Soo defineerimine :Variable
view - soolahtrist
Values ... - 1=mees, 2=naine - data view - ülevalt
view -
value labels ette
linnuke Kasvavas
järjekorras järjestamine:Teed
lahtri aktiivseks mida järjestada soovid - ülevalt Data - Sort
cases -
valid mida soovid sortida - linnuke ascending lahtri ees
kindlalt ja OK
Mingi
väärtuse minimaalse ja maksimaalse väärtuse leidmine,
standardhälve, keskmine:Analyze -
descriptive statistics - descriptives/frequencies (kui vaja
ekstsessi, histogrammi kellukat jn) - valid mille puhul
tahad uurida
- Options - valid milliseid väärtusi leida tahad ja ok, vastused
ilmuvad OutPuti
aknasse .
Charts all
on võimalik kasutada histogrammi joonistamise võimalust.
Joonisel olev küsimärk käib osutatud linnukese kohta.
Display frequency tables annab käskluse moodustada iga pikkuse kohta
sagedustabel . Küsimärk on juurde tehtud, et uurida, kas sellise
tabeli koostamine on vajalik.
Uue muutuja arvutamine:Transform
- Compute variable - kirjutad uue lahtri nimetuse (tühikuid ei
kasuta) - liidad mida vaja liita (võrdusmärki pole vaja) Kehamassiindeks=Kaal kg'des jagadtud pikkus cm'tes
ruudus (Pikkus x
Pikkus)
Andmete
eraldamine:Data - select cases - If condition is satisfied ette linnuke - klikid
If...-le - valid nt ainult meeste tulemuste saamiseks vasakult Sugu,
siis = ja 1 (sest 1=mees ja tahan ainult meeste tulemusi) ja
continue.
Kui valid
samas
aknas (Select cases) alumisest osast
Filter Out Unselected
cases, siis on naiste andmed jätkuvalt näha aga nendega ei
arvestata, kui valid
Delete unselected cases, siis kustutab
süsteem kõikide naiste andmed ära.
Asümmeetriakordaja
=
skewness (Asümmeetriakordaja
iseloomustab jaotuse asümmeetriat keskmise suhtes.)
Kvartiilid
= quartiles (Kvartiilid
jaotavad rea
neljaks võrdsete liikmete arvuga osaks. Kvartiile on
kolm: esimene ehk alumine
kvartiil Q1,
teine kvartiil Q2,
mis on võrdne mediaaniga ja kolmas ehk ülemine kvartiil Q3.
Alumiseks kvartiiliks nimetatakse tunnuse väärtust, millest
väiksemaid (või võrdseid) liikmeid on variatsioonreas ¼ ehk 25%.
Ülemiseks kvartiiliks nimetatakse
tunnuse väärtust, millest
suuremaid (või võrdseid) liikmeid on
variatsioonreas ¼ ehk 25%. Enamasti kui räägitakse kvartiilidest,
peetaksegi silmas alumist ja
ülemist kvartiili , teise kvartiili
kohta kasutatakse mediaani
nimetust . Ka kvartiile mõõdetakse
samades ühikutes, mis tunnustki. )
Ekstsess
= Kurtosis -
Ekstsess
iseloomustab jaotuskõvera suhtelist teravust või lamedust võrreldes
normaaljaotusega.
Uue
muutuja kodeerimine :Transform
- transform into different variables - sealt paned vahemikud ja
vahemiku väärtuse new value alla ja siis Add ja olemas.
Kui sugu
on defineeritud kui F=naine ja M=mees, siis F'st saab N'i teha kui
lähed transform - recode into
same variables - Old value=F , new
value=N ja OK. Siis variable view's lähed soo
lahtris kolmele
punktikesele, teed lahti, ja muudad et N=naine
Muutuja standardiseerimine :Muutuja standardiseerimiseks nimetatakse teisendust, kus muutuja
igast väärtusest lahutatakse aritmeetiline keskmine ning saadud
vahe jagatakse standardhälbega. Saadud tulemust nimetatakse ka
z-skoorideks. Nt muutuja Kokku,
kõigepealt leiad selle standardhälbe
ja keskmise, siis teed tehte aknas Transform - compute variable - uus
muutuja "Kokku_z" ja
tehe Kokku-arit.kesk. / standardhälve. Kui küsitakse, et milline test on olnud vastajaile kõige lihtsam,
siis see, mille histogrammi kellukakõver näitab, et enamus
lahendajaid on üsna suure skoori saanud, ehk kellukatipp on
võimalikult paremal.
