Statistiline modelleerimine –
kokkuvõte
Muutujad:
Sõltuvad muutujad (dependent, outcome variables) – muutujad, mis on uurimise
keskmes, millele uurija arvab, et teised muutujad mõju avaldavad. Nö katseisikust
sõltuv muutuja.
Sõltumatud muutujad (independent, predictor variables) – muutujad, mille kohta
uurija arvab, et neil võiks olla mõju uuritavatele muutujatele.
Statistilise analüüsi keskmes on uurida, kuidas teatud tunnused koos muutuvad.
Kui on vaja muutujat iseloomustada, on kaks põhilist viisi, kuidas seda teha:
o Milline on selle muutuja tüüpiline väärtus?
o Kui hästi iseloomustab see tüüpiline väärtus kõiki mõõdetud juhtumeid? Ehk
kui palju on varieeruvust selle tüüpilise väärtuse “ümber”?
Statistika jagunemine:
Kirjeldav statistika (descriptive stat.) meetodid andmetest kokkuvõtete tegemiseks
ning kirjeldamiseks. („65-70% USA elanikest on ülekaalulised või rasvunud.“)
Järeldav statistika (inferential stat.) kasutab andmeid baasina hinnangute
andmiseks ja prognooside tegemiseks. („Ülekaalulisus on II tüübi diabeedi
riskifaktorite hulgas.“)
Kirjeldav statistika tegeleb valimi resümeerimisega, järeldava statistika ülesanne on
üldistuste tegemine üldkogumi kohta.
Üldkogum (populatsioon)
on teatud nähtuste (objektide, isikute) hulk, mida soovitakse
objektiivsete meetoditega tundma õppida (näiteks üliõpilased Eestis)
Valimiks
nimetatakse teatud hulka üldkogumi elemente, mille mõõtmisandmed on
uurija käsutuses
Mõõteskaalad:
Kategoorilised muutujad
o Binaarne skaala
– kahene skaala (binaarkood: 0;1)
o Nominaalne skaala
– eristab andmeid, kuid ei anna suunda ega väärtust (nt
sugu, kodulinn, rass jms)
o Ordinaalne ehk järjestusskaala
– eristab andmeid ja annab suuna, kuid mitte
vahemike (nt haridustase või subjektiivne rahulolu)
Pidevad muutujad
o Intervallskaala
– eristab andmeid, annab suuna ja vahe nende suuruste vahel,
kuid puudub nullpunkt (nt temperatuur Celvini või Farenheiti skaalal (Kelvini
skaalal on defineeritud absoluutne nullpunkt -273,15°C))
o Suhteskaala
- eristab kõiki eelnevaid punkte, kuid lisaks eksisteerib ka
nullpunkt (nt raha)
o Lickerti skaalal tehtud mõõtmisi on lubatud käsitleda vajadusel pideva
muutujana
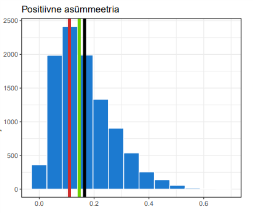
Jaotused (normaaljaotus, negatiivne asümmeetria, positiivne asümmeetria)
:Andmetöötluse alused:
Valemid ja tähised
n või
N – juhtumite arv
x – muutuja
X̅ või
µ – keskmine
i – indekseerimistähis
σ või
SD – standardhälve (standard deviation)
σ2 või
SD2 – hajuvus
Σ – summeerimine
Standardhälve
Näitab, kui hästi keskmine esindab mõõdetud andmeid.
Muutjal on keskmine väärtus ja iga juhtum on sellest teatud kaugusel: x1-
X̅
Hajuvus on keskmine ruutkaugus, seega standardhälve on nö keskmine kaugus
keskmisest:
Normaaljaotuse puhul paikneb kõigist mõõtetulemustest
68,27% ±1SD,
95,45% ±2SD
ja
99,73% ±3SD kaugusel keskmisest.
