Ökonomeetria KT kordamisküsimused
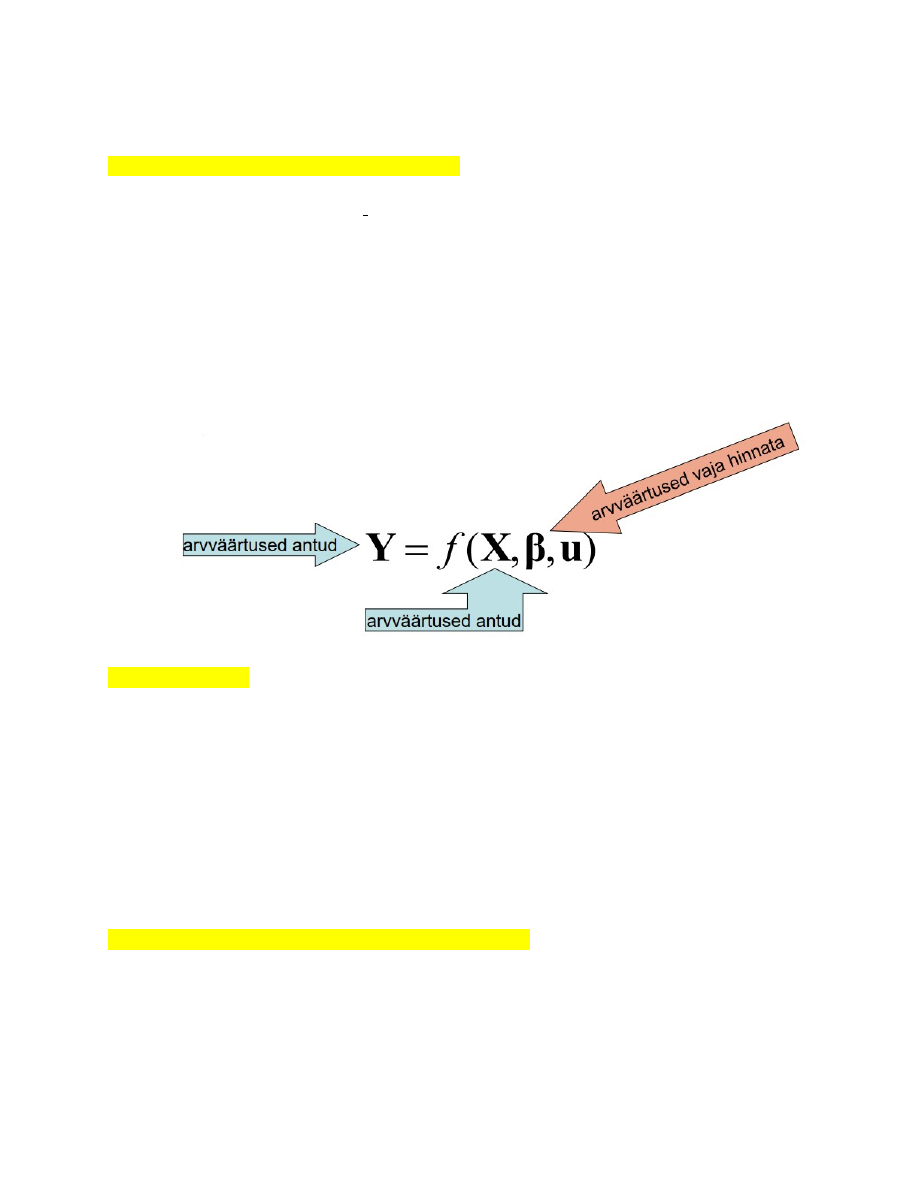
1. Ökonomeetrilise mudeli komponendid.
● Modelleeritavad näitajad:
endogeenselt (sisemiselt) määratud ehk
sõltuvad
muutujad (Y). Väärtused määratakse mudeli siseselt
● Modelleeritavat nähtust mõjutavad näitajad:
eksogeenselt (väliselt) määratud
ehk
sõltumatud, seletavad muutujad (X). Väärtused määratakse mudeli väliselt.
● Statistiliste meetoditega hinnatavad mudeli parameetrid (b).
● Juhuslik komponent ehk vealiige (u).
2. Andmetüübid.
Ökonomeetriline mudel baseerub arvandmetel:
● Ristandmed (cross-sectional)
● Aegread (time series)
● Paneelandmed (panel data)
Andmed saavad olla kas
● Kvalitatiivsed (ei saa mõõta arvudega, nt haridustase)
● Kvantitatiivsed (mõõdetakse arvudega, nt vanus)
3. Valimvaatlused ja parameetri hinnangu mõiste.
● Uuritav objekt on üldkogum
● Andmebaas on üldjuhul valim
Järeldusi soovime teha üldkogumi kohta, selleks kasutame valimit.
Valimi parameetrite põhjal leitakse üldkogumi parameetrite hinnangud.
Valimi põhjal leiame mudeli parameetrite
hinnangud. Valim on juhuvalim =>
hinnang
on
juhuslik suurus.
4. Punkthinnang, intervallhinnang.
Punkthinnang (point estimate) on statistik, mis annab parameetrile ühese väärtuse.
Näiteks valimi aritmeetiline keskmine on punkthinnang kogumi keskväärtusele.
Intervallhinnang (interval estimate) on lõik, mis sisaldab parameetri tegelikku väärtust
mingi etteantud tõenäosusega. Ka usaldusvahemik (confidence interval)
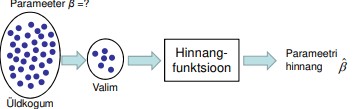
5. Hinnangfunktsioon.
Hinnangfunktsioon (estimator) on reegel üldkogumi parameetri(te) hinnangu(te)
leidmiseks.
● Ühe ja sama parameetri hindamiseks võib kasutada erinevaid
hinnangfunktsioone.
● Mõned sobivad paremini, mõned halvemini
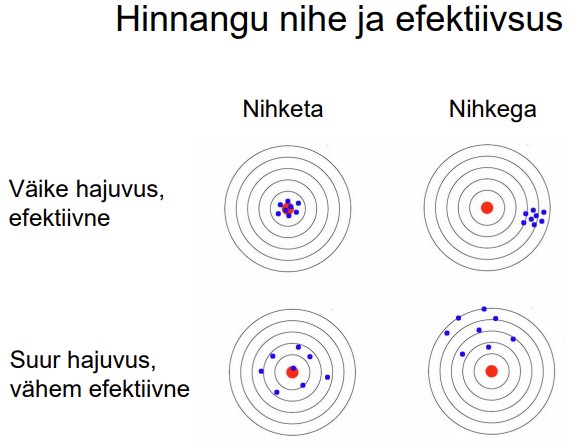
6. Hinnangute omadused.
1. Nihe (bias). Iseloomustab süstemaatilist viga.
2. Efektiivsus (efficiency). Iseloomustab hinnangute hajuvust.
3. Mõjusus (consistency). Iseloomustab koondumist suurte valimite korral – suure
valimi korral
4. Asümptootiline jaotus – suure valimi korral
5. Asümptootiline efektiivsus – suure valimi korral
7. Hinnangu nihe, nihketa hinnang. Hinnangu nihe võrdub parameetri hinnangu keskväärtuse ning parameetri tegeliku
väärtuse β vahega:
Parameetri
hinnang on nihketa (unbiased), kui hinnangu keskväärtus võrdub
parameetri tegeliku väärtusega:
● Kahest hinnangfunktsioonist on parem see, mis on nihketa.
● Nihketa hinnangfunktsioone võib olla mitmeid
nt sümmeetrilise jaotuse korral on üldkogumi mediaani nihketa
hinnanguteks valimi aritmeetiline keskmine ja valimi mediaan.
8. Hinnangu efektiivsus, efektiivne hinnang.
● Efektiivne hinnang on nihketa vähima dispersiooniga hinnang kõigi nihketa
hinnangute seas.
● Hinnangute dispersioone tasub võrrelda vaid nihketa hinnangute korral, kuna
hinnangu väike dispersioon ei ole eesmärk omaette.
9. Mõjus hinnang.
● Hinnang on mõjus (consistent), kui ta koondub tõenäosuse järgi parameetri
tegelikuks väärtuseks:
:
● Kui hinnang on mõjus, siis valimi mahu kasvades tõenäosus, et hinnangu ja
parameetri tegeliku väärtuse erinevus oleks väiksem kui mistahes positiivne arv,
läheneb ühele.
● Hinnangu mõjusus on asümptootiline omadus
●
Asümptootika: valimi maht n → ∞
(Wolfram) Uute valimite moodustamisel on näha, et väikese mahuga valimite korral võib
hinnang tegelikust väärtusest päris palju erineda. Valimi mahu suurenedes läheneb
hinnang tegelikule väärtusele. Järelikult on valimi keskmine kogumi keskväärtuse jaoks
mõjus hinnang.
10. Hinnangu asümptootiline jaotus.
● Asümptootiline jaotus näitab, millisele klassikalisele jaotusele läheneb hinnangu
valimjaotus valimi mahu kasvamisel.
● Hinnang on asümptootiliselt normaaljaotusega, kui hinnangu valimjaotus läheneb
valimi mahu kasvamisel normaaljaotusele
● Asümptootilist jaotust kasutatakse parameetrite usalduspiiride leidmisel,
testimisel. Sellest leitakse kriitilised väärtused, olulisuse tõenäosus
11. Hinnangu asümptootiline efektiivsus.
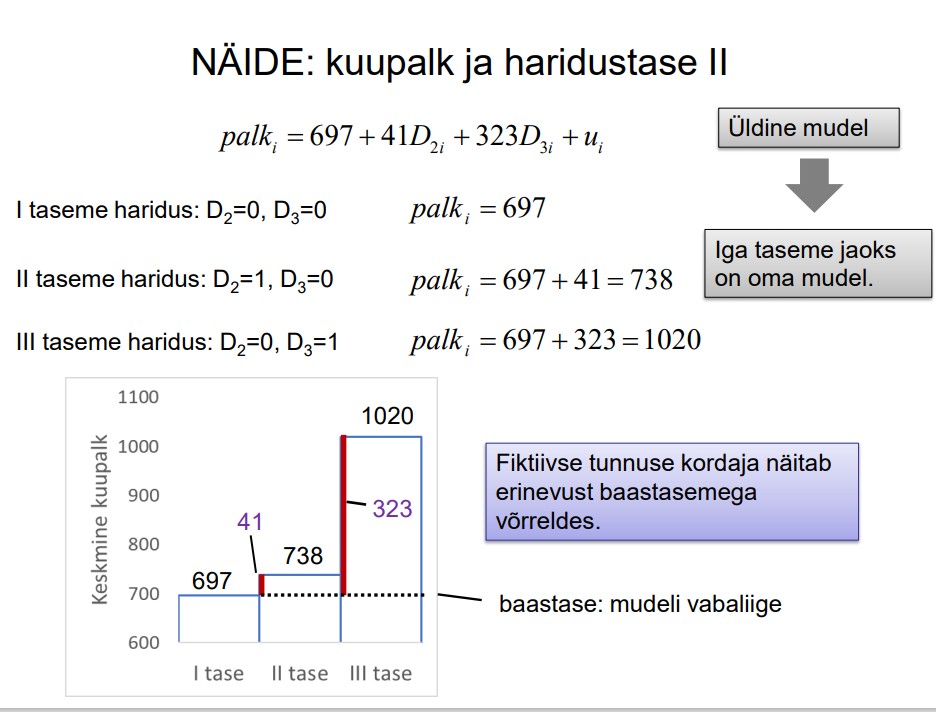
Mõjusat hinnangut nimetatakse asümptootiliselt efektiivseks (asymptotically efficient),
kui selle asümptootilise jaotuse dispersioon on väiksem suvalise mõjusa
asümptootiliselt normaaljaotusega hinnangu dispersioonist.
Näiteks mõningad suurima tõepära meetodil leitud hinnangud.
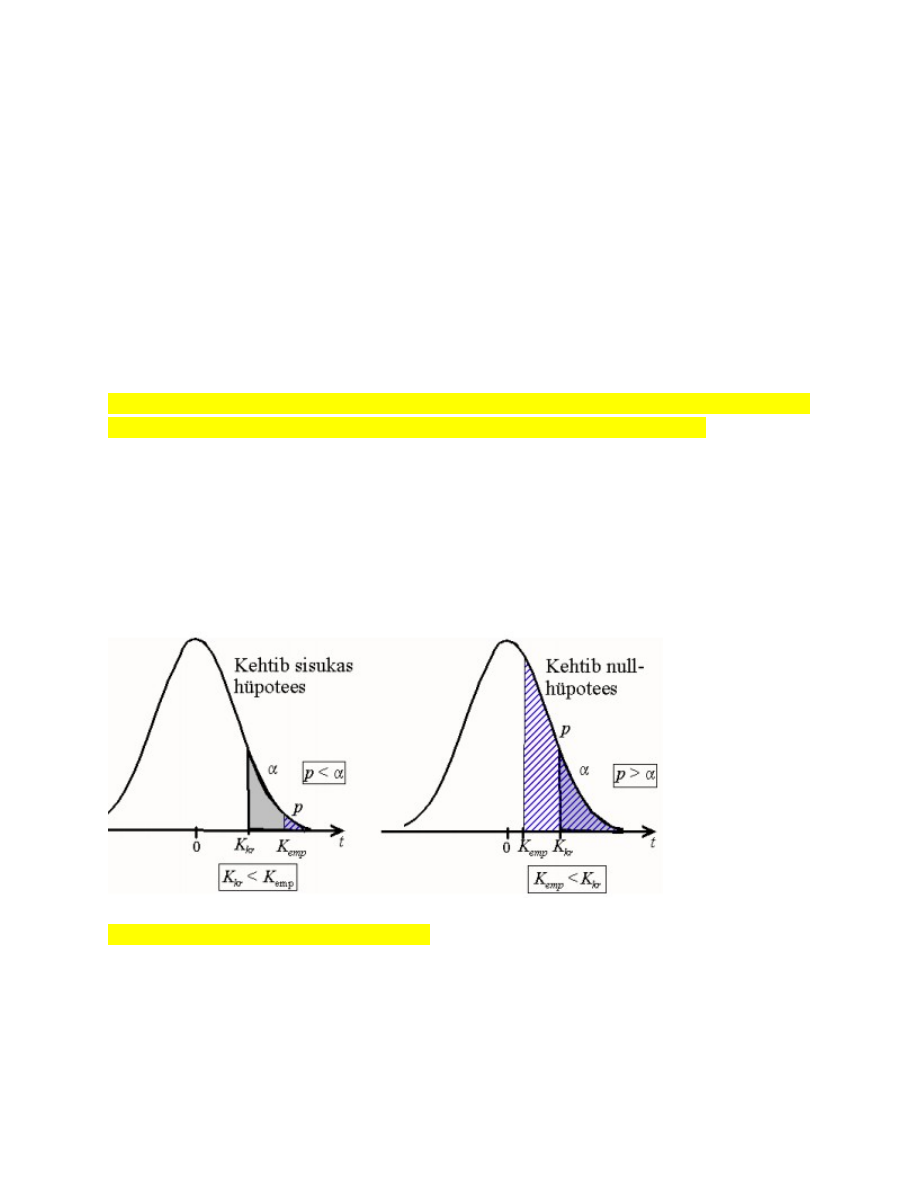
12. Hüpoteeside kontrollimine: otsuse vastuvõtmine, kui on antud teststatistiku
empiiriline ja kriitiline väärtus.
● Nullhüpotees: miski võrdub millegagi (erinevus on null)
– kogumi keskväärtus μ = μ0
– kogumi A keskväärtus = kogumi B keskväärtus
– mudeli parameeter β = 0
● Sisukas (alternatiivne) hüpotees: võrdus ei kehti
● Otsustamiseks kasutatakse juhuvalimit.
● Juhuvalimi keskväärtus on juhuslik suurus, st erineb arvust μ.
● Kuidas otsustada, kas
– kogumi keskväärtus μ = μ0
kehtib nullhüpotees;
– kogumi keskväärtus μ ≠ μ0
kehtib sisukas hüpotees?
● Ehk: kui palju võib juhuvalimi keskväärtus erineda nullhüpoteesiga püstitatud
väärtusest, et võime öelda: nullhüpotees ei kehti?
● Vaja
kriteeriumi!
Statistiline kriteerium ja teststatistik
● Otsustamiseks vajaliku statistilise kriteeriumi leidmiseks kasutatakse
teststatistikut.
● Valimi andmete põhjal arvutatakse teststatistiku
empiiriline väärtus
– sõltuvalt sellest, mida kontrollitakse, on konkreetsed arvutusvalemid erinevad
– z-test, t-test, F-test, χ 2 -test, ….
● Empiirilist väärtust võrreldakse vastava
kriitilise väärtusega ja võetakse vastu
otsus.
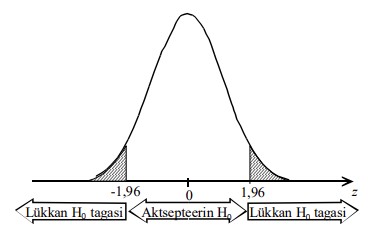
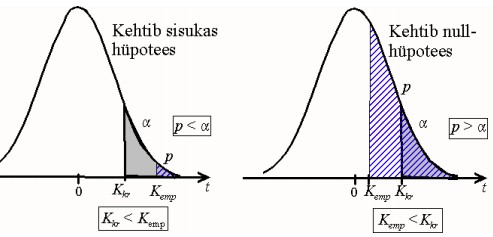
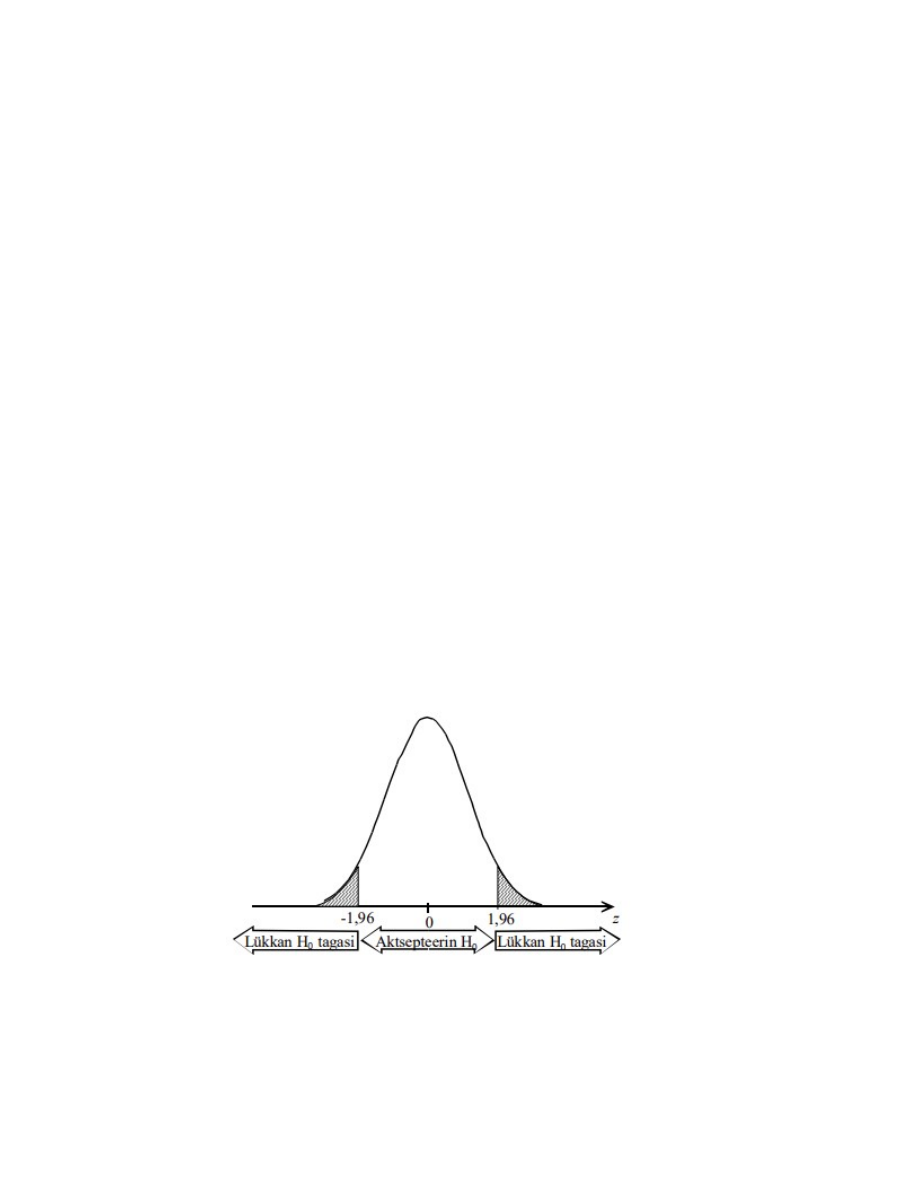
Kriitilised väärtused
● Nullhüpotees lükatakse tagasi, kui valimile vastava teststatistiku empiirilise
väärtuse esinemise tõenäosus on väiksem kui olulisuse nivoo α
● Sagedasemad olulisuse nivood: 0,1;
0,05; 0,01
● Olulisuse nivoole vastav teststatistiku väärtus on kriitiline väärtus.
○ Näiteks kriitilised väärtused kahepoolse z-testi korral on -1,96 ja 1,96.
Kriitilistest väärtustest kaugemal on kriitiline piirkond (viirutatud), kus kehtib sisukas
hüpotees
KOKKUVÕTVALT:
● Püstitatakse hüpoteesipaar: nullhüpotees ja sisukas hüpotees.
● Valitakse sobiv teststatistik.
● Valimi põhjal leitakse selle empiiriline väärtus.
● Võetakse ette olulisuse nivoo (tavaliselt 0,05).
● Võrreldakse
– kas empiirilist ja kriitilist väärtust või
– olulisuse tõenäosust p ja olulisuse nivood α.
● Otsustatakse, kumb hüpotees tuleb vastu võtta
– Kui empiiriline väärtus on kriitilisest suurem (ehk p < α), on nullhüpotees
ümber lükatud ja tuleb vastu võtta sisukas hüpotees.
13. Hüpoteeside kontrollimine: otsuse vastuvõtmine, kui on antud teststatistiku
empiirilisele väärtusele vastav olulisuse tõenäosus ja olulisuse nivoo.
Olulisuse nivoo ja olulisuse tõenäosus
● Statistika- ja ökonomeetriapaketid võimaldavad hüpoteeside kontrollimisel leida
lisaks teststatistiku empiirilisele väärtusele ka sellele vastavat tõenäosust.
● See on
olulisuse tõenäosus p (näitab tõenäosust, kui hästi valim sobib
nullhüpoteesiga)
● Nullhüpotees
lükatakse tagasi, kui olulisuse tõenäosus
p < α olulisuse nivoo (nt
0,05)
14. Olulisuse nivoo ja kahte liiki vead. ● I liiki vea tõenäosuse ülempiir on olulisuse nivoo α.
● See määratakse ära enne hüpoteesi kontrollimist.
● Võetakse enamasti kas 5% või 1% (mõnikord ka 10%)
● Olulisuse nivoo alandamine (α väärtuse vähendamine)
○ vähendab I liiki vea tõenäosust;
○ suurendab II liiki vea tõenäosust
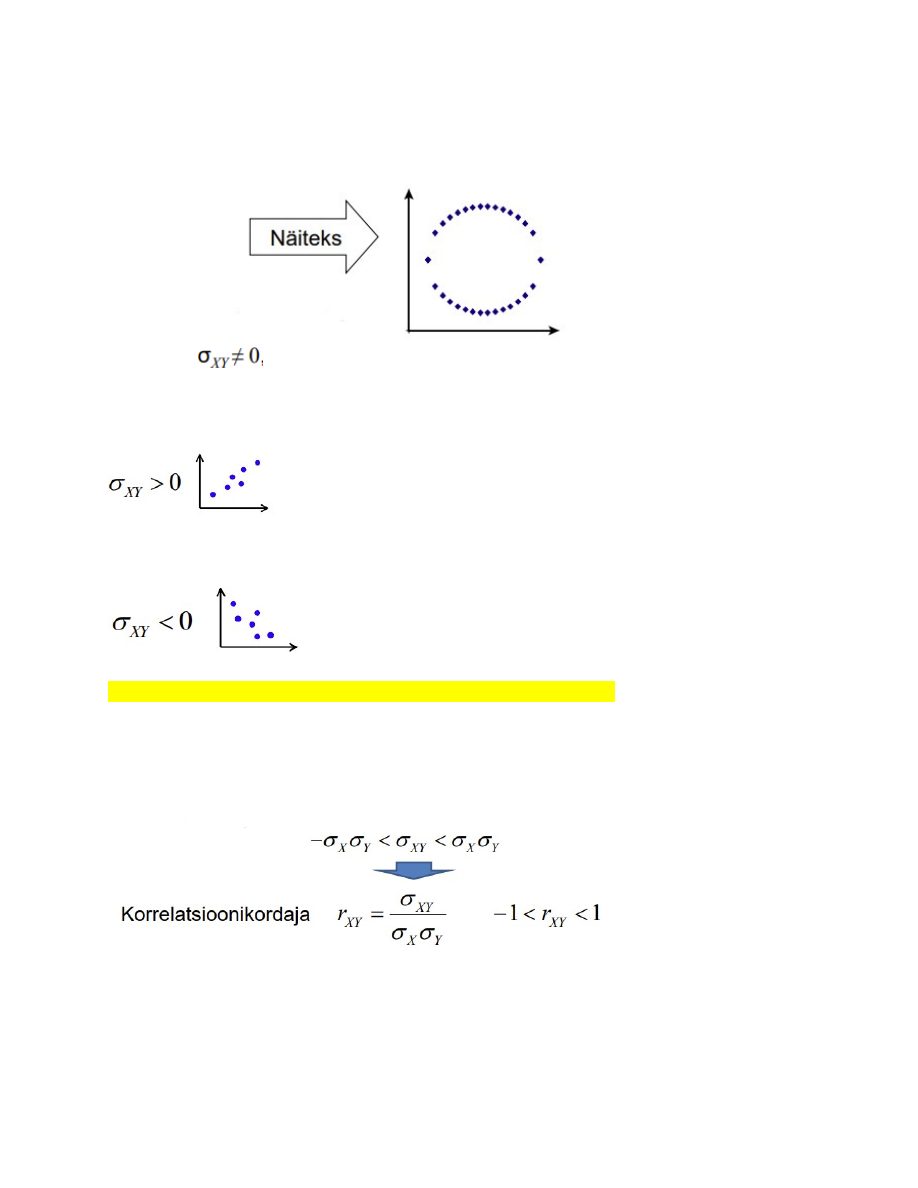
15. Kovariatsioon, selle arvutusvalem ja omadused.
Dispersioon: ühe suuruse hajumine:
Kovariatsioon: kahe suuruse koosmuutumine
Diskreetsete tunnuste korral:
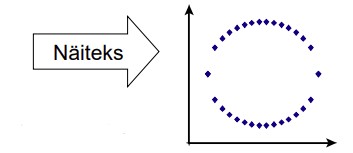
Erinevalt dispersioonist võib kovariatsioon olla nii positiivne kui ka negatiivne:
Kovariatsiooni omadused:
1. Sümmeetrilisus:
2. Kui X=Y, siis
● Kovariatsioon on dispersiooni üldistus
● Dispersioon on kovariatsiooni erijuht: kovariatsioon iseendaga
3. Sõltumatute juhuslike suuruste kovariatsioon on võrdne nulliga:● Vastupidine ei kehti, st kui kovariatsioon on null, ei pruugi suurused olla
sõltumatud.
●
4. Kui
siis nimetatakse suurusi X ja Y korreleeruvateks
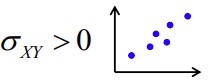
Positiivne kovariatsioon: suurematele X väärtustele vastavad ka suuremad Y
väärtused, väiksematele X väärtustele väiksemad Y väärtused
