ANDMEANALÜÜSI
KONSPEKT
Sisukord
Andmefailid
SPSS ’is 2
Normaaljaotuse kontroll 2
ANOVA vs T-test 2
ANVOA või regressioonanalüüs 3
Efekti suurus 3
Andmeanalüüs SPSS’is 4
Kirjeldav statistika 4
Kuidas testida normaaljaotust? 4
Sagedustabeli analüüs (Hii-ruut) 5
Ühesuunaline ANOVA 5
Faktoriaalne ANOVA 6
Korduvmõõtmsite ANOVA (Repeated
measures ANOVA) 6
Kurskall-Wallise test (e. mitteparameetriline ANOVA) 7
T-test sõltumatute gruppidega 7
T-test sõltuvate gruppidega 8
Mann -Whintey U Test (e. mitteparameetriline t-test) 8
Korrelatsioon 9
Lineaarne (paaris)
regressioon 10
Logistiline regressioon 11
Andmefailid SPSS’is
1)
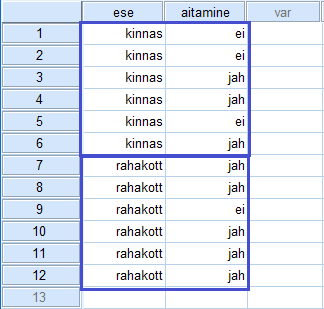
Sõltumatute gruppidega katseplaanKI
valed
6iged
VAS
vanus
sugu
katsetingimus
1
5
3
1,4
21
m
1
5
9
1
1,1
21
m
1
9
4
5
0,6
22
n
1
21
21
1
6
19
n
1
17
26
3
2,8
22
n
1
27
13
2
0,9
21
n
1
30
2
6
5,6
24
m
1
Analüüs
- Faktoriaalne ANOVA (two way ANOVA)
2)
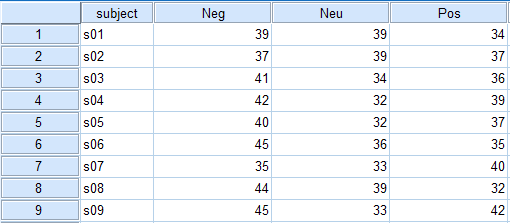
Sõltuvate gruppidega katseplaanSugu
Maskuliinsed sõnad
Vabalt valitud sõnad
Feminiinsed sõnad
mees
10
13
7
naine
12
8
8
mees
6
18
12
mees
12
10
12
mees
10
12
10
naine
12
15
14
naine
10
6
12
naine
13
15
11
Analüüs
- Korduvmõõtmiste ANOVA
NB!
Sugu on katseisikute vaheline (between
subject ) faktor. Tegemist on
seega segatüüpi disainiga – faktor „sõnade tüüp“ on
kõikidel katseisikutel sama, faktor „sugu“ jaotab
katseisikud kahte gruppi.
Normaaljaotuse kontroll
- Enne parameetrilise testi tegemist tuleks kontrollida muutujate normaaljaotust
- SPSS’is on selleks kaks testi: Shapiro Wilki test (väiksemate valimite puhul, kuni 2000) ja Kolmogorov Smirnov (n > 2000)
- Analyze -> Descriptive Statistics - > Explore -> Plots
- Kui p > .05 siis on normaaljaotusega (st nullhüpotees – on normaaljaotusega)
- NB! kui asümmeetriakordaja (ingl. k. skewness ) ja ekstsess (ingl. k. kurtosis) on vahemikus -1 kuni 1, siis võib pidada andmeid normaaljaotusele vastavaks
ANOVA vs T-test
- Esimest liiki viga tekib siis, kui võetakse vastu alternatiivne hüpotees, aga tegelikult on õige nullhüpotees (raske viga; näidatakse erinevuse või seose olemasolu, mida tegelikult pole).
- Teist liiki viga tekib siis, kui jäädakse nullhüpoteesi juurde, ehkki tegelikult on õige alternatiivne hüpotees. See on kergem viga, mis tihti tähendab, et alternatiivse hüpoteesi tõestamiseks tuleb andmeid juurde koguda.
- Iga kord kui teete t-testi on I tüüpi vea tõenäosus 5 % (olulisusnivoo 0.05). Kui teete mitu testi, siis suureneb tõenäosus leida vale positiivseid tulemusi.
- ANOVA kasutamine hoiab I tüüpi vea tõenäosuse 5% peal.
