Hinnang on nihutamata kui hinnangu kui juhusliku suuruse
keskväärtus E(a) on võrdne hinnatava parameetri ɑ tegeliku
väärtusega. Parimaks lineaarseks nihutamata hinnangus nim nihketa hinnangut mis on andmete lineaarne funktsioon ning on vähima
dispersiooniga kõigi nihketa lineaarsete hinnangute seas.
PARIM
HINNANG: et hinnang leitakse
valimi alusel, mis on juhuslik, siis on ka hinnang juhuslik suurus. Samast üldkogumist komplekteeritud sama suurusega valimite põhjal
saadud hinnangud on tavaliselt erinevad, mis kinnitab valimi alusel
leitavate hinnangute juhuslikku iseloomu. Eesmärgiks on valimi
andmeid kasutades leida võimalikult täpselt parameetri Xhinnang a.
Parameetrihinnanguks nim statistikut mis leitakse valimi põhjal ning
mis annab ühese väärtuse x-le. Hinnangut, mis on nihketa ja millel
on antud valimi korral väiksem võimalik dispersioon, nimetatakse
parimaks hinnanguks .
NIHUTAMATA
HNNANG: hinnangu erinevust
tegelikust väärtusest iseloomustatakse nihke abil. Parameetri
hinnangu keskväärtuse E(a) ja parameetri tegeliku ɑ vahel
käsitletaksegi nihkena. Kui tegemist on nihutamata hinnanguga, siis
see vahe võrdub nulliga, mis tähendab et hinnangu keskväärtus
võrdub parameetri tegeliku väärtusega. E(a) = ɑ.
EFEKTIIVNE
HINNANG: hinnangute hajuvust
isel efektiivsuse mõistega. Parameetri ɑ1 nihketa hinnang a1 on
efektiivsem kui parameetri ɑ1 nihketa hinnang a2, kui hinnangu a1
dispersioon on väiksem kui hinnangu a2 dispersioon. Efektiivne
hinnang on selline hinnang, ille dispersioon on minimaalne, st
hinnangu kui juhusliku suuruse varieeruvus on minimaalne.
Multikollineaarsuse olemus. Multikollineaarsuse avastamine. Tolerants (TOL), varieeruvusindeks (VIF). Multikollineaarsuse tagajärjed.
Terminiga
multikollineaarsus iseloomustatakse olukorda või seisundit , kui
regressioonivõrrandi sõltumatute muutujate arvväärtused on
omavahelises sõltuvuses.
Kaks
erinevat multikollineaarsuse taset:
- y täielik multikollineaarsus
- y mittetäielik multikollineaarsus
AVASTAMINE
- Korrelatsioonikordaja kahe sõltumatu muutuja korral on suurem kui > 0,8
- Suurema arvu sõltumatute muutujate korral ei pea mittetäieliku multikollineaarsusele vastava olukorra tekkeks üksikute sõltumatute muutujate vahelise sõltuvuse korrelatsioonikordaja olema väga suur (võib olla
- Täiendavad regressioonid - regressioonid sõltumatute muutujate vahel, milles iga sõltumatu muutuja on üks kord sõltuvaks muutujaks
Tolerants
(TOL) – kui suur osa sõltumatu
muutuja varieeruvusest jääb ülejäänud
sõltumatute
muutujate poolt kirjeldamata
Varieeruvusindeks
(VIF) ehk dispersiooni mõju
faktor näitab sõltumatu muutuja mõju regressiooniparameetri
hajuvusele ja on tolerantsi pöördväärtus
Multikollineaarsuse mõju regressioonanalüüsi tulemustele (labortöö).
Multikollineaarsuse
tagajärjed: kui reg kordajate
varieeruvus on väga suur, siis regressioonikordaja parameetri
standardvea (Sa1)
arvutusvalemist järeldub, et juhul kui sõltumatute muutujate X1i
ja X2i
vahelise sõltuvuse korrelatsioonikordaja r1,2
läheneb 1-le siis murru nimetaja väheneb ning Sa1
suureneb.
Varieeruvuse suurenemisel t- statistik muutub mitteusaldusväärseks/t-statistiku
avaldises parameetri hinnang jagatakse standardevaga t=a/Sai. Multikollineaarsus suurendab regressioonikordajate varieeruvust..
Mittetäieliku multikollineaarsuse korral kui muutujad on
omavahelises tugevas korrelatsioonis(mitte täielikus), parameetrite
hinnangud omavad suurt varieeruvust (standardhälve suur) ja
kovariatsiooni, ning parameetrite hinnangud muutuvad
ebastabiilseteks. Parameetri usalduspiirid muutuvad väga laiaks.
Kõrge R2
kuid mitteusaldusväärsed t-statistiku väärtused. Väke andmemahu
muutus põhjustab parameetri hinnangute standardvigade olulisi
muutusi.
MULTIKOLLINEAARSUSE
VÄHENDAMISE VÕIMALUSED: tugevalt korreleeruvate sõltumatute
muutujate eemaldamine mudelist. Andmete täpsustamine ja teisendamine . Valimi muutmine. Peamiste komponentide meetodi eelnev kasutamine. Kantregressiooni eelnev kasutmine. Uus mudelipüstitus.
Oluliste argumentide varieeruvuse mõju regressioonanalüüsi tulemustele (labortöö).
- Kui regressioonikordajate varieeruvus on väga suur, siis regressioonikordaja parameetri standardvea (Sa1) arvutusvalemist järeldub, et juhul kui sõltumatute muutujate X1i ja X2i vahelise sõltuvuse korrelatsioonikordaja r1,2 läheneb 1-le, siis murru nimetaja väheneb ning Sa1 suureneb. Seega parameetrite hinnangud a1 ja a2 muutuvad ebatäpsemateks.
- Varieeruvuse suurenemisel t-statistik muutub mitteusaldusväärseks (t-statistiku avaldises parameetri hinnang jagatakse standardveaga)
- Multikollineaarsus suurendab regressioonikordajate varieeruvust
Fiktiivsete muutujatega regressioonimudel, tõlgendus.
Alati
ei saa majandusnähtust või -protsessi iseloomustada vaid
kvantitatiivsete näitajatega. Küllalt sageli tuleb arvesse võtta
ka kvalitatiivset infot, näiteks töötaja haridus , sugu,
majandus-protsessi toimimine enne või pärast mõnda
majanduspoliitilist otsust jne.
Tegemist
on kvalitatiivsete andmetega , mida saab teisendada
kvantitatiivseteks. Sel viisil saadud regressioonimudeli muutujaid
nimetatakse teisendatud või fiktiivseteks muutujateks (dummy
variables).
Kvalitatiivsed muutujad iseloomustavad objekti või subjekti tunnuseid, mille
väärtuseks ei ole arvud, näiteks töötaja sugu, haridustase,
perekonnaseisu jne.
Kvalitatiivsete
muutujate lülitamiseks regressioonimudelisse kasutatakse nn
fiktiivseid muutujaid (dummyvariables).
Fiktiivsed
muutujad on sellised muutujad, millel on ainult kaks väärtust, mis
reeglina on 0 ja 1.
Näiteks,
kui soovime uurida palga sõltuvust haridusest, siis defineeritakse muutuja:
Üldine
reegel fiktiivsete muutujate defineerimisel:
Kui
kvalitatiivne muutuja omab m erinevat väärtust, siis tema
lülitamiseks regressioonimudelisse defineeritakse m-1 fiktiivset
muutujat.
Fiktiivseid
muutujaid saab kasutada ka sesoonsuse kirjeldamiseks andmetes.
Kui
sesoonsuse perioode on m, siis defineeritakse maksimaalselt m -1
fiktiivset
muutujat.
- Näiteks sesoonsuse uurimisel kvartalite lõikes (m = 4) defineeritakse maksimaalselt 3 fiktiivset muutujat (m -1 = 3);
- Kuude (m = 12) andmete korral maksimaalselt (12 -1) 11 fiktiivset muutujat.
Heteroskedastiivsuse olemus; põhjused; tagajärjed; avastamise meetodid.
Kui
juhusliku liikme dispersioonide konstantsuse nõue ei ole täidetud,
siis on mudelis tegemist heteroskedastiivsusega.
Heteroskedastiivsuse
põhjused
1.
Modelleeritava protsessi omapära
- Majandussubjekti suuremad võimalused (sissetulekud, kasum) annavad subjektile suurema valikuvabaduse.
- Sõltumatu muutuja kasvuga varieeruvus muutub (õpiprotsesse kirjeldavad mudelid: mida pikem õpiaeg, seda vähem trükivigu)
- Heteroskedastiivsuse oht mudelis on sageli seda suurem, mida suurem on erinevus mudelis kasutatud majandusnäitajate suurima ja väiksema taseme vahel.
2.
Vead mudeli spetsifitseerimisel
- Mõni oluline seletav muutuja on mudelist välja jäänud.
- Mudeli kuju on vale.
3.
Ebaharilikud vaatlused (mõnede muutujate oluliselt erinevad
väärtused).
- Kui heteroskedastiivsus mudelis on tingitud modelleeritava protsessi sisust ning mudeli parameetrite hindamiseks tuleb lisaks tavalisele vähimruutude meetodile kasutada ka teisi hindamismeetodeid, siis sellist heteroskedastiivsust nim ka puhtaks heteroskedastiivsuseks.
- Mudeli valest spetsifikatsioonist tulenevat heteroskedastiivsust nim ebapuhtaks heteroskedastiivsuseks.
Heteroskedastiivsuse
tagajärjed
- Mõju parameetrite hinnangule
- Parameetrite hinnangud on lineaarsed nihketa hinnangud, kuid nad ei ole parimad, st nad ei ole vähima dispersiooniga, nad ei ole efektiivsed.
Mis
juhtub heteroskedastiivsuse korral?
- 1.Hinnangud ei ole efektiivsed.
- 2.Parameetri hinnangute standardhälbed on nihkega ja üldjuhul ei ole teada, kas leitud standardhälve ülehindab või alahindab hinnangu tegelikku standardhälvet.
- 3.Leitud usalduspiirid ei ole tõesed, seega ei pruugi usaldusväärsed olla ka hüpoteeside testimise tulemused.
Heteroskedastiivsuse
avastamine
Heteroskedastiivsuse
olemasolu vahetu kontrollimine ei ole enamasti võimalik, kuna valimi
põhjal ei saa leida juhuslike vigade dispersioone. Analüüsitakse
vaid hinnatud mudeli jääkliikmete ruutusid käsitledes neid
juhuslike vigade dispersioonide hinnangutena. Jääkliikmete ruutude
põhjal otsustatakse, kas mudelis on heteroskedastiivsus või mitte.
Heteroskedastiivsuse avastamiseks puudub ühene ja ainuõige meetod.
Avastamine
graafilisel meetodil
- Y teljel kujutatakse jääkliikmeid või nende absoluutväärtusi.
- X teljel kas vaatlustulemuse järjekorra numbrit, mõnda sõltumatut muutujat või hinnatud sõltuvat muutujat Y arv.
- Kui on näha jääkliikmete varieeruvuse muutust sõltuvalt x-teljel asuvast muutujast, siis see viitab heteroskedastiivsuse olemasolule.
Mitmese regressioonimudeli konstrueerimise põhimõtted.
Mitmese
regressioonimudeli korral uuritakse seost endogeense (sõltuva)
muutuja Y ning eksogeensete (sõltumatute) muutujate vahel.
Eeldatakse, et sõltuvat muutujat Y mõjutavad mitu sõltumatut
muutujat ning nende mõju sõltuvale muutujale on lineaarne.
Selline
olukord on majanduslike protsesside analüüsimisel tüüpiline, sest
tegelikus elus mistahes majanduslik nähtus või protsess sõltub
alati suurest hulgast teguritest i (sõltumatutest muutujatest).
Parima
alamhulga meetod
Kriteerium – korrigeeritud deterimantsioonikordaja
- Mitmese regressioonimudeli konstrueerimine – sõltumatute muutujate valik – toimub mitmes etapis ( etappide arv sõltub sõltumatute muutujate arvust)
- Parimaks mudeliks osutub mudel, kus korrigeeritud determinatsioonikordaja omab kõige kõrgemat väärtust (parameetri hinnangud peavad olema selles mudelis statistiliselt olulised, võrrelda t‐statistikuväärtust t‐kriitiliseväärtusega)
Kriteerium
– Mallow Cp statistik
- Alternatiivsete mudelite leidmisel on eesmärgiks leida mudel, kus Cp on võrdne või väiksem kui k+1.
- Kui mitu mudelit vastavad sellele kriteeriumile, tuleb kontrollida, kas muutujad nendes regressioonimudelites on statistiliselt olulised.
16.
Andmed ökonomeetrilistes mudelites. Põllumajanduslike
ökonomeetriliste mudelite koostamine. Muutujate valik
põllumajanduslike ökonomeetriliste mudelite koostamisel.
EMÜ
majandus- ja sotsiaalinstituudis välja töötatud Eesti
piimandussektori mudel. Mudeli koostamise aluseks on FAPRI EU GOLD mudel, mis on oma olemuselt dünaamiline, osaliselt tasakaalustatud
globaalne mudel:
mudeli
dünaamilisus
võimaldab
mõjurite (endogeensete ja eksogeensete muutujate) kirjeldamist ajas
ning prognooside tegemist tuleviku kohta;
osaline tasakaalustatus tähendab
seda, et olulised makromajanduslikud näitajad nagu oluliste
piimatoodete (või, juust, lõssipulber ja piimapulber ) hinnad,
elanike arv (sisetarbijad), SKP ühe elaniku kohta, SKP kasvuindeks ,
tarbijahinnaindeks jne määratakse kindlaks mudeliväliselt;
mudeli
globaalsus tähendab
seda, et nii endogeensed kui eksogeensed muutujad on oma olemuselt
makromajanduslikud, st iseloomustavad kogu Eesti
põllumajandussektorit ning majandust kui tervikut .
