Statistika on teadus, mis uurib andmete kogumist, töötlemist, analüüsi ja järelduste tegemist. Üldistav statistika: andmete põhjal järelduste tegemine üldisemale grupile. Pakub meetodeid vea hindamiseks (vea me teeme nagunii). Kirjeldav statistika: kirjeldab neid andmeid, mida mõõtsime. Tehakse järeldusi, aga ainult nende andmete kohta, mida kogusime. Üldkogumi all mõeldakse kõiki juhtumeid või objekte, mille kohta meie poolt püstitatud järeldused, oletused kehtivad. Mõõtmiseks valitud (uuringusse kaasatud) üldkogumi osa nimetatakse valimiks. Valimi tingimused: Juhuslik – kõigil üldkogu liikmeil on võrdne võimalus sattuda valimisse. Esinduslik – samad proportsioonid, mis on üldkogus, peavad olema ka valimis. Piisavalt arvukas. Tunnused- nimi, järjestus, intervall, binaarne. Võtmeküsimused: Kas väärtused on järjestatavad? Kas skaalavahemikud on võrdsed? Nimitunnused nimi, sugu, perek. seis, elukoht, maakond.
Statistiline modelleerimine – kokkuvõte Muutujad: Sõltuvad muutujad (dependent, outcome variables) – muutujad, mis on uurimise keskmes, millele uurija arvab, et teised muutujad mõju avaldavad. Nö katseisikust sõltuv muutuja. Sõltumatud muutujad (independent, predictor variables) – muutujad, mille kohta uurija arvab, et neil võiks olla mõju uuritavatele muutujatele. Statistilise analüüsi keskmes on uurida, kuidas teatud tunnused koos muutuvad. Kui on vaja muutujat iseloomustada, on kaks põhilist viisi, kuidas seda teha: o Milline on selle muutuja tüüpiline väärtus? o Kui hästi iseloomustab see tüüpiline väärtus kõiki mõõdetud juhtumeid? Ehk kui palju on varieeruvust selle tüüpilise väärtuse “ümber”? Statistika jagunemine: Kirjeldav statistika (descriptive stat.) meetodid andmetest kokkuvõtete tegemiseks ning kirjeldamiseks. („65-70% U
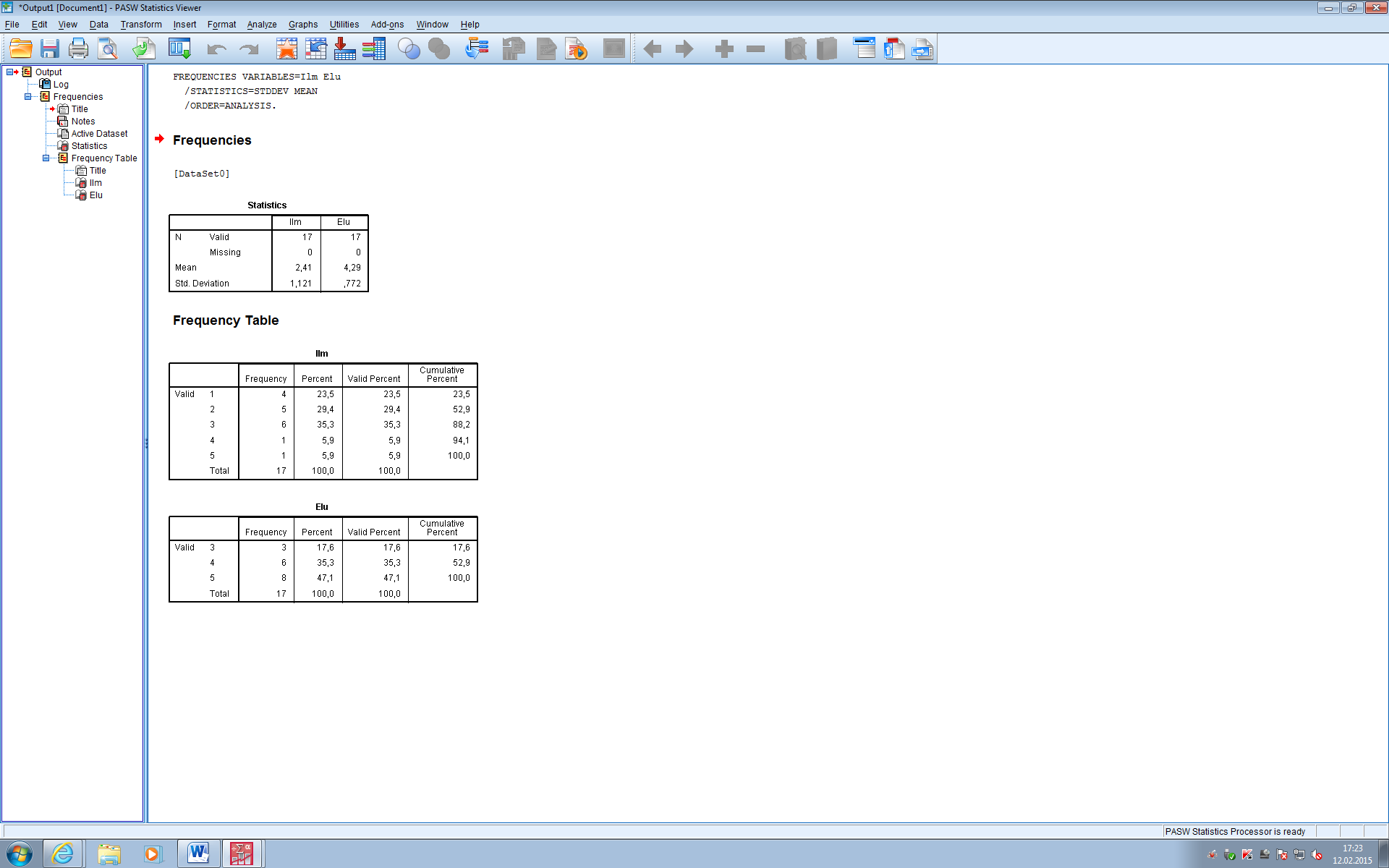