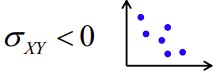
Negatiivne kovariatsioon: suurematele X väärtustele vastavad väiksemad Y
väärtused, väiksematele X väärtustele suuremad Y väärtused.
16. Korrelatsioonikordaja, selle arvutusvalem ja omadused.
● Kovariatsiooni puudus: absoluutväärtus võib olla väga suur! => Raske hinnata
seose tugevust.
● Normeeritakse nii, et absoluutväärtuse maksimaalne väärtus oleks 1
● Korrelatsioonikordaja
absoluutväärtus näitab lineaarse seose
tugevust.
●
Märk näitab seose
suunda: positiivne või negatiivne
rAB = 0,58 rAC= - 0,87
A ja C vahel on tugevam seos kui A ja B vahel
Korrelatsioonikordaja valem:
17. Hüpoteesi kontrollimine korrelatsioonikordaja olulisuse kohta: nullhüpotees
ja sisukas hüpotees.
Korrelatsioonikordaja statistilise olulisuse kontrollimine seisneb hüpoteeside paari
H0: r = 0;
H1: r
≠ 0; kontrollimises
18. Regressioonanalüüs ja regressioonmudeli komponendid.
Regressioonmudel koosneb deterministlikust ja juhuslikust komponendist.
Y = deterministlik komponent + juhuslik komponent
Tinglik keskväärtus on deterministlik komponent y=E[Y|X]+u
Näiteks lineaarne regressioonmudel y=
ax+b + u
ax+b - deterministlik komponent ehk tinglik keskväärtus
u - juhuslik komponent
Regressioonanalüüs uurib suuruste vahelist sõltuvust ja võimalusi selle
funktsionaalseks kirjeldamiseks etteantud valemi põhjal.
Regressioonanalüüsi käigus leitakse regressioonmudeli deterministlik komponent, st
leitakse vastava matemaatilise funktsiooni parameetrite hinnangud.
19. Vähimruutude meetodi olemus.
Vähimruutude meetod on kõige tuntum meetod, selle abil minimeeritakse
hälvete
ruutude summat.
● Lineaarne mudel: harilik vähimruutude meetod OLS (Ordinary Least Squares).
● Mittelineaarne mudel: mittelineaarne vähimruutude meetod NLS (Nonlinear
Least Squares)
● Teatud juhtudel üldistatud vähimruutude meetod GLS (Generalized Least
Squares)
Vähimruutude meetodi kasutamiseks peab mudel olema lineaarne
parameetrite
suhtes.
Vähimruutude meetod: regressioonmudeli parameetrite hinnangud leitakse nii, et
jääkide ruutude summa on minimaalne. Parameetrite hinnangute valemite tuletamine:
Hälvete ruutude summa RSS (Residual Sum of Squares). Tuleb leida kahe muutuja
funktsiooni miinimumkoht.
Matemaatilisest analüüsist: I järku osatuletised peavad võrduma nulliga
20. Vähimruutude meetodil leitud hinnangute omadused, kui kehtivad klassikalise
lineaarse mudeli eeldused.
On võimalik näidata (Gauss-Markovi teoreem), et sel moel leitud hinnangud on
● nihketa;
● efektiivsed, so vähima dispersiooniga kõigi nihketa lineaarsete hinnangute seas;
● lineaarsed vaatluste yi suhtes.
KUI
Kehtivad klassikalise lineaarse mudeli eeldused
Sellisel juhul annab vähimruutude meetod lineaarse regressioonmudeli jaoks parima
lineaarse nihketa hinnangu (
BLUE)
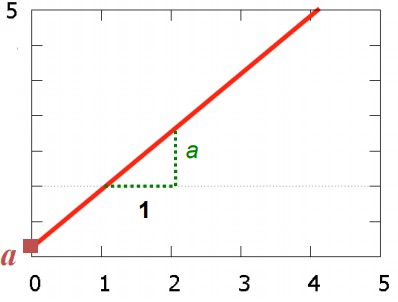
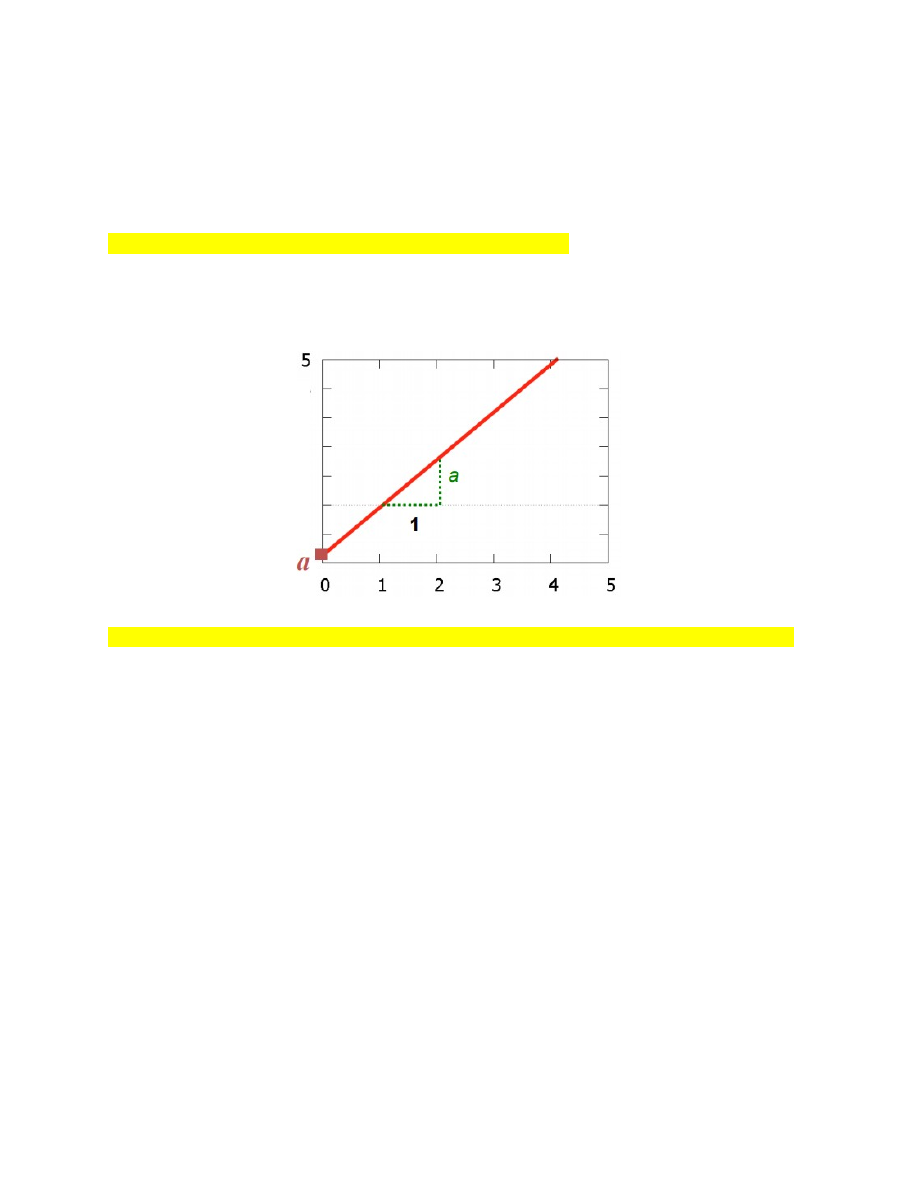
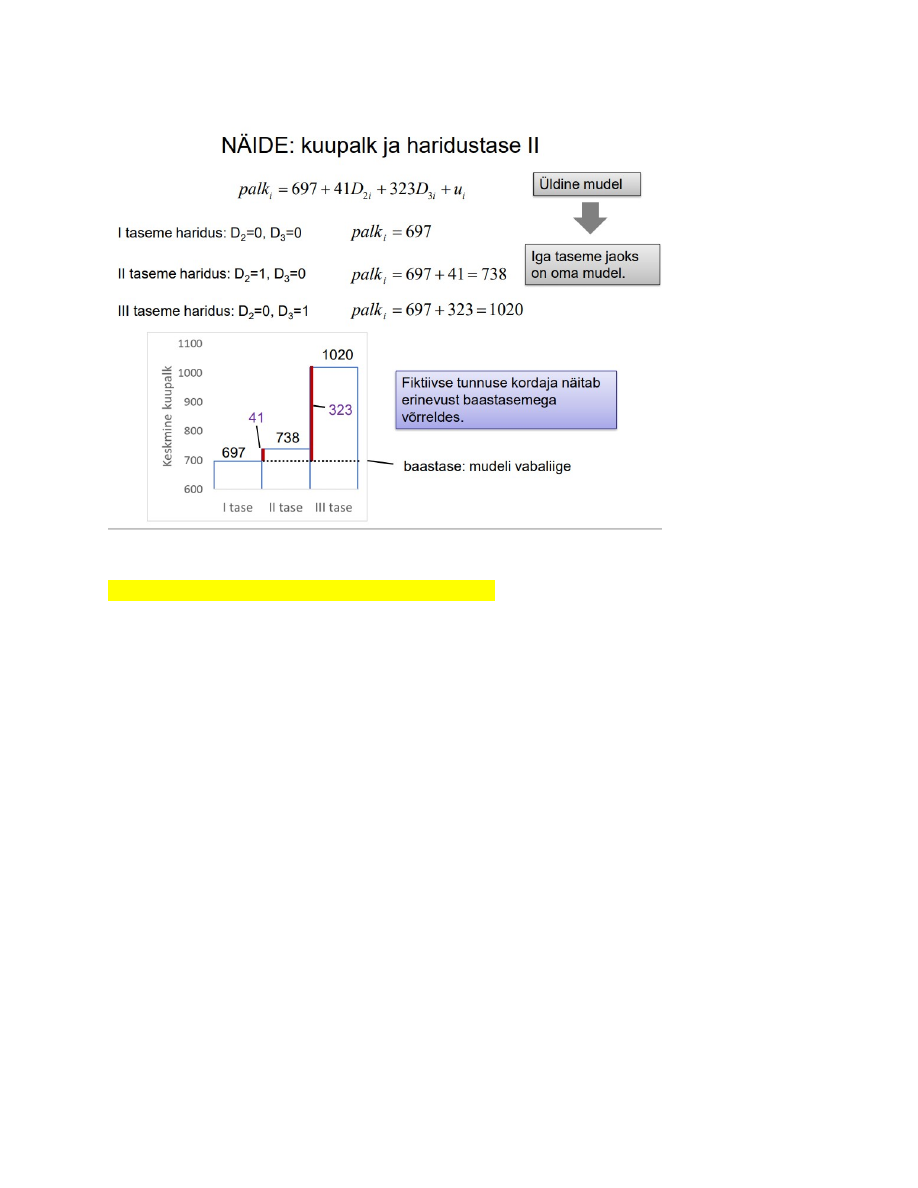
21. Lineaarse mudeli parameetrite tõlgendus üldjuhul.
y = b + ax
a - sirge tõus (näitab, kui palju muutub y, kui x muutub ühiku võrra)
b - konstant ehk vabaliige (näitab, millega võrdub y, kui x=0)
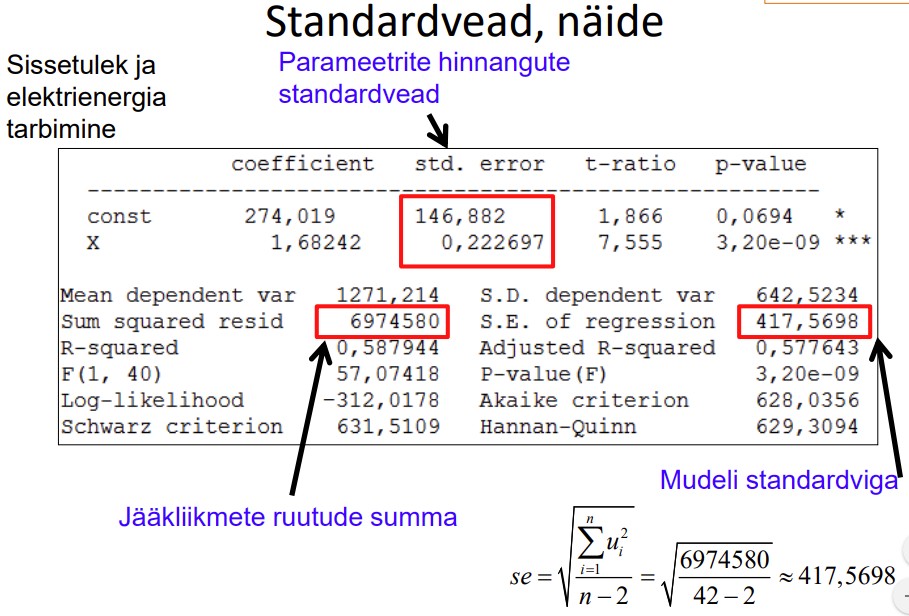
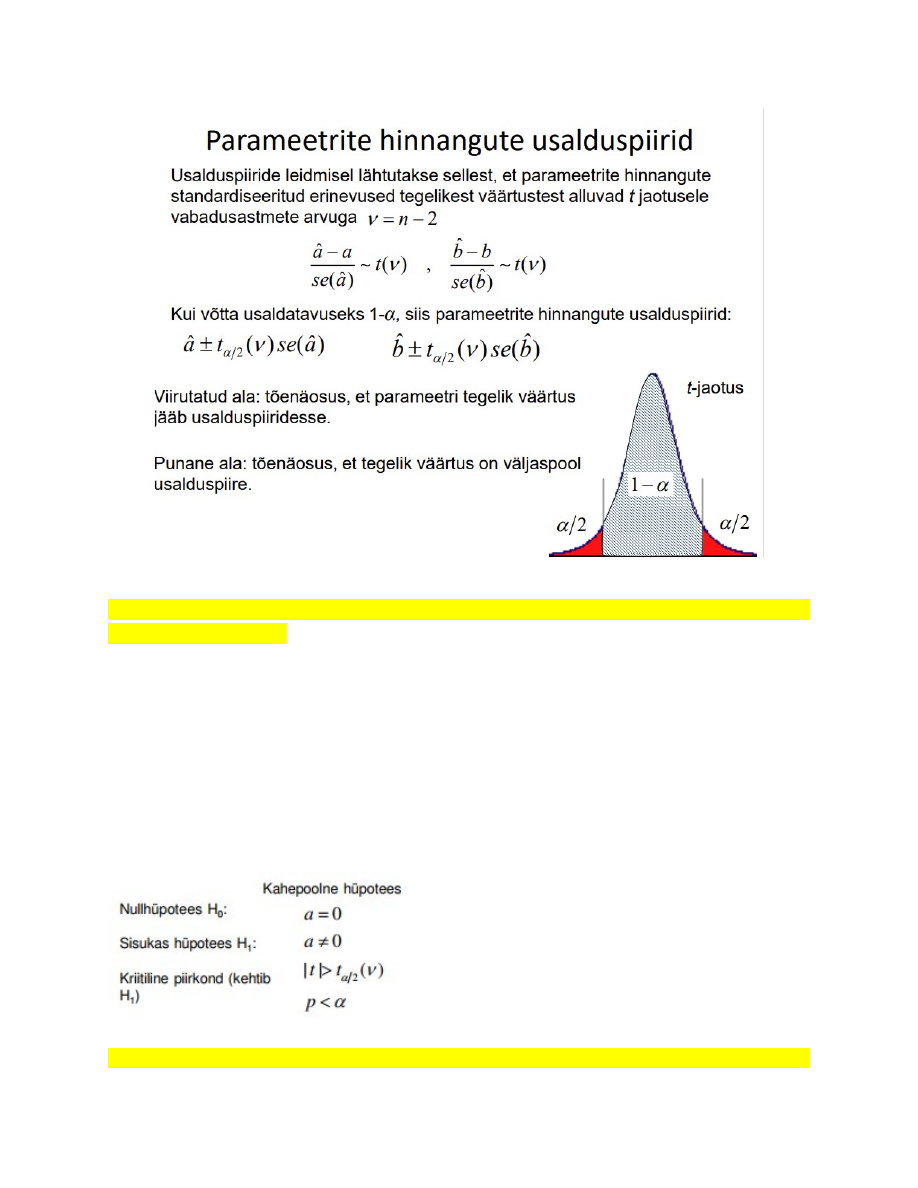
22. Parameetrite hinnangute usalduspiirid, millest sõltub usaldusvahemiku laius
Usalduspiiride leidmisel lähtutakse sellest, et parameetrite hinnangute standardiseeritud
erinevused tegelikest väärtustest alluvad t jaotusele vabadusastmete arvuga
v=n-2
Parameetrite hinnangute standardvead näitavad, kui täpsed on parameetrite hinnangud.
Täpsemate hinnangute saamiseks peavad x väärtused võimalikult palju hajuma.
Usalduspiiride leidmisel lähtutakse sellest, et parameetrite hinnangute standardiseeritud
erinevused tegelikest väärtustest alluvad t jaotusele vabadusastmete arvuga.
23. Hüpoteeside testimine parameetrite jaoks ja parameetrite statistilise olulisuse
kontrollimine (t-test).
Parameetrite statistiline olulisus
Kõige sagedamini on regressioonmudeli korral vaja testida, kas tunnused Y ja X on
omavahel seotud, st kas tõusuparameeter a
erineb oluliselt nullist.
Ökonomeetriapakettides leitakse t ja p väärtused just selle juhu jaoks. See on
parameetrite
statistilise olulisuse kontrollimine. Kui nullhüpotees on ümber lükatud
(võetakse vastu sisukas hüpotees), on parameeter oluliselt nullist erinev, järelikult seos
on olemas.
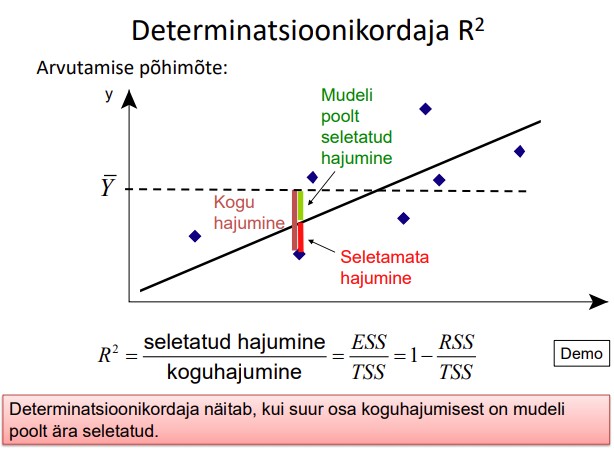
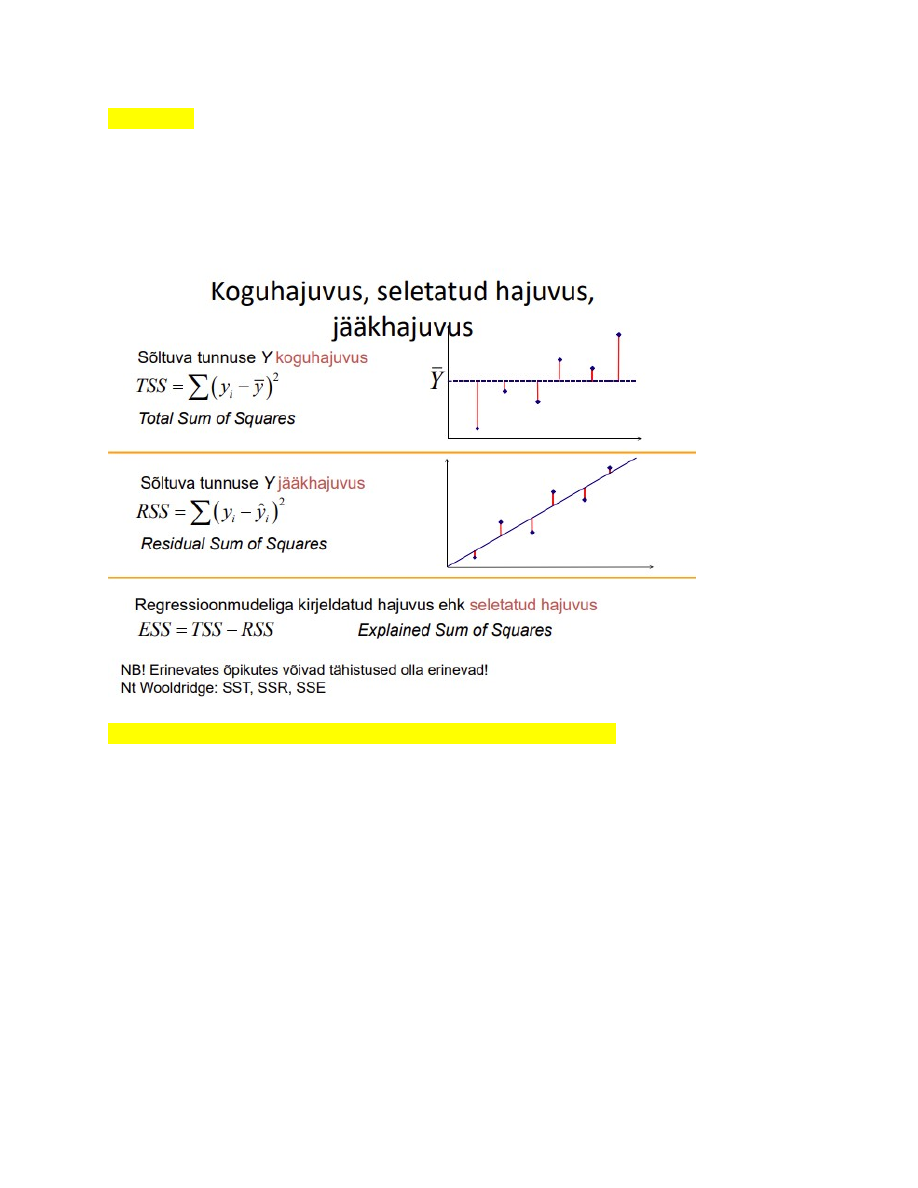
24. Koguhajuvus, seletatud hajuvus, jääkhajuvus ja neid iseloomustavadsuurused.
● Sõltuva tunnuse Y koguhajuvus on TSS
● Sõltuva tunnuse Y jääkhajuvus on RSS.
● Regressioonmudeliga kirjeldatud hajuvus ehk seletatud hajuvus ESS =TSS-RSS
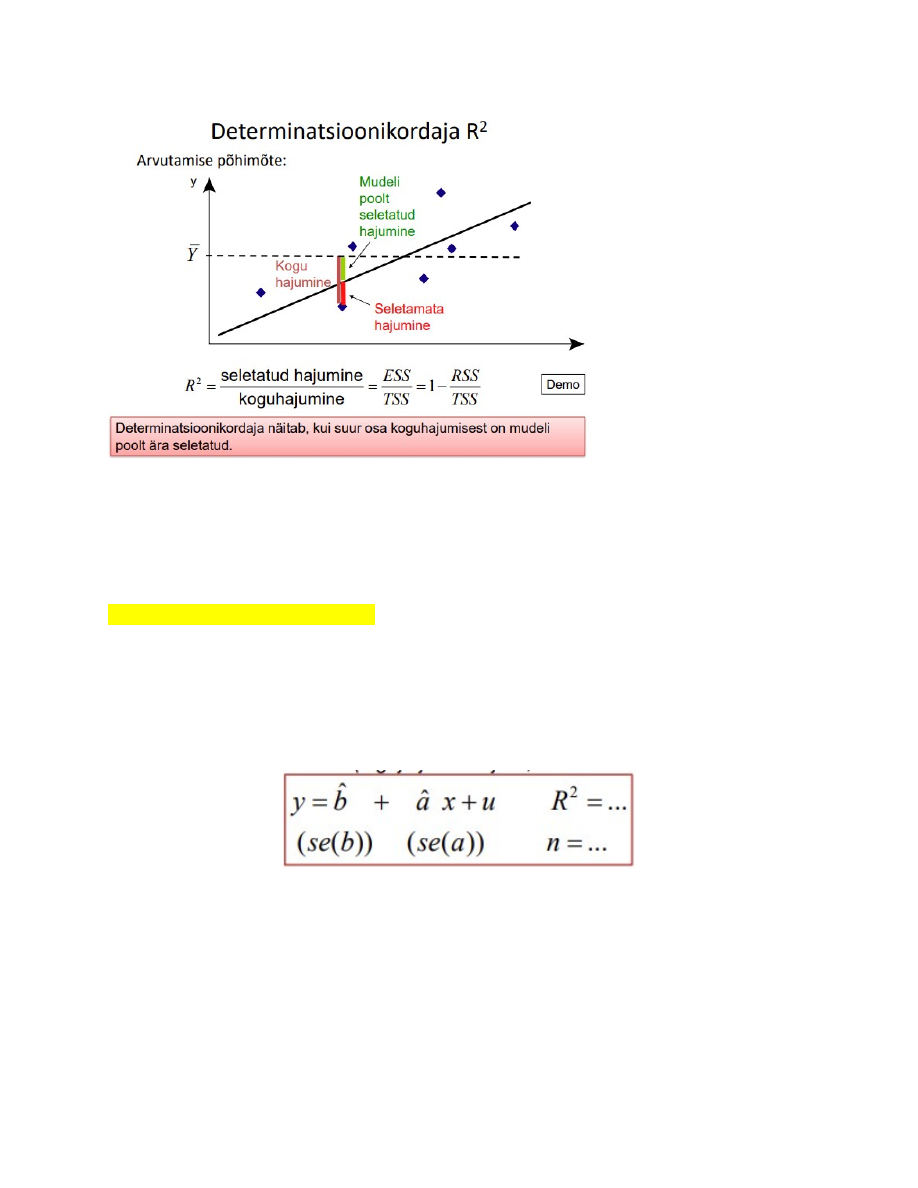
25. Determinatsioonikordaja, selle arvutus ja tõlgendamine.
Determinatsioonikordaja näitab, kui suur osa koguhajumisest on mudeli poolt ära
seletatud
Kui mudeli parameetrid on statistiliselt olulised, tuleb hinnata ka mudeli kirjeldusvõimet.
Kvantitatiivseks kirjeldamiseks kasutatakse determinatsioonikordajat R2.
Kui võrrelda determinatsioonikordajat ja korrelatsioonikordajat, siis
determinatsioonikordaja sisu on paremini mõistetav, aga ei näita seose suunda.
26. Mudeli korrektne esitamine.
Regressioonanalüüsi põhitulemuste esitamisel esitatakse
● parameetrite hinnangud;
● parameetrite standardvead;
● determinatsioonikordaja R2 ;
● valimi maht n (lugeja jaoks vajalik, kui soovib t-testi läbi viia)
VARIANT 2: Mõnikord esitatakse parameetrite all sulgudes standardvigade asemel
vastavad t-statistiku väärtused. See võimaldab lugejal neid kohe võrrelda vastava
kriitilise väärtusega.
VARIANT 3: Mõnikord esitatakse sulgudes vastavad olulisuse tõenäosused. Sellisel
juhul ei pea lugeja arvutama kriitilist väärtust, võib kohe võrrelda olulisuse nivooga ja
hinnata, kui võimsalt on mingi tunnuse mõju tõestatud.
Variandid 2 ja 3 on vastuvõetavad vaid siis, kui huvi pakub vaid koefitsientide erinevus
nullist.
27. Regressioon läbi nullpunkti.
Mõnikord tuleb siiski hinnata lineaarset mudelit, kus teatud kaalutlustest lähtudes peab
vabaliige puuduma.
Seda nimetatakse regressiooniks läbi nullpunkti (Regression through the Origin, RTO)
ja sellise mudeli üldkuju ühe tunnuse korral on
y=ax+u
Deterministlik komponent on võrdeline seos
28. Seletavate tunnuste astmeid, ruutjuurt ja pöördväärtust sisaldava
mittelineaarse mudeli lineariseerimise võtted.
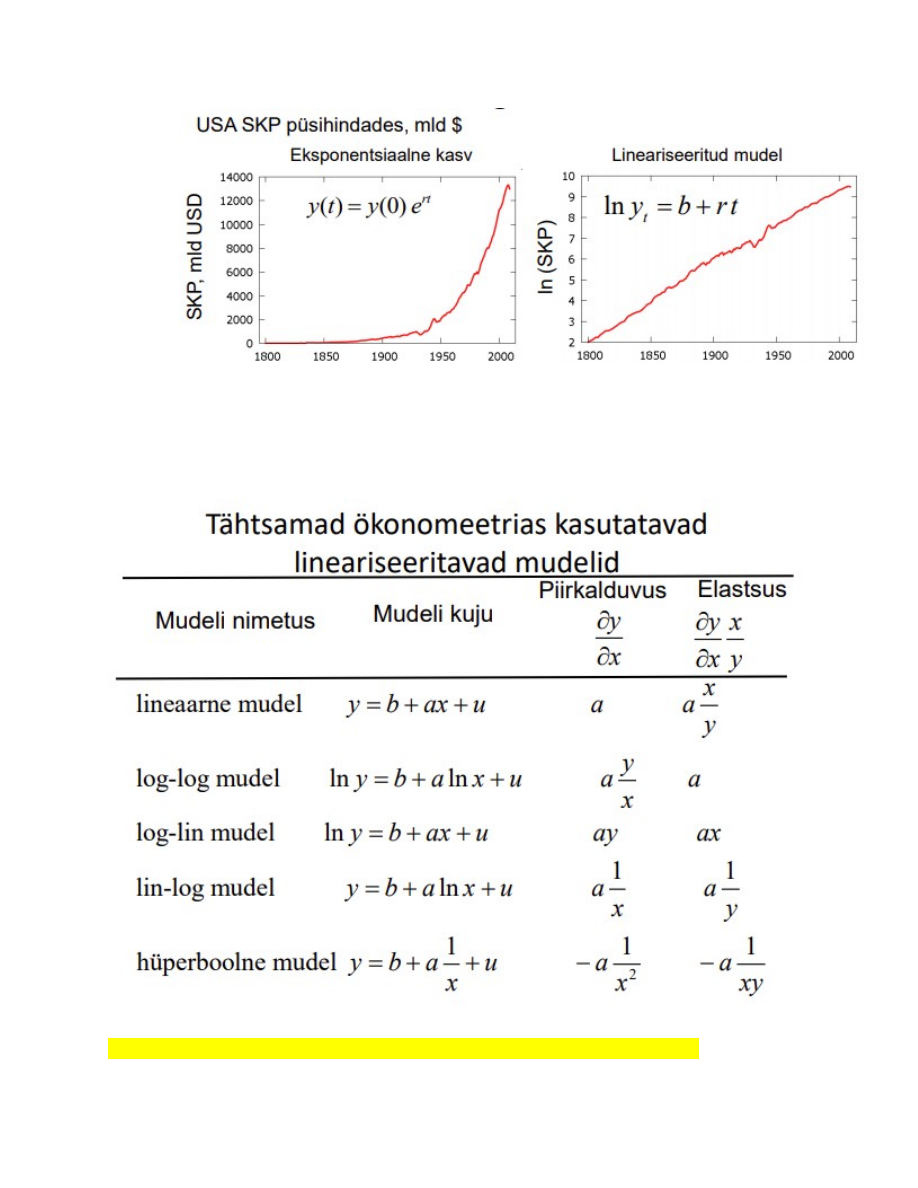
29. Sagedamini kasutatavad erikujulised mudelid: log-log, log-lin, lin-log ja
hüperboolne mudel.
1. Log-log mudel - logaritmime kõiki tunnuseid, saame log-log mudeli
(logaritmimata tunnused on väga asümmeetrilised, logaritmitud tunnused on
asümmeetrilisemad)
Log-log mudeli kordaja tõlgendus näide:
Log-log mudeli kordaja näitab, mitu % muutub Y, kui X suureneb 1%. See on
elastsuskordaja.
Lineaarse mudeli puhul on piirkalduvus konstantne.
Log-log mudeli puhul on elastsuskordaja konstantne!
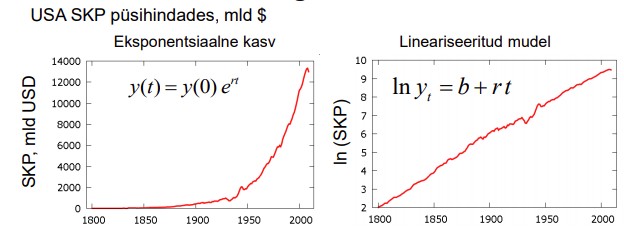
2. Log-lin mudel - logaritmitakse ainult sõltuvat tunnust (Y). Lineariseeritud mudel :
ln y=b+rt, kus parameeter r on kasvumäär ja sõltumatu tunnus t on aeg. Sõltuva
tunnuse logaritmimine teisendab eksponentsiaalse kõvera lineaarseks.
3. Lin-log mudel - logaritmitakse ainult sõltumatut tunnust (X). lin log mudel:
y=b+a*ln_x+u
4. Hüperboolne mudel - y= b+a(1/x)+u
KOKKUVÕTVALT:
30. Mitmese lineaarse regressioonmudeli parameetrite tõlgendamine. Mitmene lineaarne regressioonmudel
Lihtsa regressioonmudeli korral on üks sõltumatu tunnus X, mis mõjutab sõltuva
tunnuse Y käitumist. Reaalses elus võib sõltuvale tunnusele Y mõjuda aga mitmeid
erinevaid tegureid. Nt. hüvise nõudlust mõjutab sissetulek, hüvise hind, teiste hüviste
hinnad jne.
● Parameetrite arv on k
● Seletavate tunnuste ehk regressorite arv on k-1:
● Parameetrite hinnangud leitakse vähimruutude meetodil (OLS)
Parameetrite tõlgendamine:
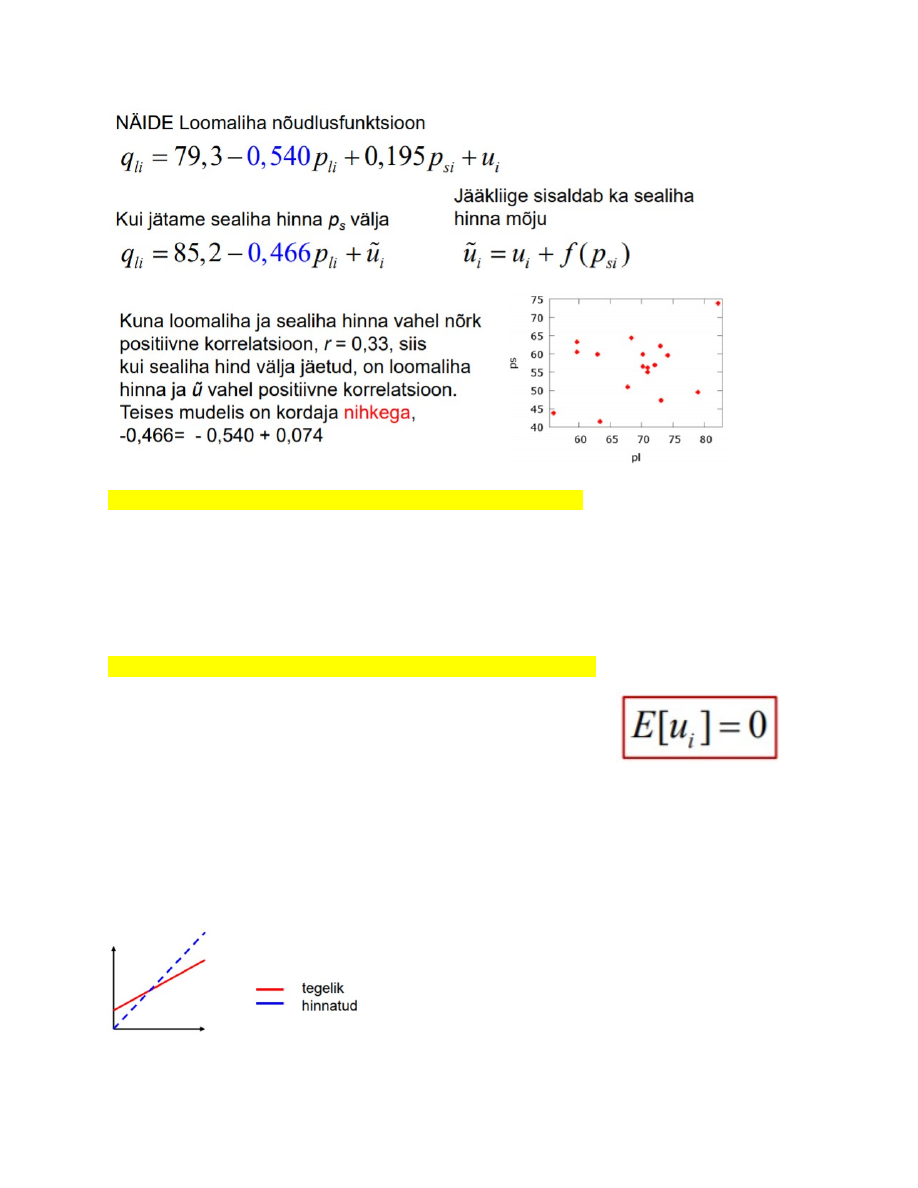
Loomaliha nõudlusfn.
● Kui loomaliha hind tõuseb 1 sent ja sealiha hind jääb konstantseks, siis
loomaliha nõutav kogus väheneb 0,54 naela elaniku kohta aastas.
● Kui sealiha hind tõuseb 1 sent ja loomaliha hind jääb konstantseks, siis loomaliha
nõutav kogus suureneb 0,195 naela elaniku kohta aastas.
● Kui x2 suureneb ühiku võrra ja ülejäänud seletavad tunnused x3 , … xk jäävaks
samaks, siis y muutub b2 võrra.