Piimandussektori
mudeli üheks iseärasuseks on asjaolu, et mudelis käsitletakse
eraldi kolme põhikomponenti: toorpiima, piimavalku ja piimarasva.
Põhiliste toodete (juust, või, lõssipulber, piimapulber jm tooted)
tootmise, tarbimise, impordi, ekspordi, varude jm võrrandite
modelleerimise aluseks on kasutada olev piimavalk ja piimarasv.
Nagu
ka Eesti piimanduse makroökonomeetriline mudel, on Eesti
teraviljasektori mudel oma olemuselt dünaamiline, osaliselt
tasakaalustatud globaalne mudel:
Teraviljasektori
mudelis on vaatluse all neli peamist teraviljakultuuri – oder,
nisu, kaer ja rukis . Kõikide kultuuride tootmist, tarbimist,
importi, eksporti ning varude muutumist modelleeritakse erinevate
võrrandite abil. Mudelis on 52 endogeenset (modelleeritavat)
muutujat ja 41 eksogeenset (mudelivälist) muutujat.
Ökonomeetriliste
mudelite võrrandid koosnevad uuritavatest näitajatest ning neid
mõjutavatest teguritest, mida nimetatakse endogeenseteks ja
eksogeenseteks muutujateks:
endogeensete
muutujate, ehk uuritavate näitajate, väärtused määratakse
kindlaks antud mudeliga (käitumisvõrrandite ning võrdustega);
eksogeensed
muutujad on uuritavat näitajat mõjutavad mudelivälised tegurid,
mida käsitletakse mudeli seisukohalt etteantud suurustena.
Erineva kujuga regressioonimudelid: muutujate suhtes lineaarne, astmefunktsioon , eksponentfunktsioon , logaritmfunktsioon , hüperbool, parabool , logaritmfunktsioon, polünoom. Mudelite võrrandid, joonised, elastsuskoefitsient , lineariseerimine, parameetrite tõlgendused, võrrandite nimetused (poollogaritmiline, log-lin jt), erinevate regressiooni- mudelite võrdlemine.
Muutujate
suhtes lineaarne mudel
Kõige tavalisem mudeli esitusviis on muutujate suhtes lineaarne mudel kujul
Y=a0+a1*X+e
Regressioonikordaja
a1
tähendus:
Regressioonikordaja
väljendab sõltuva muutuja Y muutust, kui sõltumatu muutuja X
muutub ühe ühiku võrra. Üldine võte regressioonikordaja
tõlgendamiseks – diferentseerida regressioonimudeli mõlemaid
pooli a1=dY/dX
Kordaja
näitab ligikaudselt, mitu ühikut muutub keskmiselt Y, kui muutuja X
muutub ühe ühiku võrra.
- Kui kordaja on positiivne, siis X kasvades muutuja Y kasvab.
- Kui kordaja on aga negatiivne, siis X kasvades muutuja Y kahaneb.
Lineaarse
mudeli keskmine elastsus E=a1*Xkesk/Ykesk
- Xkesk ja Ykesk on vastavalt muutujate X ja Y keskmised väärtused.
- Lineaarse mudeli regressioonikordaja ja elastsuskoefitsent ei lange kokku.
Elastsuskoefitsent
Majandusprotsessi
uurimiseks on vaja võrrelda omavahel üksteisest sõltuvaid suurusi,
mida mõõdetakse erinevate mõõtühikutega. Selliseks suuruseks,
mis ei sõltu võrreldavate suuruste mõõtühikutest, on
protsentides mõõdetav elastsus.
Astmefunktsioon
Astmefunktsioon
Y=a0*Xa1*e
ei ole lineaarne muutujate suhtes.
Regressioonimudeli
parameetrite hindamiseks kasutatakse lineariseerimist (võrrandi
mõlemad pooled logaritmitakse)
lnY=lna0+a1lnX
Nüüd
on mudel lineaarne parameetrite suhtes ja lineaarne ka muutujate Y ja
X logaritmide suhtes.
Log-log
või log-lineaarne mudel
Kui
astmefunktsiooni mudel on teisendatud logaritmilisele kujule
lnY=c0+a1*lnX+e
siis
nim sellist mudelit log-log mudeliks, kuna nii sõltuv kui sõltumatu
muutuja on logaritmitud kujul. Ning log-lineaarseks mudeliks, kuna
sellises mudelis on muutujad logaritmitud kujul, mudel on aga
parameetrite suhtes lineaarne.
Konstantse elastsusega mudeli korral on muutujad mudelis logaritmitud kujul.
Poollogaritmiline
mudel
Eksponentsiaalne
funktsioon logaritmilisel kujul
lnY=c0+a1*X
Sellist
mudelit nim poollogaritmiliseks mudeliks(st avaldise parem pool on
tavalises mastaabis) lineaarne funktsioon ning vasak pool
logaritmilises mastaabis.
Kui
sõltuv muutuja Y on logaritmilisel kujul ning sõltumatud muutujad X
lineaarsel kujul, siis sellist mudelit nim ka log-lin mudeliks.
Sellist
funktsiooni on otstarbekas kasutada siis, kui sõltuv muutuja muutub
võrreldes sõltumatu muutujaga oluliselt kiiremini.
Mudel
Kuju
Regressioonikordaja sisu
Elastsuskoefitsent
lineariseerimine
Lineaarne
Y=a0+a1X
Kui X muutub ühe ühiku, siis Y muutub a1 võrra
E=a1*(Xkesk/Ykesk)
Log-log(astmefunktsioon)
lnY=c0+a1lnX
Kui X muutub 1%, siis Y muutub a1%
E=a1
lnY=lna0+a1lnX
(võrrandi mõlemad pooled on logaritmitud)
Log-lin(eksponentsiaalne)
lnY=c0+a1X
Kui X muutub ühe ühiku võrra, siis Y muutub 100a1% võrra
E=a1*X
Y=a0*ea1x
Lin-log(logaritmiline)
Y=c0+a1lnX
Kui X muutub 1% võrra, siis Y muutub 0,01a1 võrra
E=a1*(1/Y)
Ruutfunktsiooni mudel (parabool)
Kõige
enam praktikas kasutamist leidnud mittelineaarse funktsiooni tüübiks
on parabool ehk ruutmudel.
Y=a0+a1*X+a2*X2+e
Võrrelda
lihtsa regressiooni ja ruutfunktsiooni mudeli korrigeeritud
determinatsioonikordaja R2 väärtusi.
Kui
ruutfunktsiooni mudeli korrigeeritud determinatsioonikordaja R2 on
suurem kui lihtsa regressioonimudeli R2, siis on ruutfunktsiooni
mudel selgitanud suurema osa sõltuva muutuja Y varieeruvusest.
Hüperboolne
mudel
Hüperbooli
ehk pöördvõrdelise sõltuvuse korral regressioonivõrrand omab
järgmist kuju.
Y=a0+a1*(1/X)+e
Hüperboolse
mudeli korral on olulisem tähendus parameetril a0 ehk vabaliikmel,
mis väljendab sõltuva muutuja Y väärtust sõltumatu muutuja X
lähenemisel lõpmatusele.
Parameetri
a1 analüüsimisel on oluline tähendus tema märgil.
- Kui a1 on positiivne, siis X-i kasvades Y kahaneb.
- Kui a1 on negatiivne, siis X kasvades Y kasvab.
Elastsuskoefitsent
on leitav E=-a1*(1/X*Y)
Hüperboolset
mudelit on kasutatud järgmiste majandusnähtuste vaheliste seoste
analüüsimiseks.
Astmefunktsiooni (Cobb– Douglase tootmisfunktsiooni) parameetrite leidmine (labortöö).
Cobb-Douglase
tootmisfunktsioon – toodangu mahu sõltuvus kapitalist (x1) ja
tööjõust (x2). Funktsioon eeldab, et ressursid on vastastikku asendatavad
Y=a0*X1a1*X2a2
A0=1
A1+a2=1
A1
ja a2 näitavad kapitali ja tööjõu osakaalu
Ressursi
kasutamise efektiivsuse hindamiseks kasutatakse osatuletist
(funktsiooni muutumise kiirust). See võimaldab teada saada, mis
juhtub toodanguga, kui muutuvad ressursside mahud
Cobb-Douglase
funktsiooni graafikuks on kumer pind. Cobb-Douglase funktsioon on
kasvav funktsioon
Ressursi
x2 suurenedes kasvab funktsioon oluliselt mittelineaarselt, kuna astendaja a2 ligikaudu 0
Ressursi
x1 suurenedes kasvab funktsioon praktiliselt lineaarselt, kuna a1
astendaja=1
Majanduslikult
näitab ressursi K osatuletis ∂y/∂x1 (ressursi kasutamise
efektiivsus)
tootmismahu
ligikaudset muutu, kui ressurssi K kasutatakse ühe ühiku võrra
enam ja ressursi L kogus ei muutu.
Majanduslikult
näitab ressursi L osatuletis ∂y/∂x2 tootmismahu ligikaudset
muutu,
kui
ressurssi L kasutatakse ühe ühiku võrra enam ja ressursi K kogus
ei muutu.
Järelikult
vastava ressursi osatuletis näitab kogutoodangu ligikaudset muutu
selle
ressursi ühe täiendava ühiku kasutamisest eeldusel, et teine
ressurss ei muutu.
Isokvandid. Nende kasutamine (labortöö).
Majandusmudelite
analüüsimisel on tihti otstarbekas kujutada uuritavaid funktsioone
graafiliselt. Kahe muutuja funktsioonide kujutamiseks saab kasutada
selle funktsiooni nivoojooni. Majanduses kasutatavate kahe muutuja
funktsioonide nivoojoonteks on samatoodangujooned, samakulujooned,
samakasulikkuskõverad.
Olgu
Y = f(x1, x2) mingi tootmisfunktsioon, kus x1 ja x2 on
tootmistegurite K ja L mahud.
Selle
funktsiooni nivoojoon f(x1,x2) =Y (etteantud Y suurus) kõikvõimalikud
tootmistegurite K ja L mahtude paarid (x1, x2), kus tootmismaht on
võrdne suurusega Y.
Seda
nivoojoont nimetatakse antud juhul samatoodangujooneks ehk
isokvandiks. Seega samatoodangujoone kõikides punktides on
tootmisfunktsiooni väärtused võrdsed.
Omadused
- Kõik isokvandid on nõgusad
- Erinevad samatoodangujooned omavahel ei lõiku. Seega vastab kindlale tootmistasemele parjasti üks samatoodangujoon .
- Suuremale toodangu mahule vastav samatoodangujoon paikneb koordinaatide alguspunktist kaugemale.
- Samatoodangujoone kõigis punktides on tema puutuja tõus negatiivne, st ühe muutuja kasvades teine muutuja kahaneb. Ühe tootmisteguri kulu suurendamisel võib tootmismaht jääda muutumatuks, kui teise tootmisteguri kulu kahaneb.
Tootmismaht
Y=13 ei muutu, kui samaaegselt suurendada tööjõudu väärtuselt L1
väärtuseni L2 ja vähendada kapitali väärtuselt K1 väärtuseni
K2.
20.
Mittestandardne ökonomeetrilise mudeli parameetrite hindamise
meetod: peamiste komponentide meetod (olemus; kasutamise võimalused)
(labortöö).
Peamiste
komponentide meetod on suhteliselt kaua eaga tuntud mitmemõõtmelise
statistilise analüüsi meetod. Peamiseks takistuseks peamiste
komponentide meetodii kasuamisel on olnud suur arvutustööde maht,
keskel läbi üks suurusjärk suurem võrreldes klassikale
regressioonanalüüsiga. Ulatuslikumalt on nimetatud meetodit hakatud kasutama alles personaalarvutite
kasutusele võtmise järel.
Peamiste
komponetide meetodi olemus seisneb järgmises. Esialgsed sõltumatud
muutujad X1,
X2,
… ,Xn
teisendatakse lineaarse teisenduse abil tinglikeks suurusteks
ehk komponentideks. Kõigepealt leitakse
esimene komponent K1.
Seejärel leitakse lineaarse teisenduse abil teine komponent K2.
Edasi leitakse kolmas, neljas jne komponendid.
Peamiste
komponentide meetodi kasutamise korral on kaks “aga”. Esiteks
saadud komponente on sisuliselt raske tõlgendada. See asjaolu on
tähtis siis, kui peamisi
komponente
käsitletakse eraldi
analüüsiobjektina.
Teiseks peamiste komponentide kasutamisel üles kerkivaks
probleemiks on edaspidises
analüüsis kasutatav komponentide arv.
Regressioonivõrrandi kordajad on efektiivsed seetõttu,
et peamised komponendid rahuldavad kõiki klassikalise
regressioonanalüüsi eeldusi (komponendid on ortogonaalsed, peamiste
komponentide varieeruvus on suurim).
Teoreetiliselt peaksid kõik variandid andma regressioonikordaja a = 1.
Kui
sõltumatute muutujate vahel ei esine multikollineaarsust, siis
peamiste komponentide meetodi kasutamine mingit eelist ei anna (tase
1).
Kui sõltumatute muutujate vahel esineb multikollineaarsus, siis teoreetiliselt peaks parameetrite hindamisel (regressioonikordajate leidmisel) olema kõige parem meetod vähimruutude meetod, kuid sellisel juhul muutuvad regressioonikordajate varieeruvused suureks ning regressioonikordajad muutuvad ebastabiilseteks ja ebausaldusväärseteks (tase 4 - klassikaline regressioon).