Kaugus keskmisest (indiv. tulemusest lahutada keskmine) jagatud standardhälbega;
z-skoor
Iga z-skooriga on seotud teatud tõenäosus, mille järgi on võimalik hinnata selle
väärtuse esinemissagedust.
Andmeanalüüsimeetodeid välja töötades on kasutatud eeldusi:
Kui tunnus on arvuline ja ligilähedane normaaljaotusele, saab sellele rakendada
parameetrilist statistikat.
Järjestustunnuste või mitte-normaaljaotuslike tunnuste puhul tuleks kasutada
mitteparameetrilisi teste.
Statistilised momendid
Mõningaid jaotuse kirjeldamiseks kasutatud kirjeldavaid statistikuid nimetatakse ka
momentideks.
Esimest järku moment on aritmeetiline keskmine, teiseks momendiks on hajuvus,
kolmandaks asümmeetria ja neljandaks järsakus.
Esimest ja teist järku momendid (keskmine ja hajuvus) aitavad hinnata muutuja
tüüpilist väärtust ja seda kui hästi see tüüpiline väärtus kõiki mõõdetud juhtumeid
iseloomustab (ehk hajuvust keskmise ümber)
Kolmandat ja neljandat järku momendid on abiks andmete normaaljaotuslikkuse
hindamisel.
Shapiro-Wilk test
Uurib, kas andmestik erineb oluliselt normaaljaotusest.
Kui olulisuse tõenäosus (p) on väiksem kui 0.05, siis testi kohaselt andmed ei ole
normaaljaotuslikud.
o Vaikimisi eeldame, et andmestikes muutuja jaotus ei erine oluliselt
normaaljaotusest. S-W hindab, kas meil on piisavalt tõendeid, et see väide
ümber lükata.
Standardiseerimine
Tulemuste z-skooridele viimine
Valem:
Peaks olema lähedane normaaljaotusele:
Standardiseeritud andmestiku keskmine antakse kujul:
Xe-A ;see tähendab, et X-i
komakohta peab liigutama A võrra vasakule, et saada selle andmestiku keskmist
väärtust:
Keskmine väärtus on alati 0 või väga lähedal 0-le.
Standardhälve on täpselt 1.
Skewness – asümmeetriakordaja
•
Kokkuleppeliselt on tegemist normaaljaotusega, kui asümmeetriakordaja väärtus on
vahemikus [-2; 2], konservatiivsemalt ka [-1; 1]
Kurtosis – järsakuskordaja ehk ekstsess
•
Kokkuleppeliselt on tegemist normaaljaotusega, kui järsakusastmekordaja väärtus on
vahemikus [-2; 2], konservatiivsemalt ka [-1; 1]
•
Standardviga SEM
Hindab, kuidas on KI testi tulemused kordusmõõtmistel jaotunud tema nö tõelise
tulemuse ümber. Näitab, kui palju meie ennustused mudeli parameetrite kohta võivad
varieeruda.
Valimite aritmeetiliste keskmiste jaotuse standardhälve.
Lihtsustatult: SEM= σ / √nn, ehk valimi standardhälve jagatuna valimi suuruse
ruutjuurega.
Üksiktulemuste puhul SEM = σx √n 1- rxx, kus SEM on funktsioon testi reliaablusest
rxx ja testiskooride variatiivsusest σx.
Mida suurem hajuvus valimis, seda suurem standardviga.
Standardviga saab vähendada, suurendades valimi suurust.
Mida väiksem standardviga, seda kindlamad võime olla, et valimi aritmeetiline
keskmine on lähedane üldkogumi keskväärtusele.
Usalduspiirid
Üldkogumi keskväärtuse usalduspiiriks nim. valimi põhjal määratud vahemikku, kuhu
valimi keskmine kuulub teatud tõenäosusega (enamasti 95%, aga ka 99%). Ehk kui
kordaksime testi, siis selle teatud tõenäosusega jääks ka uue valimi keskmine
nendesse piiridesse. Kui näiteks kahe võrreldava grupi usalduspiirid ei kattu, saame
öelda, et tõenäoliselt laieneb valimi erinevus ka populatsioonile.
