ANVOA või regressioonanalüüs Kui meil sõltumatu muutuja koosneb kategooriatest, siis on parem kasutada ANOVA't. Kui sõltumatu muutuja on pidev tunnus, siis on parem kasutada regressiooni. ANOVA'ga hinnatakse gruppide keskmiste erinevust. Regressiooniga saab ennustada sõltuva muutuja väärtust prediktori (sõltumatu muutuja) väärtuste põhjal. Efekti suurus Efekti suurus on statistiline näitaja, mis võimaldab lisaks statistilisele olulisusele kirjeldada gruppidevahelisi erinevusi. Efekti suurust saab väljendada mitmete statistikutega; ilmselt levinuim on Cohen-i d. Kokkuleppeliselt tähistavad Cohen'i d väärtused väikest efekti väärtusel d = 0.2; keskmise suurusega efekti väärtus on d = 0.5; suure efekti väärtuse algus on d = 0.8. SPSS-is ei ole funktsiooni/käsklust, millega saaks paari kliki abil efekti suurust (st Coheni d-d) kätte.
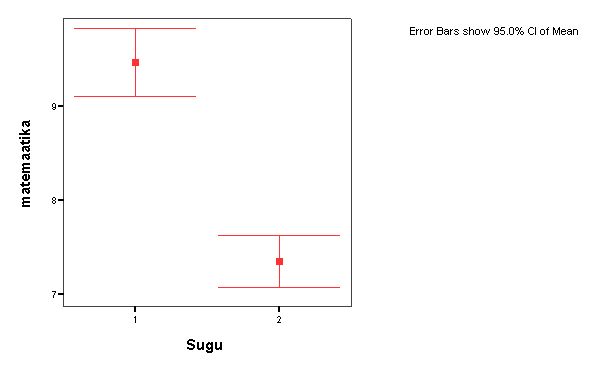
- Tunnuse, mille järgi toimub rühmitamine, valite aknasse: Factor - Aknast Post Hoc, teete linnukese kastidesse LSD ja Bonferroni (need on gruppide võrdlemise erinevad meetodid) ehkki ANOVA näitab, kas gruppide vahel on erinevusi, näitavad post hoc testid, mis gruppide vahel on erinevused. - Options aknast teete linnukese Descriptive ja Homogenity of the variance test juurde EFEKTI SUURUSE ARVUTAMINE Efekti suurusvi on statistiline näitaja, mis võimaldab lisaks statistilisele olulisusele kirjeldada gruppidevahelisi erinevusi. Efekti suurust saab väljendada mitmete statistikutega; ilmselt levinuim on Cohen-i d. Kokkuleppeliselt tähistavad Cohen'i d väärtused väikest efekti väärtusel d = 0.2; keskmise suurusega efekti väärtus on d = 0.5; suure efekti väärtuse algus on d = 0.8. SPSS-is ei ole funktsiooni/käsklust, millega saaks paari kliki abil efekti suurust kätte. Seega on mõned alternatiivid
Statistiline modelleerimine – kokkuvõte Muutujad: Sõltuvad muutujad (dependent, outcome variables) – muutujad, mis on uurimise keskmes, millele uurija arvab, et teised muutujad mõju avaldavad. Nö katseisikust sõltuv muutuja. Sõltumatud muutujad (independent, predictor variables) – muutujad, mille kohta uurija arvab, et neil võiks olla mõju uuritavatele muutujatele. Statistilise analüüsi keskmes on uurida, kuidas teatud tunnused koos muutuvad. Kui on vaja muutujat iseloomustada, on kaks põhilist viisi, kuidas seda teha: o Milline on selle muutuja tüüpiline väärtus? o Kui hästi iseloomustab see tüüpiline väärtus kõiki mõõdetud juhtumeid? Ehk kui palju on varieeruvust selle tüüpilise väärtuse “ümber”? Statistika jagunemine: Kirjeldav statistika (descriptive stat.) meetodid andmetest kokkuvõtete tegemiseks ning kirjeldamiseks. („65-70% U
Gretl - Gnu Regression, Econometrics and Time Series Library Gretl on avatud koodil põhinev vabavara, mida võib legaalselt installeerida oma kodusesse arvutisse või sülearvutisse. Programmi koduleht http://gretl.sourceforge.net/ TÖÖ PROGRAMMIGA Gretl Käivitada programm – avaneb menüü 1. Andmete importimine – File → Open data → Import → nimi.xlsx. Selleks et oleks võimalik andmetabelit Gretl-isse importida tuleb tabel eelnevalt sobivale kujule viia: a) kontrollida, et Exceli tabeli esimeses reas oleksid muutujate nimed (ei peaks sisaldama täpitähti) ning teisest reast alates andmed. sulgeda Exceli fail; b) avada programm Gretl; c) valida File/Open data/Import/Excel d) otsida Exceli fail (muuta Files of type) e) valida, mitmendast veerust ja reast importimist alustatakse f) näidatakse töölehtede , muutujate ja vaatlustulemuste arv g)
TALLINNA TEHNIKAÜLIKOOL Majandusteaduskond Rahandus ja majandusteooria instituut Matemaatika, statistika ja ökonomeetria õppetool Laura Kallasvee, Liisi Saksakulm BRUTOPALKADE SEOS HARIDUSE, SOO JA ELUKOHAGA EESTI MAAKONDADE LÕIKES AASTATEL 2005-2008 Ökonoomeetriline projekt Juhendaja: dotsent Ako Sauga Tallinn 2014 SISUKORD SISSEJUHATUS.........................................................................................................................4 1. REGRESSIOONANALÜÜS..................................................................................................7 1.1. Ökonomeetriline mudel....................................................................................................7 1.2. Töös kasutatavad andmed..........................................