Kui sõltumatute muutujate vahel esineb tugev korrelatsioon (multikollineaarsus), siis komponentanalüüs annab paremad tulemused. Peamiste komponentide meetodi kasutamise korral multikollineaarsuse mõju kaob ära ja selle tulemusena regressioonikordajad on lähemal ideaalsele (a=1) ja muutuvad stabiilsemateks. Regressioonikordaja standardhälve väheneb võrreldes klassikalise regressioonanalüüsi tulemustega (Sai). Mida väiksem on regressioonikordaja varieeruvus (standardhälve), seda usaldusväärsem (täpsem) on tulemus (tase 4, r= 0,95).) Mida vähem komponente komponentanalüüsis kasutatakse, seda paremad tulemused.
21.
Ökonomeetrilise mudeli analüüs statistiliste näitajate (F, t
–kriteeriumi baasil).
Formaal statistiline analüüs – 1 tabel: üldinfo regressioonimudeli kohta. Põhinäitaja on R2, sellega iseloomustatakse kvaliteeti, näitab millise osa võrrandist seletab ära (%). Üle 80% on väga hea mudel. Mida väiksem standard error ehk jääkstandardhälve (ε) on seda parem. 2 tabel: dispersioonanalüüsi tabel. Oluline F, mis iseloomustab mudeli statistilist usaldusväärsust, peaks olema vähemalt 3. Paremal olev on statistilist eksimuse tõenäosust iseloomustav. Kui on väike on usaldusväärne. 3 tabel: coefficent on regressioonikordaja. Teine veerg standarthälve, mida väiksem seda usaldusväärsem. Kolmas veerg t-kriteerium, kui on üle I2I on usaldusväärne. Neljas veerg näitab t tõenäosust, kui on alla 0,05 on usaldusväärne.
Majanduslik analüüs – esiteks leida mõõtühik (y on teravilja kg/ha ja x on väetise kg/ha; y=a*x; a=y/x; a=teravilja kg*ha/ha*väetise kg=teravilja kg/väetise kg). Samas a on kui efektiivsuse karakteristik, näitab kui efektiivne on kasutamine.
Analüüs:
- Märgi analüüs – miinus tähendab, et suurenedes y väheneb; lähtuvalt majandusest tuleb analüüsida milline peab olema
- Hinnang – hea, halb, suur, väike. Näiteks kordaja 1,03, kui väetist suurendame 1 kg võrra, siis saagikus suureneb 1,03. 1 kg väetist on 3 kr, 1 kg teravilja 1,5 kr. Kulutame 3 kr ja saame 1,5 kr, seega on väetamine mõtetu.
- Hindepunkt iseloomustab mulla viljakust. Kõige kõrgem Järvamaal.
22.
Ökonomeetrilise mudeli majanduslik ( sisuline analüüs):
regressioonikordajate mõõtühikud; regressioonikordajate
majanduslik sisu; regressioonikordajate märkide vastavus
majandusteooria seisukohtadele.
Majandusterminites
regressioonikordaja aj
kujutab endast sõltumatu muutuja efektiivsust ehk sõltumatu muutuja
puhasmõju. Lihtsa lineaarse regressioonivõrrandi funktsiooniks on
piimatoodang lehma kohta ja
argumendiks töökulu
piima tootmisel.
Anda
ette argumendi ja funktsiooni mõõtühikud
Y
- piimatoodang
lehma kohta - kg/lehma
kohta
X
- töökulu
piima tootmisel
tundi/lehma
kohta − €/lehma kohta
tundi/kg
kohta − €/kg kohta
- tundi/lehma kohta - Y suureneb
- €/lehma kohta - Y suureneb
- tundi/kg kohta - Y väheneb
- €/kg kohta - Y suureneb ( tunnipalk on kõrgema toodangu korral suurem)
Y
- söödakulu - €/kg kohta
–X
- piimatoodang (kg/ lehma kohta)
Kui
piimatoodang lehma kohta suureneb 1 kg võrra, siis söödakulu 1 kg
piima tootmisel väheneb regressioonikordaja võrra
Y
- söödakulu - €/lehma kohta
–X
- piimatoodang (kg/lehma kohta)
Kui
piimatoodang lehma kohta suureneb 1 kg võrra, siis söödakulu 1
lehma kohta suureneb regressioonikordaja võrra
Regressioonikordaja
aj
Y/Xj=aj
näitab mitme ühiku võrra muutub sõltuv muutuja Y, kui sõltumatu
muutuja Xj
muutub ühe ühiku võrra. Majandusterminite regressioonikordaja aj
kujutab endast sõltumatu muutuja efektiivsust ehk sõltumatu muutuja
puhasmõju.
Regressioonikordaja
tõlgendus: mitmese lineaarse
statistilise sõltuvuse(MLSS) sõltuvaks muutujaks Y on kartuli
saagikus (ts/ha) ja sõltumatuks muutujaks X1
väetise kulu (kg/ha) ning regrssioonikordaja a1=0,25.
Mida sellest arvväärtusest järeldada?Väetise kulu suurenedes 1 kg
võrra hektari kohta suureneb kartuli saagikus 0,25 ts võrra hektari
kohta.
Regressioonivõrrandi
kordaja ai?-0,03.
Argumendiks on piimatoodang lehma kohta (ts/lehma kohta).
Funktsiooniks on söödakulu 1 ts piima tootmisel (€/ts piima
kohta) Mis juhtub funktsiooniga kui argument suureneb 500 kg võrra
lehma kohta? Argumendi mõõtühik ts/lehma kohta. 500kg = 5ts.
Regressioonikordaja ai=-0,03
seega söödakulu Y väheneb 5*0,03 =0,15 € võrra ts piima kohta.
Regressioonikordaja
mõõtühik ja majanduslik sisu:
lihtsa lineaarse regressioonivõrrandi funktsiooniks on piimatoodang
lehma kohta ja argumendiks töökulu piima tootmisel. Y(funktsioon)
piimatoodang lehma kohta x(argument) töökulu piima tootmisel. Anda
ette mõõtühikud: Y kg/lehma kohta. X tundi lehma kohta -- €
lehma kohta (tundi kg kohta---€/kg kohta.) kui piimatoodang
suureneb lehma kohta 1 kg võrra, siis söödakulu 1kg piima
tootmisel väheneb regressioonikordaja võrra.. Y-söödakulu
(€/lehm) Xpiimatoodang (kg/lehm) Kui piimatoodang lehma kohta
suureneb 1 kg võrra, siis söödakulu 1 lehma kohta suureneb
regressioonikordaja võrra.
23.
Statistilise näitaja olemus. Põllumajandusstatistika näitajate
süsteem.
Statistiline
näitaja on
andmeelement, mis esitab kindla aja, koha ja muude tunnustega
määratud statistilisi andmeid. Statistiline näitaja iseloomustab
uuritavat objekti või nähtust — statistilist üksust kui liiki.
Statistilisel üksusel on mitmesuguseid tunnuseid.
Osa
neist on mõõdetavad ehk arvulised (ettevõtte investeeringud ja
tulud, leibkonna sissetulek), osa liigitavad ehk klassifitseerivad
(ettevõtte tegevusala ja omaniku liik, leibkonna tüüp ja elukoht,
isiku vanus ja sugu).
Mõõdetavaid
tunnuseid nimetatakse koguselisteks
muutujateks,
liigitavaid klassifitseerivateks.
Klassifitseeriva muutuja võimalikud väärtused on määratud
klassifikaatori või muu liigituse kategooriatega. Näiteks
tegevusala on määratud Eesti majanduse tegevusalade
klassifikaatoriga (EMTAK). Koguseline muutuja määrab statistilise
näitaja sisu, klassifitseeriv muutuja näitab, millises lõikes
koguseline muutuja esitatakse. Klassifitseeriv muutuja võib puududa .
Statistilist
näitajat iseloomustavad järgmised tunnused:
1.
Statistilisel näitajal on olemas nii kvantitatiivne
kui
ka kvalitatiivne
külg,
st mistahes näitaja omab arvulist väärtust ja vastavat mõõtühikut
(näitaja kvantitatiivne külg) ning sisulist väärtust, mille
alusel me otsustame kas vastav arvväärtus on suur või väike; rahuldab see meid või ei rahulda; kas tulemused on head, keskpärased
või halvad jne (näitaja kvalitatiivne külg).
2.
Statistiline näitaja on oma olemuselt üldistav
näitaja.
Näiteks näitaja “teravilja saagikus Eestis 2010. aastal” on
välja kujunenud üksikute põllumajandustootjate teravilja
saagikuste alusel ning edasi üksikute põldude saagikuste baasil.
3.
Statistiline näitaja on ajalooliselt
konkreetne,
st mistahes statistilisel näitajal on olemas nii aja kui koha
koordinaadid. Mistahes näitaja iseloomustab alati mingit konkreetset
objekti – Eesti vabariiki, maakonda, põllumajanduslikku ettevõtet,
kogu Euroopa põllumajandust jne ning see näitaja iseloomustab seda
objekti mingil konkreetsel ajahetkel või ajavahemikul.
4.
Statistilised näitajad on oma olemuselt olulised
karakteristikud (tunnused), milles avaldub arengu seaduspärasus. Mistahes
põllumajandusettevõtet või tootmisprotsessi võib iseloomustada
väga paljude erinevate näitajatega. Statistikaameti poolt kogutakse
ainult olulised näitajad.
Statistiliste
näitajate süsteem
Statistikaameti
poolt hangitakse põllumajanduse kohta suur hulk arvandmeid ehk
statistilisi näitajaid. Selleks et omada ülevaadet ja orienteeruda
selles suures näitajate hulgas on need näitajad vaja teatud
põhimõtete kohaselt süstematiseerida. Süstematiseerimine võib
toimuda erinevate tunnuste alusel.
Esimeseks
võimaluseks on näitajate süstematiseerimine tootmisharude järgi:
1.
Taimekasvatust
iseloomustavad näitajad;
teraviljakasvatust iseloomustavad näitajad;
kartulikasvatust iseloomustavad näitajad;
heinakasvatust iseloomustavad näitajad;
linakasvatust iseloomustavad näitajad jne.
2.
Loomakasvatust
iseloomustavad näitajad;
veisekasvatust iseloomustavad näitajad;
seakasvatust iseloomustavad näitajad;
linnukasvatust iseloomustavad näitajad jne.
Teiseks
võimaluseks on näitajate süstematiseerimine nende osavõtu järgi
tootmisprotsessis:
1.
Tootmisressursside
(tootmispotentsiaali) olemasolu ja nende kasutamist iseloomustavad
näitajad;
põllumajandusliku maa olemasolu, maa kvaliteeti ja maa kasutamist iseloomustavad näitajad (maaressursi näitajad);
tööjõu olemasolu, tööjõu kvaliteeti ja tööjõu kasutamist iseloomustavad näitajad (tööjõuressursi näitajad);
hoonete ja masinate olemasolu, hoonete ja masinate kvaliteeti ja nende kasutamist iseloomustavad näitajad (kapitaliressursi näitajad);
ilmastikku iseloomustavad näitajad (kliimaressursi näitajad).
2.
Tootmistulemusi iseloomustavad näitajad;
tootmise mahtu iseloomustavad näitajad;
tootmise struktuuri iseloomustavad näitajad;
tootmise intensiivsust iseloomustavad näitajad;
tootmise efektiivsust iseloomustavad näitajad;
toodangu kvaliteeti iseloomustavad näitajad;
3.
Toodangu
realiseerimist (turustamist) iseloomustavad näitajad;
naturaalsed näitajad;
rahalised näitajad;
4.
Põllumajandusettevõtte majanduslikku tegevust iseloomustavad
näitajad:
kogutoodangut iseloomustavad näitajad;
sissetulekuid iseloomustavad näitajad;
tootmiskulusid iseloomustavad näitajad;
ettevõtte maksustamist iseloomustavad näitajad.
Peale
eespool toodud statistiliste näitajate süstematiseerimist võib
kasutada ka muid statistiliste näitajate süstematiseerimise
põhimõtteid.
24.
Maastatistika. Maade kasutamist iseloomustavad näitajad. Maafondi
dünaamika.
Maa
on esmaseks ja põhiliseks tootmisressursiks põllumajanduslikus
tootmises. Maa liigitatakse põllumajandusliku kasutamise otstarbe järgi järgmisteks kõlvikuteks:
Põllumajandusmaa;
Mittepõllumajandusmaa.
Põllumajandusmaa
omakorda liigitatakse järgmiselt:
Põllumaa;
Viljapuu- ja marjaaiad;
Looduslik rohumaa.
d)
maa, mida ei kasutata põllumajandustootmises, kuid mida hoitakse heades põllumajandus- ja keskkonnatingimustes.
Eestis kasutatava maa kvaliteeti iseloomustatava näitaja – hindepunktide
väljatöötamisel on lähtutud mulla looduslikust viljakusest.
Looduslikku viljakust iseloomustava hindepunkti algväärtust on
korrigeeritud vastavalt maadel tehtud kultuurtehnilistele töödele.
Eesti põllumaa keskmine hindepunkt on ligikaudu 43 palli (punkti).
Parimate maade hindepunkt ulatub ca 60 punktini ning halvemate maade
hindepunkt on ainult ca 25 punkti.
25. Taimekasvatuse statistika. Kasvupindade statistika. Kasvupindade
dünaamika.
Taimekasvatus on väga oluline põllumajandusharu. Taimekasvatustoodang on tooraineks toiduainete tööstusele ja söötadeks loomakasvatuses.
Taimekasvatust on võimalik iseloomustada väga paljude näitajatega.