Uued tunnused matemaatiliste funktsioonide
abil:Näiteks
matemaatika testi tulemusi logaritmilisele skaalale
teisendades, tuleb valda Transform - Compute variables - Uue muutuja
nimeks log_mat ja vastav funktsioon LN(matemaatika)
Tulpdiagrammi saamiseks:Graphs -> Bar.Ühe tunnuse jaoks vali:
Simple - Summaries of groups of cases, Define .
Tunnus, mille sagedusjaotust soovid
illustreerida paiguta väljale
Category Axis Kastis
Bar represent saab valida kas
absoluutsed
sagedused (N of cases) või protsentuaalsed osakaalud.
Kui
soovite , et puuduvate väärtuste jaoks
eraldi tulpa ei kuvataks:
Options
ja
vajuta kastil
Display groups
defined by missing values.Pealkirja saamiseks vajuta nuppu
Titles.Graafik paigutatakse tulemilehele, kus saab teda täiendavalt redigeerida.
Gruppide keskmiste leidmine/võrdlemine:Kui soovid leida näiteks ühe testi puhul nii meeste kui naiste
keskmised tulemused eraldi, siis valid Analyze -
Compare means -
Means -
Dependent listi 'matemaatika' ja Independent listi 'sugu' -
OK
Meeste ja naiste keskmiste tulemuste
joonistamine koos usalduspiiridega:Graphs - Legacy Dialogs -
Error Bar - Define - variable (ehk
y-
telg )=see millise testi tulemusi vaadata soovid nt matemaatika ja
category axis=sugu ja OK
Test
et kindlaks teha kas andmed pärinevad normaaljaotusega
populatsioonist.Analyze->
Descriptive Statistics-> Explore->
Plots->
Normality Plots with tests +histogram
;normaaljaotusega on tegemist siis kui
tulpdiagramm näeb kelluka
kujuline välja.
KAHE
SÕLTUMATU GRUPI KESKMISTE VÕRDLEMINE PARAMEETRILISE TESTIGA
Analyze-Compare
means - independent samples T test - Test variables'i kõik mille
keskmisi tahan uurida ja Grouping variables'i Sugu (sest tahan sugude
vahelisi erinevusi võrrelda) (defineerin soo 1 ja 2) - OK
Saan
tabeli, kust näen meeste naiste keskmiste erinevusi alatestide
lõikes. Alumises tabelis on üks tulp nimega Sig (Olulisuse nivoo),
kui sealne number jääb alla 0,05, siis on tegu statistiliselt
oluliselt erinevate keskmistega.
Kui
Sig on väiksem kui 0.05, siis ei ole andmed normaaljaotuslikud.T-testi
läbiviimise eeldus on, et üldkogum oleks normaaljaotusega,
intervallskaalal, ja et neil oleksid võrdsed
dispersioonid .
Kui
Levene’i testi Sig on suurem kui 0.05, vaatame edaspidi ülemist
tabelirida; kui Levene’i test Sig on väiksem kui 0.05, loeme
edaspidi alumist rida. 0,5 0,05 0,005 0
Vastus
tuleb Sig (2-
tailed ) alt!!!
T-testi
raporteerimine:Selles
suvalises näidislauses leiti, et loengutes kohalkäijate keskmine
tulemus (M = 4.51, SD = 0.30) on statistiliselt oluliselt kõrgem kui
neil, kes magavad sisse ja kohale ei tule (M = 2.92, SD = 0.31),
t(kirjuta siia df väärtus) = (kirjuta siia t väärtus), p = 0.008.
KESKMISTE
VÕRDLEMINE ROHKEM
KUI KAHE SÕLTUMATU
RÜHMA KORRAL
Kas
andmete piisavuse testi keskmised tulemused on erinevad defineeritud
vanuseklasside lõikes?
-
Analyze->
Compare means-> ANOVA
-
Aknast valite tunnuse, mille keskmiste erinevust uurite aknasse:
Dependent
list
-
Tunnuse, mille järgi toimub
rühmitamine , valite aknasse:
Factor
-
Aknast
Post
Hoc,
teete linnukese kastidesse
LSD
ja Bonferroni
(need on gruppide võrdlemise erinevad meetodid) –
ehkki ANOVA
näitab,
kas
gruppide
vahel on erinevusi, näitavad
post
hoc testid,
mis
gruppide
vahel on erinevused.