Vastavalt usaldusnivoo väärtusele arvutatakse parameetri usalduspiirid so. kaks arvu,
mille vahel parameeter asub etteantud tõenäosusega.
Valem 95% usalduspiiride arvutamiseks:
Alumine usalduspiir= X̅-1.96SD*SEM
Ülemine usalduspiir= X̅+1.96SD*SEM
Usaldusnivoo (confidence level) on psühholoogias 95%, ehk et 95 % tõenäosusega
on tulemus usaldusäärne.
Olulisusnivoo (level of significance) ehk vea tõenäosus on sellisel juhul p=0,05 ehk
tõenäosus eksida valimi tulemuste populatsioonile laiendamises on 5%
o Esimest liiki viga – arvatakse, et tulemused kehtivad populatsioonile, kuigi ei
kehti (false positive)
o Teist liiki viga – arvatakse, et tulemused ei kehti populatsioonile, kuigi
kehtivad (false negative)
Hüpoteeside testimine ehk keskmiste võrdlemine:
Vaja vastata küsimustele: (1) kas rühmad (või valimid ja nende jaotused) on nii sarnased, et
võime öelda, et nad kuuluvad samasse üldkogumisse või (2) on nad nii erinevad, et
esindavad kahte erinevat üldkogumit? (Nt. Kas naissoost üliõpilased saavad sõnavaratestis
paremaid tulemusi kui meessoost üliõpilased?)
Hüpoteesi kontrollimine:
püstitada nullhüpotees (nt erinevust ei ole) ning alternatiivne e. sisuline hüpotees
(erinevus on)
defineerida testimise protseduur, sealhulgas olulisuse nivoo (psühholoogias 95%)
otsustada, millist keskmiste erinevuste testi kasutada
arvutada teststatistikud ja nendega seotud olulisuse tõenäosused
arvutada efekti suuruse näitajad
teha järeldus, kas andmed on kooskõlas nullhüpoteesiga või mitte
Nullhüpotees ja alternatiivne hüpotees:
Alustatakse eeldusest, et valimid ei erine; H0: μ1= μ 2 (nullhüpotees)
Kui erinevus kahe valimi aritmeetilise keskmise vahel osutub liiga suureks (ehk on
statistiliselt oluline erinevus), et pidada neid valimeid ühest üldkogumist pärinevaks,
lükatakse nullhüpotees ümber ja jäädakse alternatiivse hüpoteesi juurde.
Efekti suurus:
Leidnud statistiliselt olulise mõju (erinevuse), tuleb arvutada ka, kui suur see mõju
(erinevus) on.
Arvutatakse Coheni d
o d < 0,2 – väike efekt
o 0,2 < d < 0,8 – keskmine ehk arvestatav efekt
o d > 0,8 – suur efekt
Nö on tegu keskmiste erinevusega standardhälbe ühikus. Ehk kui d=0,5, siis
keskmised erinevad üksteisest poole standardhälbe võrra.