Esimeseks tingimuseks taimekasvatustoodangu saamiseks on maa olemasolu, selle
harimine ja seemnete külvamine. Kasvupinna suurus on kõige
olulisemaks teguriks , millest sõltub taimekasvatustoodangu maht.
Kasvupindade kohta peetakse arvestust kultuuride ja kultuuride
rühmade lõikes.
Üksikasjalikuma
statistilise arvestuse korral eristatakse kahte erinevat kasvupinna
kategooriat:
a)
külvipind ( kasvupind ) (aruandeaastal saagi saamiseks külvatud pind,
sh eelmistest
aastatest säilinud külvid, püsirohumaa, kesa);
b)
koristuspind (pind, millelt aruandeaastal koristati saak).
Kasvupind
(külvipind) - põllukultuuri all olev pind. Selle pinna alusel
toimub ka saagikuse arvutamine.
Statistikaamet kasutab andmete kogumisel erinevatel aastatel erinevat mõistet.
Koristuspind
on see osa kasvupinnast, millelt aruandeaastal koristati saak.
KASVUPINDADE
DÜNAAMIKA
Statistiliste
näitajate dünaamika all mõistetakse vastavate näitajate muutumist
aja jooksul.
Kuna
statistilise näitaja dünaamikat käsitleme antud kursuse käigus
esmakordselt, siis vaatleme kõigepealt statistiliste näitajate
dünaamika analüüsi üldisi põhimõtteid, mis peavad paika nii
kasvupindade dünaamika analüüsimisel kui ka muude näitajate
dünaamika analüüsil. Näitajate dünaamikat iseloomustavad
statistiliste näitajate aegread.
Dünaamika
analüüsi eesmärgiks on:
a)
anda hinnang analüüsitava näitaja kujunemisele analüüsitava
perioodi kestel;
b)
välja selgitada need põhjused, mis on oluliselt mõjutanud
analüüsitava näitaja kujunemist;
c)
prognoosida analüüsitava näitaja kujunemist lähemas või kaugemas
tulevikus.
26.
Kogusaaki ja saagikust iseloomustavad näitajad. Põhinäitajate
dünaamika.
Kogusaak ja saagikus on kõige tähtsamad taimekasvatust iseloomustavad
statistilised näitajad. Üksikasjalikuma statistilise arvestuse
korral eristatakse nelja erinevat kogusaagi ja saagikuse kategooriat
(nimetatud kategooriad kehtivad eelkõige teravilja kohta):
Kogusaagi ja saagikuse prognoos;
Bioloogiline kogusaak ja saagikus;
Kogusaak ja saagikus esialgses kaalus (punkrikaalus);
Kogusaak ja saagikus aidakaalus.
Vaatleme
neid näitajaid lähemalt ja selgitame, mis on nende näitajate
majanduslik sisu.
Kogusaagi
ja saagikuse prognoos
määratakse kindlaks kevadel peale kultuuride tärkamist, st samal
ajal kui määratakse kindlaks kasvupind (kevadine produktiivne külvipind). Valikvaatlustega hinnatakse tärganud kultuuride
tihedust ja võrsumist ning selle alusel prognoositakse saagikus ja
kogusaak. See on saagikuse hindamine nn “oraste pealt”. Nende
näitajate , olgugi et ligikaudsete näitajate, majanduslik sisu
seisneb selles, et varakult (praktiliselt juunikuu alguses) saadakse
esimene hinnang loodetavast saagist. Kehva kogusaagi ja saagikuse
prognoosi korral on aeg hakata otsima kohta, kust saab soodsalt (varakult sõlmitud lepingute tõttu) juurde osta puudu tulev
teravilja kogus. Kui aga prognoos on soodne, siis on vaja hakata
otsima turgu, kuhu realiseerida ülejäägid (eriti tähtis on see
kiiresti riknevate taimekasvatussaaduste korral). Varakult sõlmitud lepingud võivad osutuda soodsamateks.
Bioloogiline
kogusaak ja saagikus
määratakse kindlaks valikvaatluste teel vahetult enne koristamise
algust. Nimetatud näitaja iseloomustab seda potentsiaalset kogusaagi
ja saagikuse taset mida on võimalik saavutada kasutatud (olemasoleva
seemnematerjali) seemnete ja tootmistehnoloogia ning ilmastiku
korral. Bioloogiline kogusaak ja saagikus on kogusaagi ja saagikuse
potentsiaalne maksimum.
Kogusaak
ja saagikus esialgses kaalus
(punkrikaalus) määratakse kindlaks koristuse käigus. Neid
näitajaid mujal maailmas ei tunta. See on nõukogude perioodi rudiment . Kuid neid näitajaid statistikaamet registreerib ning neid
on kuni viimase ajani avaldatud statistika aastaraamatutes ja
kogumikes. Põhjuseks on nimetatud näitajate lihtne hankimine ning
nende näitajate küllaltki oluline majanduslik sisu. Kogusaak ja
saagikus esialgses kaalus (punkrikaalus) iseloomustavad koristuse
käigus tehtud tööde mahtu. Nimetatud kogus teravilja on vaja lasta
läbi kombaini peksuaparaadi, nimetatud kogus teravilja on vaja
transportida põllult kuivatisse ja nimetatud kogus teravilja on vaja
kuivatada jne.
Kogusaak
ja saagikus aidakaalus
on kogusaagi ja saagikuse põhiliseks näitajaks. Neid näitajaid
kasutataks kogu arenenud maailmas. Sellist kogust teravilja saame
müüa, söödaks ja seemneks kasutada jne.
27.
Loomakasvatuse statistika. Loomade arvu iseloomustavad näitajad.
Loomade arvu dünaamika.
Loomade
olemasolu on esmaseks tingimuseks loomkasvatustoodangu saamiseks.
Loomade arv on kõige olulisemaks teguriks, millest sõltub
loomakasvatustoodangu maht. Loomade arvu kohta peetakse arvestust
looma liikide ja vanusrühmade lõikes. Eesti statistika peab loomade
arvu kohta eraldi arvestust talude, elanike majapidamiste ja
ettevõtete lõikes.
Loomade
arvu statistilist arvestust peetakse kahe erineva näitaja abil:
Loomade arv teatud kuupäeva seisuga (tavaliselt aastavahetuse seis);
Aasta keskmine loomade arv.
Loomade
arv teatud kuupäeva seisuga
kujutab endast tavalist inventuuri näitajat. Selle näitaja alusel
ei saa anda hinnangut loomakasvatuse tootmispotentsiaali kohta. Asi
on nimelt selles, et loomade arv aasta kestel pidevalt muutub. Loomi
sünnib juurde, loomad viiakse ühest vanusrühmast teise, loomad
viiakse tapamajja jne. Seejuures aastavahetusel on loomade arv
tavaliselt kõige väiksem, sest talvine sööt on kõige kallim ning
seetõttu ei ole otstarbekas pidada suurt karja. Suvel vastupidi on
sööt kõige odavam ja loomade arv on tavaliselt kõige suurem.
Nimetatud näitaja peamine eelis seisneb selles, et seda on lihtne
hankida (registreerida).
Aasta
keskmine loomade arv
on põhiline loomakasvatuse tootmispotentsiaali iseloomustav näitaja.
Aasta keskmine loomade arvu järgi saame hinnata võimalikku
loomakasvatustoodangu mahtu, hinnata vajaminevat söödakogust jne.
Selle näitaja peamiseks puuduseks on asjaolu, et seda on keerulisem
hankida (registreerida). Aasta keskmine loomade arvu leidmiseks peab
olema organiseeritud vastav pidev loomade arvu arvestus. Aasta
keskmine loomade arvu arvutamiseks kasutatakse kahesugust metoodikat:
Aasta keskmine loomade arv leitakse kronoloogilise keskmise abil;
Aasta keskmine loomade arv leitakse söötmispäevade alusel.
Kronoloogiline keskmine on vähem täpne ja seda kasutatakse vähemväärtuslike
loomade ( linnud , lambad , vasikad, sead jne) aasta keskmise arvu
leidmiseks. Suurema väärtusega loomade (lehmad, hobused , pullid
jne) aasta keskmine arv leitakse söötmispäevade alusel. Selleks
on vaja kõikide loomade jaoks pidada arvestust selle kohta, mitu
päeva üks või teine loom on karjas olnud. Kõikide loomade
söötmispäevad liidetakse ja saadud summa jagatakse 365 –ga. Kui
mingi loom on terve aasta karjas olnud, siis tema jaoks arvestuslik
söötmispäevade arv on 365. Kui mingi loom läheb aasta keskel
karjast välja (müüakse või prakeeritakse), siis tema jaoks
lähevad arvesse karjas oldud päevade arv. Kui mingi loom tuleb
aasta keskel karja (ostetakse, mullikas poegib jne), siis tema jaoks
lähevad arvesse karjas oldud päevade arv (päevad karja tulekust
kuni aasta lõpuni). Sisuliselt on siin tegemist kaalutud
aritmeetilise keskmisega, kusjuures iga looma kaaluks on karjas oldud
päevade arv.
Dünaamika
Peale sõda vähenes veiste arv võrreldes sõjaeelsega oluliselt. Kuid juba 1970. a. veiste arv ületas ennesõjaeelse taseme. Edasi veiste arv suurenes veelgi. Veiste arv oli suurim 1983. a. – 857,6 tuhat veist, ületades ennesõjaeelset taset 1,6 korda. Peale seda hakkas veiste arv vähenema. 1990. a. oli Eestis 757,8 tuhat veist. 1990. –ndatel aastatel on veiste arv pidevalt vähenenud. Peamine veiste arvu vähenemise põhjus on turu puudumine loomakasvatustoodangu jaoks.
Lehmade arvu dünaamikas avalduvad veiste arvu dünaamikaga analoogsed tendentsid. Erinevusena olgu märgitud, et peale sõda lehmade arv ei saavutanud kunagi ennesõjaaegset taset. Nõukogude perioodil oli lehmade arv suurim 1975. A. – 330,4 tuhat lehma. Sellist arengut võib hinnata normaalseks, sest kogu maailmas on mindud lehmade arvu vähendamise teed suurendades samal ajal oluliselt karja produktiivsust. Väiksema lehmade arvu korral läheb vaja vähem loomakasvatushooneid, väiksemad on kulutused hoonete sisseseadeteks, vähem läheb vaja inimesi lehmade hooldamiseks jne. 1999. aastaks on lehmade arv kahanenud 138,4 tuhandeni. Olgu märgitud, et aastatel 1992 … 1993 koostatud Phare programmis põllumajanduse arendamise kohta Eestis prognoositi lehmade arvuks Eestis 160 tuhat lehma. Seejuures eeldati, prognoositud lehmade arv on vajalik Eesti elanikkonna toitmiseks, kusjuures produktiivsuseks arvestati 4000 kg lehma kohta. Lehmade arv on nüüdseks sellest prognoosist juba tunduvalt väiksem.
Sigade arv on muutunud hoopiski suuremates piirides. Seejuures juba 1960. a. ületas sigade arv ennesõjaaegse taseme. 1979. a. ületas sigade arv miljoni piiri ja edaspidi oluliselt enam ei suurenenud. Üle miljoni oli sigade arv kuni 1989. aastani. Suurim oli sigade arv 1983. a. – 1118,3 tuhat siga, ületades ennesõjaeelset taset 3,9 korda. 1999. aastaks oli sigade arv väiksem kui enne sõda.
Lammaste arv on pidevalt vähenenud ja moodustas 1999. aastal alla 10 protsendi ennesõjaaegsest tasemest.
Hobuste arv on veelgi kiiremini vähenenud. See on ka arusaadav, sest kaasaegses põllumajanduses ei kasutata enam hobuveojõudu. 1999. aastal oli hobuseid 3,9 tuhat, mis moodustas ennesõjaaegsest 1,9 protsenti.
Lindude arv on muutunud analoogselt sigade arvuga. Lindude arv kasvas kiiresti ja ületas 1980. aastal 6 miljoni piiri ja edaspidi oluliselt enam ei suurenenud. Sellel tasemel oli lindude arv kuni 1990. aastani. Suurim oli lindude arv 1989. a. – 6922,5 tuhat lindu, ületades ennesõjaeelset taset 4,3 korda. 1996. aastaks oli lindude arv vähenenud 2324,9 tuhande linnuni. Viimasel kahel aastal lindude arv on natuke tõusnud.
28.
Loomakasvatustoodangut iseloomustavad näitajad (toodangu mahu ja
intensiivsusnäitajad).
Põhinäitajate dünaamika.
Loomakasvatuse kogutoodang ja loomakasvatuse produktiivsus on kõige tähtsamad
loomakasvatust iseloomustavad statistilised näitajad. Loomakasvatuse
kogutoodangu statistilise arvestuse korral võib eristada kolme
erinevat kogutoodangu
arvestuse viisi:
Kogutoodang naturaalsetes ühikutes (tonnides, tükkides jne);
Kogutoodang rahalises vääringus;
Kogutoodang nn valgu – rasvaühikutes.
Vaatleme
neid näitajaid lähemalt ja selgitame, mis on nende näitajate
majanduslik sisu.
Kogutoodang
naturaalsetes ühikutes
(tonnides, tükkides jne) on kõige põhilisem loomakasvatuse
kogutoodangut iseloomustav näitaja. Nimetatud näitaja kasutamise
korral iga loomakasvatustoodangu liigi kohta saadakse erinevad
näitajad vastavates mõõtühikutes. Kogutoodang naturaalsetes
ühikutes võimaldab hinnata vastava toodanguliigi kasutamise
võimalusi (kui palju saame tarbida, müüa või kui palju on vaja
antud toodangu liiki vajaduse korral juurde osta jne). Antud näitaja
puuduseks on asjaolu, et erinevate (paljude) loomakasvatusharude
viljelemise korral iseloomustab loomakasvatuse kogutoodangut suur
hulk erinevaid näitajaid. See raskendab ülevaate saamist ettevõtte
(riigi) loomakasvatuse kogutoodangust. Eriti tülikas on erinevate
ettevõtete (riikide) loomakasvatuse kogutoodangu võrdlemine.