-
Option s
aknast teete linnukese
Descriptive
ja
Homogenity
of the variance test juurde
EFEKTI
SUURUSE ARVUTAMINE
Efekti
suurusvi
on
statistiline näitaja, mis võimaldab lisaks statistilisele
olulisusele kirjeldada gruppidevahelisi erinevusi. Efekti suurust
saab väljendada mitmete statistikutega; ilmselt levinuim on
Cohen -i
d.
Kokkuleppeliselt
tähistavad Cohen’i
d
väärtused
väikest efekti väärtusel
d
=
0.2; keskmise suurusega efekti väärtus on
d
=
0.5; suure efekti väärtuse algus on
d
=
0.8.
SPSS-is
ei ole funktsiooni/käsklust, millega saaks paari kliki abil efekti
suurust kätte. Seega on mõned alternatiivid – meie kasutame siin
kursusel ühte
veebis leiduvat kalkulaatorit, mis asub aadressil
http://www.uccs.edu/~lbecker/ .
Siin pole muud kunsti, kui et tuleb väärtused lahtritesse sisestada
(
kasutage punkti, mitte
koma ).
Analyze
- compare means - one-way anova - dependent listi see mida uurid nt
sotsiaalsus , factor listi sugu - Post hoc (LSD, Bonferroni) - Options
(descriptive ja homogeneity..) ja OK, siis leheküljele.
MITTEPARAMEETRILISED
TESTID KESKMISTE VÕRDLEMISEKS
Analyze
–
Nonparametric
Tests –
Legacy
Dialogues –
2
Independent Samples.
Analyze
- nonparametric tests - independent samples -
Mitteparameetriliste
testide menüüribas vaadake käsklust. Valige kõigepealt
Settings.
Choose tests valik
laseb teil määratleda, millist testi te kasutate (soovitatavalt ise
määrata, vastasel korral valib arvuti ise testi).
Test
options alt
saate määratleda olulisuse nivoo. - costumize tests alt
Mann whitney U - Fields - testfields (milliseid keskmisi tulemus võrrelda
soovin, nt antisotsiaalsus) - groups (sugu, kui tahan sugude vahelisi
erinevus võrrelda) - Run - OutPut aknas
avaneb tabel, sinna
topelt klõps ja raporteerid tulemusi.
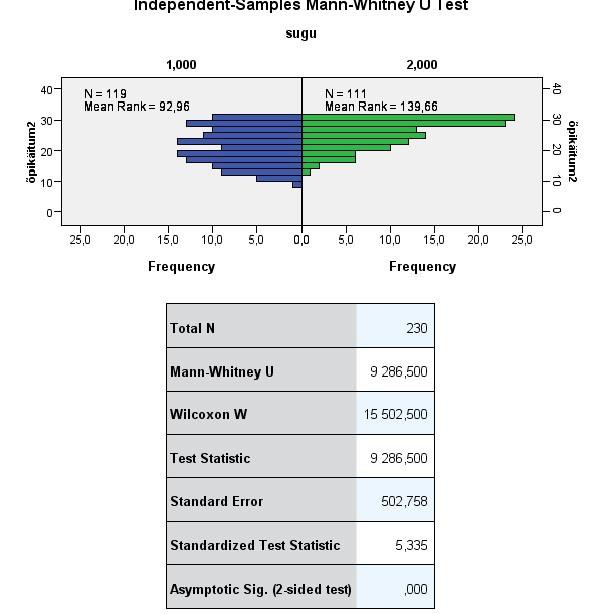
Näidis
raporteering:
Meeste
(n = 111, mastak
=
139.66) ja naiste (n = 119, mastak
=
92.96) keskmised astakud erinesid statistiliselt oluliselt määral,
(Mann-Whitney) U = 9286.50, p = 0.00.
Kahe
sõltuva rühma keskmiste omavaheline võrdlemine:Olukorras
kus on samu indiviide mõõdetud kaks korda on vaja kasutada
paarikaupa
võrdlemise t-testi.
Analyze
-> Compare means -> Paired Samples T test - lisad mõlemad
mille keskmist tahad võrrelda ja okKuidas
testida normaaljaotust?
Selleks
järgige järgmist käskluste rida: Analyze-> Descriptive
Statistics-> Explore-> (ärge unustage valida sõltuvateks
muutujateks ruumiline mõtlemine ja sõnavara ning sõltumatuks
muutujaks sugu)
Plots->
Normality Plots with tests
Võite ära märkida, et tahate joonist histogrammi kujul. Kui olete need
sammud ära teinud, peaks teile ilmuma tabel. Selleks,
et vastata küsimusele – kas on tegemist normaaljaotusega või
mitte – peame
esmalt välja nuputama, millist testi vaatame.