- Kui võrdlete omavahel rohkem kui kahte gruppi, siis tuleks alati eelistada ANOVA’t.
ANVOA või regressioonanalüüs
- Kui meil sõltumatu muutuja koosneb kategooriatest, siis on parem kasutada ANOVA’t.
- Kui sõltumatu muutuja on pidev tunnus, siis on parem kasutada regressiooni.
- ANOVA’ga hinnatakse gruppide keskmiste erinevust.
- Regressiooniga saab ennustada sõltuva muutuja väärtust prediktori (sõltumatu muutuja) väärtuste põhjal.
Efekti suurus
Efekti
suurus on statistiline näitaja, mis võimaldab lisaks statistilisele
olulisusele kirjeldada gruppidevahelisi erinevusi. Efekti suurust
saab väljendada mitmete statistikutega; ilmselt levinuim on
Cohen -i
d.
Kokkuleppeliselt tähistavad Cohen’i
d
väärtused väikest efekti väärtusel
d
= 0.2; keskmise suurusega efekti väärtus on
d
= 0.5; suure efekti väärtuse algus on
d
= 0.8.
SPSS-is
ei ole funktsiooni/käsklust, millega saaks paari kliki abil efekti
suurust (st Coheni d-d) kätte. Seega on mõned alternatiivid –
kiirelt Coheni d arvutamiseks saab kasutada kalkulaatorit, mis asub
aadressil
http://www.uccs.edu/~lbecker/ .
Siin pole muud kunsti, kui et tuleb väärtused lahtritesse sisestada
(
kasutage punkti, mitte
koma ).
Mitteparameetriliste
testide puhul on aga vaja kasutada teistsuguseid kalkulaatoreid.
Erinevaid efekti suurusi saab arvutada leheküljel
https://www.psychometrica.de/effect_size.html
Andmeanalüüs SPSS’is
Kirjeldav statistika
Kui
me tahame teadmisi
andmestiku kohta, kas kirjeldavat või järeldavat,
pöördume menüüribal oleva käskluse
Analyze
poole.
Käesolevas
praktikumis vaatame kirjeldava statistika võimalusi
selle käskluse alt.
Valige
Analyze
käskluse
alt
Descriptive
statistics
ning
sealt edasi
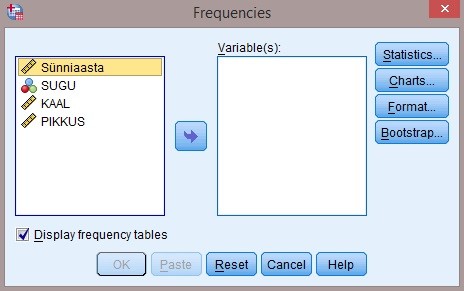
Frequencies...,
avaneb järgnev dialoogikast:
?Joonisel
näete, et vasakul on muutujad. Kui te tahate mingi muutuja kohta
kirjeldavat informatsiooni, viige see muutuja paremale poole
(joonisel tühi kast). Seejärel klikake käsklusele
Statistics.
Sealt saate erinevate vajalike kirjeldavate statistikute arvutamist
„
tellida “.
Charts
all
on võimalik kasutada histogrammi joonistamise võimalust.
Joonisel
olev küsimärk käib osutatud linnukese kohta.
Display frequency tables
annab
käskluse moodustada iga pikkuse kohta
sagedustabel . Küsimärk on
juurde tehtud, et uurida, kas sellise tabeli koostamine on vajalik.
Mis
on tabelite ja jooniste eesmärk?
Kuidas testida normaaljaotust?
Selleks
järgige järgmist käskluste rida:
Analyze->
Descriptive Statistics-> Explore-> (ärge
unustage valida sõltuvateks muutujateks ruumiline mõtlemine ja
sõnavara ning sõltumatuks muutujaks sugu)
Plots->
Normality Plots with tests Võite
ära märkida, et tahate joonist histogrammi kujul. Kui olete need
sammud ära teinud, peaks teil
tulema alljärgnev tabel:
Tests of NormalitySugu
Kolmogorov-SmirnovaShapiro-WilkStatistic
df
Sig.
Statistic
df
Sig.ruumiline
mees
,093
608
,000,974
608
,000
naine
,071
742
,000,985
742
,000
Sõnavara
mees
,091
608
,000
,988
608
,000
naine
,071
742
,000
,989
742
,000
a. Lilliefors Significance
Correction Selleks,
et vastata küsimusele – kas on tegemist normaaljaotusega või
mitte – peame
esmalt välja nuputama, millist testi vaatame.