KIRJELDAVAD STATISTIKUD INTERVALLITUD REAS Kirjeldav statistika on numbriliste andmete organiseerimine ja summeerimine, see on vajalik andmeanallüüsi esimesel etapil. Valimit kirjeldatakse, kuid üldistusi ei laiendata üldkogumile. Kirjeldav statistika annab järgmist informatsiooni: uuritava tunnuse väärtuste vahemik tunnuse kõige tüüpilisemad väärtused tunnuse varieeruvus Lisaks aitab kirjeldav statistika sõnastada hüpoteese ning tõlgendada uurimistulemusi. Asendikarakteristikud(annavad infot selle kohta, kuidas tunnuse väärtus paikneb). Need on aritmeetiline keskmine, mediaan ja mood. Nende välja arvutamine oleneb sellest, pas meil on tegu pidevate(mingi vahemik) või diskreetsete(1 väärtus) andmetega. Hajuvuskarakteristikud(kui erinevad on väärtused valimi erinevatelobjektidel).Nende eesmärgiks on mõõta andmete varieeruvust andmekogumis(iseloomustavad tunnuse üksikväärtuseerinevust keskmisest) Need on d
Ökonomeetria KT kordamisküsimused 1. Ökonomeetrilise mudeli komponendid. ● Modelleeritavad näitajad: endogeenselt (sisemiselt) määratud ehk sõltuvad muutujad (Y). Väärtused määratakse mudeli siseselt ● Modelleeritavat nähtust mõjutavad näitajad: eksogeenselt (väliselt) määratud ehk sõltumatud, seletavad muutujad (X). Väärtused määratakse mudeli väliselt. ● Statistiliste meetoditega hinnatavad mudeli parameetrid (b). ● Juhuslik komponent ehk vealiige (u). 2. Andmetüübid. Ökonomeetriline mudel baseerub arvandmetel: ● Ristandmed (cross-sectional) ● Aegread (time series) ● Paneelandmed (panel data) Andmed saavad olla kas ● Kvalitatiivsed (ei saa mõõta arvudega, nt haridustase) ● Kvantitatiivsed (mõõdetakse arvudega, nt vanus) 3. Valimvaatlused ja parameetri hinnangu mõiste. ● Uuritav objekt on üldkogum ● Andmebaas on üldjuhul valim Järeldusi soovime teha üldkogumi kohta, selleks kasuta