Kolmogorov-Smirnov testi on mõttekas vaadata siis, kui
valim on väga
suur (tuhanded
indiviidid ),
Shapiro -Wilk test on kohane väikese
valimi puhul (u 50-2000 indiviidi). Meie andmestikus on 1350 inimest,
seega võiks kasutada Shapiro-Wilk testi.
Järgnevalt
tuleb vaadata Sig.-i. Kui Sig on väiksem kui 0.05, siis ei ole
andmed normaaljaotuslikud.
Sageduste
võrdlemine:(
Analyze
Descriptive Statistics ->Crosstabs).
Lisaks on võimalik
tellida statistik (
Statistics
-> Chi- Square ),
mis näitab kas nimetatud seos (
risttabeli andmetel ilmnev
koosesinemine) on statistiliselt oluline. Hi
ruut on statistiliselt oluline, kui olulisuse tõenäosus tabelis on
väiksem kui 0.05.
II
KT:Tunnustevaheliste
korrelatsioonide leidmine /paariskorrelatsioon:Analyze->
Correlate -> BivariateValige
kõik alatestid .
Vaikimisi
leitakse Pearsoni korrelatsioonikordaja. Kas see on õigustatud antud
andmetel? Tunnused
peavad olema arvud, vähemalt intervallskaalal
Millised
kaks testi on omavahel kõige suuremas korrelatsioonis? matemaatika
ja
diagrammid (vaatad esimest numbrit kastikeses) Pool tabelit
kordab ennast!!
Ja
millised kõige
väiksemas?
tekst
ja ruumiline
Kas
kõik
korrelatsioonid on statistiliselt olulised? Oluline
kui Sig väiksem kui 0,05 (N ja korrelatsioonikordaja enda suurus)
Nupu
all Option on võimalik valida välistamist:
Pairwise(nt
kui sõnavaral üks vastus puudu, siis jäetakse välja arvutamata
need korrelatsioonid, kus see vastus on puudulik)
and
Listwise deletion
(
Piisab sellest, kui üks vastus puudu alatestis ja jäetakse terve
see indiviid välja)
Tunnuste
vahelised seosed graafiliselt (hajuvusdiagrammi saab teha ainult kahe
muutuja vahel):Graphs
- legacy dialogs - Scatter/Dot - Simple ... - x=matemaatika,
y=diagrammid (Kõrgeim korreltsioon)On
võimalik ka regressioonijoont lisada graafikule:
Topeltklõps
graafikul ja siis klõpsata nupul
Add
Fit Line at Total Sealt
tuleb R(ruut)=0,301 tähendab et 30% on ühisvariatiivsust (kõrgeima
korrelatsiooniga) Lineaarteisendus ja sirge võrrand:transform
- compute variable
-
Uusr=24-5*Ruumiline
Kujutage muutuja Ruumiline ja Uusr vaheline seos graafiliselt.
Analyze
- correlate - bevariate - uusr ja ruumilineLeidke
nende muutujate omavaheline korrelatsioonikordaja.
Kuidas
saadud joonist tõlgendada?
Graphs
- legacy dialogs - scatter – simple..
Mitmene regressioon :OSAKORRELATSIOON LEIDMINE:Osakorrelatsioonide
leidmiseks
kasutame käsklusterida Analyze
– Correlate – Partial. Üles
pisa ja Iq, alla demogracy (sest meid huvitab osakorrelatsioon pisa
ja iq vahel nii, et demokraatiaindeks on kontrollitud) siis üles
pisa ja demogracy ja alla iq (sest meid huvitab see nii, et iq on
kontrollitud).
Kollineaarsus:Linnukesed ette
analyze- regression - linear -statistics
– part and partial correlations ja collinearity ...Oluline
on jälgida, et
Tolerance
ei oleks alla 0.01 ning et
VIF
ei oleks suurem kui 10 - kui on üle 0,01 jn siis pole kollineaarne.
MITMENE REGRESSIOONIANALÜÜSPaarisregressioon:Ennustame...
näide
1: õpilaste lugemise
tulemusi matemaatika
tulemuste
järgi.
näide
2: Kas inimese pikkus
ennustab tema kaalu?
ehk Ennustame inimese kaalu
tema pikkuse
kaudu.