Kogutoodang
rahalises vääringus
võimaldab ühe ainsa arvuga iseloomustada kogu loomakasvatuse
kogutoodangut. Seda näitajat on mugav kasutada, kui on vaja võrrelda
erinevate ettevõtete (riikide) loomakasvatuse kogutoodangut, kuna
vajalike järelduste tegemiseks on vaja võrrelda ainult kahte arvu.
Antud näitaja puuduseks on asjaolu, et jääb avamata (selgitamata)
milliseid loomakasvatuse toodanguliike kogutoodang sisaldab ja
milline on loomakasvatustoodangu struktuur.
Kogutoodang
nn valgu – rasvaühikutes
on teiseks võimaluseks (rahalise vääringu kasutamise kõrval)
iseloomustada loomakasvatuse kogutoodangut ühe arvnäitajaga. Valgu
– rasvaühiku kasutamise idee autoriks oli prof . Leida Lepajõe.
Nimetatud näitaja kasutamise korral teisendatakse kogu toiduks tarbitav loomakasvatustoodang valgu – rasvaühikutele. Iga
konkreetne tooteliik sisaldab teatava koguse valku ja rasva. Need kogused summeeritakse ja saadakse kogutoodang nn valgu –
rasvaühikutes. Antud näitaja kasutamine kerkis päevakorrale
nõukogude perioodil, kui tookordsed hinnad ei peegeldanud
loomakasvatustoodangu tegelikku väärtust (kogutoodang rahalises
vääringus ei iseloomustanud loomakasvatustoodangu tegelikku
väärtust). Olgu märgitud, et ka käesoleval ajal on
põllumajandustoodangu hinnad Euroopa Liidus rakendatud doteerimiste
tõttu moonutatud. Seetõttu valgu – rasvaühiku kasutamine võib
anda objektiivsema pildi loomakasvatuse kogutoodangust.
Loomakasvatuse
produktiivsust iseloomustavaks näitajaks on loomakasvatustoodang ühe
looma kohta. Peamisteks produktiivsuse näitajateks on: piimatoodang
lehma kohta aastas, munatoodang kana kohta aastas ja villatoodang ühe
lamba kohta aastas.
Dünaamika:
Liha kogutoodang (tapakaalus) sõltub eelkõige realiseeritud loomade arvust. Liha kogutoodangust moodustab põhilise osa sealiha . Seetõttu liha kogutoodangu dünaamikas jälgitavad tendentsid on analoogsed sigade arvu dünaamikas valitsevate muutustega . Juba 1960. a. ületas liha kogutoodang ennesõjaaegse taseme. 1983. a. ületas liha kogutoodang 200 tuhande tonni piiri ja edaspidi oluliselt enam ei suurenenud. Üle 200 tuhande tonni oli liha kogutoodang kuni 1990. aastani. Suurim oli liha kogutoodang 1989. a. – 228,9 tuhat tonni, ületades ennesõjaeelset taset 3,2 korda. Aastatel 1996 … 1999 liha kogutoodang stabiliseerus 60 tuhande tonni tasemel, kuid oli väiksem kui enne sõda, moodustades rekordaastast ainult 26% ning sõjaeelsest tasemest 83,2%. Seejuures olgu märgitud, et enne sõda oli elanikke (liha sööjaid) Eestis 1 miljon 54 tuhat ja nüüd 1 miljon 453 tuhat.
Veiseliha kogutoodang sõltub eelkõige veiste arvust. Koos veiste arvu suurenemisega on suurenenud ka veiseliha kogutoodang. 1980. a. ületas veiseliha kogutoodang 70 tuhande tonni piiri ja edaspidi oluliselt enam ei suurenenud. Üle 70 tuhande tonni oli veiseliha kogutoodang kuni 1990. aastani. Suurim oli veiseliha kogutoodang 1990. a. – 79,9 tuhat tonni, ületades ennesõjaeelset taset 3,6 korda. Aastatel 1997 … 1999 liha kogutoodang stabiliseerus 19 tuhande tonni tasemel, kuid oli väiksem kui enne sõda, moodustades rekordaastast ainult 24% ning sõjaeelsest tasemest 84,42%.
Sealiha kogutoodang moodustab liha kogutoodangust ligikaudu poole. 1979. a. ületas sealiha kogutoodang 100 tuhande tonni piiri ja suurenes tasapisi 1980. -ndate aastate lõpuks kuni 125 tuhande tonnini . Üle 100 tuhande tonni oli sealiha kogutoodang kuni 1990. aastani. Suurim oli sealiha kogutoodang 1987. a. – 127,2 tuhat tonni, ületades ennesõjaeelset taset 3,1 korda. Aastatel 1996 … 1998 sealiha kogutoodang stabiliseerus 30 tuhande tonni tasemel, kuid oli väiksem kui enne sõda, moodustades rekordaastast ainult 24% ning sõjaeelsest tasemest 72,6%.
Lambaliha toodeti enne sõda küllaltki palju. Lambaliha osakaal moodustades 9% liha kogutoodangust. Seoses lammaste arvu pideva vähenemisega on vähenenud ka lambaliha kogutoodang. Aastatel 1996 … 1999 lambaliha kogutoodang stabiliseerus 0,5 tuhande tonni tasemel, moodustades selle perioodi liha kogutoodangust 0,8% ja sõjaeelsest tasemest ainult 7,7%.
Linnuliha kogutoodang saavutas sõjaeelse taseme alles 1960. aastal. Veiseliha ja sealiha tootmisel oli selleks ajaks sõjaeelne tase juba 1,5 kordselt ületatud. Linnuliha tootmine sai hoo sisse linnukasvatuse spetsialiseerumisega (linnuvabrikute rajamisega). Olgu märgitud, et linnukasvatus oli nõukogude perioodi lõpupoole kõige enam spetsialiseeritud loomakasvatusharu . 1985. a. ületas linnuliha kogutoodang 20 tuhande tonni piiri ning suurenes 1989. aastaks 25,4 tuhande tonnini. See oli ka linnuliha kogutoodangu maksimaalne tase, ületades ennesõjaeelset 14,1 korda. Aastatel 1996 … 1997 linnuliha kogutoodang stabiliseerus 4,4 tuhande tonni tasemel, moodustades rekordaastast ainult 17,3% ning ületades sõjaeelsest taset 2,4 korda. Kahel viimasel aastal on linnuliha toodang suurenenud. Linnuliha on ainus lihaliik, mille kogutoodang käesoleval ajal ületab sõja eelset taset.
Piima kogutoodang oleneb otseselt lehmade arvust ja produktiivsusest. Juba 1960. a. ületas piima kogutoodang ennesõjaaegse taseme. 1970. a. ületas piima kogutoodang 1000 tuhande tonni piiri ja suurenes 1985. aastaks 1250 tuhane tonnini ning edaspidi oluliselt enam ei suurenenud. Üle 1200 tuhande tonni oli piima kogutoodang kuni 1990. aastani. Suurim oli piima kogutoodang 1987. a. – 1290,2 tuhat tonni, ületades ennesõjaeelset taset 1,65 korda. Aastatel 1995 … 1998 piima kogutoodang stabiliseerus 700 tuhande tonni tasemel, kuid oli väiksem kui enne sõda, moodustades rekordaastast ainult 53,4% ning sõjaeelsest tasemest 90%. Seejuures olgu märgitud, et enne sõda oli elanikke (piima joojaid) Eestis 1 miljon 54 tuhat ja nüüd 1 miljon 453 tuhat.
Munade kogutoodang sõltub eelkõige kanade arvust ja produktiivsusest. Juba 1960. a. ületas munade kogutoodang ennesõjaaegse taseme 1,8 korda. 1980. a. ületas munade kogutoodang 500 miljoni muna piiri ja suurenes 1989. aastaks 600 miljoni munani ning edaspidi enam ei suurenenud. Üle 550 miljoni muna oli munade kogutoodang kuni 1991. aastani. Suurim oli munade kogutoodang 1989. a. – 600,1 miljonit muna, ületades ennesõjaeelset taset 4,5 korda. Aastatel 1995 … 1999 munade kogutoodang stabiliseerus 300 miljoni muna tasemel, moodustades rekordaastast 50% ning ületades sõjaeelsest taset 2,2 korda.
Villa kogutoodang sõltub eelkõige lammaste arvust. Kuna lammaste arv pidevalt vähenes, siis pidevalt on vähenenud ka villa kogutoodang. 1998. aastal villa kogutoodang moodustas sõjaeelsest ainult 9,7%.
Piima produktiivsus (piimatoodang lehma kohta aastas) on Eesti loomakasvatuse produktiivsust iseloomustavatest näitajatest kõige olulisem. Juba 1960. a. ületas piima produktiivsus ennesõjaaegse taseme 1,4 korda. 1985. a. ületas piima produktiivsus olulise rajajoone 4000 kg lehma kohta aastas ja suurenes 1989. aastaks 4217 kg lehma kohta aastas ning edaspidi enam ei suurenenud. Üle 4000 kg lehma kohta aastas oli piima produktiivsus kuni 1991. aastani. Edasi piima produktiivsus langes saavutades miinimumi 1993. aastal (3322 kg lehma kohta aastas) ja seejärel hakkas uuesti tõusma, saavutades kõigi aegade rekordtaseme 1998. aastal – 4456 kg lehma kohta aastas.
Munatoodang ühe kana kohta aastas (munatootmise produktiivsus) on üks stabiilsemaid näitajaid kõigi eelpool käsitletud näitajate hulgas. Antud näitaja saavutas küllaltki arvestatava taseme juba 1970. aastal – 241 muna ühe kana kohta aastas. Praktiliselt samal tasemel oli munatoodang ühe kana kohta aastas kuni 1991. aastani, seejärel nimetatud näitaja natuke langes ja alates 1994. aastast hakkas uuesti tõusma saavutades 1998. aastaks kõigi aegade kõige suurema munatoodang ühe kana kohta aastas - 298 muna kana kohta aastas.
Kokkuvõtvalt võib märkida, et loomakasvatuse kogutoodangu näitajad välja arvatud linnuliha ja munade kogutoodang on käesolevaks ajaks langenud madalamale tasemele kui vastavad näitajad olid enne sõda. 1990. –ndate aastate lõpu loomakasvatuse kogutoodangu näitajad moodustavad 1980. –ndate aastate lõpu tasemest liha kogutoodangu korral keskmiselt 25% ja piima korral 50%. Parem on olukord produktiivsusnäitajate (intensiivsusnäitajate) osas. Siin on kõrgeimad näitajad just analüüsitava perioodi viimasel aastal.
29.
Ökonomeetrilised mudelid põllumajanduses: piimasektori, lihasektori
ja taimekasvatussektori mudelite olemus.
LIHASEKTOR
Antud
mudel on dünaamiline osalise tasakaalu mudel, mille ülesehitus on
analoogiline tuntud FAPRI1 EU GOLD mudelile. Mudeli dünaamilisus
tähendab, et selle abil on
võimalik koostada prognoose tulevaste perioodide kohta. Mudeli
osaline tasakaalustatus tähendab
seda, et liha pakkumine ning nõudlus (ehk tootmine ja tarbimine) on
mudelis tasakaalus, kuid nende modelleerimisel on kasutatud ka nn
mudeliväliseid näitajaid.
Liha
tootmismahu modelleerimise aluseks on tapetud loomade arv ning
tapakaal. Nende kahe teguri korrutamisel saadakse liha kogutoodangu
näitajad. Peamised tegurid, millega liha tootmismahu võrrandites
arvestatakse on vastavad trendinäitajad, liha hinnad, sisendite
hinnaindeks ning järglaste saamine. Mudeli tarbimise pool koosneb
neljast alaosast: sisetarbimine, eksport , import ning aastalõpu
varu. Ka nende näitajate modelleerimisel on olulised trendinäitajad
ning liha hinnad. Samuti on tarbimist kirjeldavates võrrandites
olulisel kohal SKP ühe elaniku kohta ning SKP deflaator2, kuna
üldine majanduslik heaolu mõjutab liha tarbimist.
PIIMANDUSSEKTOR
EMÜ
majandus- ja sotsiaalinstituudis välja töötatud Eesti
piimandussektori mudel. Mudeli koostamise aluseks on FAPRI EU GOLD
mudel, mis on oma olemuselt dünaamiline, osaliselt tasakaalustatud
globaalne mudel:
mudeli
dünaamilisus
võimaldab
mõjurite (endogeensete ja eksogeensete muutujate) kirjeldamist ajas
ning prognooside tegemist tuleviku kohta;
osaline
tasakaalustatus tähendab
seda, et olulised makromajanduslikud näitajad nagu oluliste
piimatoodete (või, juust, lõssipulber ja piimapulber) hinnad,
elanike arv (sisetarbijad), SKP ühe elaniku kohta, SKP kasvuindeks,
tarbijahinnaindeks jne määratakse kindlaks mudeliväliselt;
mudeli
globaalsus
tähendab
seda, et nii endogeensed kui eksogeensed muutujad on oma olemuselt
makromajanduslikud, st iseloomustavad kogu Eesti
põllumajandussektorit ning majandust kui tervikut.
Piimandussektori
mudeli üheks iseärasuseks on asjaolu, et mudelis käsitletakse
eraldi kolme põhikomponenti: toorpiima, piimavalku ja piimarasva.