1. PRAKTIKUM 1) JÄRJESTAMINE NOOREMAST VANIMANI Parmeklõps Sort Ascending/Descending -> Kasvavas/Kahanevas järjestuses Data Sort cases Sort Ascending/Sort Descending (tuleb valida muutujad ka) 2) VARIABLE VIEW 3) KIRJELDAVAD ANDMED Leiame vanusele antud hinnangute keskmise, moodi, mediaani, maksimaalse ning minimaalse hinnangu. + HISTOGRAMM Käsklusrida: Analyze - Descriptive statistics Frequencies. Muutujatekasti liigutage muutuja. Statistics -Mean, Mode, Median, Minimum, Maximum. Charts - Histograms 2. PRAKTIKUM 1) UUE MUUTUJA ARVUTAMINE Tihtipeale tuleb andmete töötlemise jooksul tekitada uusi muutujaid eelmiste muutujate põhjal. Käesolevas praktikumis tutvume uue muutuja arvutamise põhitõdedega. Etteruttavalt võib öelda, et me arvutame saadavaloleva andmestiku põhjal uueks muutujaks kehamassiindeksi (BMI body mass index). Käsklusrida: Transform Compute variable
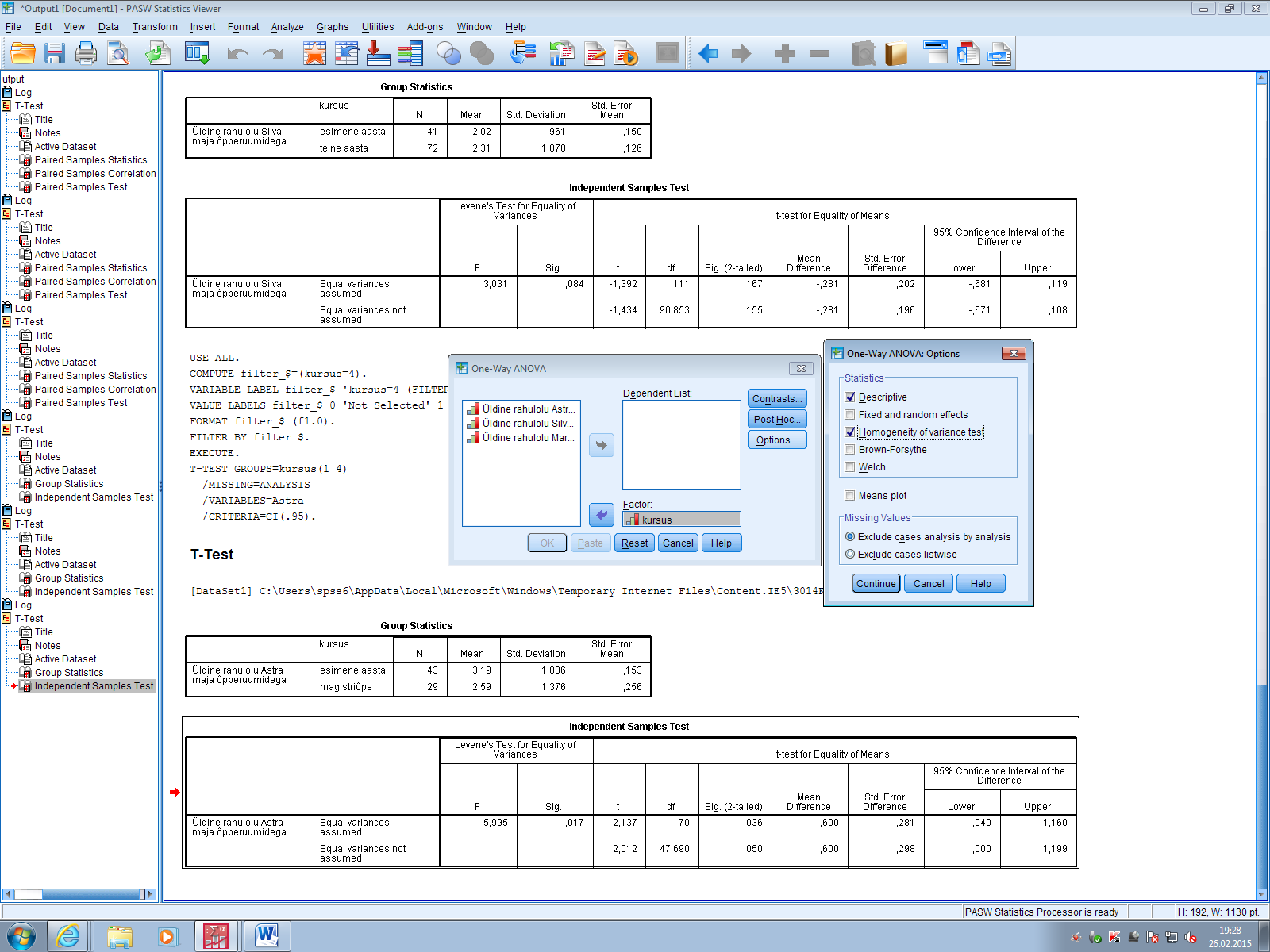
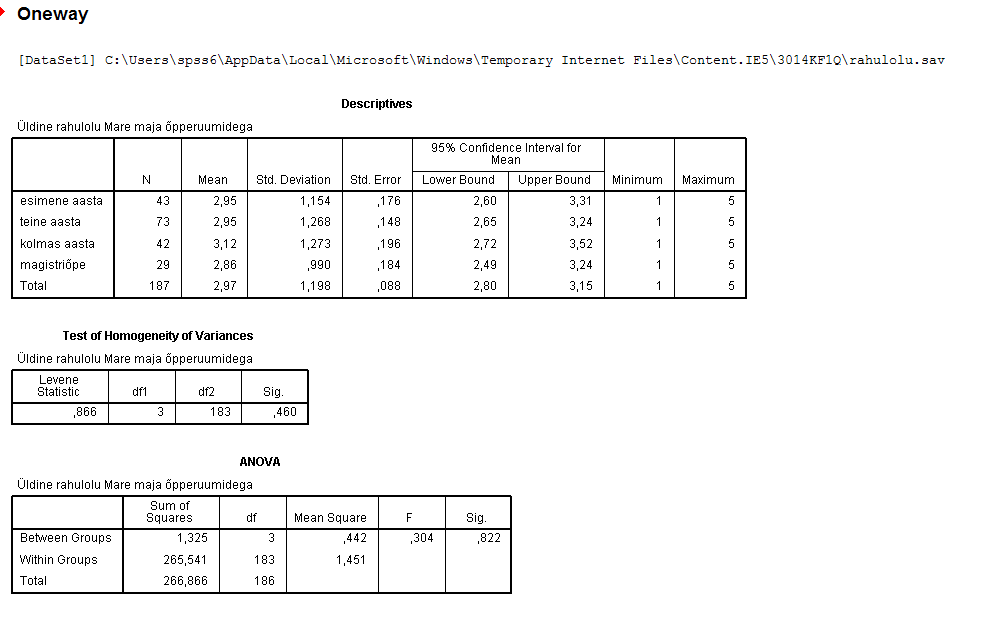
ANDMEANALÜÜSI KONSPEKT Sisukord Andmefailid SPSS'is................................................................................................ 2 Normaaljaotuse kontroll.......................................................................................... 2 ANOVA vs T-test...................................................................................................... 2 ANVOA või regressioonanalüüs............................................................................... 3 Efekti suurus........................................................................................................... 3 Andmeanalüüs SPSS'is........................................................................................... 4 Kirjeldav statistika............................................................................................... 4 Kuidas testida normaaljaotust?.........................................................................