Kolmogorov-Smirnov
testi on mõttekas
vaadata siis, kui
valim on väga suur (tuhanded indiviidid),
Shapiro-Wilk
test on kohane
väikese valimi puhul (u 50-2000 indiviidi). Meie andmestikus on 1350
inimest, seega võiks kasutada Shapiro-Wilk testi. Juurde tasub aga
märkida, et mõlemad testid on üsna tundlikud äärmuslike
väärtuste ning valimi suuruse suhtes, mistõttu teatud olukordades
ei pruugi nende testi alusel tehtud otsustused olla täpsed!
Järgnevalt
tuleb vaadata
Sig.-i
(olulisuse tõenäosus).
Kui
Sig on väiksem kui 0.05, siis ei ole testi(de) kohaselt andmed
normaaljaotuslikud.
Kas meie ülesandes on andmestik selle testi kohaselt normaaljaotusega?Normaaljaotuse
testimist saab testada mitmel juhul – eelpool oli kirjeldatud
normaaljaotustesti. Samuti saab aga normaaljaotuslikkust vaadata
asümmeetriakordaja, järsakusastme ning joonise abil. Lõppude
lõpuks on andmeanalüütik see, kes peaks sisuliselt lahti mõtestama
tulemused.
Nii
asümmeetriakordaja kui ka järsakusastme väärtuse 0 korral
loetakse andmestikku (ideaalselt) normaaljaotuslikuks; paraku on
pisut ebarealistlik oodata käitumisteadustes säärast ideaalset
jaotust.
Seepärast
on teadlased kokku leppinud, et kui asümmeetriakordaja ning
järsakusaste jäävad -1 ja 1 vahele, võib sisuliselt rääkida
normaaljaotusest.
Sagedustabeli analüüs (Hii-ruut)
Kahe
kategoriaalse tunnuse analüüsimiseks saame kasutada Hii-ruut testi.
SPSS’is
näeksid andmed välja järgmised:
Selle
analüüsi tegemiseks SPSS’is järgige alltoodud käsklusi:
Analyze
– Descriptives
–
Crosstabs - Avanenud aknas üks muutuja lahtrisse „Rows“ ja teine muutuja lahtrisse „Columns“.
- Statistics aknast saate valida Hii-ruut analüüsi, tehke linnuke Chi- square ette.
Mida
näitab väljundiaken (
Output)?
- Kõige olulisem on tabel Chi-Sqaure Test.
- Vaadake rida " Pearson Chi-Square". Esimene number näitab Hii-ruut statistiku suurust, teine number vabadusastmeid ja kolmas number näitab p-väärtust. Kui p-väärtus on alla 0.05, siis on jaotustes oluline erinevus.
Ühesuunaline ANOVA
Kui
sõltuv muutuja on pidev tunnus ja meil on üks sõltumatu muutuja
rohkem kui 2 tasemega, siis saame kasutada ühefaktorilist ANOVAT –
One-Way
ANOVA.
Selle analüüsi tegemiseks SPSS’is järgige alltoodud käsklusi:
Analyze
– Compare Means –
One-Way
ANOVA - Avanenud aknas viite sõltuva muutuja kasti Dependent list, sõltumatu muutuja on Factor.
- Ehkki ANOVA ise näitab, kas esineb gruppievahelisi erinevusi, siis dispersioonanalüüs ei näita, milliste gruppide vahel need erinevused on. Menüüst Post Hoc saate valida nn järeltesti ehk post hoc testi, mis analüüsib konkreetsete tingimuste vahelisi erinevusi. Kui grupidde hajuvused on sarnased, tuleks kasutada Tukey (HSD) testi, kui aga ei ole sarnased, on soovitatav kasutada Games -Howell testi.
- Options aknast saate lisaks valida kirjeldavate statistikute kuvamise (Descriptive) ja samuti saate ka hajuvust testida (Homogeneity of variance test).
Mida
näitab väljundiaken (
Output)?
- Kui valisite kirjeldava statistika kuvamise, siis see peaks olema esimene tabel, mis ANOVA puhul näidatakse. Seal on mh kajastatud gruppide suurused, nende keskmised mõõdetud parameetril, jms.
- Järgmisena peaks olema hajuvustest – selle abil otsustaste, kumma post hoc testi tulemusi vaatate . Kui p> .05 (ehk ei ole statistiliselt olulist erinevust), on tegemist sarnase hajuvusega ning vaadata tuleks Tukey testi tulemusi; kui aga p Games-Howell testi tulemusi.