Põhiliste toodete (juust, või, lõssipulber, piimapulber jm tooted)
tootmise, tarbimise, impordi, ekspordi, varude jm võrrandite
modelleerimise aluseks on kasutada olev piimavalk ja piimarasv.
TAIMEKASVATUSSEKTOR
Nagu
ka Eesti piimanduse makroökonomeetriline mudel, on Eesti
teraviljasektori mudel oma olemuselt dünaamiline, osaliselt
tasakaalustatud globaalne mudel:
Mudeli
dünaamilisus
võimaldab
mõjurite (endogeensete ja eksogeensete muutujate) kirjeldamist ajas
ning prognooside tegemist tuleviku kohta.
Osaline
tasakaalustatus tähendab
seda, et olulised makromajanduslikud näitajad nagu
teraviljakultuuride hinnad, elanike arv (sisetarbijad), SKP ühe
elaniku kohta, SKP kasvuindeks, tarbijahinnaindeks jt on eksogeensed,
st määratakse kindlaks mudeliväliselt.
Mudeli
globaalsus
tähendab
seda, et nii endogeensed kui eksogeensed muutujad on oma olemuselt
makromajanduslikud, st iseloomustavad Eesti põllumajandussektorit
kui tervikut.
Teraviljasektori
mudelis on vaatluse all neli peamist teraviljakultuuri – oder,
nisu, kaer ja rukis. Kõikide kultuuride tootmist, tarbimist,
importi, eksporti ning varude muutumist modelleeritakse erinevate
võrrandite abil. Mudelis on 52 endogeenset (modelleeritavat)
muutujat ja 41 eksogeenset (mudelivälist) muutujat.
1. Ökonomeetria mõiste ja ülesanded. Ökonomeetria komponendid. 2. Ökonomeetrilise mudeli olemus, mudeli komponendid. Ökonomeetrilise modelleerimise etapid. 3. Lihtne regressioon, regressioonivõrrandi põhikuju. Determineeritud regressioonivõrrand. 4. Stohhastiline regressioonivõrrand. Juhuslik komponent (regressioonijääk). Visualiseerimine (joonis). 5. Vähimruutude meetod, olemus, visualiseerimine. 6. Vähimruutude meetodil leitud parameetrite hinnangute omadused. 7. Statistilise seose tugevus: determinatsioonikordaja (hajuvuse (RSS, TSS, ESS) mõõtmine (joonised)), korrelatsioonikordaja, jääkstandardhälve, kovariatsioon, (eespool toodudnäitajate olemus, selgitus joonise abil). Kordajate omavahelised seosed. 8. Lihtsa regressioonimudeli a. headuse hindamine; b. usaldatavuse kontrollimine; c. mudeli parameetrite statistilise olulisuse kontrollimine; usalduspiiride leidmine; d. eespool toodud näitajate leidmine ja seoste analüüs Exceli regressioonanalüüsi tabeli põhjal. 9. Mitmene regressioon. Klassikalise regressioonanalüüsi põhieeldused. Gauss-Markovi teoreemi olemus. Parim hinnang. Nihutamata hinnang. Efektiivne hinnang. 10. Multikollineaarsuse olemus. Multikollineaarsuse avastamine. Tolerants (TOL), varieeruvusindeks (VIF). Multikollineaarsuse tagajärjed.11. Multikollineaarsuse mõju regressioonanalüüsi tulemustele (labortöö). 12. Oluliste argumentide varieeruvuse mõju regressioonanalüüsi tulemustele (labortöö). 13. Fiktiivsete muutujatega regressioonimudel, tõlgendus.14. Heteroskedastiivsuse olemus; põhjused; tagajärjed; avastamise meetodid. 15. Mitmese regressioonimudeli konstrueerimise põhimõtted. 16. Andmed ökonomeetrilistes mudelites. Põllumajanduslike ökonomeetriliste mudelite koostamine. Muutujate valik põllumajanduslike ökonomeetriliste mudelite koostamisel17. Erineva kujuga regressioonimudelid: muutujate suhtes lineaarne, astmefunktsioon, eksponentfunktsioon, logaritmfunktsioon, hüperbool, parabool, logaritmfunktsioon, polünoom. Mudelite võrrandid, joonised, elastsuskoefitsient, lineariseerimine, parameetrite tõlgendused, võrrandite nimetused (poollogaritmiline, log-lin jt), erinevate regressioonimudelite võrdlemine. 18. Astmefunktsiooni (Cobb–Douglase tootmisfunktsiooni) parameetrite leidmine (labortöö). 19. Isokvandid. Nende kasutamine (labortöö). 20. Mittestandardne ökonomeetrilise mudeli parameetrite hindamise meetod: peamiste komponentide meetod (olemus; kasutamise võimalused) (labortöö).21. Ökonomeetrilise mudeli analüüs statistiliste näitajate (F, t –kriteeriumi baasil). 22. Ökonomeetrilise mudeli majanduslik (sisuline analüüs): regressioonikordajate mõõtühikud; regressioonikordajate majanduslik sisu; regressioonikordajate märkide vastavus majandusteooria seisukohtadele. 23. Statistilise näitaja olemus. Põllumajandusstatistika näitajate süsteem. 24. Maastatistika. Maade kasutamist iseloomustavad näitajad. Maafondi dünaamika. 25. Taimekasvatuse statistika. Kasvupindade statistika. Kasvupindade dünaamika. 26. Kogusaaki ja saagikust iseloomustavad näitajad. Põhinäitajate dünaamika.27. Loomakasvatuse statistika. Loomade arvu iseloomustavad näitajad. Loomade arvu dünaamika. 28. Loomakasvatustoodangut iseloomustavad näitajad (toodangu mahu ja intensiivsusnäitajad). Põhinäitajate dünaamika. 29. Ökonomeetrilised mudelid põllumajanduses: piimasektori, lihasektori ja taimekasvatussektori mudelite olemus.
Sarnased õppematerjalid
![Ökonomeetria eksam]()
18
doc
Ökonomeetria eksam
majandusüksuste(ettevõtete, talude, maakondade jne.) majandustegevust
iseloomustavatest näitajatest. Kõik vaatlustulemused iseloomustavad ühte ja sama
ajahetke või ajavahemikku.Aegread,mis iseloomustavad ühe ja sama majandusüksuse
tegevust teatud perioodi kestel. Aegrida moodustavad näitajad kujutavast endast
makromajanduslikke näitajaid( sisemajanduse koguprodukt, tarbijahinna indeks).
Enamik ökonomeetrias kasutatavaid arvandmeid on hangitud statistikaorganite
poolt, seega ökonomeetria vaatleb majandusprotsesse passiivselt.
Ökonomeetrilise analüüsi põhialuseks on majandusteooria järeldused antud
probleemi kohta.
Ökonomeetriliseks mudeliks nim-teoreetiliste seisukohtade kogumit, mida me
konkreetses analüüsis kasutame.Kokkuvõtvalt võib märkida järgmist:
a)Ökonomeetrilises analüüsis ja ökonomeetrilise mudeli koostamisel vundamendiks
on majandusteooria (majandusteooriast tulenevad järeldused, seisukohad)
![Ökonomeetria]()
14
doc
Ökonomeetria
Kõige olulisemaks neist on mudeli korrektsuse eeldus. Mudeli korrektsus sõltub ühelt poolt
analüüsi tegija majanduslikteoreetilisest ettevalmistusest ja teadmistest ning teiselt poolt
mudeli koostises vajalike arvandmete kättesaadavusest. Arvandmeid iseloomustab eelduste
(2-5) olulisemateks kõrvalekaldumisteks on: 1)multikollineaarsus (sõltumatud muutujad on
omavahelises sõltuvuses) 2)multikollineaarsese ja sõltumatute muutujate mitteküllaldase
varieeruvuse mõju ökonomeetria mudeli parameetrite hinnangule. Ökon. analüüsis
eeldatakse, et arvandmed on korrektsed. Arvandmete representatiivsus tähendab seda, et
vaatlustulemuste arv on küllaltki suur ja isel. modelleeritavat probleemi. reg.jääke
puudutavate eelduste korral: a) kui ei ole täidetud võimalus kasut. standardseid statistilisi
hüpoteese reg.võrrandi ja reg.kordajate kohta, siis selle põhjuseks on ebakorrektne mudel. b)
kui ei ole täidetud reg
![Gretl juhend 2016]()
32
pdf
Gretl juhend 2016
Gretl - Gnu Regression, Econometrics and Time Series
Library
Gretl on avatud koodil põhinev vabavara, mida võib legaalselt
installeerida oma kodusesse arvutisse või sülearvutisse.
Programmi koduleht
http://gretl.sourceforge.net/
TÖÖ PROGRAMMIGA Gretl
Käivitada programm – avaneb menüü
1. Andmete importimine – File → Open data → Import →
nimi.xlsx.
Selleks et oleks võimalik andmetabelit Gretl-isse importida tuleb tabel eelnevalt sobivale
kujule viia:
a) kontrollida, et Exceli tabeli esimeses reas oleksid muutujate nimed (ei peaks
sisaldama täpitähti) ning teisest reast alates andmed. sulgeda Exceli fail;
b) avada programm Gretl;
� c) valida File/Open data/Import/Excel
d) otsida Exceli fail (muuta Files of type)
e) valida, mitmendast veerust ja reast importimist alustatakse
f) näidatakse töölehtede , muutujate ja vaatlustulemuste arv
g)
![Ökonomeetria mõisted]()
5
doc
Ökonomeetria mõisted
Ökonomeetria mõisted
1. Autokorrelatsioon ja heteroskedastatiivsus võivad mudelis olla kahel põhjusel: 1) mudeli
spetsifikatsioon on vale. Mudelist on välja jäetud mõned olulised muutujad ja/või mudeli
funktsionaalne kuju on vale. Mudel tuleb ümber vaadata. 2) Tavalise vähimruutude meetodi
rakendamise protseduur võib anda standardhälvete nihkega hinnangud. Tuleb kasutada uusi
lähenemisi mudeli parameetrite hindamiseks. Autokorrelatsiooni testitakse aegridade puhul.
Kui juhuslikud vead korreleeruvad omavahel, siis on olemas autokorrelatsioon. Kui autok.
Esineb, tuleb mudel ümber vaadata, tuleb muuta spetsifikatsiooni.
2. Asümptootilised hinnangud kui juhuslike vigade normaaljaotuse eeldus ei ole täidetud, siis
usalduspiirid on asümptootilised. Nad on täpsed siis, kui valimi maht on lõpmatu; lõpliku valimi
mahu korral usalduspiirid on ligikaudsed.
![Ökonomeetriline projekt - Brutopalga sõltuvus haridustasemest-meeste osakaalust ning linlaste osakaalust maakondade lõikes]()
36
docx
Ökonomeetriline projekt - Brutopalga sõltuvus haridustasemest, meeste osakaalust ning linlaste osakaalust maakondade lõikes
TALLINNA TEHNIKAÜLIKOOL
Majandusteaduskond
Rahandus ja majandusteooria instituut
Matemaatika, statistika ja ökonomeetria õppetool
Laura Kallasvee, Liisi Saksakulm
BRUTOPALKADE SEOS HARIDUSE, SOO JA ELUKOHAGA
EESTI MAAKONDADE LÕIKES AASTATEL 2005-2008
Ökonoomeetriline projekt
Juhendaja: dotsent Ako Sauga
Tallinn 2014
�SISUKORD
SISSEJUHATUS.........................................................................................................................4
1
![KORDAMINE ÖKONOMEETRIA KONTROLLTÖÖKS]()
13
docx
KORDAMINE ÖKONOMEETRIA KONTROLLTÖÖKS
KORDAMINE ÖKONOMEETRIA KONTROLLTÖÖKS
2013 sügissemester kasutatud 2017. aasta sügissemestri KT õppimiseks
Teooria
1. Ökonomeetrilise mudeli komponendid.
Endogeensed (sõltuvad Y), eksogeensed (sõltumatud, X), hinnatavad parameetrid (beeta) ja
juhuslik komponent ehk vealiige (u)
2. Andmetüübid.
Kvalitatiivsed, kvantitatiivsed, ristandmed, aegread, paneelandmed
3. Valimvaatlused ja parameetri hinnangu mõiste.
Uuritav objekt on üldvalim, andmebaas on üldjuhul valim. Järledusi teeme üldkogumi kohta
ja selleks kasutame valimit. Valimi parameetrite põhjal leitakse üldkogumi parameetrite
hinnangud. Valim on juhuvalim, hinnang on juhuslik suurus. Suvaline valimi andmete põhjal
arvutatud funktsioon on statistik ning erinevad valimid annavad statistikutele erinevad
väärtused. Statistik on juhuslik suurus.
4. Punkthinnang, intervallhinnang.
Punkthinnang on statistik, mis annab paramee
![PIIMA TOOTMINE 2000 AASTAL]()
24
doc
PIIMA TOOTMINE 2000 AASTAL
EESTI PÕLLUMAJANDUSÜLIKOOL
Majandus- ja sotsiaalteaduskond
Informaatika instituut
PIIMA TOOTMINE 2000 AASTAL
Kursusetöö aines Ökonomeetria
Koostajad: Sille Kasvandik
Maris Lees
Juhendaja: J. Roots
� Tartu 2004
SISUKORD
PIIMA TOOTMINE 2000 AASTAL.....................................................1
SISUKORD...................................................................................................................2
SISSEJUHATUS.......................................................................................................... 2
1. ÜLDINE STATISTILINE ANALÜÜS....................................................................4
1.1. Sisuline valitud muutujate analüüs.................................................................... 4
1.2. Põhiliste
![Ökonomeetria kontrolltöö kordamisküsimused 2020]()
70
docx
Ökonomeetria kontrolltöö kordamisküsimused 2020
Ökonomeetria KT kordamisküsimused
1. Ökonomeetrilise mudeli komponendid.