Statilised järeldused Isiklik veeb: www.tlu.ee/ˇkairio Kursuse veeeb: www.tlu.ee/ˇkairio/7070 Kursus hõlmab üldistavat statistikat. Tõmba SPSS 14p treial Võid ka vaadata nuditud vabavara PSPP Tunnused on väga oluline. Intervall - – väärtused on järjestatavad ning nende väärtuste vahemikud on võrdsed. Nt. sissetulek (123€, 125€, 130€, 1500€ jne.); -pikkus, kaal, avtelg, mitu eurot. Saab arvutada skeskväärtust. On anud vahemike otspunktid – siis läheb ta selle alla nt kui üks on hea ja 10 on halb, siis määramatu keskosa annab meile intervalltunnused. Järjestus- tunnused, mille väärtused moodustavad kategooriad ning neid saab omavahel järjestada. Samas ei ole nende väärtuste vahemikud võrdsed. Nt. hinnang (väga hea, hea, rahuldav) nt 0-100, 101-100 jne –vahemikud ei ole ühepikkuses, keskmist arvutada ei saa. Ka skaalad. – on olemas kindel järjekord aga v.heast heani ja heast halvani ei ole ühepikused Binaarne- sellel on ainult
enama muutuja vahelise teoreetilise suhte lühikirjelduse, samuti muutujate mõõtmisviisi kirjelduse (nimetamise). (näit. Kas õppimine on efektiivsem üksinda v. väikeses grupis? Tuleks lisada, kuidas me õppimise efektiivsust mõõdame!) c) kirjanduse ülevaate koostamine; d) piloot-uuring (pilot study), et leida ja täpsustada sobivad uurimisprotseduurid; samuti sobivad sõltumatu muutuja tasemed; e) lõplik uurimiskava koostamine; f) andmete kogumine; g) andmete statistiline töötlemine; h) tulemuste interpreteerimine; i ) uurimisaruande (artikli) koostamine. 2.2. Kirjanduse ülevaate koostamine. Kuidas lugeda teaduslikku artiklit. Kirjanduse ülevaate koostamine on eelduseks iga uurimuse läbiviimisele. Pärast idee tekkimist ja hüpoteesi sõnastamist tuleks koguda võimalikult palju infot selle kohta, mis on seni antud probleemist uuritud/teada. Kasulik on see a) leidmaks, kas ja kuivõrd üldse on probleemi uuritud