Oluline
ära taibata, kumb on sõltuv ja kumb sõltumatu muutuja!Analyze
-> Regression -> LinearDependent
(sõltuv):
PVREAD (muutuja mille muutumist ennustame, sõltuv muutuja)
Indipendent
(sõltumatu):
PVMATH (muutujad, mida kasutatakse ennustamiseks)
Arvutamise
meetodid: Enter- kõik valitud tunnused pannakse mudelisse
Foward-
mudelisse lisatakse sammhaaval need tunnused, mis mõjutavad sõltuvat
tunnust statistiliselt olulisel määral
Backward-
kõik tunnused pannakse mudelisse ning hakatakse statistiliselt vähem
olulisi välja võtma.
Paarisregressiooni
puhul pole mingit tähtsust meetodil. Ehk vaikimisi meetod Enter
sobib väga hästi.
Vajuta
OK!
Tulemuseks
mitu tabelit:
Esimeses
tabelis tuuakse ära muutujate vaheline
korrelatsioon (R) ja
determinatsioonikordaja (R square), mis näitab
regressioonivõrrandi
ennustusvõimet
(korruta
100ga). Näiteks: Model summary tabel output aknas: R-ruut ehk
determinatsioonikordaja
ütleb et 70% lugemise tulemustest on kirjeldatud/ennustatud ära
matemaatika tulemuste kaudu.
Kordaja
statistiline olulisus:
ANOVA tabeli viimane sig.
Järgmises
tabelis on regressioonivõrrandi statistilise olulisuse näitaja. Ehk
teisisõnu , kui kasutame antud võrrandit ennustamiseks, kui suur on
eksimise tõenäosus.
Coefficients 'ide tabelist:
vabaliikme
statistiline olulisus
( vaatad constanti sig'i)
Lineaarne
seos:Saab
kontrollida:
Analyze
-> Regression -> Curve estimation. Püsivad
lineaarsel
joonel siis on lineaarne seos.
Regressiooni
võrrand
(arvud leiad Coefficients'ide tabelist):
Näide
1: PVREAD(see
mille tulemust
ennustad )=40,66(Constant
B ümardatult)+ 0,89(PVMATH
B)*PVMATH
(see
pole arv, vaid muutuja nimetus)
Näide
2:
vocab = -0,011+0,358*
reading +0,428*sentcomp+0,2*mathmtcs
Regressioonanalüüsi
eeldused
on järgmised:
1) jäägid
olgu
normaaljaotusega
(Normaaljaotuse
testimiseks, analyze-descriptive stat – explore – panin Jääkide
andmed ehk RES_1 esimesse kasti ja ok - Output aknas vaatad
Shapiro-Wilk'i sig'i kui valim on 50-2000 inimest - normaaljaotusega
on tegu siis, kui sig väiksem kui 0,05)2) jääkide dispersioon peab olema sõltumatu (ehk siis x-telje)
muutuja väärtusest sõltumatu.
Kuidas
kontrollida kas regressiooni jäägid jaotuvad normaaljaotusele
lähedaselt?
Laseme
arvutada mudelikohased sõltuva muutuja väärtused ja jäägid:
Analyze
-> Regression -> Linear - Save - Linnuke kasti Predicted
values (unstandardized) ja Residuals (unstandardized). Järgneb
jääkide täpsem
diagnostika (kas on normaaljaotusega jne).
Logistiline
regressioonLogistiline
regressioon või
üldisemalt logistiline mudel ehk logit-mudel
prognoosib uuritava sündmuse toimumise tõenäosust ja selle
muutumist sõltuvalt pideva argumenttunnuse väärtuse muutumisest.
Näiteks uurimaks, kas
isiksuseomadused ennustavad
eesnäärmeuuringutele minekut tulevikus. / Uuritakse, kas
suutmatus tähele panna (inattention_inatt18a), sugu ja tulemus Raven’i
testis ennustavad kõrghariduse saamist 25-ks eluaastaks EHK
ennustame inimese kõrghariduse
saamist 25ndaks eluaastaks
soo,
raveni testi ja inattention'i
kaudu.
Analyze
-> Regression -> Binary Logistic.
(Dependent
alla see muutuja mida ennustatakse ehk haridustase ja covariate
alla see muutuja(d) mille kaudu ennustatakse, ehk sugu, raven ja
inattention) - OK
Esimesed
3 tabelit, näitavad baasmudelit, sellist millesse pole valitud
ühtegi sõltumatut muutujat.
Tabelid enne Block 0-i näitavad üldiselt analüüsitud andmete kohta.