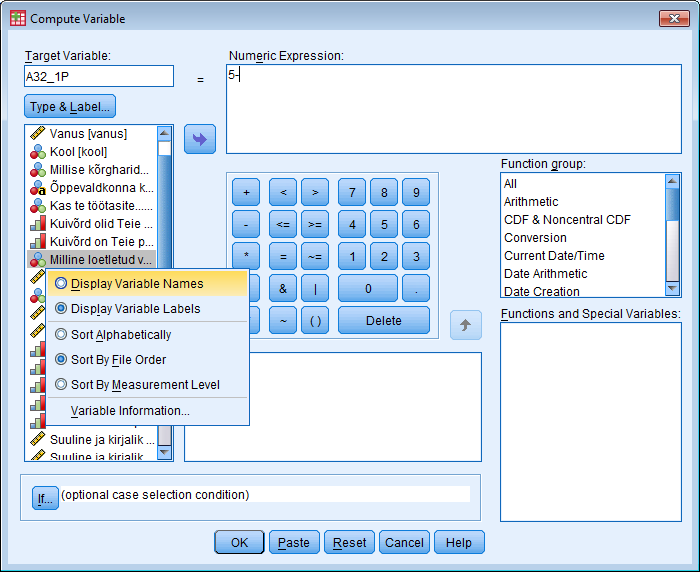
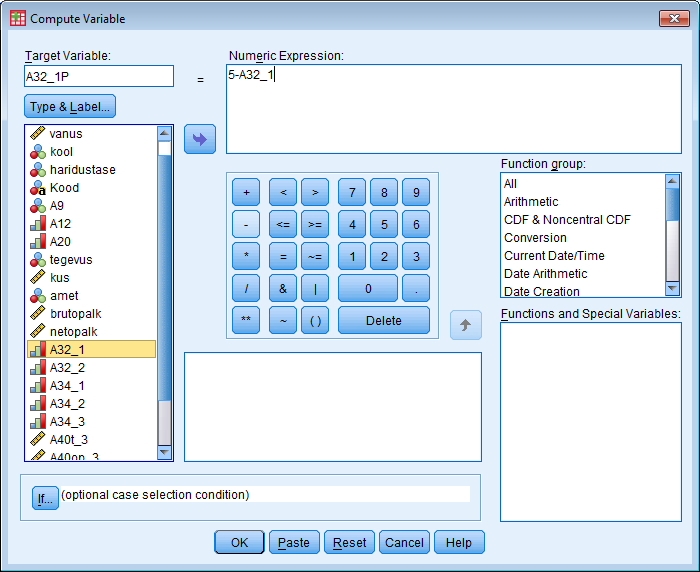
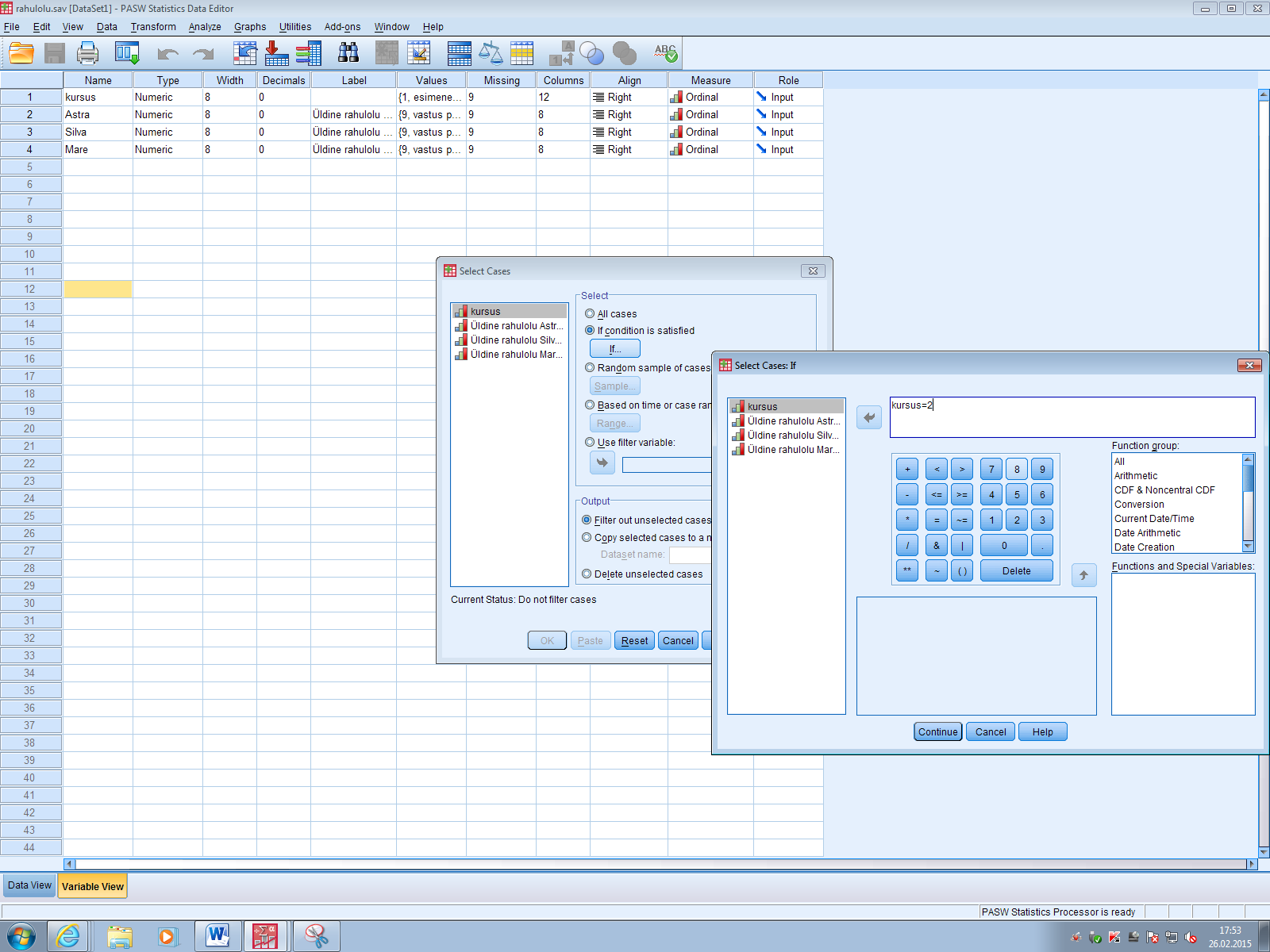
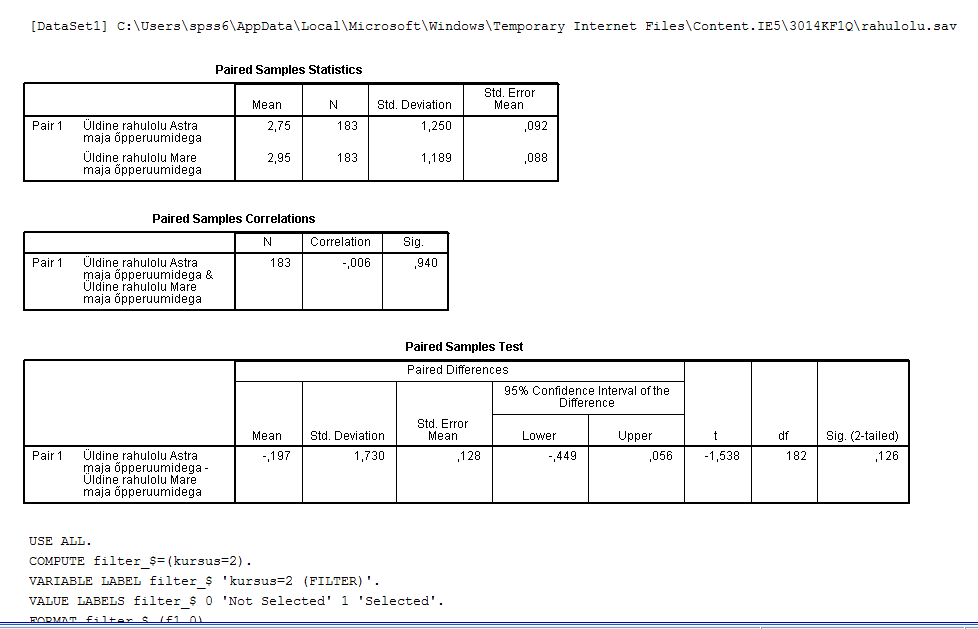
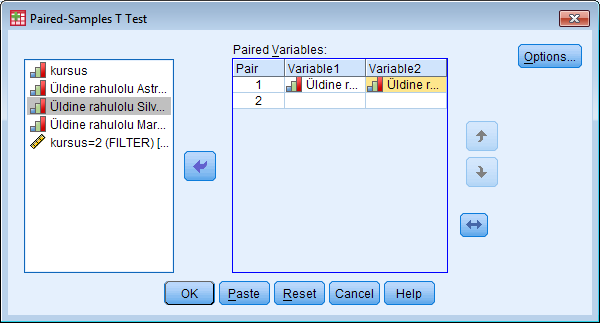
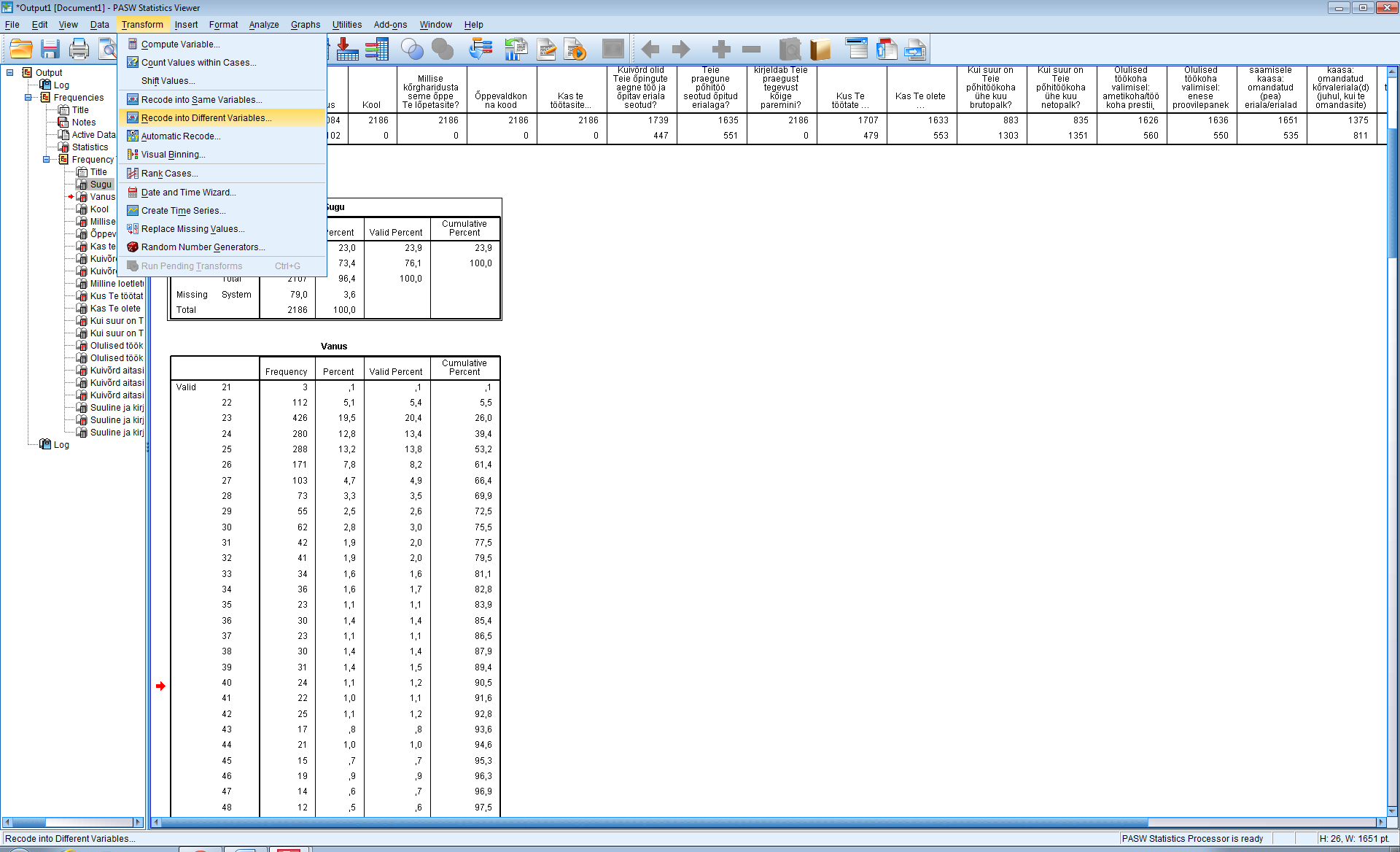
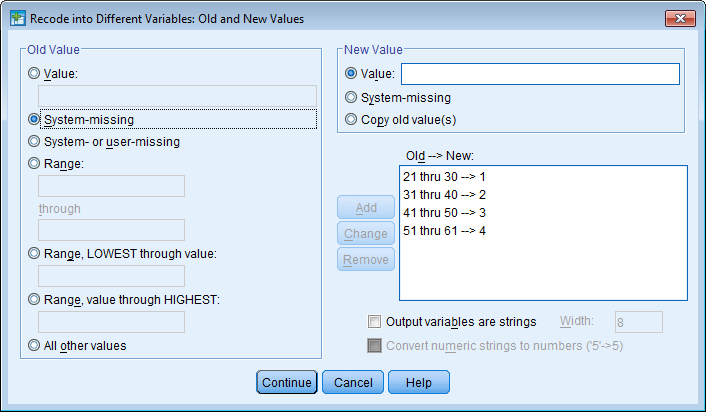
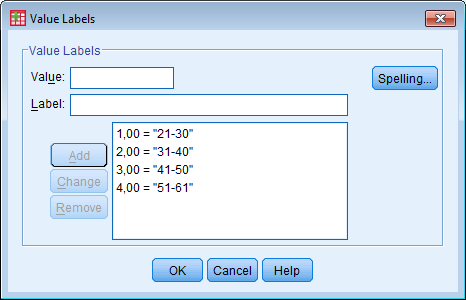
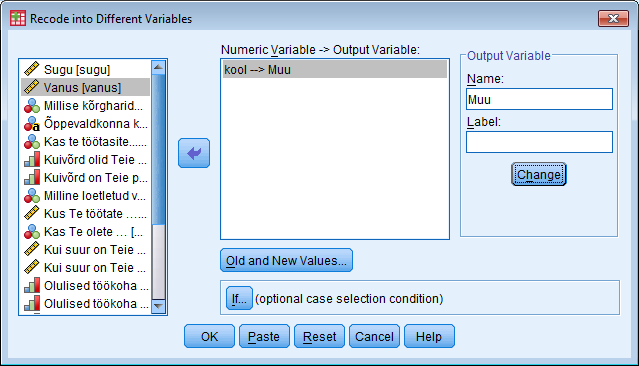
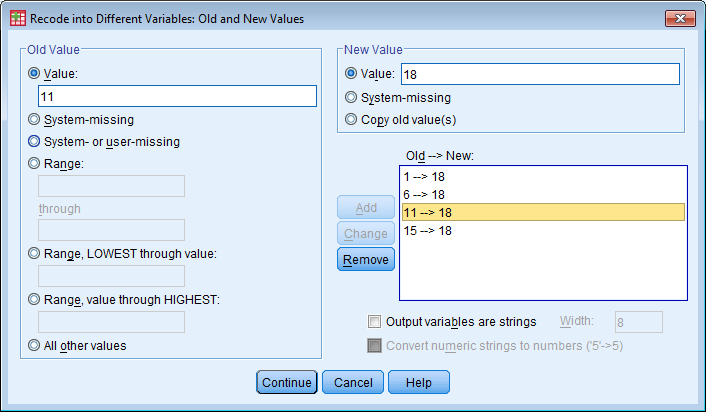
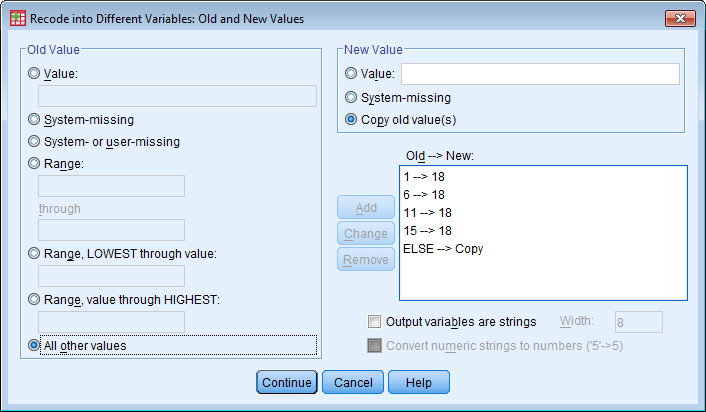
Soo defineerimine: Variable view - soolahtrist Values... - 1=mees, 2=naine - data view - ülevalt view - value labels ette linnuke Kasvavas järjekorras järjestamine: Teed lahtri aktiivseks mida järjestada soovid - ülevalt Data - Sort cases - valid mida soovid sortida - linnuke ascending lahtri ees kindlalt ja OK Mingi väärtuse minimaalse ja maksimaalse väärtuse leidmine, standardhälve, keskmine: Analyze - descriptive statistics - descriptives/frequencies (kui vaja ekstsessi, histogrammi kellukat jn) - valid mille puhul tahad uurida - Options - valid milliseid väärtusi leida tahad ja ok, vastused ilmuvad OutPuti aknasse. Charts all on võimalik kasutada histogrammi joonistamise võimalust. Joonisel olev küsimärk käib osutatud linnukese kohta. Display frequency tables annab käskluse moodustada iga pikkuse kohta sagedustabel. Küsimärk on juurde tehtud, et uurida, kas sellise tabeli koostamine on vajalik. Uue muutuja arvutamine: Transform - Compute variable - kirjutad u
Kvant met 40% EKSAM 25% KT 25% 10% Kirjandus: SAMM, Tooding L-M jne Uurimisprobleemi püstitamine (sots)teaduses: Probleemi leidmine ja teema sõnastamine Probleemipüstituse põhjendus Kuidas ma saan aru, et see on selline