illustreerima peaks. Lugejatel on raske näha arvutuslike puude taga statistilist metsa. Seepärast ei pöörata kogu järgnevas käsitluses tähelepanu mitte valemitele ühe või teise statistiku arvutamiseks vaid püütakse selgitada statistiliste ideede (kontseptsioonide) olemust sõnade, näidete ja jooniste abil. Loengumaterjalide koostamisel on kasutatud D. Rowntree raamatut "Statistics without tears". Mis on statistika? 2.1 Statistiline mõtteviis. Statistiline mõtteviis on meile kõigile igapäevasest elust tuttav ja omane. Võtame ühe lihtsa näite: ma ütlen teile, et ma lähen täna teatrisse kahe kolleegiga, kusjuures üks neist on 190 cm pikk ja teine 165 cm pikk. Millise järelduse te võite kummagi kolleegi soo kohta kõige kindlamini teha, kui teil rohkem mingit informatsiooni ei ole? Ma arvan, et te võisite päris veendunult väita, et üks mu kolleegidest , 190 cm pikkune, on











































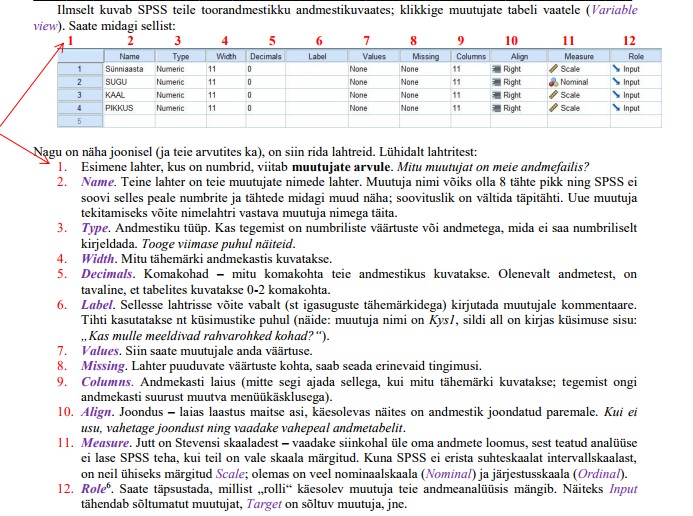

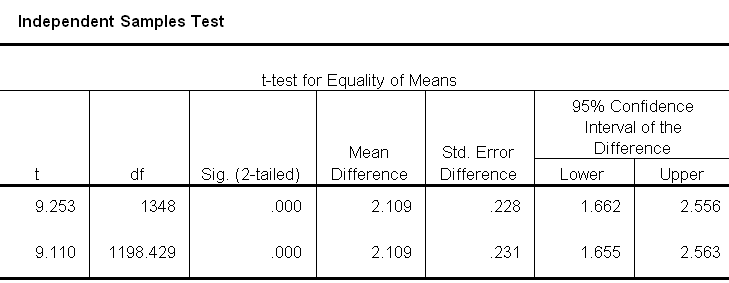
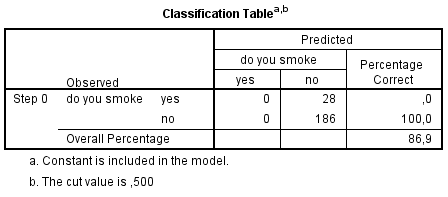
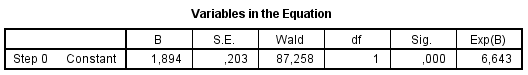
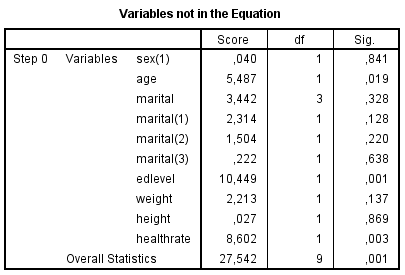
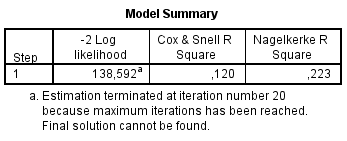
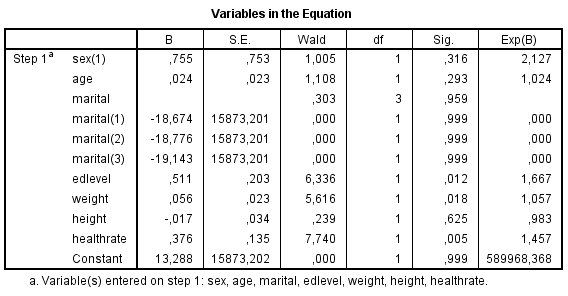
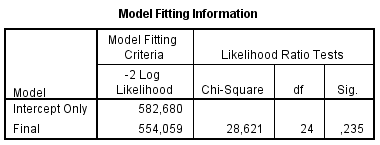
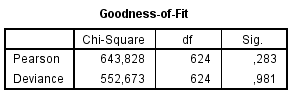
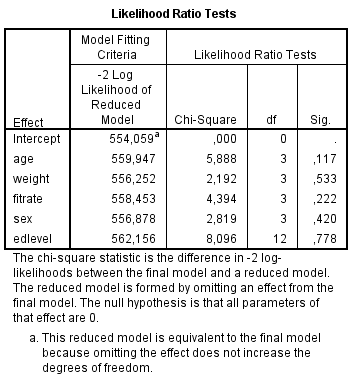
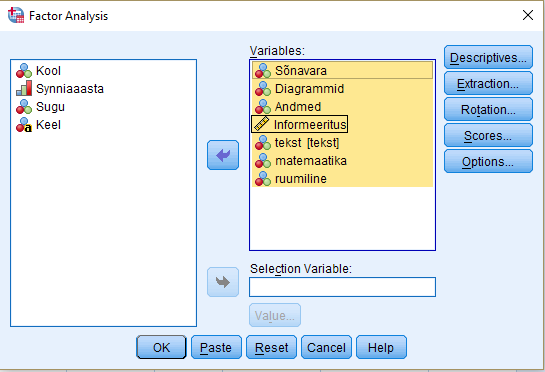
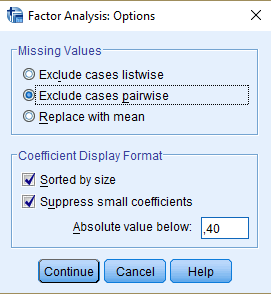
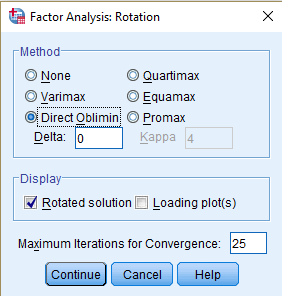




Kõik kommentaarid