- Tabel Model Summary alt saab vaadata mitu % varieeruvust nt kõrgharidusklassi kuulumises mudel kirjeldab. Cox&Snell alt tuleb nt 0,084 ehk 8,4% kuni Nagelkerke alt 0,117 ehk 11,7%. See tähendab, et mudel kirjeldab 8.4-11.7% varieeruvust kõrgharidusklassi kuulumises.
- Tabel Classification tabel(a) on vajalik, et teha mudelikohane ennustus gruppi kuulumise kohta. Nt on uuritud kõrgharidusega ja kõrghariduseta inimesi ja Percentage correct alt leiab mõlemate inimgruppide protsendid, et mitu protsenti ennustab see mudel õigesti kõrgharidusega/-ta gruppi kuulujatest. / Näitab, et korrektselt saab järeldada nii suure protsendi osalejate kohta kui vaadata tabeli Classification Table(a) alumist protsenti.
- Tabel Variables of the equation: Esimese tulba põhjal saab välja kirjutada regressioonivalemi ja viimase tulba põhjal saab otsustada sõltumatu muutuja mõju üle (mida lähemal 1-le, seda väiksem mõjujõud sellel teguril on).
+
saab vaadata sig'i.
FaktoranalüüsFaktoranalüüs:Analyze
- Dimension Reduction - Factor (muutujateks
valida need, mille faktorstruktuuri uurida tahetakse, näiteks kõik
alatestid)
- Kui soovitakse teha peakomponentide analüüs, siis ei ole rohkem midagi muuta vaja, lihtsalt OK.
- Aga meie kursuse raames tuleb kasutada teistsugust analüüsi - samas aknas vajutada paremalt Extraction - sealt üleval valida rippmenüüst Principal Axis Factoring - OK
- Communalities tabel (output aknas):
- Kui seal tabelis arvud on suured siis see näitab, et nende faktorite kommunaliteet sobitub faktorite koplekti hästi. wtf?
- Tabel "Total variance explained":
- Omaväärtus (eigenvalue) näitab kui palju andmete varieeruvusest seletab konkreetne faktor. Mida kõrgem väärtus, seda rohkem varieeruvust faktor seletab.
- Viimases lahtris Cumulative % näitab protsenti andmete kumulatiivsusest.
Omaväärtuste
graafik (Scree Plot ):
Tuuakse ära kõigi võimalike faktorite omaväärtused. Joonise
järgi saab otsustada eristatavate faktorite arvu.
- Kui eristatavate faktorite arv on ette antud, siis: Factor Analysis - Extraction - Number of Factors. Sealt samast saab ka määrata, et Scree Plot joonistatakse: Factor Analysis - Extraction - Scree Plot
- Tabel Factor matrix arvutab faktorkaalud kõigil indikaatoritele seotuna kõigi faktoritega.
- Mida suurem faktorkaal on, seda tõenäolisemalt see indikaator on antud faktori poolt määratud. Suuruse järgi järjestamiseks = analyze - dimension reduction - factor - options=sorted by size.
- Soovides ette anda väärtuse, millest väiksemaid ei kuvata (Options - Supress absolute values less than ...)
Faktorite pööramine :
matemaatiline tehnika, mis võimaldab jõuda lihtsaima faktorite
mustrini.
- Analyze - Dimension reduction - Factor - Rotation (paremalt), saab valida erinevad faktorite pööramise viisid:
- Varimax=toimub eeldusel , et kaks faktorit on risti omavahel ja pole seotud omavahel (eksisteerib harva)
- Direct Oblimin= võimaldab kaldpöördumist (vali see! Deltat ei muuda, see jääb nulliks) - OK
- Output aknas:
- Tabel "Structure Matrix": mida suurem arv seda mõjuvam.
- Faktorskooride salvestamine:
- Analyze - Dimension reduction - Factor - Scores (paremalt) - save as variables - ok. Tekib kaks uut faktorite muutujat tabelisse ja saab neid uurida.
- Tekkinud faktori Cronbachi alfa arvutamiseks: analyze- scale -reliability analysis - kõik testi muutujad sinna muutujate kasti - statistics (paremalt) - "Item" ja "Scale if item deleted" ette linnuke - ok.
- Tabel "reliability statistics" annab cronbachi alfa kõigi testide peale kokku.
- Tabel "Item-total statistics" annab cronbachi alfa erladi iga testi lõikes.

























Kõik kommentaarid