- ANOVA tabel meid kõige enam huvitava küsimuse vastust – kas gruppide vahel on statistiliselt olulised erinevused või mitte. Sig (ehk olulisuse tõenäosus) annab meile vastuse. Kui p post hoc testi, et välja selgitada, kus täpsemalt on erinevus(ed).
- Post hoc testide tabel näitab erinevate gruppide vahelisi võrdlusi. Oluline on siingi jälgida, millised nendest võrdlustest on statistiliselt olulised.
Faktoriaalne ANOVA
Kuidas
aga lahendada olukorda, kus on mitu erinevat sõltumatut muutujat,
millel omakorda on mitu taset? Sellist olukorda võiks näitlikustada
ravimiuuringuga, kus vaadatakse kahe erineva ravimi mõju kahe
erineva doosiga. Saaksime järgneva uuringu ülesehituse: 2 (
ravim 1,
ravim2) x 2 (madal
doos , kõrge doos)
eksperiment . Eeltoodud kujul
raporteeritakse tihtipeale faktoriaalset eksperimenti.
Faktoriaalse
lahenduse puhul saab rääkida
peaefekti(de)st
ja
interaktsioonist
(
koosmõjust).
Eeltoodud näite puhul tähendab peaeefekt seda, et nt ainult
ravimitüübist oleneb, kas ravi on efekti või ei – seevastu
ravimi doos ei ole oluline; realistlikum on ehk
teistpidi – doos on
oluline, ent ravimitüüp mitte.
Interaktsioon tähendab aga nt seda,
et ravimite efektiivsus sõltub doosist – nt ravim1 on efektiivne
siis, kui doos on kõrge, ravim2 on aga efektiivne siis, kui doos on
madal.
Kõigi
taoliste faktoriaalsete lahenduste puhul saab SPSS-is kasutada sama
lahenduskäiku:
Analyze
– General Linear Model –
UnivariateKui
eeltoodud käsklus on
sisestatud , siis on väga palju
valikuid .
Esmalt määratlege ära sõltuv muutuja ning sõltumatud muutujad
(
Fixed
Factors).
- Plots alt pange vanusegrupp horisontaalsele teljele ning sugu olgu eraldi joontena. Vajutage Add ning jätkake.
- Post hoc käskluse alt võite valida mõlemad sõltumatud muutujad ning Tukey test.
- Options alt valige sõltumatud muutujad ning nende interaktsioon. Display käskluse alt saate valida erinevate statistikute kuvamist. Enamasti tasub valida kirjeldavad statistikud, hajuvustest, efektisuurus ning võib valida ka statistilise jõu (statistical power ).
- Kui olete kõik valikud ära teinud, teostage analüüs.
Väljundiaknas
on mitmed
tabelid ning üks joonis. Sarnaselt
one-way
ANOVA-ga
on ka faktoriaalses lahenduses esmalt toodud kirjeldavad statistikud,
seejärel hajuvustest, ANOVA-tabel ning
post
hoc
analüüsid. Viimasena on joonis, mis ilmestab graafiliselt kas
peamõju või interaktsiooni.
ANOVA
tabel (ehk
Test
of Between- Subjects Effects)
annab infot selle kohta, kas mudel, sõltumatute muutujate peamõjud
ning interaktsioon on statistiliselt olulised. Lisaks on võimalik
teada saada, mis on nende peamõjude ja interaktsiooni efekti suurus
ja statistiline jõud.
Post
hoc
tabelid näitavad gruppide keskmisi. Kui nt analüüs näitab, et
interaktsioon on statistiliselt oluline, siis tasub raporteerida seal
tabelis toodud keskmised.
Korduvmõõtmsite ANOVA (Repeated measures ANOVA)
See
on sarnane tavalise ANOVA-ga (
One
Way ANOVA).
Tavalise ANOVA-ga võrdlesime erinevusi sõltumatute gruppide vahel.
Korduvmõõtmiste ANOVA-ga saame võrrelda erinevusi sõltuvate
gruppide korral. Eksperimentaalpsühholoogias kohtab seda analüüsi
üsna sageli, sest eelistatakse kasutada katsedisaine, kus kõik
katseisikud teevad kõik tingimused läbi (sõltuvate gruppidega
katsedisain).