● Ceteris paribus: kõik muu jääb samaks
● bj on y marginaalväärtus xj suhtes, matemaatiliselt
osatuletis
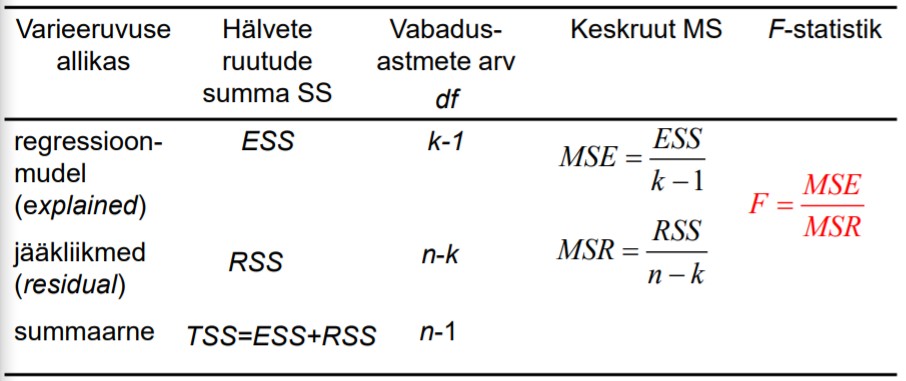
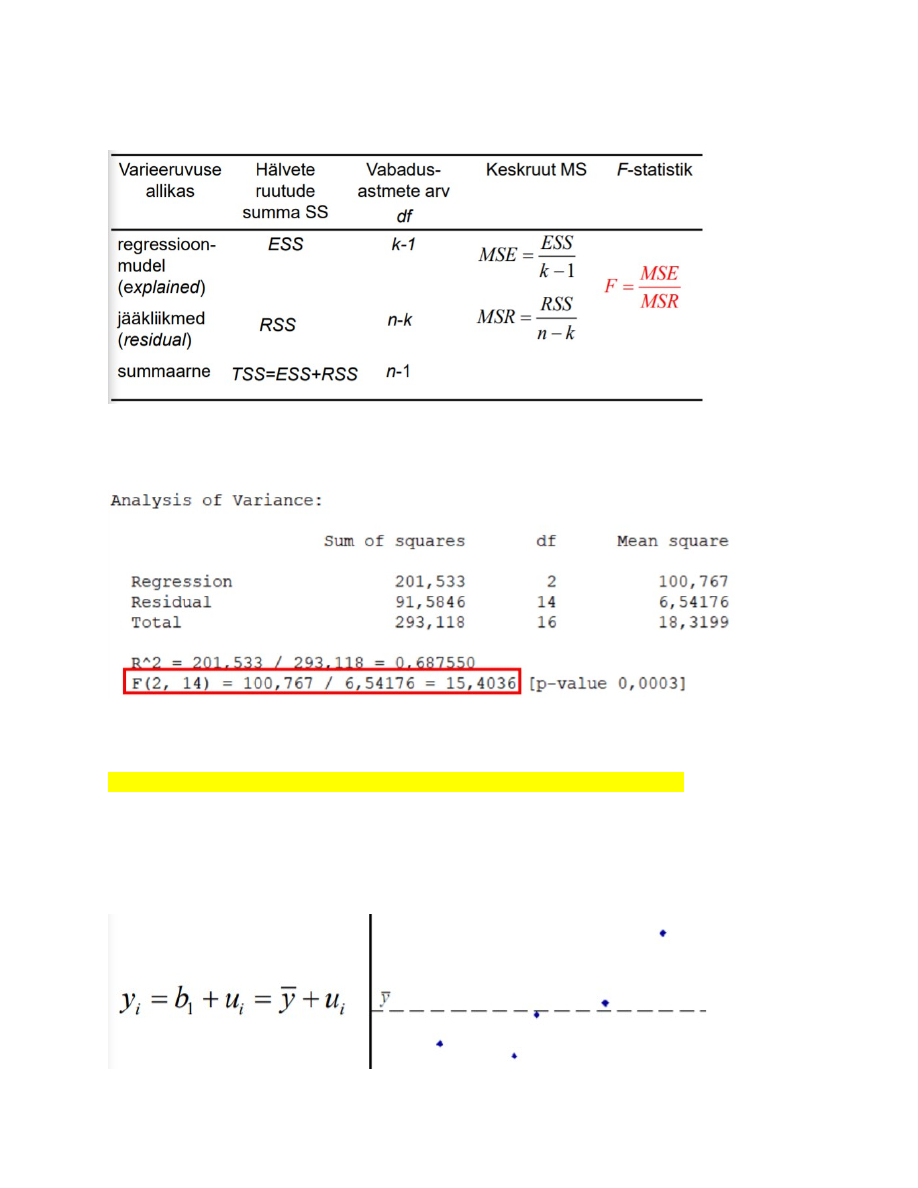
31. ANOVA tabel, F-statistiku arvutamine.
ANOVA tabel
N-valimi maht
K-parameetrite arv
F statistik
on
keskruutude jagatis. Allub Fisheri ehk F- jaotusele
Programmis Gretl näeb ANOVA tabelit, kui mudeli aruandes valida Analysis -> ANOVA
32. Regressioonmudeli statistilise olulisuse kontrollimine F-testiga.
Mudeli statistilise olulisuse kontrollimiseks kasutatakse F - testi
H0 - kõik seletavate tunnuste kordajad on nullid, b2=b3=… =bk =0
H1 - vähemalt üks kordaja b2 , b3 …., bk on nullist erinev
Nullhüpotees: Y on määratud oma keskväärtusega:
F- statistiku empiirilist väärtust võrreldakse F-jaotuse kriitilise väärtusega (või
empiirilisele väärtusele vastavat olulisuse tõenäosust p võrreldakse olulisuse nivooga
α).
Kui empiiriline väärtus ületab kriitilise (p<α), võetakse vastu sisukas hüpotees: mudel onα), võetakse vastu sisukas hüpotees: mudel on
statistiliselt oluline.
33. Korrigeeritud determinatsioonikordaja kasutamine.
Determinatsioonikordaja R2 :
• Väärtus on lihtsalt tõlgendatav
• Maksimaalne väärtus 1, st saab võrrelda, kui lähedal on arvule 1.
•
Aga ei allu ühelegi tuntud jaotusseadusele, seega pole võimalik leida kriitilist väärtus,
pole võimalik kasutada testimisel (kui suur peab olema, et mudel oleks usaldusväärne?
Determinatsioonikordaja R2
puudus: lisades mudelisse uusi tunnuseid,
determinatsioonikordaja alati suureneb. Ka siis, kui lisame suvalise juhusliku tunnuse.
Et paremini võrrelda mudeleid, kus on erinev arv tunnuseid, kasutatakse korrigeeritud
(modifitseeritud, adjusted) determinatsioonikordajat:
kus n on valimi maht ja k mudeli parameetrite arv.
Kui lisame mudelisse ühe tunnuse, siis on korraga kaks efekti:
Korrigeeritud determinatsioonikordaja tõlgendus ei ole sama, mis tavalisel
determinatsioonikordajal R2 , sest valem on teistsugune, komplitseeritud.
Kui suur osa koguhajuvusest on mudeliga seletatud, näitab ikka tavaline
determinatsioonikordaja R2 .
Korrigeeritud determinatsioonikordaja on vaid üks kvantitatiivne näitaja, mida
kasutatakse erinevat arvu tunnuseid sisaldavate mudelite võrdlemiseks.
34. Parameetrite mitteolulisuse võimalikud põhjused. 1. Tunnus ei sobi mudelisse.
2. Teooriast lähtudes peaks tunnus suurust Y mõjutama ja mudelis olema, kuid valimi
maht on liiga väike ja standardviga tuleb liiga suur.
3. Esineb multikollineaarsus.
• Mudelisse võetud tunnused on omavahel tugevas korrelatsioonis, ei ole sõltumatud.
• Parameetrite standardvigade hinnangud tulevad sel juhul suured.
4. Vabadusastmete arv n-k liiga väike, st kui tunnuste arv on suur ja valimi maht n
väike. • Soovitatav, et parameetrite arv k on oluliselt väiksem valimi mahust n.
35. Klassikalise lineaarse mudeli eeldused.
1. Eeldus: mudel on lineaarne parameetrite suhtes
Eristada tuleb:
• lineaarsus regressorite suhtes;
• lineaarsus parameetrite suhtes.
2. Eeldus: vaatluste arv ei tohi olla väiksem kui hinnatavate parameetrite arv
3. Eeldus: regressori väärtused valimis ei tohi olla ühesugused
4. Eeldus: regressorid ei tohi olla lineaarselt sõltuvad
5. Eeldus: regressorid X on eksogeensed
6. Eeldus: juhuslike liikmete keskväärtus peab olema 0
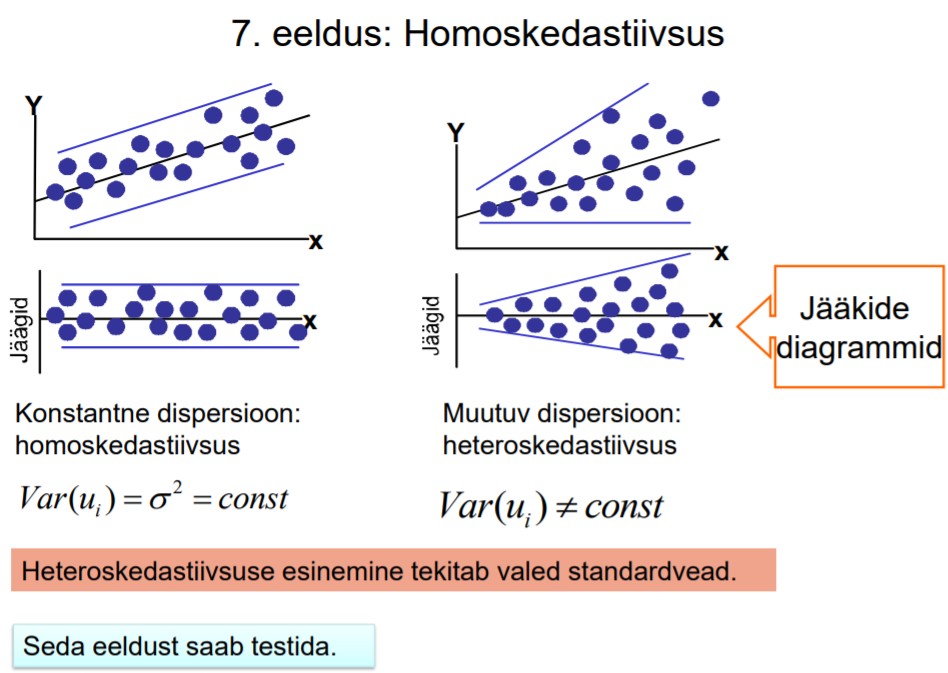
7. Eeldus: Homoskedastiivsus
8. Eeldus Cov(ui , uj )=0, jääkliikmete autokorrelatsiooni puudumine
9. eeldus: juhuslike liikmed peavad alluma normaaljaotusele
10. Aegread peavad olema statsionaarsed!36. Regressorite suhtes lineaarne mudel
Kui mudel ei ole lineaarne regressorite suhtes, aga on lineaarne parameetrite suhtes,
saab seda lineariseerida ning parameetrite hindamiseks kasutada harilikku
vähimruutude meetodit OLS.
Mudeli saab kirjutada kujul
y, x2, x3
,.... võivad olla ka mingid funktsioonid (ln, √) mõõdetud suurustest.
37. Parameetrite suhtes lineaarne mudel.
Kui mudel ei ole lineaarne parameetrite suhtes, ei saa mudelit kirjutada kujul
Ei saa kasutada harilikku vähimruutude meetodit OLS. On võimalik kasutada
mittelineaarset vähimruutude meetodit NLS.
Lineaarne parameetrite suhtes: parameetrid esinevad mudelis vaid astmes 1. Näiteks
38. Mis juhtub, kui vaatluste arv on väiksem kui parameetrite arv?
2. Eeldus: vaatluste arv ei tohi olla väiksem kui hinnatavate parameetrite arv
Vaatluste arv n ≥ k parameetrite arv.
Näiteks üks regressor, 2 parameetrit: yi = axi + b + ui
Kui meil on 1 objekt, st 1 arvupaar, ei saa määrata 2 parameetrit. Sirge määramiseks
tasandil peab olema vähemalt 2 punkti.
39. Mis juhtub, kui regressori väärtused valimis on ühesugused?
3. Eeldus: regressori väärtused valimis ei tohi olla ühesugused
Matemaatiliselt: regressori dispersioon peab olema positiivne arv:
St, seletava tunnuse Xj väärtused peavad hajuma. Kui hajumist ei
ole, ei saa me hinnata, kuidas Xj muutumine mõjutab Y.
40. Mis juhtub, kui regressorid on lineaarselt sõltuvad?
4. Eeldus: regressorid ei tohi olla lineaarselt sõltuvad
Lineaarne sõltuvus on, kui
Sellisel juhul saab suvalise regressori avaldada teiste regressorite lineaarse
kombinatsioonina. Näiteks
Kahe regressori korral: lineaarne sõltuvus tähendab kollineaarsust. Näiteks
Kollineaarsus: punktide omadus paikneda ühel sirgel.
Rohkem kui 2 regressorit: multikollineaarsus.
EI TOHI ESINEDA TÄPSET MULTIKOLLINEAARSUST.
Võib esineda ligikaudne multikollineaarsus.
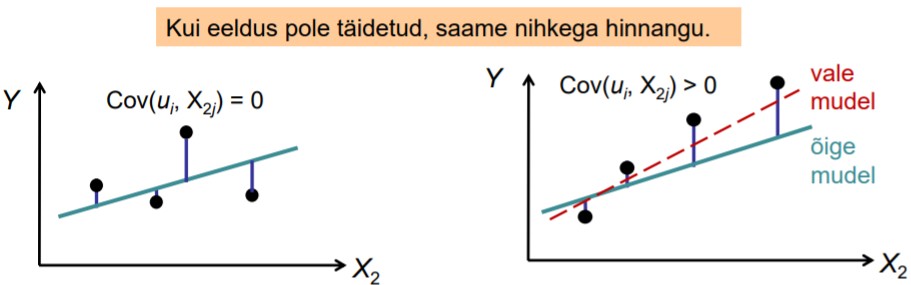
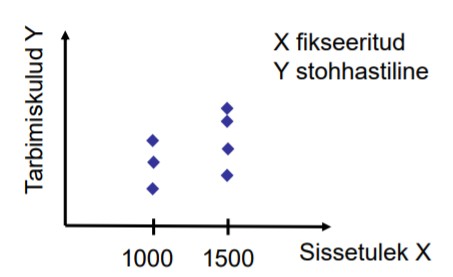
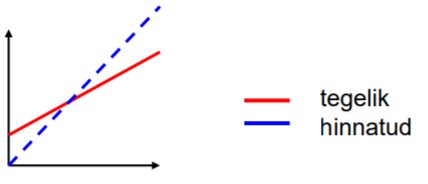
41. Eksogeensuse eeldus, kaks tingimust.
Regressorid X on eksogeensed: regressorite X väärtused on fikseeritud või sõltumatud
juhuslikest liikmetest.
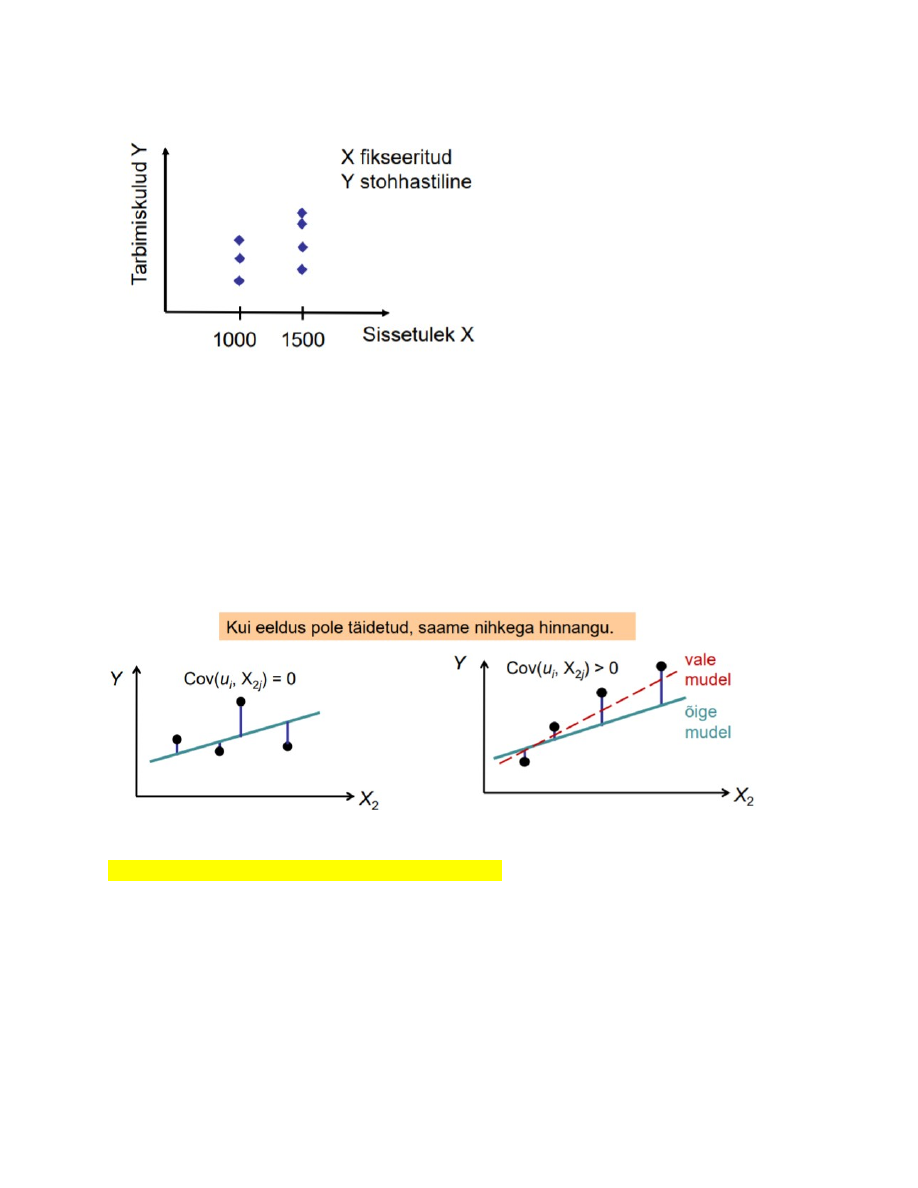
1) Väärtused on fikseeritud, ei muutu juhuslikult, ei ole stohhastilised.
Millal X väärtused fikseeritud? Näide: tarbimismudeli hindamine.
Pered, kelle sissetulek X on 1000 eurot. Mingi hüvise tarbimiskulud võivad sellistel
peredel olla 200 eurot, 250 eurot, 260 eurot jne. Saame leida E [ Y I X = 1000 ]
Pered, kelle sissetulek on X on 1500 eurot. Mingi hüvise tarbimiskulud võivad sellistel
peredel olla 250 eurot, 300 eurot, 400 eurot jne. Saame leida E [ Y I X = 1500 ]
Selle tingimuse täitmine on
majandusandmete korral tihti võimatu.
Kui see pole täidetud, peab olema
täidetud teine tingimus: sõltumatus
juhuslikest liikmetest u.
2) Regressorid ja juhuslikud
liikmed on sõltumatud: Cov(ui , Xaj)=0
Kui näiteks tunnuse X2 ja juhuslike liikmete ui vahel on seos, siis me ei saa tunnuse X2
mõju sõltuvale tunnusele Y puhtalt eraldada. Näiteks yi=b1+b2xi+ui Suuremale
juhuslikule liikmele ui vastab suurem yi
Kui aga X ja ui vahel on positiivne korrelatsioon, siis samal ajal on meil ka suurem xi
Seega näib, et suurema yi põhjustas suurem xi. Parameetri b2 hinnang tuleb suurem.
Saame nihkega hinnangu.
42. Millal eksogeensuse eeldus pole täidetud?
See eeldus pole täidetud, kui mudelist on välja jäetud mõni oluline tunnus.
43. Mis juhtub, kui eksogeensuse eeldus pole täidetud?
Kui see eeldus pole täidetud, siis saame nihkega hinnangud.
Selle eelduse täitmist on kõige raskem kontrollida. Puuduvad spetsiaalsed testid. Seda
nimetatakse ka eksogeensuse tingimuseks.
44. Mis juhtub, kui juhuslike liikmete keskväärtus pole 0?
6. eeldus: juhuslike liikmete keskväärtus peab olema 0
• Kui eeldus kehtib: mudelisse mittelülitatud sõltumatute
tunnuste mõju sõltuva tunnuse Y keskväärtusele on
summaarselt null.
• Kui mudeli hindamisel on mudelisse lülitatud ka konstant (vabaliige), siis on see
eeldus automaatselt täidetud.
• Eelduse kehtivust tuleb kindlasti kontrollida siis, kui konstanti mudelisse pole võetud
(regressioon läbi nullpunkti).
– Kui siis see eeldus pole täidetud, saame parameetrite hinnangud nihkega.
– Kontrollimiseks salvestada jääkliikmed ja viia läbi nende keskväärtuse võrdlemine
nulliga (t-test).
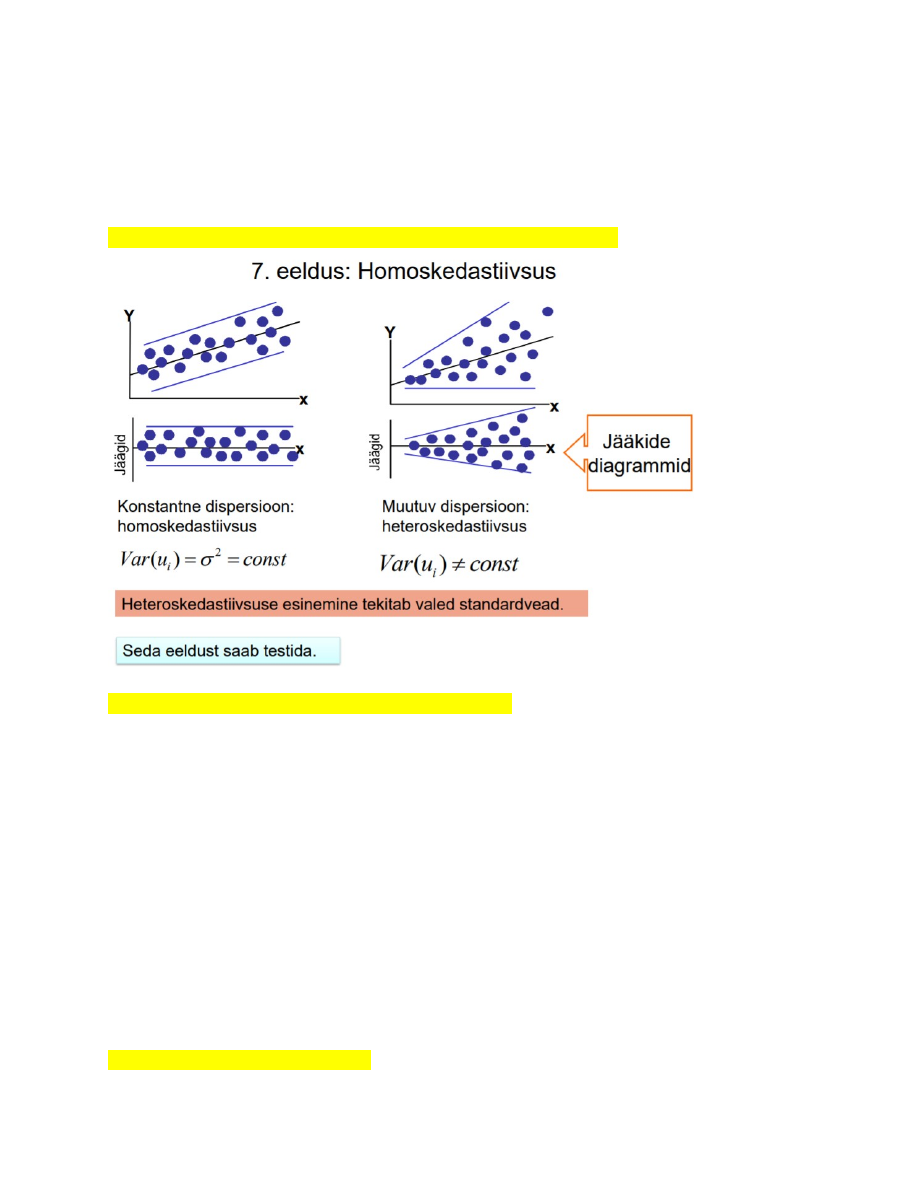
45. Mis on heteroskedastiivsus, mis on homoskedastiivsus.
46. Heteroskedastiivsuse võimalikud põhjused.
• Matemaatilise mudeli vale kuju.
– näiteks log-lin asemel hinnatakse lineaarset mudelit
• Mõni oluline seletav tunnus on mudelist välja jäänud.
• Üks või mitu seletavat tunnust on asümmeetrilised.
• Üksikute erindite (outliers) esinemine vaatluste hulgas.
• Andmekogumismeetodid paranevad -> vaatlusvigade suurus väheneb, st juhuslikud