● Modelleeritavad näitajad: endogeenselt (sisemiselt) määratud ehk sõltuvad
muutujad (Y). Väärtused määratakse mudeli siseselt
● Modelleeritavat nähtust mõjutavad näitajad: eksogeenselt (väliselt) määratud
ehk sõltumatud, seletavad muutujad (X). Väärtused määratakse mudeli väliselt.
● Statistiliste meetoditega hinnatavad mudeli parameetrid (b).
● Juhuslik komponent ehk vealiige (u).
2. Andmetüübid.
Ökonomeetriline mudel baseerub arvandmetel:
● Ristandmed (cross-sectional)
● Aegread (time series)
● Paneelandmed (panel data)
Andmed saavad olla kas
● Kvalitatiivsed (ei saa mõõta arvudega, nt haridustase)
● Kvantitatiivsed (mõõdetakse arvudega, nt vanus)
3. Valimvaatlused ja parameetri hinnangu mõiste.
● Uuritav objekt on üldkogum
● Andmebaas on üldjuhul valim
Järeldusi soovime teha üldkogumi kohta, selleks kasuta
Meedia
Kommentaarid (4)




















































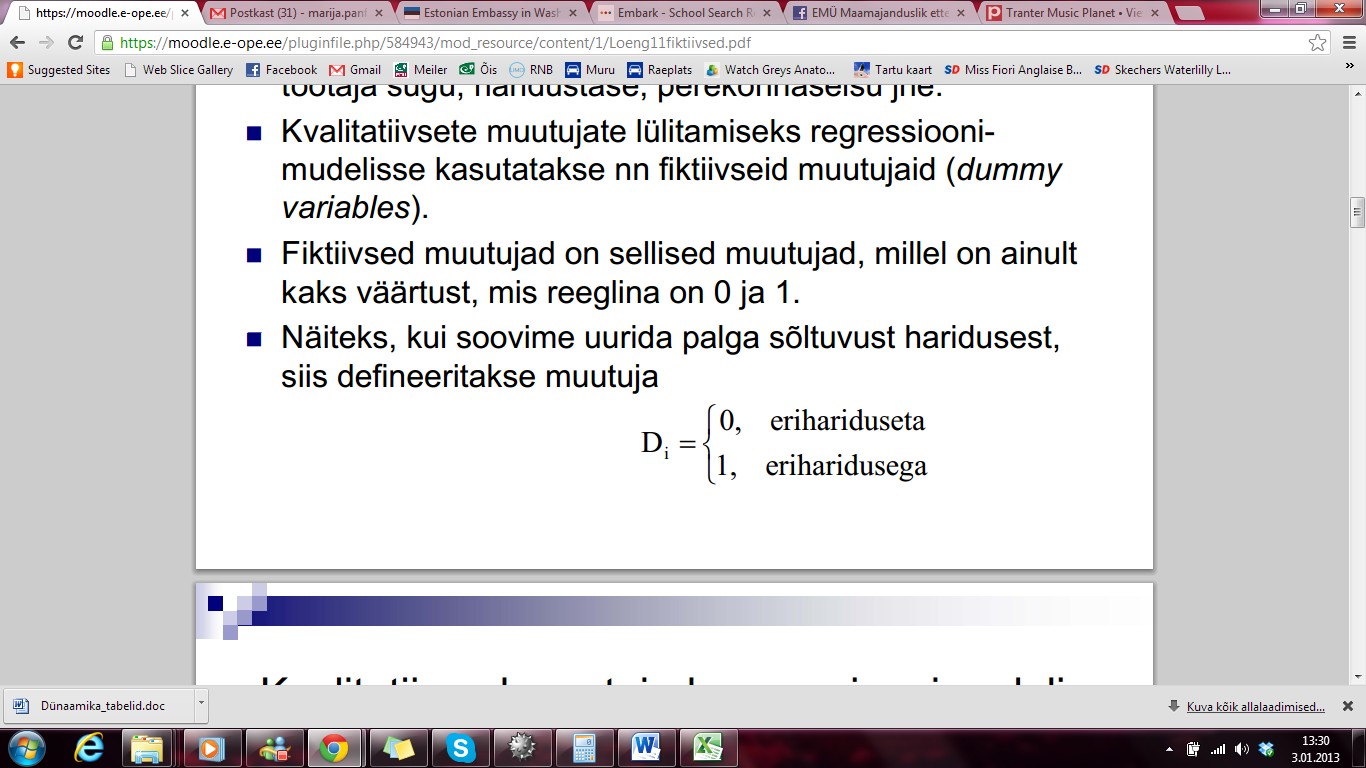

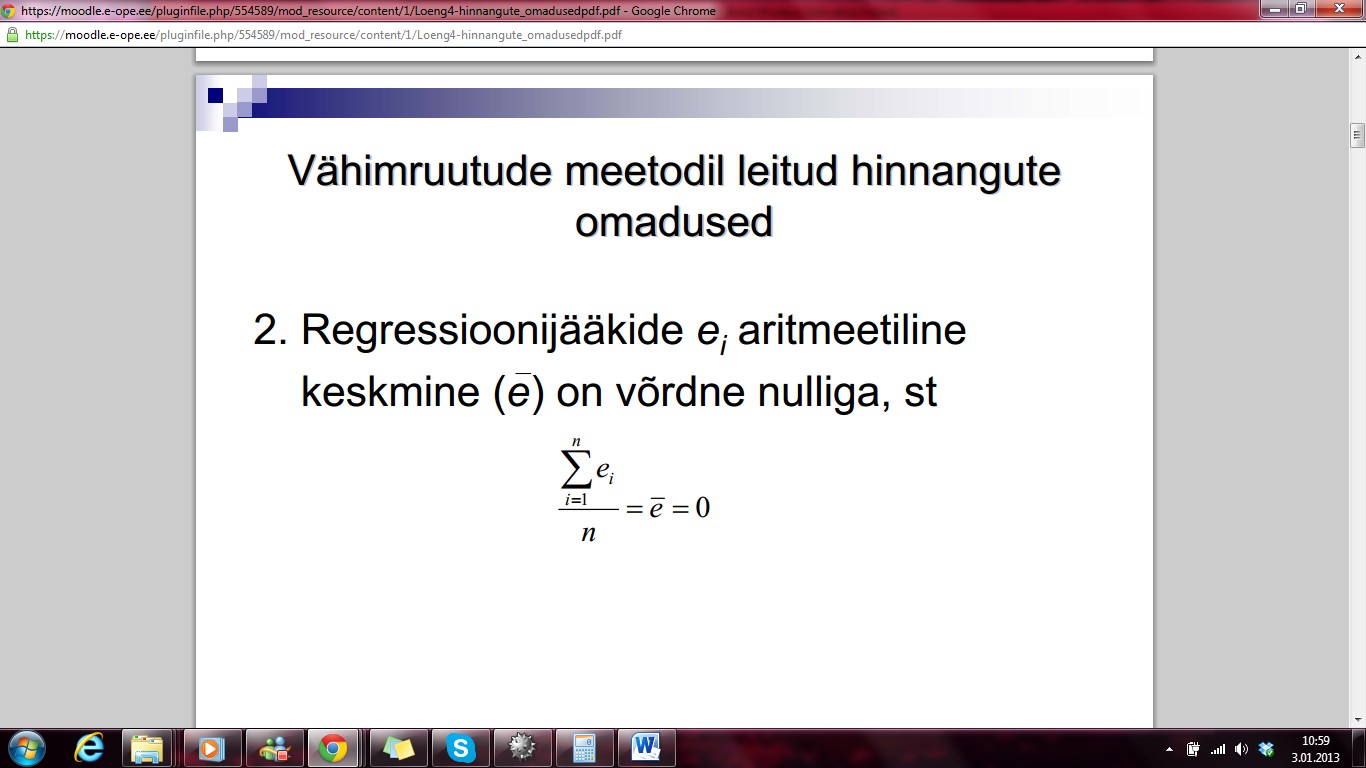
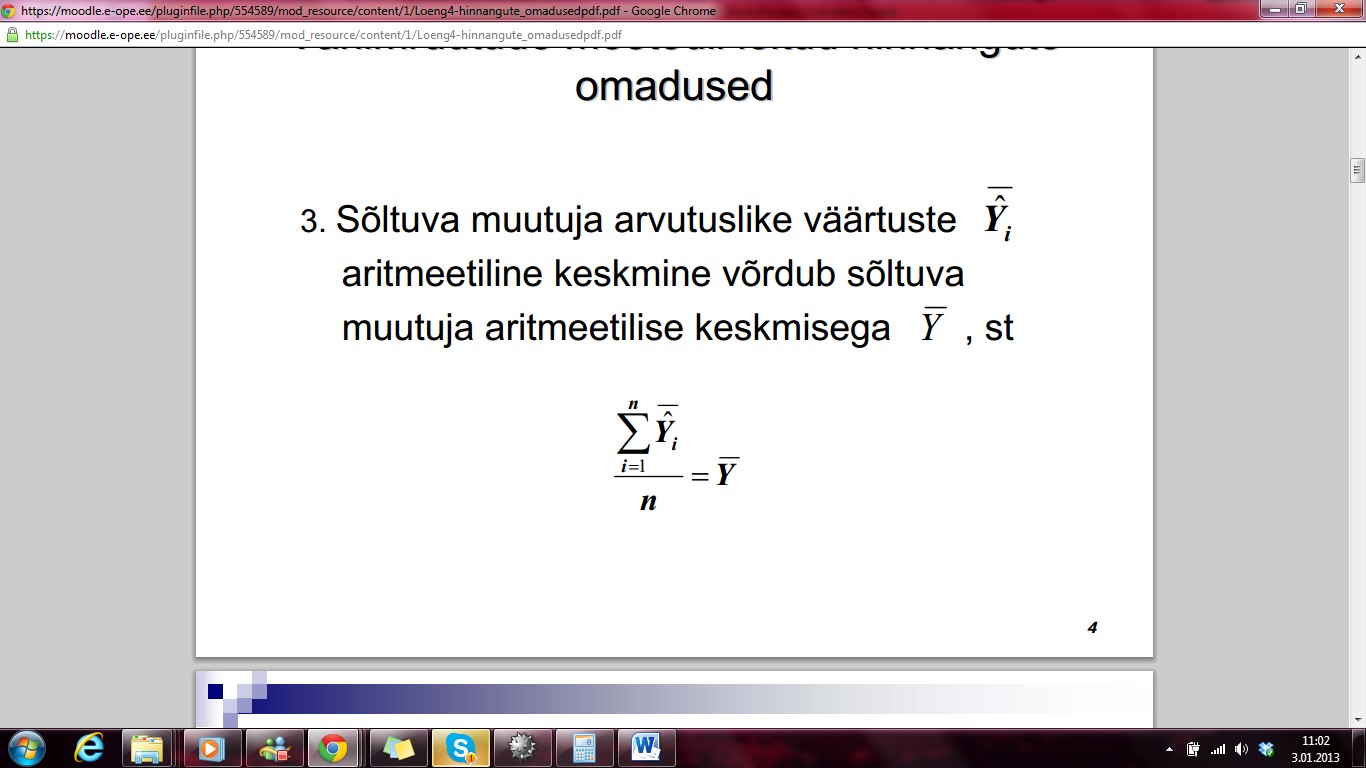
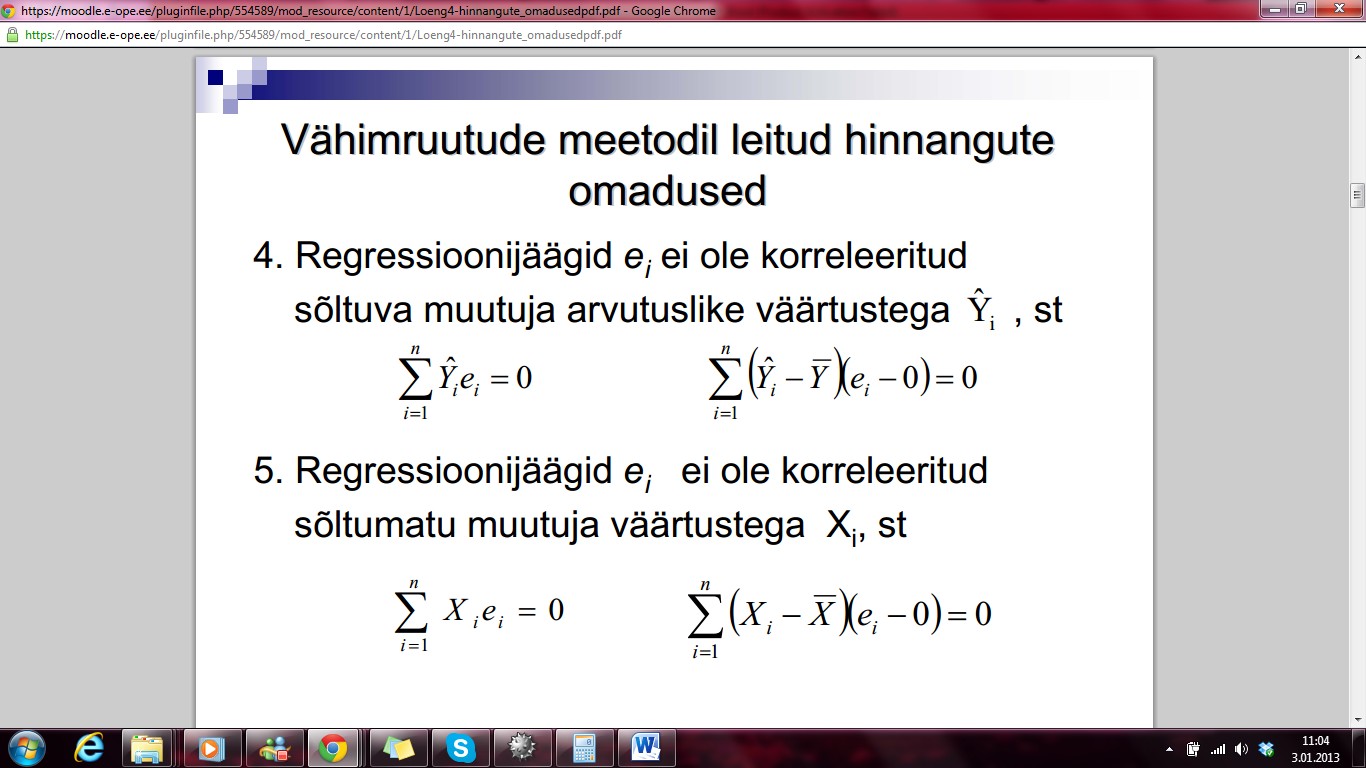
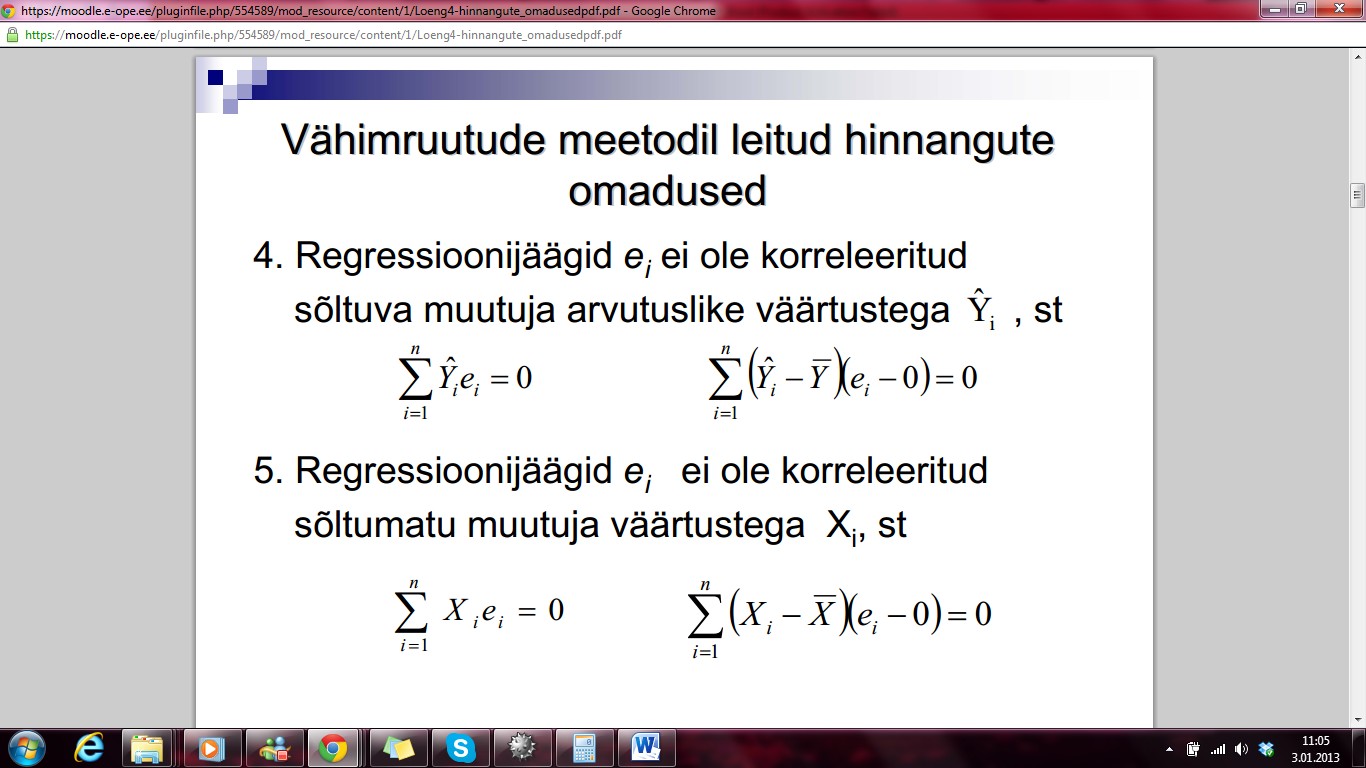
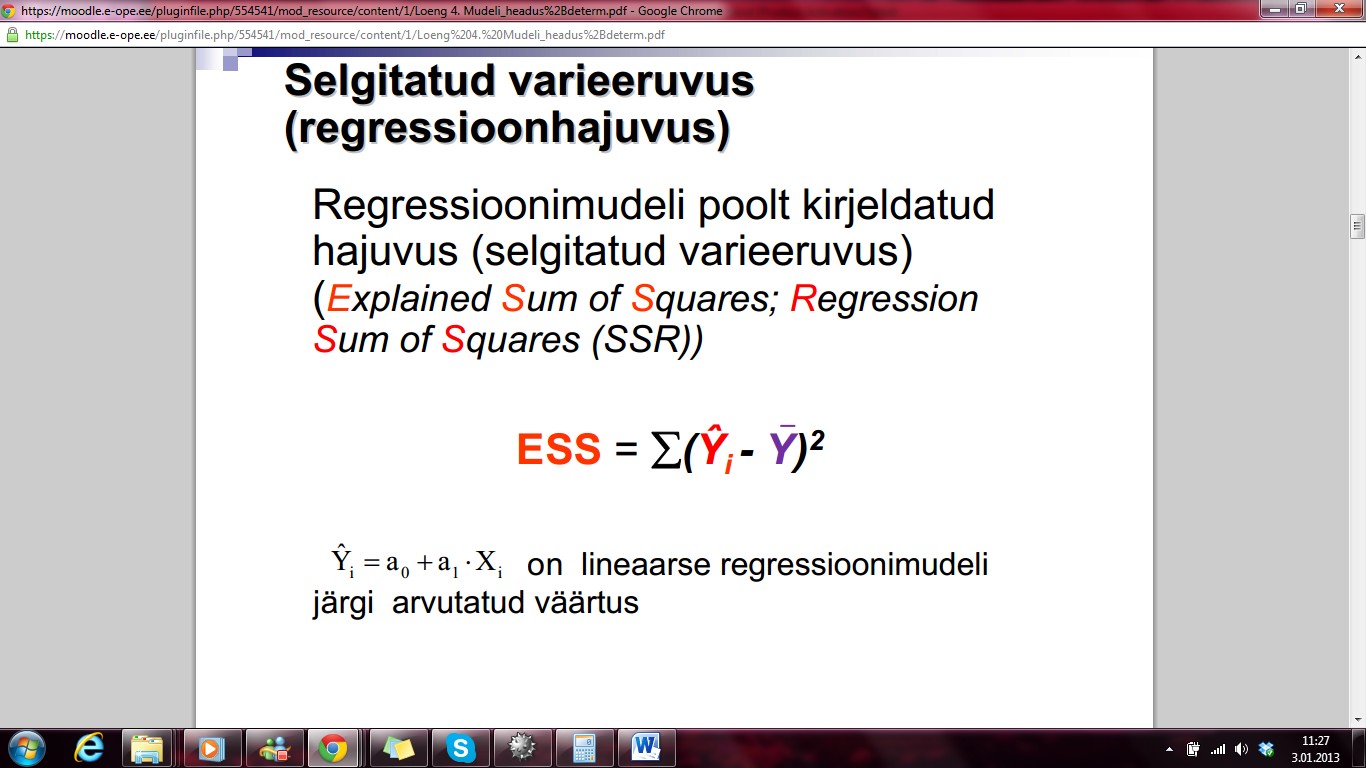
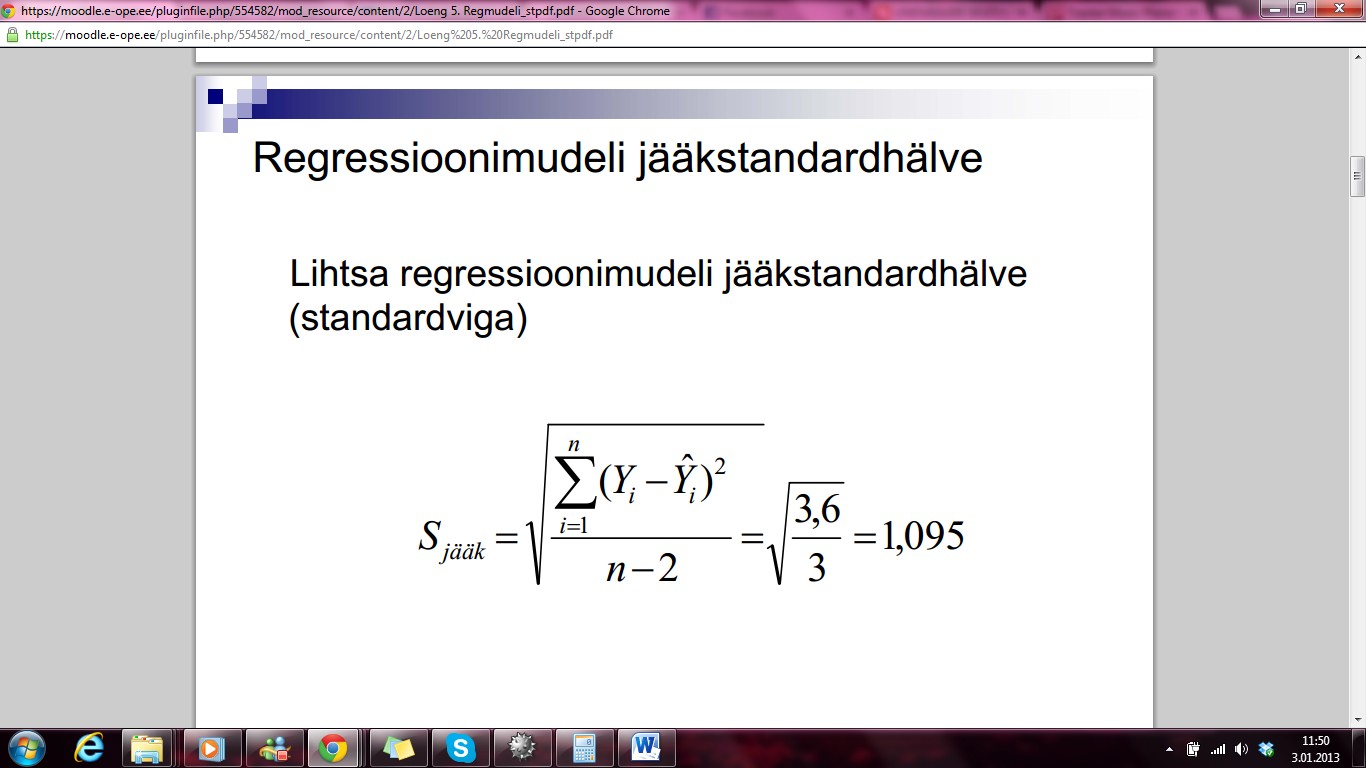
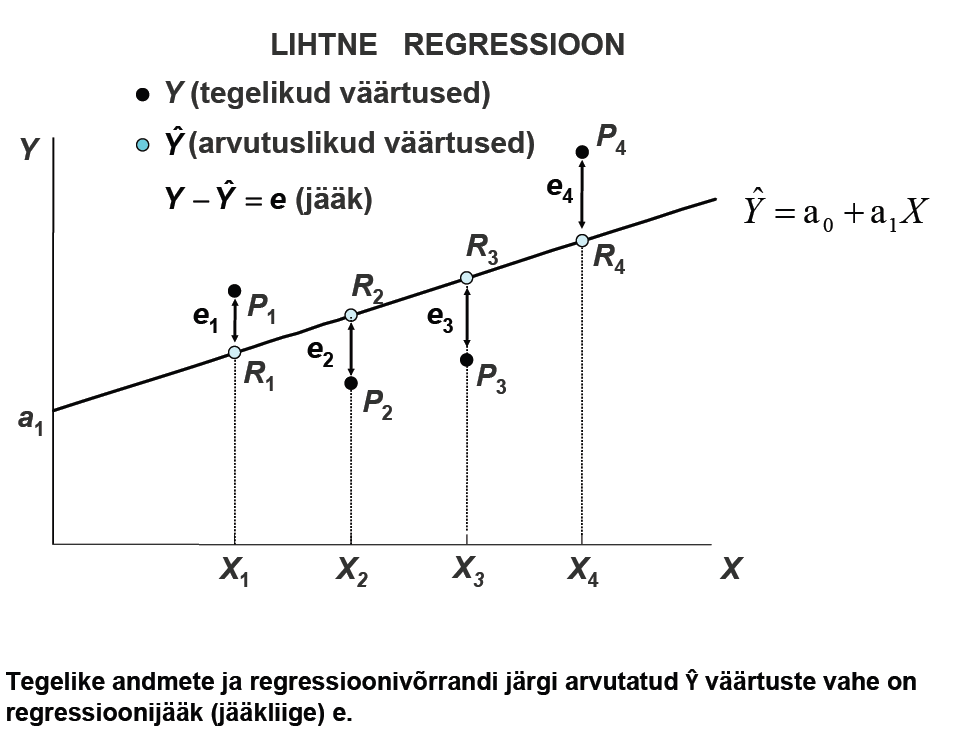




Kõik kommentaarid