Korduvmõõtmistega
andmete puhul peavad SPSS’is olema ühe katseisiku andmed ühel
real :
Koruvmõõtmiste
ANOVA analüüsi leiate:
Analyze
– General
Linear Model –
Repeated
Measures
Kurskall-Wallise test (e. mitteparameetriline ANOVA)
Kui
parameetrilise ANOVA eeldused ei ole täidetud, on olemas ka
mitteparameetriline
analoog: Kruskall-Wallis
test.
SPSS-is jõuab sinna nii:
Analyze
–
Nonparametric
Tests –
Legacy
dialogs –
K
Independent Samples.
Üldjoontes
sarnaneb edasine lahenduskäik parameetrilise testi omale.
Kui
teil on katses mitu sõltumatut muutujate, siis selle testi puhul
peate analüüsima neid eraldi.
Post-hoc
testide puhul peate samuti kasutama mitteparameetrilisi
teste (vaadake peatükki „Mann-Whintey U Test (e. mitteparameetriline
t-test)“).
T-test sõltumatute gruppidega
Kahe
sõltumatu grupi keskmiste erinevuse uurimiseks kasutame kahe
sõltumatu grupiga (
Student ’i) t testi.
Selleks,
et keskmisi võrrelda(2 sõltumatut gruppi):
Analyze
–
Compare
Means
–
Independent
Samples T Test.
Kuidas
me hüpoteesi uurima hakkame? Esmalt
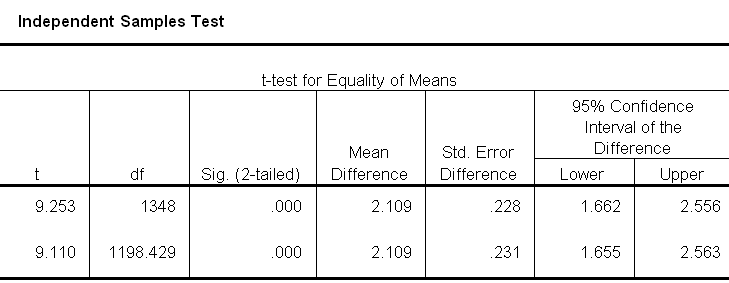
väljundiaknas kuvatud tabelitest ja arvudest:
Independent
Samples T-testi
tulemused
ja nende tõlgendamine:
Group
StatisticsSugu
N
Mean Std.
Deviation Std.
Error Mean
matemaatika 1
608
9.46
4.516
.183
2
742
7.35
3.856
.142
Esimeses
tabelis tuuakse ära mõlema grupi valimi suurus, aritmeetiline
keskmine, standardhälve ja aritmeetilise keskmise standardviga.
Teise
tabeli esimeses
pooles tuuakse ära Levene’i test gruppide
dispersioonide võrdlemiseks:
Teise
tabeli teises pooles on info gruppide keskmiste võrdlemiseks:
Statistikas
on saanud traditsiooniks kasutada
olulisusnivoosid
0.01 (ehk 1%) ja 0.05 (ehk 5%).
Valides olulisusnivooks 0.05, peab
olulisustõenäosus selleks, et nullhüpoteesi ümber lükata, olema
väiksem kui 0.05 ning vastavalt olulisusnivoo 0.01 korral peab ta
olema väiksem kui 0.01.
Seega
– mida täpsemalt vaadata? Esmalt visake pilk peale tabeli
esimesele osale, kus on Levene-i test – seda on oluline silmas
pidada, et teaksite, kumma rea tulemusi edasi lugeda.
Kui
Levene’i testi Sig on suurem kui 0.05, vaatame edaspidi ülemist
tabelirida (näitab,
et jaotuste „kujud“ ei erine statistiliselt oluliselt)
;
kui Levene’i test Sig on väiksem kui 0.05, loeme edaspidi alumist
rida (näitab,
et jaotuste „kujud“ erinevad statistiliselt oluliselt).
Kuid
teadmisest, kuidas näevad välja gruppide keskmised ning kas
gruppide vaheline erinevus on oluline või mitte, üksi ei piisa.
Need tulemused tuleb kuidagi ka kirjapilti saada. T testi
raporteeritakse järgnevalt:
Selles
suvalises näidislauses leiti, et loengutes kohalkäijate keskmine
tulemus (M
=
4.51, SD
=
0.30) on statistiliselt oluliselt kõrgem kui neil, kes magavad sisse
ja kohale ei tule (M = 2.92, SD = 0.31), t(kirjuta
siia df väärtus)
=
(kirjuta
siia t väärtus),
p
=
0.008, [efektisuuruse
statistik] =
(kirjuta
efekti suurus siia).