liikmed vähenevad.
• Muud põhjused
– suurema kasumiga ettevõtetel on dividendipoliitikas suuremad erinevused;
– suurema sissetulekuga peredel on säästmisharjumused rohkem hajunud.
HETEROSKEDASTIIVSUST VÕIB PÕHJUSTADA NII MUDEL KUI KA ANDMED
47. Heteroskedastiivsuse mõju • Vealiikmete dispersioon EI ESINE parameetrite HINNANGUTE arvutusvalemites.
• Järelikult heteroskedastiivsus parameetrite hinnanguid ei mõjuta. Need on ikka
nihketa.
• Vealiikmete dispersioon ESINEB parameetrite hinnangute STANDARDVIGADE
arvutusvalemites.
– Parameetrite hinnangud ei ole enam efektiivsed.
– Parameetrite usalduspiirid tulevad valed.
– Mudeli ja parameetrite olulisuse testimine (F-test ja t-testid) võivad anda
valesid tulemusi.
• Järelikult võime teha valesid järeldusi mudelisse kuuluvate või mittekuuluvate tunnuste
suhtes.
● Hinnangud ei ole efektiivsed
● Parameetrite usalduspiirid tunduvad valed
48. White’i testi idee, nullhüpotees ja sisukas hüpotees.
White’i heteroskedastiivsuse test
Näiteks kahe regressoriga regressioonmudel
Testimiseks 1. Viiakse läbi mudeli (1) hindamine ja leitakse jääkliikmed 2. IDEE: kui
jääkliikmete dispersioon ei ole konstantne, siis see sõltub regressoritest x.
Kontrollimiseks hinnatakse regressioonmudelit, kus sõltuvaks tunnuseks jääkliikmete
dispersioon
Nullhüpotees: mudelis (2) on vaid konstant, H0 :
Teststatistik
kus R2 u on mudeli (2) determinatsioonikordaja
Kuil TR2 väärtus ületab kriitilise (p<α), on tegemist heteroskedastiivsusega.
White’i test programmis Gretl:
49. Mida teha, kui heteroskedastiivsus esineb?
Heteroskedastiivsuse eemaldamiseks:
• logaritmida tunnuseid;
• kontrollida mudeli spetsifikatsiooni:
– kas mudelil on õige kuju;
– kas mõni oluline tunnus on äkki välja jäetud;
– mudelit teisendada, uuesti hinnata.
Kui heteroskedastiivsust eemaldada ei õnnestu:
* leida heteroskedastiivsuse suhtes kohandatud standardvigade hinnangud
(heteroskedasticity-consistent standard errors, robust standard errors)
– Nende kasutamisel võib heteroskedastiivsus esineda, need arvestavad seda.
50. Kohandatud standardvigade kasutamine.
• Kasutada siis, kui heteroskedastiivsusest/autokorrelatsioonist ei õnnestu vabaneda.
• Kohandatud standardvead
EI KAOTA heteroskedastiivsust.
• Nad võtavad heteroskedastiivsust arvesse.
– Nende arvutamisel kasutatakse teistsugust metoodikat kui tavaliste
standardvigade korral.
yi = b + axi + ui
( White’i testi tegemisel selgus, et heteroskedastiivsus esineb. Mudelit hinnati uuesti,
kasutades kohandatud standardvigu.
Kas nüüd tuleb uuesti läbi viia White’i test?
Ei oma mõtet, sest kohandatud standardvigade kasutamine juhuslike vigade jaotust ei
mõjuta. Heteroskedastiivsus jääb ikka sisse. Kohandatud standardvead on
heteroskedastiivsuse suhtes kohandatud, arvestavad sellega. )
51. Mis on autokorrelatsioon?
Autokorrelatsioon on korrelatsioon ühe ja sama tunnuse erinevate väärtuste vahel, mis
on järjestatud. (Loengud lk 179)
Testimine :
Aegrea korral tunnuse väärtused erinevatel ajamomentidel (järjestus aja järgi).
Ristandmete korral tunnuse väärtused erinevatel objektidel (järjestus mingi muu
tunnuse järgi).
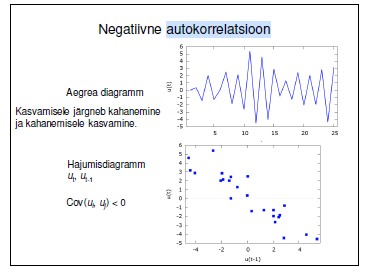
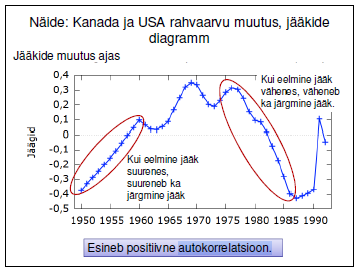
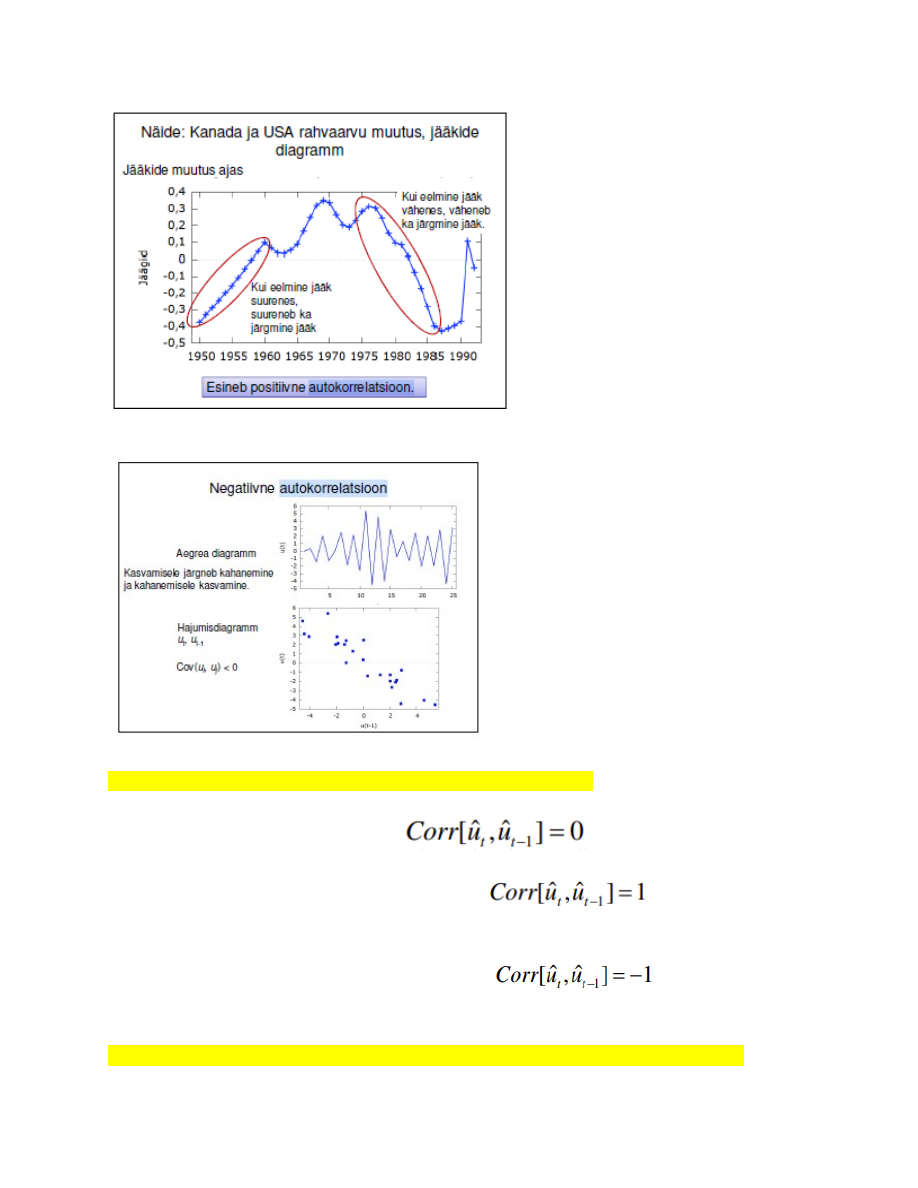
52. Positiivne ja negatiivne autokorrelatsioon. (Loengud lk 180-181)
Positiivne : kahanemisele järgneb kahanemine ja kasvamisele järgneb kasvamine
Negatiivne:Kasvamisele järgneb kahanemine ja kahanemisele kasvamine.
53. Durbin-Watsoni statistiku väärtuste interpreteerimine
Statistiku DW väärtuse interpreteerimine:
1. Kui autokorrelatsioon puudub, siis
ja DW ≈2.
2. Kui jääkide vahel on positiivne autokorrelatsioon, siis DW <α), võetakse vastu sisukas hüpotees: mudel on 2 ja kui
positiivne autokorrelatsioon on väga tugev, siis
ja
DW ≈0.
3. Kui jääkide vahel on negatiivne autokorrelatsioon, siis DW > 2 ja kui
negatiivne autokorrelatsioon on väga tugev, siis
ja DW≈4
54. Durbin-Watsoni statistiku testimine: nullhüpotees ja sisukas hüpotees. H0: positiivne autokorrelatsioon puudub
H1: positiivne autokorrelatsioon eksisteerib
Näide Loengud lk 182
55. Kõrgemat järku autokorrealtsioon.
• DW statistik hindab autokorrelatsiooni vaid vahetult järgnevate
juhuslike liikmete ut ja ut-1 vahel (1. järku autokorrelatsioon).
• Aga autokorrelatsioon võib esineda ka
ut ja ut-2 vahel (2. järku autokorrelatsioon)
ut ja ut-3 vahel (3. järku autokorrelatsioon)
jne
• Näiteks
– kvartaalsete andmete korral ut ja ut-4 vahel
– kuiste andmete korral ut ja ut-12 vahel
56. Breusch-Godfrey autkorrelatsiooni testi idee, nullhüpotees, sisukas hüpotees.
(Loengud lk 183)
H0: autokorrelatsioon puudub
H1: autokorrelatsioon esineb
1. Viiakse läbi mudeli (1) hindamine ja leitakse jääkliikmed
2. IDEE: kui järjestikuste jääkliikmete vahel on seos, siis seda seost saab modelleerida.
Selle kontrollimiseks hinnatakse regressioonmudelit jääkliikmete jaoks. Mudelisse
võetakse r eelmist jääkliiget.
r määrab ära, mitmenda järguni autokorrelatsiooni testitakse
Võib kasutada kaht erinevat teststatistikut. Mõlema teststatistiku arvutamisel lähtutakse
abiregressiooni (2) determinatsioonikordajast R2 u
1. Teststatistik, mis allub F-jaotusele:
Kui LMF väärtus ületab kriitilise (p<α), võetakse vastu sisukas hüpotees: mudel onα), võtta vastu H1, esineb autokorrelatsioon.
Sobib väikeste valimite korral.
2. Teststatistik, mis asümptootiliselt allub χ2-jaotusele:
Kui TR2 väärtus ületab kriitilise (p<α), võetakse vastu sisukas hüpotees: mudel onα), võtta vastu H1, esineb autokorrelatsioon.
Sobib rohkem suurte valimite korral
57. Jääkliikmete autokorrelatsiooni mõju.
(Loengud lk 183)
Jääkliikmete autokorrelatsiooni mõju on sama, mis heteroskedastiivsusel:
• parameetrite hinnangud on nihketa,
• parameetrite standardvead tulevad valed.
58. 1. järku autokorrelatsiooni eemaldamine: idee. ( Loengud lk 183)
59. Jarque-Bera testi idee, nullhüpotees, sisukas hüpotees. (Loengud lk 185)
Juhuslike liikmete normaaljaotumust kontrollitakse Jarque-Bera testiga.
● Jarque-Bera (JB) testi korral leitakse analüüsitava suuruse asümmeetriakordaja
S ja püstakuse kordaja K ning nende põhjal arvutatakse Jarque-Bera teststatistik
● Suurte valimite korral allub χ 2 jaotusele vabadusastmete arvuga 2.
● Normaaljaotuse korral S = 0 ja K = 3, järelikult JB=0
Nullhüpoteesiks on, et jääkliikmed alluvad normaaljaotusele. Kui JB empiiriline väärtus
ületab kriitilise (p<α), võetakse vastu sisukas hüpotees: mudel onα), lükatakse nullhüpotees normaaljaotuse esinemise kohta ümber.
Suvalise tunnuse jaotuse võrdlus normaaljaotusega:
Gretlis: Põhimenüüst Variable -> Normality test
Mudeli jääkliikmete normaaljaotuse testimine JB testiga:
1. Peale mudeli hindamist jäägid salvestada: aruande aknas Save-> Residuals.
Salvestatakse nime all uhat1
2. Valida välja uhat1 ja põhimenüüst Variable -> Normality test
Puudus:
Kui valim on väike, (nt n=42) siis JB test võib anda vale tulemuse. Töötab ainult
suure valimi korral.
60. Mis juhtub, kui jäägid ei allu normaaljaotusele? • Kui muud eeldused on täidetud, siis OLS hinnangud on ikka parimad lineaarsed
nihketa hinnangud (BLUE, Best Linear Unbiased Estimator).
• Suurte valimite (n>100) korral teststatistikud alluvad ikka (asümptootiliselt)
standardsetele jaotusseadustele => testimine annab õiged tulemused.
– Suure valimi korral ei tekita jääkide jaotuse kõrvalekaldumine normaaljaotusest
probleeme.
• Väikeste valimite korral teststatistikute jaotus võib erineda standardsest jaotusest,
millest leitakse kriitilised väärtused ja olulisuse tõenäosus => testimise tulemused
võivad olla valed.
– Väikese valimi korral omab jääkide normaaljaotus tähtsust.
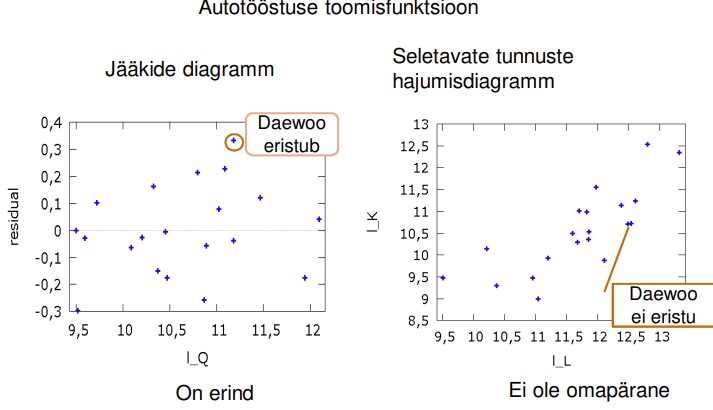
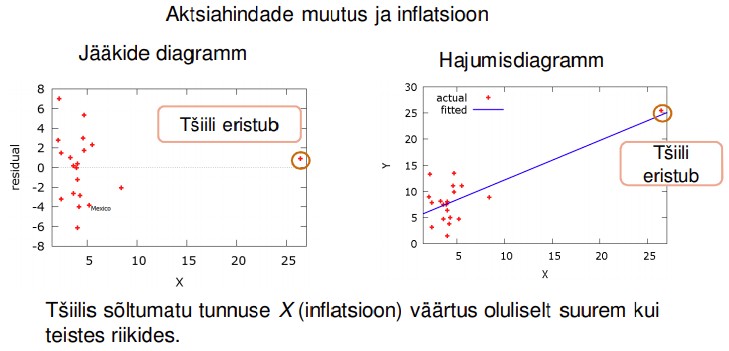
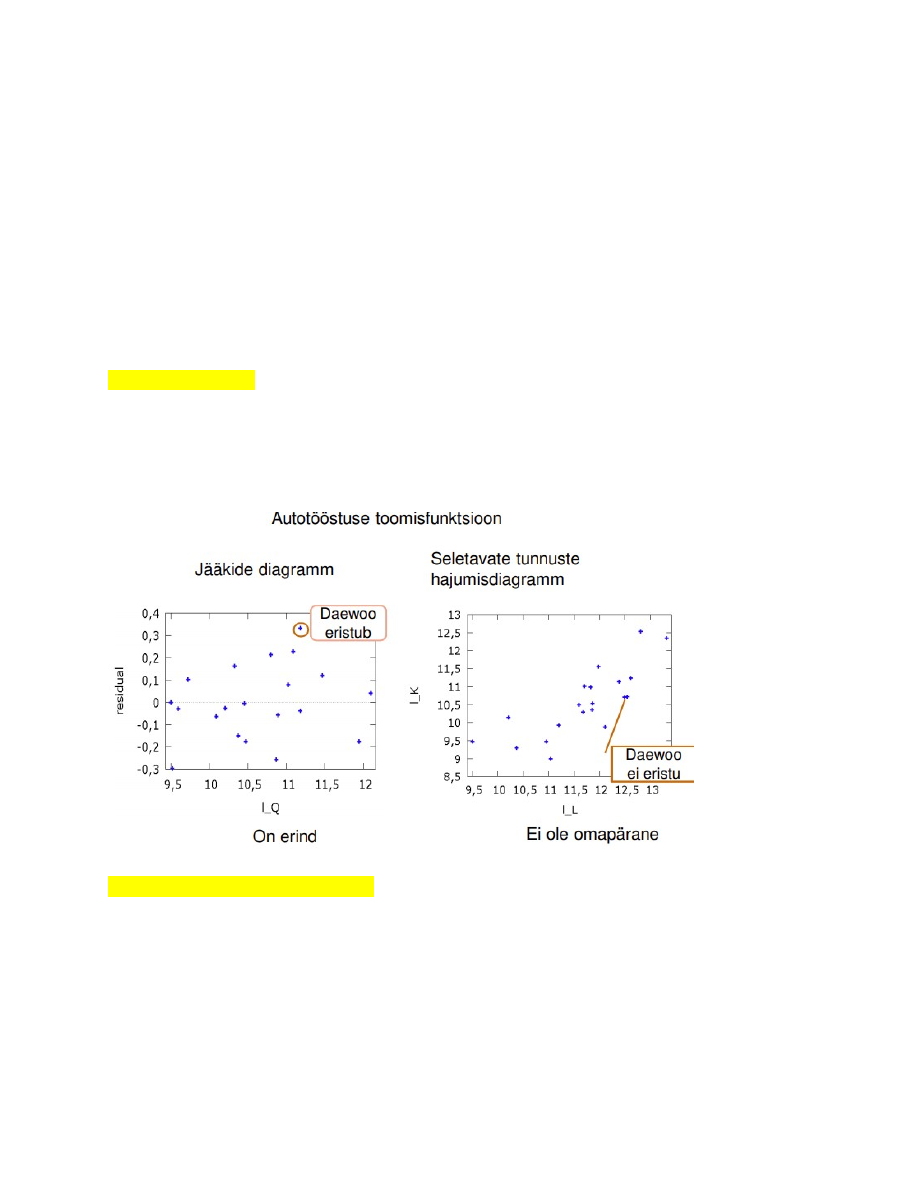
61. Mis on erind?
Erind (outlier) on sõltuva tunnuse suhtes, suure jäägiga.
● Nendes vaatluspunktides on probleem mudeli kehtivusega.
● Avastamiseks uurida jääkide diagramme.
● Kasutada standardiseeritud jääkide arvutamist
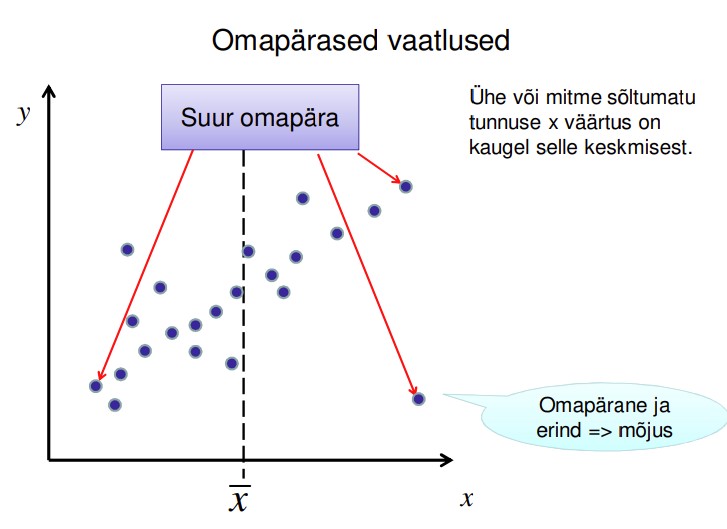
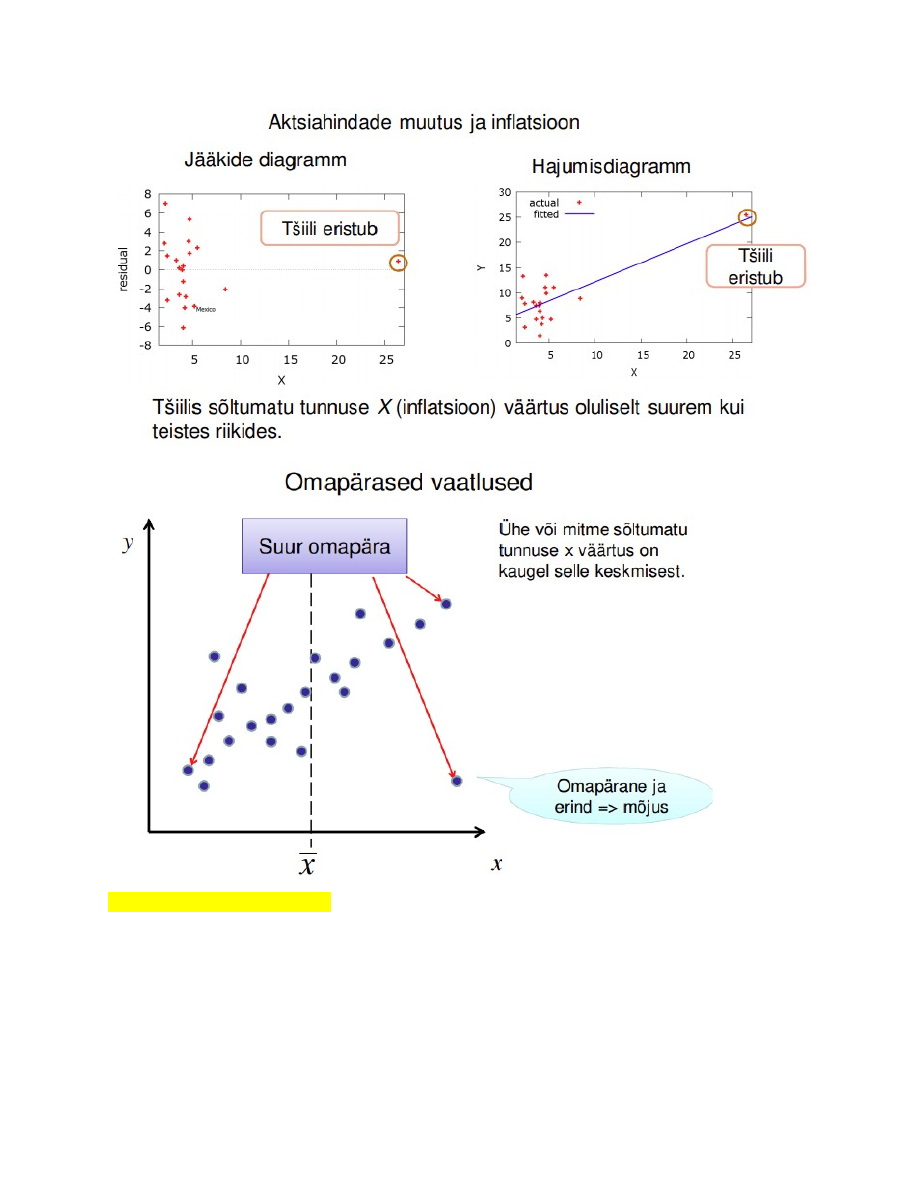
62. Mis on omapärane vaatlus?
Omapärane vaatlus (leverage): ühel või mitmel sõltumatul tunnusel ekstreemne väärtus.
● Võivad oluliselt mõjutada regressioonanalüüsi tulemust
● Kindlasti tuleb andmestikust välja jätta, kui ilmneb, et on tehtud mõõtmisvigu või