probleem, mida tasub uurida? Selle praktiline tähtsus, seos teiste valdkondadega, takistavad tegurid selle uurimisel Täpsustamine Millist osa ma sellest probleemist uurida tahan? Alamülesanded v teemad Kas ja mida varasemast teada on? Teooriad, varasemad uurimused Operatsionaliseerimine Kuidas defineerida Kuidas mõõta, uurida Analüüsimeetodi valik Sotsiaalsete probleemide konstrueerimine Sots.teaduses on uurija oma uurimisobjekti (ühiskonna) osa ja mõjutab seda enda tegevusega Statistika kui relv (sots)poliitikas Numbrilised väited sots elu kohta (n-ö objektiivsed) Sots probleemide tõlgendus, põhjendus Sots probleem: kas see on olemas v on see kellegi poolt konstruee








































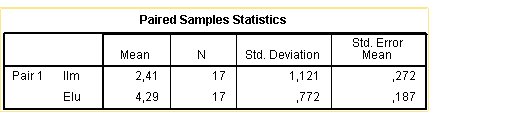
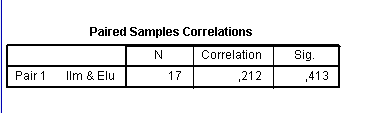
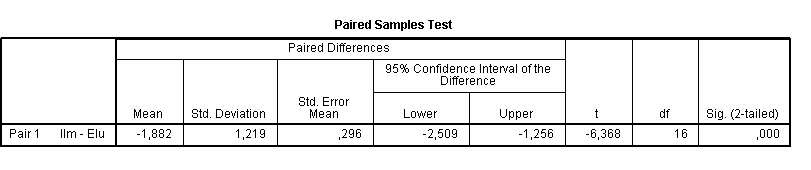



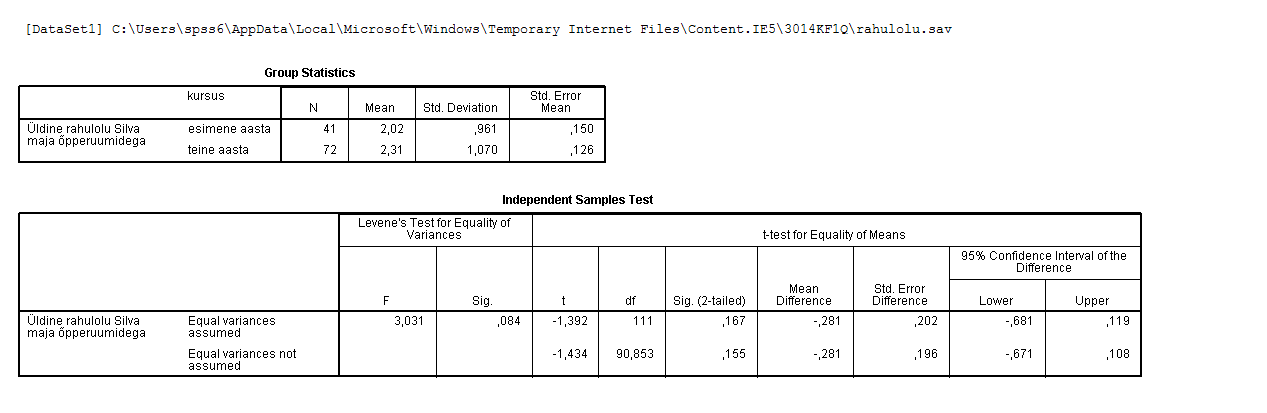
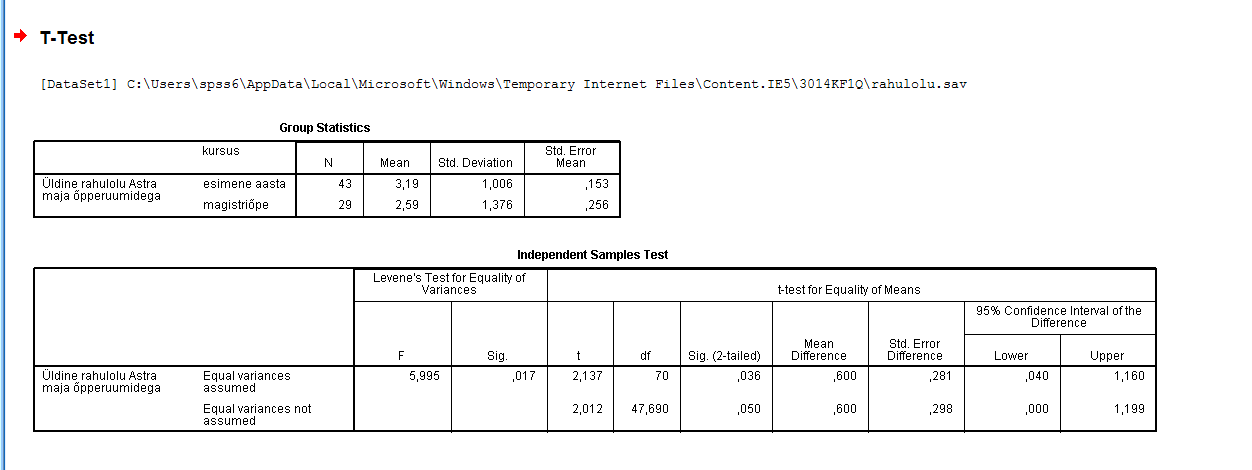
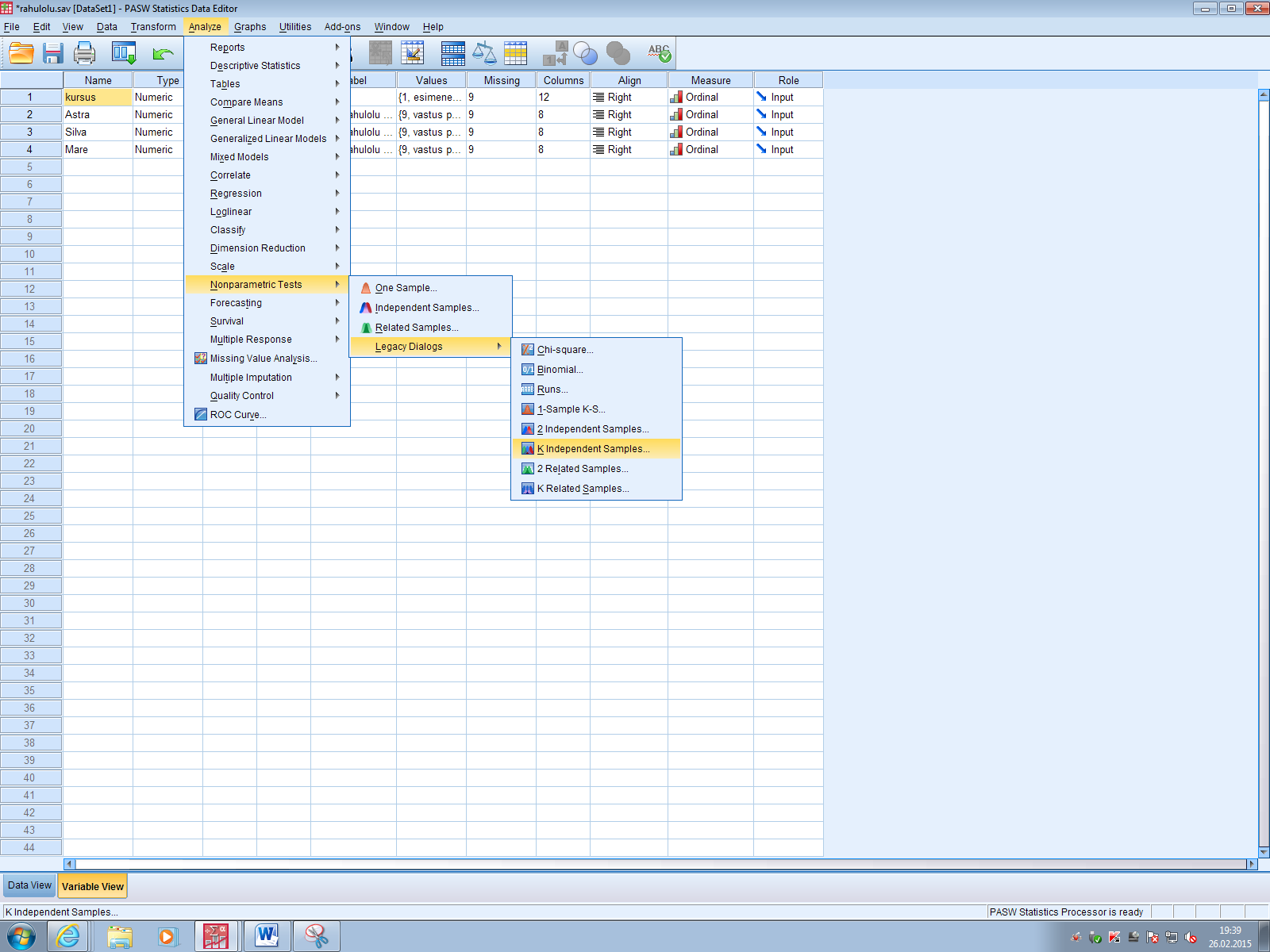
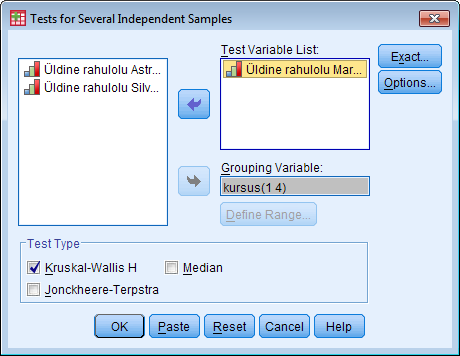
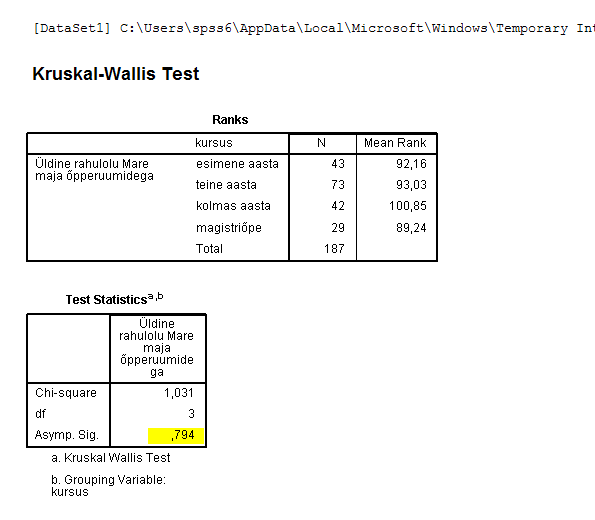
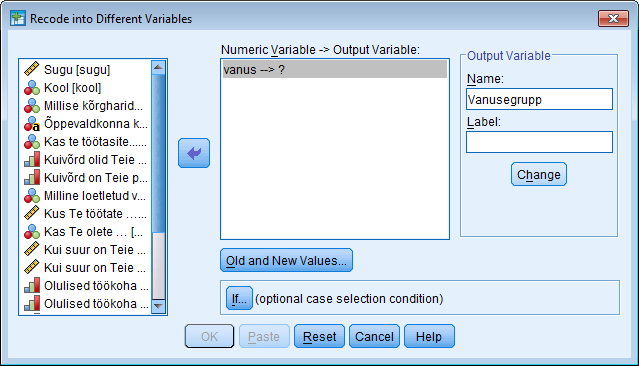




Kõik kommentaarid