T-test sõltuvate gruppidega
Lahenduskäik
on sarnane sõltumatute
valimitega t-testi korral; kaks olulist
erinevust siiski on. Kui sõltumatu t-testi puhul kontrollisime
sõltuvate
muutujate eeldusi , siis sõltuvate valimitega t-testi korral tuleb kontrollida
esimese ja teise (või ajaliselt mõne muu)
mõõtmiskorra
vahe
normaaljaotuslikkust. Selleks tekitame käskluse
Compute
variable
abil
veel
kaks muutujat:
U_vahe
ning
A_vahe.
Kui need muutujad on olemas, saate nende normaaljaotuslikkust testida
juba harjumuspärasel viisil.
Kui
eeldused on üle vaadatud, erineb käesolev analüüs sõltumatute
valimitega testist viimase käskluse poolest:
Analyze
–
Compare
Means
–
Paired -Samples
T Test.
Variable
1
alla
pange esimese mõõtmise muutuja ning
Variable
2
alla
valige tema
paariline teisest mõõtmiskorrast.
Väljundiakna
(
Output)
loogika on enam-vähem sama, mis sõltumatute valimitega testi puhul.
Mann-Whintey U Test (e. mitteparameetriline t-test)
Mis
juhtub siis, kui parameetriliste testide
parameetrid (ehk eeldused
siin kontekstis) ei ole täidetud? Väga lihtne – appi saab võtta
mitteparameetrilised testid.
Kust
leida mitteparameetrilised testid?
Tähelepanu!
Ei ole samas kohas, kus t-testid!
Käsklusterida:
Analyze
–
Nonparametric
Tests
–
Legacy
Dialogues
–
2
Independent Samples.
Vanemates
SPSS-i versioonides võivad sõltumatute ja sõltuvate gruppidega t
testid olla muud moodi nimetatud. Kui nõnda, siis vasted võivad
olla järgmised:
ParameetrilineMitteparameetriline2 sõltumatu valimiga t test
Mann-Whitney U TestSõltuva valimiga t test
Wilcoxon Signed Ranks TestSõltumatute
valimitega t-testi raporteerimine käib nõnda:
Selles
suvalises näidislauses leiti, et loengutes kohalkäijate keskmine
tulemus (N
=
kohalkäijate arv, Mastak
= keskmise astaku väärtus) on statistiliselt oluliselt kõrgem kui
neil, kes magavad sisse ja kohale ei tule (N
=
kohalkäijate arv, Mastak
=
keskmise astaku väärtus), U
=
U väärtus, p
=
toodud Sig.Sõltuva
valimiga t-testi mitteparameetrilise analoogini jõudmine järgi
eeltoodud käsklusterea loogikat:
Käsklusterida:
Analyze
–
Nonparametric
Tests
–
Legacy
Dialogues
–
2
Related Samples.
Väljundiaknas
näete erinevust statistikutes – ehkki nii parameetrilistes kui ka
mitteparameetrilistes testides kuvatakse teile olulisuse tõenäosust,
näete te mitteparameetriliste testide tulemustes keskmise (
mean)
asemel keskmist astakut (
mean rank );
samuti on mitteparameetrilises analoogis olulisel kohal
Wilcoxoni
Z
(sõltumatute valimite puhul
Mann-Whitney
U).
Need statistikud tuleb teil raporteerida järgnevalt:
Wilcoxoni
Signed Ranks Test näitas, et otse vaatava pilguga pilte hinnati
statistiliselt oluliselt atraktiivsemaks kui kõrvale vaatava pilguga
pilte, Z = ..., p = .02.Alternatiivselt:
Wilcoxoni
Signed Ranks Test näitas, et otse vaatava pilguga piltide atraktiivsuse astakud olid statistiliselt oluliselt kõrgemad kui
kõrvale vaatava pilguga piltide astakud, Z = ..., p = .02.
Korrelatsioon
Korrelatsiooni
kasutatakse selleks, et uurida muutujate vahelisi
seoseid ning nende
seoste tugevust. Parameetriline
seosekordaja on
Pearsoni
r,
mitteparameetrilisteks seosekordajateks on
Spearmani
roo
ning
Kendalli
tau.
Mitteparameetriliste analüüside korral kasutatakse tihtipeale
Spearmani roo statistikut, ent Kendalli tau-d peetakse paremaks
näitajaks väiksematel valimitel.