registreerimisvigu (valesti andmebaasi kantud)
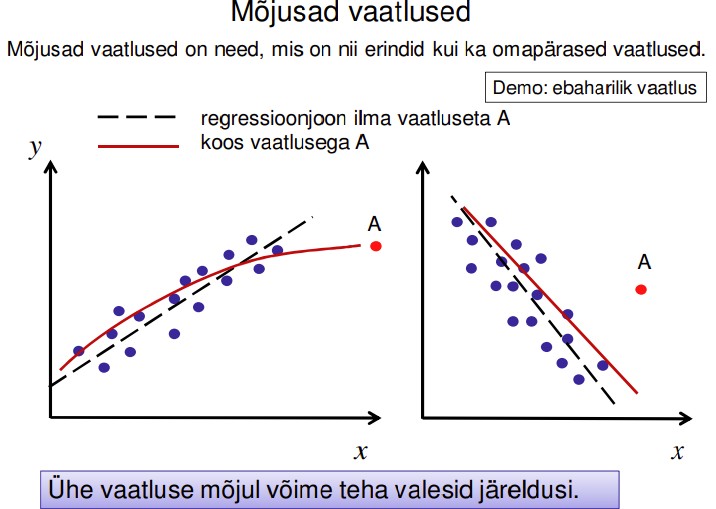
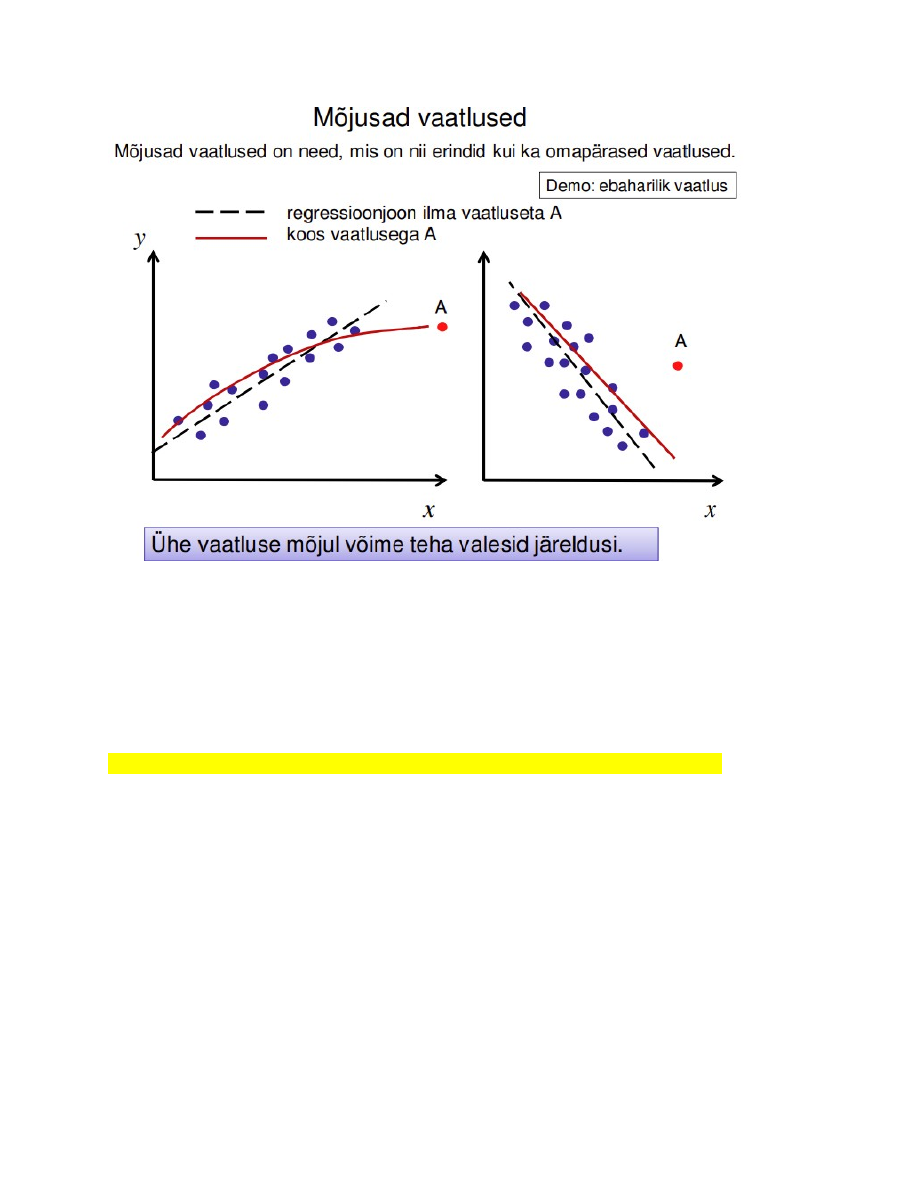
63. Mis on mõjus vaatlus?
Mõjus vaatlus (influential): nii erind kui ka omapärane vaatlus.
Suure jäägiga ja ühel või mitmel sõltumatul tunnusel ekstreemne väärtus
Kui standardiseeritud jäägi absoluutväärtus:
>2 ebatüüpiline
>3 erind
Programmis Gretl automaatselt ei arvutata.
Saab ise arvutada: salvestada jäägid ja luua uus tunnus: jääk / mudeli standardviga.
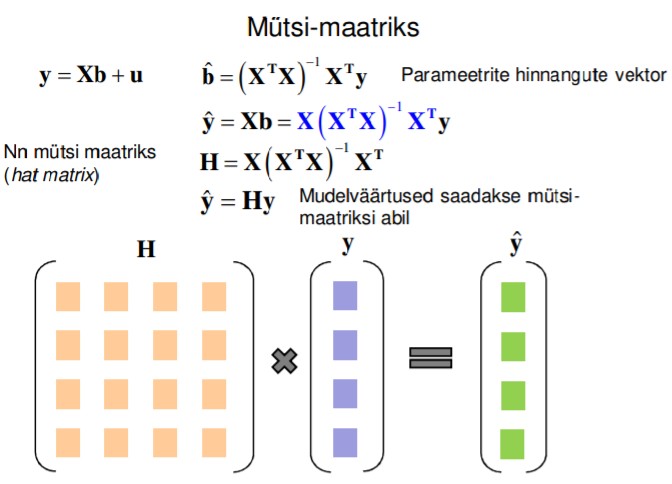
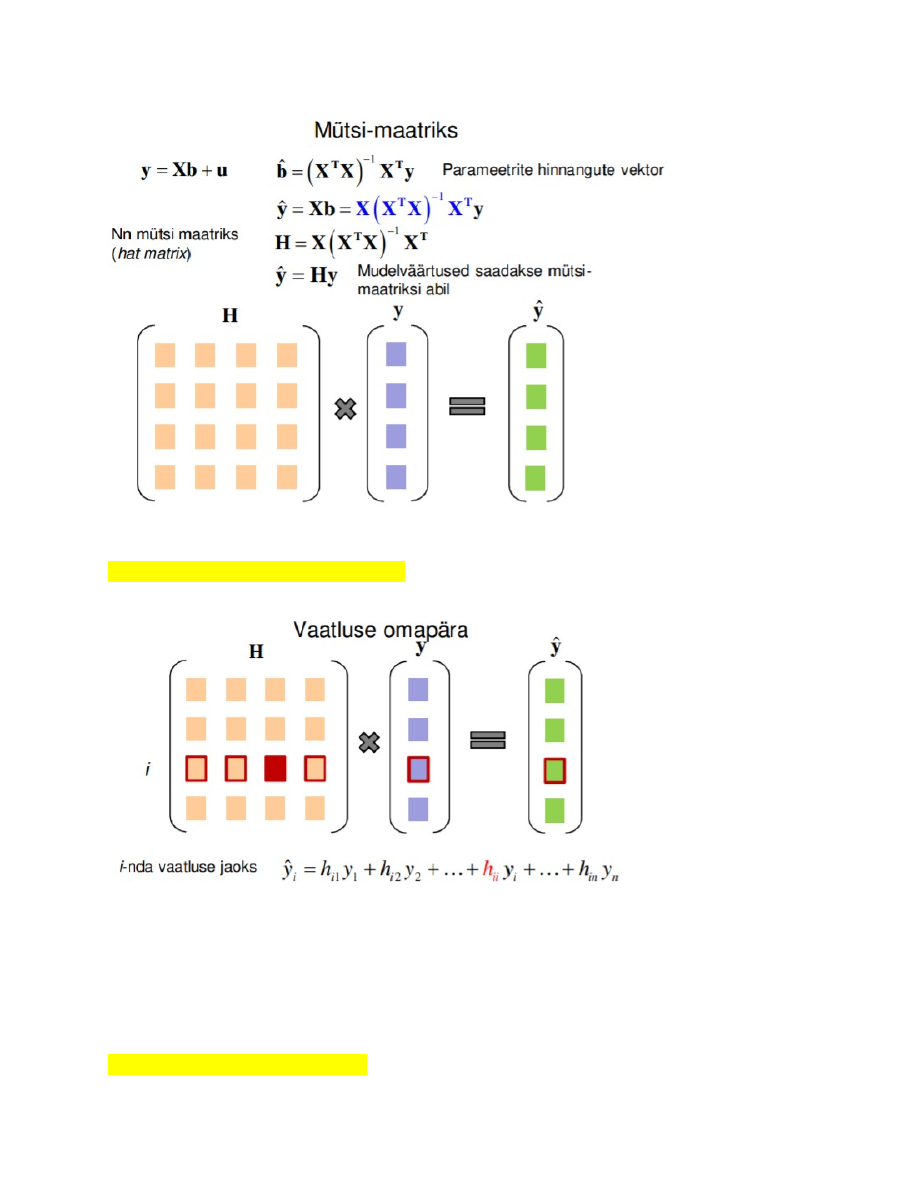
64. Milleks kasutatakse mütsi-maatriksit, mida see võimaldab arvutada?
Milleks kasutatakse mütsi maatriksit??? Mudelväärtuste leidmiseks?
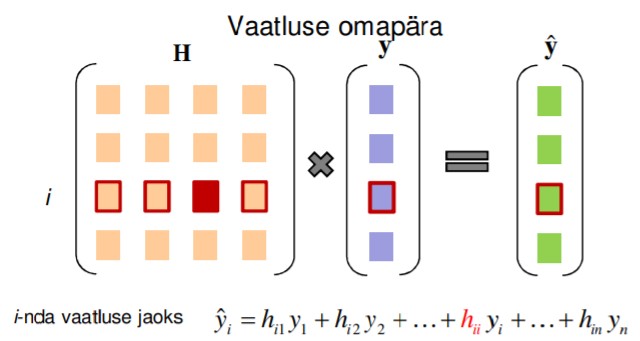
65. Mida näitab vaatluse omapära?
Mütsi-maatriksi diagonaalelement hii on i-nda vaatluse
omapära (leverage).
Omapära hi näitab i-nda vaatluse mõju sama vaatluse Y hinnangule.
0 < hi < 1
66. Mis on prognoositud jääk? • i-nda vaatluse jäägi võib leida ka siis, kui regressioonmudeli hindamisel jätame selle
vaatluse valimist välja.
• Sisuliselt on tegemist seletavatele tunnustele Xi vastava sõltuva tunnuse väärtuse
prognoosimisega ilma i-nda vaatluseta.
• Tähistame seda yi *
Prognoositud jääk
ui* = yi - yi*
Prognoositud jääk võimaldab hinnata, kuidas mudel prognoosib sõltuvat tunnust ilma i-
ndat vaatlust arvestamata.
• Kui prognoositud jäägid on suured, siis i-nda objekti sõltuva tunnuse
mudelväärtust ei saa ülejäänud vaatluste alusel piisavalt täpselt prognoosida.
• St see vaatlus ei sobi hästi sellesse mudelisse.
Deleted residuals, predicted residuals, jackniffe residuals
67. Multikollineaarsus, selle liigitus.
Multikollineaarsus esineb siis, kui regressorite vahel on lineaarne sõltuvus.
Ei tohi esineda täpset multikollineaarsust, aga võib esineda ligikaudne
multikollineaarsus.
Kui mudel ise on statistiliselt oluline, aga parameetrid on kõik statistiliselt mitteolulised,
on tõenäoliselt tegemist multikollineaarsusega.
Esineda võib kahte liiki multikollineaarsus:
● Prefektne multikollineaarsus - kaks või rohkem tunnust on omavahel lineaarselt
seotud
● Ligikaudne multikollineaarsus - Multikollineaarsuse all mõeldakse tavaliselt just
seda; ökonomeetriliste mudelite korral kõige problemaatilisem
68. Tugeva ligikaudse multikollineaarsuse ilmingud.
● Mudel on statistiliselt oluline, F-testi olulisuse tõenäosus on väike, aga enamus
tunnuseid statistiliselt mitteolulised, tunnuste standardvead suured
● Korrelatsioonikordajad sõltumatute tunnuste vahel on väga suured, suuremad kui
nende korrelatsioonikordaja sõltuva muutujaga.
● Parameetrite märgid ebaloogilised.
● Parameetrite hinnangud väga tundlikud
○ üksikute tunnuste lisamise või eemaldamise suhtes
○ vaatluste arvu suurenedes või vähenedes
Tugev ligikaudne multikollineaarsus tähendab, et sõltumatute tunnuste vahel on tugev,
kuid mitte perfektne lineaarne seos
Kui seos on tugev, siis selle determinatsioonikordaja R(abi) 2 on suur
69. Multikollineaarsuse tugevuse hindamine: variatsiooniindeks VIF ja selle
arvutamine.
, selle valemiga saab arvutada parameetrite varieeruvusindeksit
Multikollineaarsuse tugevus saab hinnata kolmel erineval moodusel:
● Korrelatsioonimaatriks (suure arvu regressorite korral ebamugav; näitab vaid
paarikaupa esinevat kollineaarsust)
● Varieeruvusindeks VIF (matemaatliliselt lihtsalt arusaadav; kasutame seda)
● Konditsiooniindeks (matemaatiliselt keerukam)
Varieeruvusindeks VIF
Gretlis Analysis>Collinearity
Kõik parameetrid, mille korral on väärtus oluliselt suurem kui 10, on tugevalt
multikollineaarsed. Kui väärtus on 10 lähedal, aga parameetrite märgid on loogilised,
siis võime ignoreerida.
Stadardvead ja VIF70. Mis juhtub parameetrite hinnangutega ja nende standardvigadega, kui esineb
multikollineaarsus?
Kui multikollineaarsus esineb, siis:
● parameetrite standardvead ja usaldusvahemikud on suured
● Parameetrite hinnangud on nihketa
● Parameetrite korrektne interpretatsioon pole võimalik
71. Mida teha multikollineaarsuse esinemise korral?
Saab
ignoreerida probleemi, kui
● Parameetrite märgid on loogilised
● Parameetrid on statistiliselt olulised
Saab
vähendada multikollineaarsust juhul, kui:
● Parameetrite märgid pole loogilised
● Parameetrid pole statistiliselt olulised
Multikollineaarsuse vähendamine:
● Jätta kollineaarne tunnus mudelist välja.
○ Sellega võib kaasneda mudeli kirjeldustaseme langus.
○ Tunnuste väljajätmisel mudelist tuleb jälgida, et välja ei jäetaks olulisi
tunnuseid, mille väljajätmisel võib saada nihkega hinnangud.
● Teisendada andmeid.
○ Näiteks kahe kollineaarse tunnuse asemel kasutada nende suhet.
● Suurendada valimi mahtu.
● Kasutada paneelandmeid.
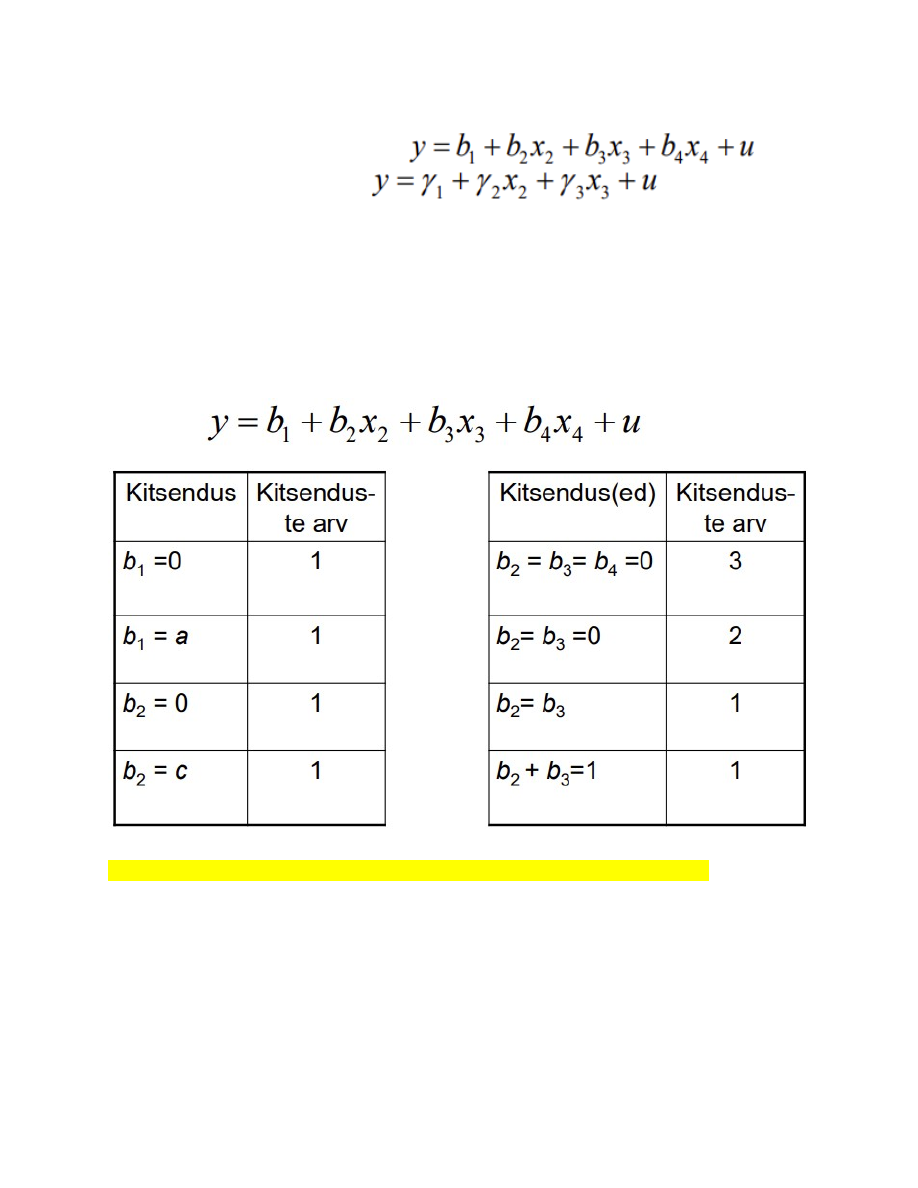
72. Kitsendused parameetritele, kitsendatud ja kitsendamata mudel. Kitsendamata mudel U (unrestricted)
Kitsendatud mudel R (restricted)
● Kitsendused kehtivad, kui erinevus nende mudelite kirjeldatavuse tasemes ei ole
oluline.
● Kui suur võib erinevus olla, et võiksime öelda: see pole oluline?
● Vaja kriteeriumi!
● Tuleb läbi viia F-test
Näiteid erinevatest lineaarsetest kitsendustest
73. Kitsenduste testimine F-testiga: nullhüpotees ja sisukas hüpotees.
H0 : erinevus pole oluline, kitsendused kehtivad
H1 : erinevus on oluline, kitsendused ei kehti
1. Mõlemat mudelit hinnatakse vähimruutude meetodil.
2. Hindamise käigus leitakse mõlema mudeli jaoks jääkide ruutude summa RSS(U)
ja RSS(R)
3. Arvutatakse F-statistik
Kus m - kitsenduste arv
N - valimi maht
K - parameetrite arv kitsendamata mudelis
Kui F<α), võetakse vastu sisukas hüpotees: mudel onF(kriitiline) või
p>a, siis võetakse vastu
H0: kitsendused kehtivad, kitsendatud
mudel pole halvem, võib kitsenduse panna
Kui F>F(kriitiline) või
p, siis võetakse vastu H1: kitsendused ei kehti, kitsendatud
mudel on oluliselt halvem
Gretlis mudeli aknas Tests>Linear restrictions
74. Tunnuste eemaldamise ja lisamise testimine kitsenduste F-testiga.
Tunnuste eemaldamine mudelist:
Kitsendamata mudel:
Kas tunnuse x2 võib mudelist eemaldada, ilma et mudel oluliselt halveneks?
Kitsendus:
b2=0
Kitsendatud mudel:
Kui kitsendatud mudel ei ole oluliselt halvem kitsendamata mudelist(H0), võib tunnuse
x2 eemaldada.
Testimiseks F-test.
Gretlis mudeli aknas Tests>Omit variables
Kui p>a, siis võtame vastu H0: kitsendatud mudel ei ole oluliselt halvem
Kui p<α), võetakse vastu sisukas hüpotees: mudel ona, siis võtame vastu H1: kitsendatud mudel on oluliselt halvem
Tunnuse lisamine mudelisse:
Kitsendatud mudel:
Kas tunnuse x4 lisamisel mudelisse mudel paraneb oluliselt?
Kitsendamata mudel:
Kitsendus:
Kui kitsendatud mudel on oluliselt parem kitsendamata mudelist (H1), võib tunnuse x2
lisada.
Testimiseks kitsenduste F-test.
Gretlis mudeli aknas Tests>Add variables
Kui p>a, siis võtame vastu H0: kitsendatud mudel ei ole oluliselt halvem
Kui p<α), võetakse vastu sisukas hüpotees: mudel ona, siis võtame vastu H1: kitsendatud mudel on oluliselt halvem
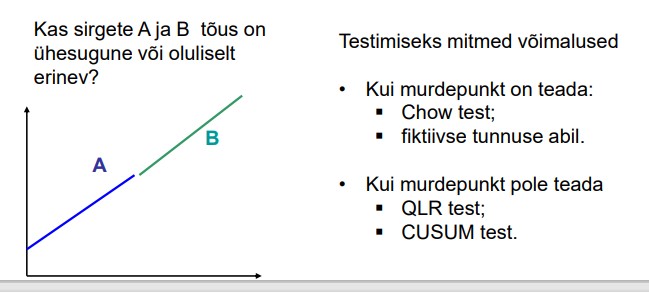
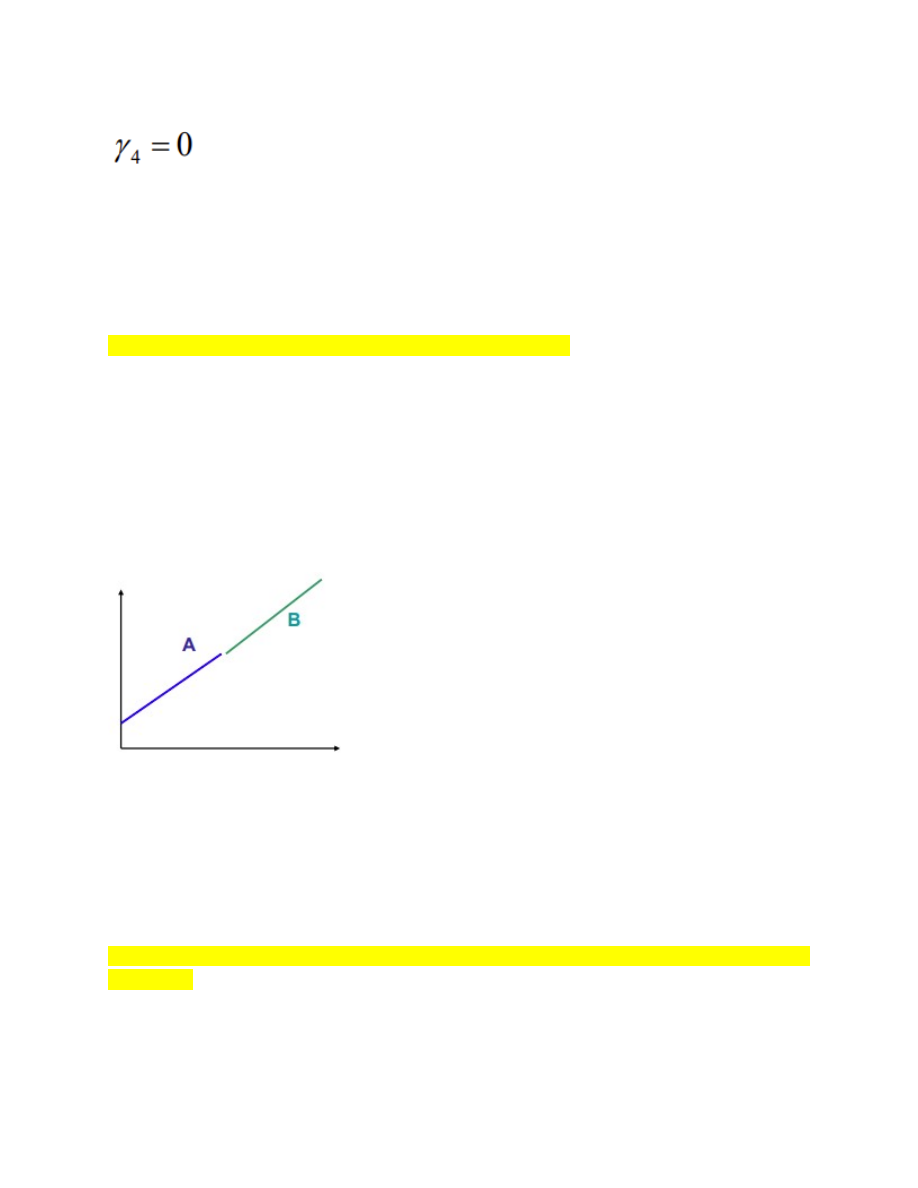
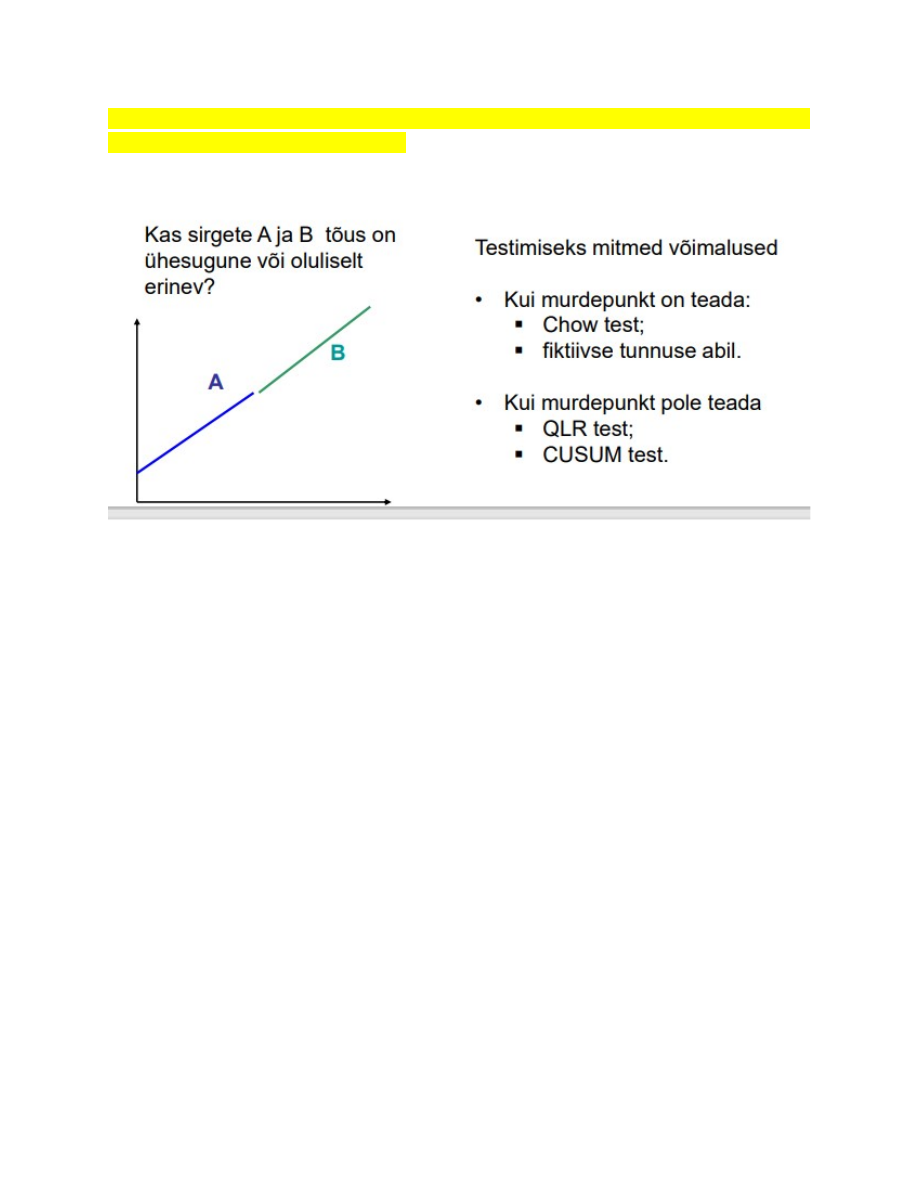
75. Mida tähendab parameetrite stabiilsuse testimine?
Soovime analüüsida, kas regressioonmudeli mingi parameetri väärtus on ühesugune
või erinev meie valimi kahes alamvalimis.
Näiteks:
● kas on erinevus arenenud riikide ja arenguriikide vahel;
● kas esineb erinevus kahel ajaperioodil
Ka struktuursete muutuste testimine
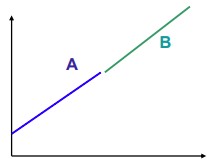
Kas sirgete A ja B tõus on ühesugune või oluliselt erinev?
Testimiseks mitmed võimalused:
Kui murdepunkt on teada:
● Chow test;
● fiktiivse tunnuse abil.
Kui murdepunkt pole teada
● QLR test;
● CUSUM test.
76. Chow test parameetrite stabiilsuse kohta: testi idee, nullhüpotees ja sisukas
hüpotees.
Gretlis mudeli aknas Tests>Chow test>murdepunkt
Struktuursete muutuste kontrollimiseks kasutatakse Chow testi.
Kui vastu võetakse H0, siis struktuurseid muutusi ei esine ning kitsenduse, et
parameetrid on ühesugused, võib peale panna.
H0: parameetrid on stabiilsed
H1: parameetrid ei ole stabiilsed, parameetrid muutuvad.
Kui p<α), võetakse vastu sisukas hüpotees: mudel ona, siis võetakse vastu H1 ehk esineb struktuutne muutus. Parameetrid muutuvad
Kui p>a, siis võetakse vastu H0 ehk parameetrid on stabiilsed.