Pearsoni
korrelatsioonikordaja eeldused:
- muutujad peaksid olema mõõdetud intervall või suhteskaalal;
- lineaarne seos muutujate vahel (hea viis testimiseks -> Scatterplot -> visuaalselt hinnata seose olemust);
- ei tohiks olla märkimisväärseid erindeid (saab samuti hinnata joonise abil);
- muutujad peaksid olema vähemalt ligilähedaselt normaaljaotuslikud.
Korrelatsioonikordajate
väärtused jäävad vahemikku -1 ja 1,
kusjuures mida enam selle
vahemiku piiridele lähemal, seda tugevam seos (korrelatsioon
väärtusega 0 tähendab seose puudumist); ühtlasi näitab väärtuse
ees olev pluss- või miinusmärk ka seos suunda. Positiivne
korrelatsioonikordaja tähendab, et kui ühe muutuja väärtused
kasvavad, kasvavad ka teise muutuja väärtused; negatiivne
korrelatsioonikordaja aga näitab, et kui ühe muutuja väärtused
kasvavad, teise muutuja väärtused
kahanevad .
Lisaks
saab SPSS-is testida seoste statistilist olulisust (nii ühe- kui ka
kahesuunalise hüpoteesi puhul).
Korrelatsioonikordaja
on sisuliselt ka efekti suuruse ning mudeli seletusvõime näitaja.
Võttes korrelatsiooni ruutu, saame
R2
statistiku ehk, eesti keeles, determinatsioonikordaja. Kui me seda
kordajat sajaga korrutame, saame protsendid selle kohta, kui palju
ühe muutuja varieerimine teise muutuja varieeruvusest seletab.
Näiteks kui kahe muutuja – X ja Y – vaheline korrelatsioon
r
= 0.20, siis
R2=
(0.20)2=
0.20*0.20 = 0.04 ning
muutuja X seletab ära 0.04*100 = 4% muutuja Y varieeruvusest.
Väga
oluline on tähele panna ja meelde jätta, et korrelatsioon ei näita
põhjuslikkust. Ka tulemuste raporteerimisel saame rääkida
muutujatevahelisest
seosest,
mitte
ühe
muutuja mõjust teisele.
Statistiliselt võttes saame rääkida kolmest võimalikust
põhjuslikkuse
suunast . Eeltoodud näite põhjal võivad nad olla
järgnevad:
Muutuja X põhjustab muutuja Y varieerumist.
Muutuja Y põhjustab muutuja X varieerumist.
Kolmas muutuja Z põhjustab nii muutuja X kui ka muutuja Y varieerumist.
Enne
statistikute uurimist vaatame aga hajuvusdiagrammi (scatter plot ).
Mille leiate Graphs
menüü
alt.
Graphs
– Legacy
Dialogs –
Scatter/Dot
– Simple Scatter.
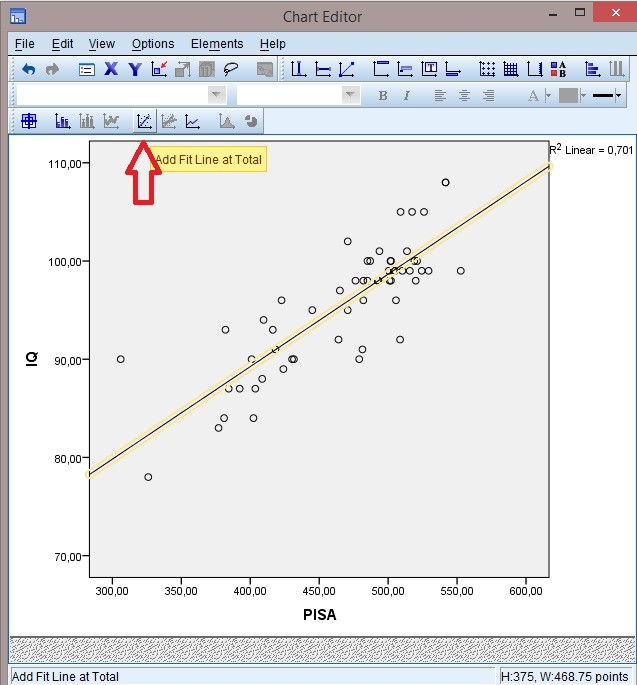
Kui
teete joonisele topeltkliki, saate lisada ka lineaarset seost
kujutavad joone joonisele. Joone lisamisel peaks olema ilmsem,
millise seosega on tegemist.
Kuidas
aga see graafiline info statistikutes väljendub? Korrelatsioonide
leidmiseks kasutage käsklusterida Analyze
–
Correlate
–
Bivariate.