(Kui Chow testi p>a, siis võtame vastu H0: sel aastal murdepunkti ei esine)
Kui võetakse vastu H1, siis tuleb mudelit hinnata kahes alamvalimis (algus-
(murdepunkt-1) ja murdepunkt-lõpp).
● Ristandmete korral saab Chow testi läbi viia mingi välja valitud tunnuse
muutumise suhtes.
● Objektid peavad andmebaasis olema reastatud selle tunnuse kasvamise (või
kahanemise) järgi.
● Valim tuleb kaheks jagada: ette tuleb anda objekti järjenumber, millise objekti
juures kaheks jagatakse.
77. QLR test struktuursete muutuste testimisel: testi idee, nullhüpotees ja sisukas
hüpotees.
Gretlis mudeli aknas Tests>QLR test
Struktuursete muutuste murdepunkti avastamiseks viiakse läbi QLR test
● QLR (Quandt likelihood ratio) testi korral leitakse Chow testi Fstatistiku väärtus
järjest erinevate murdepunktide (break-points) τ jaoks.
● Valitakse see murdepunkt, mille korral F-statistiku väärtus on kõige suurem.
Teststatistik on maksimaalne F-statistiku väärtus:
● Test annab õiged tulemused siis, kui murdepunkt on piisavalt kaugel vaadeldava
perioodi algusest või lõpust.
○ Tavaliselt võetakse mõlemalt poolt 15%, st F-statistik leitakse 70% valimi
keskel olevate potentsiaalsete murdepunktide jaoks.
● Kui võrreldakse korraga mitmeid F-statistiku väärtusi, ei saa kriitilise väärtuse
leidmiseks kasutada F-jaotust. Kasutada tuleb mittestandardset jaotust
(Andrews)
H0: ei esine struktuurseid muutusi
H1: esineb struktuurseid muutusi
Kui p>a, siis võtame vastu H0: ei esine struktuurseid muutusi.
Kui p, siis võtame vastu H1: esineb struktuurseid muutusi.
QLR test annab ka suurima F väärtuse.
Murdepunktide läbimine QLR testi korral
Näiteks aegrea pikkus (valimi maht) T=20.
F-statistik leitakse valimi keskel oleva 14 perioodi (potentsiaalse) murdepunkti jaoks.
78. Rekursiivne hindamine ja CUSUM test: nullhüpotees ja sisukas hüpotees.
● Algul hinnatakse mudelit väikese alamvalimi põhjal.
○ Alustatakse valimist mahuga r +1, kus r on parameetrite arv mudelis.
● Hinnatud mudeli põhjal leitakse järgmise vaatluse silutud väärtus.
● Kuna järgmise vaatluse tegelik väärtus on teada, leitakse jääk.
● Nüüd võetakse valimisse ka järgmine vaatlus ning leitakse parameetrite
hinnangud 1 võrra suurema valimi põhjal.
● Leitakse järgmise vaatluse jääkliige.
● Niimoodi jätkatakse, kuni kõik vaatlused on kaasa haaratud.
● Saab kasutada aegridade korral ja mingi tunnuse abil järjestatud ristandmete
korral.
● Tulemusi saab uurida visuaalselt.
● Testimiseks on olemas sobivad statistikud
CUSUM test
Gretlis mudeli aknas Tests>CUSUM test
Rekursiivse hindamise alusel on välja töötatud CUSUM test. Test põhineb rekursiivse
hindamise jääkliikmete ut normaliseeritud kumulatiivsel summal.
se - mudeli standardviga (terve valimi põhjal)
r - mudeli parameetrite arv
n - valimi maht
Kui struktuurseid muutusi pole, siis summad Wp alluvad normaaljaotusele
keskväärtusega 0: Wp ~ N(0, p-r)
Testimiseks Harvey-Collier statistik.
H0 : struktuursed muutused puuduvad
H1: esinevad struktuursed muutused, parameetrid pole konstantsed
Märkus: teine test, CUSUMSQ test, on sobiv jääkliikmete dispersiooni testimiseks.
Harvey-Collier p-value!
Kui p>a, siis võetakse vastu H0: ei esine struktuurseid muutusi
p<α), võetakse vastu sisukas hüpotees: mudel ona, siis võetakse vastu H1: esinevad struktuursed muutused
Rekursiivne hindamine: valimi suurendamine
79. Mudeli spetsifikatsioonivigade liigitus.
1. Mudelis on mõni ebaoluline tunnus.
2. Mõni oluline tunnus on välja jäänud.
3. Mudeli funktsionaalne kuju on vale.
80. Mis juhtub, kui mudelist on oluline tunnus välja jäänud?
Kui jätame välja olulise tunnuse:
● Nihkega on ainult nende tunnuste kordajad, mis on korrelatsioonis välja jäänud
tunnusega.
● hinnangud ei ole mõjusad
● hüpoteeside testimine annab valesid tulemusi
● prognoosid tulevad valed.
Aga, nihkega on ainult nende tunnuste kordajad, mis on seotud (korrelatsioonis) välja
jäänud tunnusega.
Oluline tunnus on välja jäänud:
● Kui X2 ja X3 vahel esineb mõningane korrelatsioon, siis mudeli (2) parameetrite
hinnangud on nihkega ja ei ole mõjusad.
● Kui X2 ja X3 vahel korrelatsioon puudub on vabaliikme a1 hinnang nihkega
● Juhusliku vea dispersiooni hinnang on ebaõige
● Parameetrite standardhälvete hinnangud on nihkega
● Järelikult hüpoteeside testimise protseduurid ei võimalda teha õigeid järeldusi
parameetrite olulisuse kohta.
● Kuna hinnangud on nihkega, tulevad valed prognoosid ja valed usalduspiirid.
81. Mis juhtub, kui mudelis on sees mitteoluline tunnus?
1. Parameetrite hinnangud on nihketa
2. Hinnangud võivad olla mõjusad
3. Parameetrite standardvead on suuremad kui võrreldaval mudelil
4. hinnangud ei ole efektiivsed
5. hüpoteeside testimine võib anda valesid tulemusi.
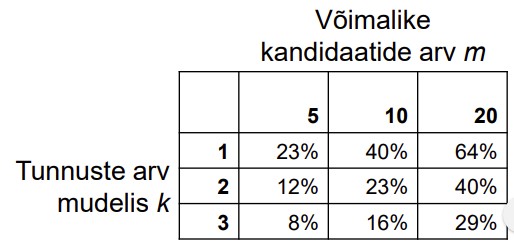
82. Mis on nominaalne ja tegelik olulisuse nivoo?
● Olgu meil võimalike seletavate tunnuste kandidaate m tükki.
● Nendest valitakse välja k tunnust, mis lülitatakse mudelisse.
● Iga tunnuse olulisuse hindamiseks eraldi kasutatakse olulisuse nivood α (see on
nominaalne olulisuse nivoo).
● Siis tegelik olulisuse nivoo
Paljude võimalike tunnuste korral ei anna kasutatav nominaalne olulisuse nivoo
parameetrite statistilise olulisuse hindamisel kokkuvõttes tõelist tulemust.
Tegelik olulisuse nivoo mõningatel juhtudel, kui nominaalne olulisuse nivoo on 5%.
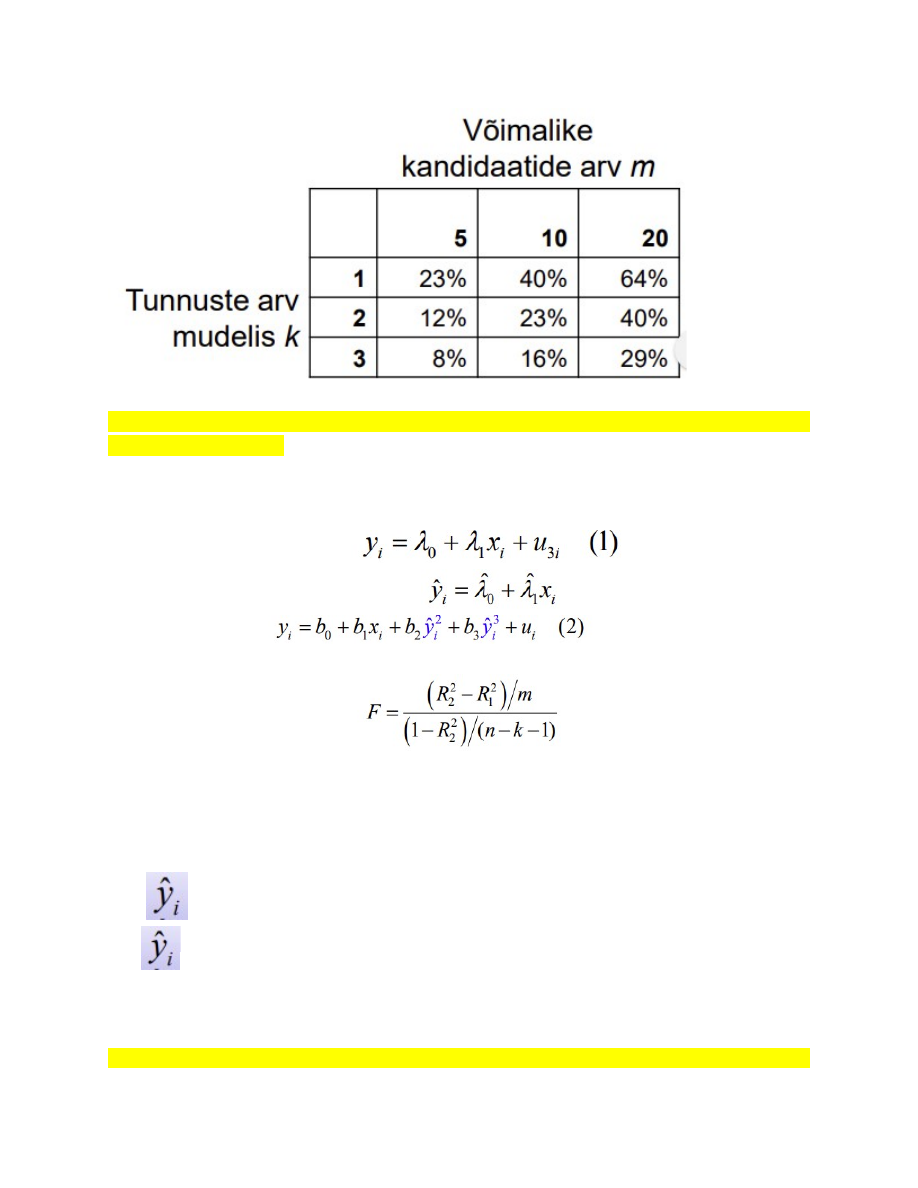
83. Mudeli funktsionaalse kuju hindamine RESET testiga: testi idee, nullhüpotees
ja sisukas hüpotees.
Ramsey (1969) pakkus välja mudeli spetsifikatsioonivigade testi ehk RESET testi
(regression specification error test).
1. Hindame lineaarset mudelit
2. Mudelist (1) leiame silutud väärtused
3. Hindame mudelit
4. Leiame F-statistiku
R1 2 ja R2 2 on vastavalt mudelite (1) ja (2) determinatsioonikordajad
n – valimi maht,
m - uute regressorite arv mudelis (2),
k – tunnuste arv kokku mudelis (2)
H0 :
lisamine ei parandanud mudelit oluliselt, mudeli kuju on õige.
H1:
lisamine parandas mudelit oluliselt, mudeli kuju on vale.
Kui F > Fkr (p<α), võetakse vastu sisukas hüpotees: mudel onα), võtta vastu H1 . Siis on mudeli (1) kuju on vale.
Gretlis Tests -> Ramsey’s RESET squares and cubes
84. Mis on fiktiivsed tunnused ja kuidas neid kasutatakse kvalitatiivsete tunnuste
mudelisse panekuks?
● Fiktiivne ehk binaarne tunnus on kaheväärtuseline tunnus, mis võib omada
väärtusi 0 või 1 ning mis vastab kvalitatiivse tunnuse kindlale tasemele.
● Fiktiivsete tunnuste arv mudelis on ühe võrra väiksem kvalitatiivse tunnuse
tasemete arvust. Väärtus, mille fiktiivset tunnust mudelis pole, on baasväärtus.
85. Mis on baaskategooria?
Baaskategooria moodustab see, mis tunnus on mudelist väljas. Kui on 3 seletavat
tunnust, siis 1 kategooria võetakse baaskategooriaks ning 2 kategooriat on fiktiivsed
tunnused
86. Mis on ANOVA mudel ja ANCOVA mudel?
ANOVA
Tüüpiline regressioonmudel sisaldab:
● Kvantitatiivseid seletavaid tunnuseid
● Kvalitatiivseid seletavaid tunnused
Mõlemat tüüpi seletavaid tunnuseid sisaldav mudel on ANCOVA mudel,
ANCOVA mudel võimaldab hinnata ka kvantitatiivsete seletavate tunnuste mõju. Need
on kovariandid ehk ühismuutujad (covariates, concomitant variables). – Ühismuutujad,
sest on ühised kõigile kvalitatiivse tunnuse kategooriatele.
87. Fiktiivsete tunnuste kordajate tõlgendamine.
Fiktiivseete tunnuste tõlgendamise näide (vt IPodi näidet)
88. Fiktiivsete tunnuste mitteolulisus ja tunnuste komplekti eemaldamise
testimine.
● Ära eemalda üht fiktiivset tunnust, kuna see ei ole eraldi tunnus, vaid vastab
ühele väärtusele!
● Kui eemaldad, siis eemalda terve komplekt!
● Pane peale kitsendus: D1 = 0, D2 = 0, D3 = 0!
● Test -> Omit variables
● Kui p <α), võetakse vastu sisukas hüpotees: mudel on 0,05 -> siis kitsendust ei tohi peale panna, kuna mudel halvenes oluliselt
89. Struktuursete muutuste testimine fiktiivse tunnuse abil: testi idee,
nullhüpotees ja sisukas hüpotees, neli võimalikku tulemust.
Tests - > Chow test -> Määra ajahetk, kus esineb murre.
H0 - parameetrid on stabiilsed - ära muuda mudelit - p > 0,05
H1 - Parameetrid ei ole stabiilsed - mudeli hindamine tuleb viia läbi kummaski alavalimis
eraldi p <α), võetakse vastu sisukas hüpotees: mudel on 0,05
Testid, mis uurivad terve valimi läbi:
● QLR (quandt likelihood ratio) test
● Rekursiivne hindamine RLS (recursive least squares)
○ CUSUM test