Options
alt saate valida, mida teha puuduva andmestikuga. Vaikimisi peaks
seal olema käsklus Exclude cases pairwise,
mis tähendab, et kui terve indiviidi/andmerea sees on ühel muutujal väärtus puudu, siis ainult seda andmepunkti ei kasutata edaspidises
analüüsis – kõigi teiste muutujate vahelisi korrelatsioone aga
vaadatakse. Exclude
cases listwise
aga
eemaldab terve indiviidi/andmerea. Viimast käsklust kasutades
oleksid kõikides korrelatsioonimaatriksi lahtrites valimid võrdsed.
Lineaarne (paaris)regressioon
Regressioon
on korrelatiivne protseduur , mis võimaldab tulemuse väärtusi
korrelatsiooni alusel mingi teise muutujaga ennustada. Korrelatsioon
ja regressioon on olemuselt üsna sarnased mõisted; arvuliselt on
tegelikult Pearsoni
r,
mis väljendab kahe muutuja (nt X ja Y) vahelist seost, üsna sama
väärtusega kui standardiseeritud regressiooni koefitsient. See
tähendab ka seda, et determinatsioonikordaja R2
on sarnase väärtusega. Ühtlasi on oluline teada, et nii
korrelatsioon kui ka lihtne, lineaarne paarisregressioon ei ütle
otseselt ära põhjuslikkuse suunda.
Viimast
lauset silmas pidades on oluline ära mainida, et regressiooni puhul
on väga oluline see, kumb kahest muutujast – kas, meie näites, X
või Y – on prediktor (ehk ennustav muutuja; ingl k predictor;
sisuliselt sõltumatu muutuja) ning kumba muutujat ennustatakse (ingl
k outcome variable;
sisuliselt sõltuv muutuja). Regressioonianalüüsi tulemusena
saadakse võrrand, mis kirjeldab iga prediktori osakaalu ennustatavas
muutujas. Seesama võrrand on graafiliselt regressioonisirge
võrrandiks, kus vabaliige kirjeldab y- teljega lõikumispunkti
(intercept)
ning sirge tõus (gradient)
kirjeldab sirge paiknemist y- ja x-telje vahel (vt Fieldi õpikust lk
199). Sisuliselt üritab lineaarne regressioon läbi andmepunktide
parve joonistada sirge, millest võimalikult palju väärtusi on
sarnase kaugusega.
Regressioonianalüüsi
läbiviimiseks on 6 eeldust :
sõltuva muutuja andmed on intervall- või suhteskaalal (st on pidevtunnus);
muutujatevaheline suhe on lineaarne;
puuduvad märkimisväärsed erindid (outliers);
vaatluste sõltumatus;
püsihajuvus (homoskedastilisus; homoscedasticity);
jääkide normaaljaotuslikkus (normality of residuals).
Kui
1. ja 4. eeldust saab juba lausa enne uuringu läbiviimist täita,
siis eeldused 2, 3 ja 5 on testitavad hajuvusdiagrammiga, st üldist
pilti on võimalik vaadelda graafiliselt. Eeldust 6 saame testida
siis, kui viime läbi regressioonianalüüsi.
Lineaarse
regressiooni läbiviimiseks tuleks järgida käsklusterida: Analyze
– Regression
–
Linear.
Dependent
on
sõltuv muutuja, Independent
on prediktor. Statistics
alt valida Estimates,
Model
Fit
ning Descriptives.
Salvestame ka regressioonijäägid uue muutujana: Save
– Residuals
– Unstandardized.
Pärast analüüsi läbiviimist tuleb selle uue, salvestatud
muutujaga läbi viia normaaljaotuslikku test.
Tulemustena
kuvatakse mitu tabelit. Leiate, et on (a) kirjeldavat statistikat (nt
mõlema muutuja keskmised); (b) muutujatevahelised korrelatsioonid ;
(c) muutujate lisamine/eemaldamine mudelisse (paarisregressiooni
puhul ebaoluline); (d) mudeli kokkuvõte, kus on kirjeldatud mh
determinatsioonikordaja R2
– korrutades seda väärtust 100-ga, saame teada, kui suure osa
kogu ennustatava muutuja (siin: testitulemus) variatiivsusest
kirjeldab ära prediktor (siin: vanus). (e) ANOVA tulemused mudeli
olulisuse hindamiseks (kui Sig.






























Kõik kommentaarid