○ CUSUMSQ test
90. Tunnuste koosmõju: kuidas hinnata, tõlgendamine.
91. Sesoonsuse hindamine fiktiivsete tunnuste abil.
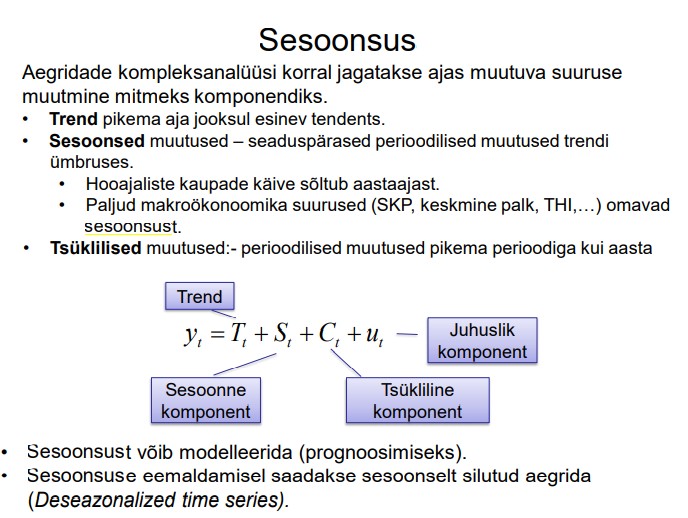
Sesoonsus - aegridade kompleksanalüüsis korral jagatakse ajas muutuva suuruse
muutmine mitmeks komponendiks.
Add -> observation range dummy - > lisada mudelisse ainult 3 dummyt - 4 jääb baas
mudeliks.
Ülesanded (praktiline andmeanalüüs)
1. Lineaarse mudeli hindamine vähimruutude meetodil.
Model>OLS ???
Vähimruutude meetodi korral minimeeritakse sirge ja üksikute punktide vaheliste y-telje
sihiliste hälvete ui ruutude summat.
2. Regressioonmudeli hindamise aruande tõlgendamine:
● parameetrite hinnangud;
Parameetrite hinnangud leitakse vähimruutude meetodil (OLS).
Parameetri a hinnang ja parameetri b hinnang (vabaliige)
● parameetrite standardvead;
● parameetrite t-statistikud;
Parameetrite t-statistikud on gretlis t-ratio all.
● t-statistikute olulisuse tõenäosused;
Parameetrite t-statistikute olulisuse tõenäosused on p-value all.
● mudeli statistilise olulisuse F-test;
P-value (F)
● determinatsioonikordaja;
R-squared
● korrigeeritud determinatsioonikordaja;
Adjusted R-squared
● Durbin-Watsoni statistik.
Durbin-Watson Gretl Tools->Statistical Tables->DW
3. Parameetrite statistilise olulisuse testimine.
Parameetrite
statistilise
olulisuse
testimine:
Nullhüpotees H0 : bj = 0 ehk parameetrid on statistiliselt mitteolulised
Sisukas hüpotees H1 : bj ≠ 0 ehk parameetrid on statistiliselt olulised
Kui t-statistiku väärtus ületab kriitilise (olulisuse tõenäosus p on väiksem kui olulisuse
nivoo α), on vastav parameeter oluliselt nullist erinev: tunnuse lülitamine mudelisse on
põhjendatud. Kui p<α, siis võetakse vastu H1
Vastupidisel juhul tuleb tunnus mudelist eemaldada ja viia läbi uue mudeli hindamine.
4. Mudeli statistilise olulisuse testimine.
H0: kõik seletavate tunnuste kordajad on nullid, b2=b3=… =bk =0
H1 vähemalt üks kordaja b2 , b3 …., bk on nullist erinev ehk mudel on statistiliselt
oluline
Nullhüpotees: Y on määratud oma keskväärtusega
F-statistiku empiirilist väärtust võrreldakse F-jaotuse kriitilise väärtusega (või
empiirilisele väärtusele vastavat olulisuse tõenäosust p võrreldakse olulisuse nivooga
α).
Kui empiiriline väärtus ületab kriitilise (p<α), võetakse vastu sisukas hüpotees: mudel on
statistiliselt oluline
5. Tunnuste lisamine ja eemaldamine.
Tunnuseid tuleb lisada/eemaldada ükshaaval. Kõigepealt tuleb tunnused järjestada
kõige tugevama seose järgi.
Gretlis View>Correlation matrix>kõik tunnused peale y.
6. Korrigeeritud determinatsioonikordaja kasutamine.
Lisades mudelisse uusi tunnuseid, peab vaatama korrigeeritud
determinatsioonikordajat. Kui uue parameetri lisamisel korrigeeritud
determinatsioonikordaja suureneb, siis mudel paraneb ja saame jätkata. Kui aga
korrigeeritud determinatsioonikordaja väheneb, siis tuleb uus tunnus mudelist
eemaldada ja jätkata vanaga.
7. Heteroskedastiivsuse testimine (White’i test).
Mudel (kui OLS on tehtud juba): Tests>Heteroskedasticity>White’s Test
Kui esineb heteroskedastiivsus, siis logaritmida tunnuseid. Kui peale logaritmimist ei
kao heteroskedastiivsus ära, siis kasutage kohandatud standardvigade hinnanguid.
H0: mudelis ei esine heteroskedastiivsust
H1: heteroskedastiivsus esineb
Kui p>α, siis vastu võtta H0: heteroskedastiivsust ei esine!
Heteroskedastiivsuse testimisel kasutatakse abiregressiooni. Selle abiregressiooni
sõltuv tunnus on mudeli jääkliikmete ruudud, sest jääkliikmete dispersioon on määratud
jääkliikmete ruutudega.
8. Jääkide autokorrelatsiooni testimine: Durbin-Watsoni statistiku kasutamine ja
Breusch-Godfrey test.
H0: autokorrelatsioon puudub
H1: autokorrelatsioon esineb
Breusch-Godfrey test:
Gretlis Tests>Autocorrelation>Lag order to test X. Kui valimi maht on väike,
vaadatakse LMF p-valued.
LMF statistiku p>a, võtame vastu H0: autokorrelatsioon puudub
LMF statistiku p, võtame vastu H1: autokorrelatsioon esineb
Durbin-Watsoni statistiku kasutamine:
Mudeli parempoolne viimane näitaja (Durbin-Watson).
Leida Durbin-Watsoni alumine ja ülemine kriitiline väärtus (Tools>Statistical
tables>DW)
(sisestame mudeli alusel valimi mahu ja mitu regressorit (v.a const) mudelis on.
Kui esineb jääkliikmete 1. järku autokorrelatsioon, siis mida võib teha?
●
Püüda autokorrelatsioonist vabaneda (nt lisada tunnuseid, viitaegu)
●
Kasutada mõnd autokorrelatsiooni eemaldamise protseduuri
●
Kasutada kohandatud standardvigu
Millised
on
Durbin-Watsoni
statistiku
puudused
* teatud väärtuste korral pole võimalik otsustada, kas autokorrelatsioon esineb või mitte
* sõltub ainult vahetult üksteisele järgnevatest jääkliikmetest ut ja ut-1
9. Jääkide normaaljaotuse testimine: Doornik-Hansoni test.
H0: jääkliikmed alluvad normaaljaotusele
H1: jääkliikmed ei allu normaaljaotusele
Kui DH empiiriline väärtus ei ületa kriitilist väärtust (p>a), siis võetakse vastu H0:
jääkliikmed alluvad normaaljaotusele
Kui DH empiiriline väärtus ületab kriitilise väärtuse (p<α), võetakse vastu sisukas hüpotees: mudel ona), siis võetakse vastu H1:
jääkliikmed ei allu normaaljaotusele
Gretlis mudeli aknas Tests>Normality of residual
Teststatistik DH
10. Mudeli kuju testimine: RESET test.
Gretlis Tests>Ramsey’s test
Reset testi p-value
Kui p>a, siis võetakse vastu H0: mudeli kuju on õige
Kui p<α), võetakse vastu sisukas hüpotees: mudel ona, siis võetakse vastu H1: mudeli kuju on vale
11. Tunnuste lisamise või eemaldamise F-test.
Fiktiivsete tunnuste eemaldamine:
Gretlis mudeli aknas Tests>Omit variables
Kui p>a, siis võtame vastu H0: kitsendatud mudel ei ole oluliselt halvem
Kui p<α), võetakse vastu sisukas hüpotees: mudel ona, siis võtame vastu H1: kitsendatud mudel on oluliselt halvem
Fiktiivsete tunnuste lisamine:
Gretlis mudeli aknas Tests>Add variables
Kui p<α), võetakse vastu sisukas hüpotees: mudel on0,05 -> H1: tegevusala on statistiliselt oluline
Tavaliselt tunnuste eemaldamise/lisamise puhul peab eemaldamisel eemaldama
kõige suurema p-valuega tunnuse. Lisamisel tuleb lisada kõige suurema
korrelatsiooniga tunnused. View>Correlation
12. Parameetrite stabiilsuse (struktuursete muutuste) testimine: Chow test, QLR
test, CUSUM test.
Kui murdekoht on teada:
● Chow test
● Fiktiivse tunnuse abil
Kui murdepunkt pole teada
● QLR test
● CUSUM test
‘
Kui p>a, siis võtame vastu H0: Parameetrid on stabiilsed
Kui p <α), võetakse vastu sisukas hüpotees: mudel on a, siis võame vastu H1: Parameetrid ei ole stabiilsed, tuleb kahte mudelit eraldi
hinnata.
Test-> QLR
13. Uute tunnuste arvutamine: logaritmimine, ruutu võtmine, diferentside
leidmine.
Valin tunnuse(d) ning Gretlis menüüst valin:
Add>logs of selected variables
Add>squares of selected variables
Add>Seasonal difference of selected variables
14. Lineariseeritud mudelite hindamine (log-log, log-lin, ruutpolünoom).
Log-log mudeli kordaja näitab, mitu % muutub Y, kui X suureneb 1% .
See on elastsuskordaja.
Add - > Logs of selected variables - > Lisa mudelisse
Struktuursete muutuste kontrollimiseks kasuta CUSUMi testi:
Tests - > Cusum test
Kui p > 0, võta vastu H1 esinevad struktuursed muutused, parameetrid pole
konstantsed
Kui p < 0, võta vastu H0 ei esine struktuurseid muutusi
15. Valimi kitsendamine (alamvalimi tekitamine).
Soovime analüüsida, kas regressioonmudeli mingi parameetri väärtus on ühesugune
või erinev meie valimi kahes alamvalimis:
Näiteks: – kas on erinevus arenenud riikide ja arenguriikide vahel;
– kas esineb erinevus kahel ajaperioodil.
16. Fiktiivsete tunnuste loomine ja nende kasutamine mudelis.
Kontrolli esiteks, kas tunnus on diskreetne - > Right click tunnuse peale - > edit
attributes -> linnkue: treat this variable as discrete ja numeric values represent an
encoding. -> Add -> Dummies for discrete variables
Kontrolli kas võib mudelisse lisada -> test -> Add variables,
kui p<α), võetakse vastu sisukas hüpotees: mudel on0,05 -> H1: tegevusala on statistiliselt oluline
17. Mudeli parameetrite tõlgendamine erineva kujuga mudelite korral: lineaarne,
log-log, log-lin, ANCOVA.
18. Arvutused mudeli järgi, mudelväärtuse leidmine.
19. Determinatsioonikordaja tõlgendamine.
Determinatsioonikordaja näitab, kui suur osa koguhajumisest on mudeli poolt ära
seletatud.
20. Eeldused kokkuvõtlikult























































































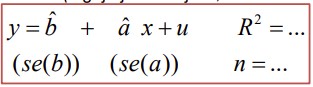


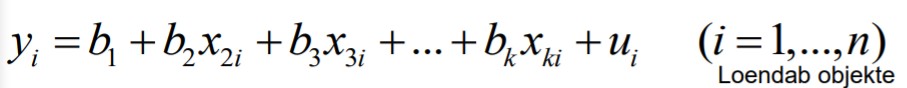

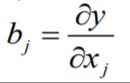
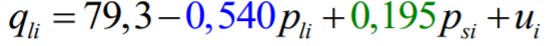

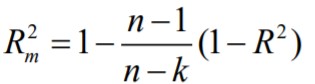


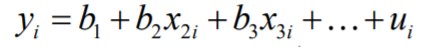
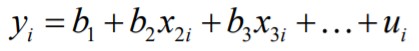

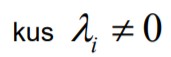
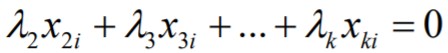
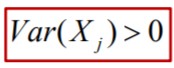
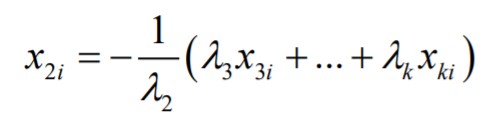
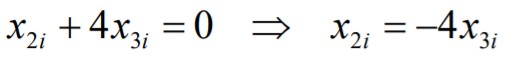


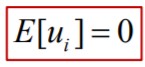
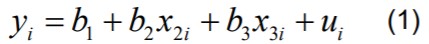
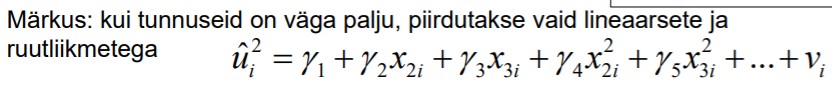
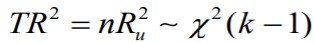
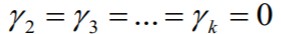
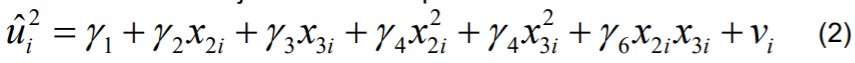

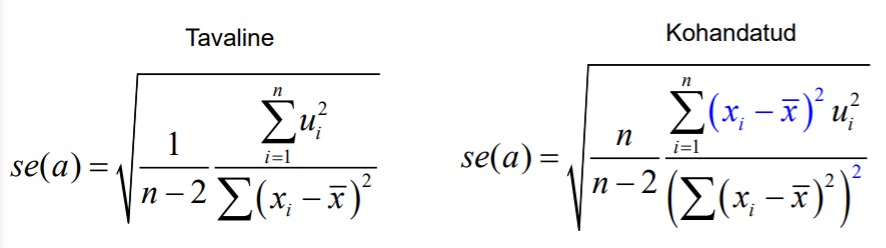
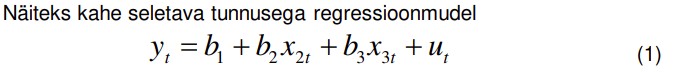

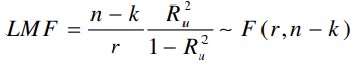
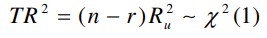

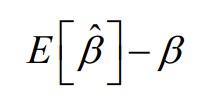
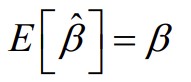




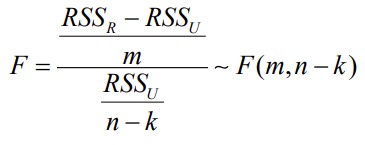
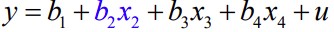
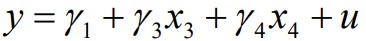
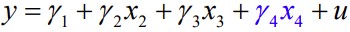

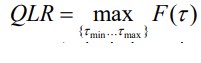

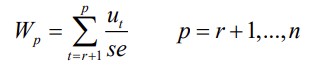

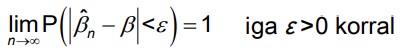

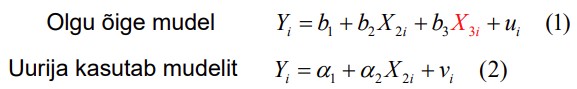

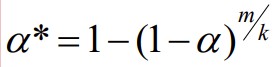
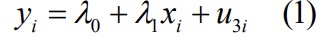
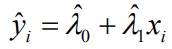
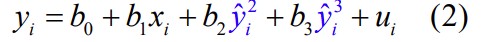
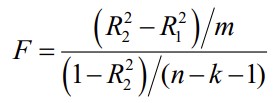
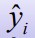




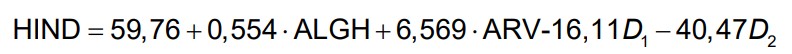












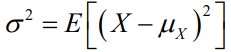
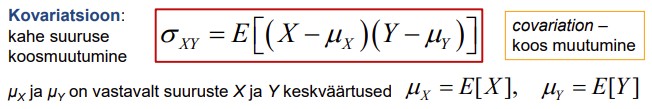
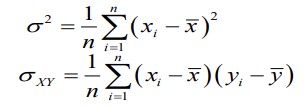
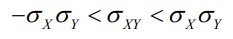
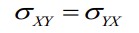
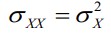
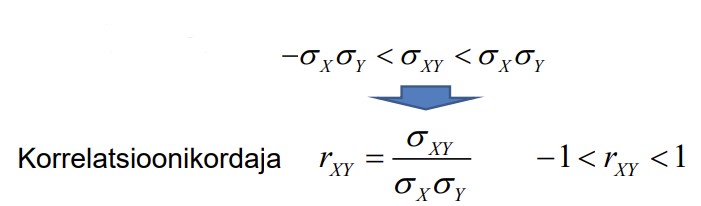
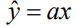

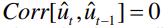
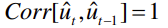
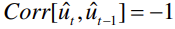


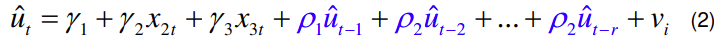

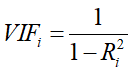
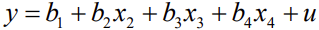
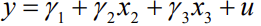
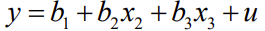
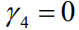
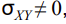
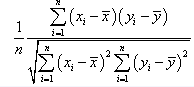

















































Kõik kommentaarid