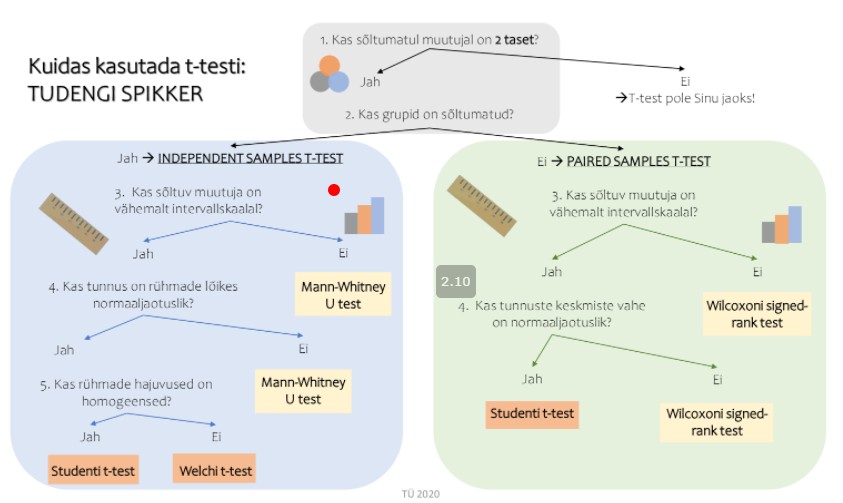
Võrreldavate rühmade liigitamine (T-testid)
On üksteisest kaks sõltuvat või sõltumatut rühmad
Kui erinevad rühmad tekivad näiteks sootunnuste (või muu rühmitava tunnuse)
alusel, siis on rühmad üksteisest sõltumatud ja kasutatakse
t-testi sõltumatute
rühmade jaoks (independent samples t-test)
Kui võrreldakse ühe ja sama katsegrupi seisundeid erinevail ajahetkedel
(kordusmõõtmised), siis on tegemist omavahel sõltuvate rühmadega ja kasutatakse
sõltuvate rühmade t-testi (dependent samples/ paired-samples t-test)
Andmed peavad olema vähemalt intervall skaalal (mõõdetav tunnus peab olema
pidev muutuja)
Sõltuvate rühmade t-testi puhul peab olema normaaljaotus, mis on moodustatud
järgmiselt: ühel korral mõõdetud tulemustest on lahutatud teisel korral mõõdetud
tulemused.
Sõltumatute gruppidega t-testi puhul peaksid olema dispersioonid sarnased (seda
saab kontrollida
Leveni testiga). Kui gruppide suurused on sarnased, siis ei ole selle
eelduse rikkumine väga tõsine. JASPis saab arvutada t-testi statistiku, mis arvestab
selle eelduse rikkumisega (Welchi statistik).
o Kui Levene’i testi Sig on suurem kui 0.05, vaatame Student T-testi; kui
Levene’i test Sig on väiksem kui 0.05, siis Welshi oma.
T-statistik, df (vabadusastmed)
, p, Cohenid (efektisuurus)
o T-statistik – mida suurem, seda parem (seda tõenäolisem, et grupid erinevad)
o p – mida väiksem, seda parem (seda väiksem eksimistõenäosus; p<0,05)
o Coheni d – mida suurem, seda parem (kui suur on leitud erinevus)
o df – valimi suurusest lahutatakse maha võrreldavate gruppide arv
Kategoriaalset tunnust, mille alusel grupid jaotatakse, nimetatakse faktoriks (pole
seotud faktoranalüüsiga!)
One-Sample T-test – kui on vaja võrrelda tulemusi mingi olemasoleva väärtusega.
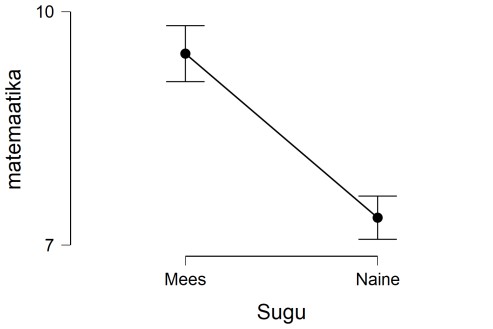
T-testi tulemuste raporteerimine: Uurides meeste ja naiste matemaatikatestide tulemusi
leiti, et meeste keskmine tulemus (M = 9,46, SD = 4,5) on statistiliselt oluliselt kõrgem kui
naistel (M = 7,35, SD = 3,86), t(1198,43) = 9,11, p<0.001, d=0,5.
Paired-Samples T-Test
Ei ole vaja uurida valimite hajuvuse sarnasust (Levene’i test), kuna valim on sama.
Normaaljaotuslikkuse uurimiseks on hea Shapiro-Wilki test, kuna on vaja esimesest
mõõtmisest lahutada teise mõõtmise tulemused ning alles siis nende
normaaljaotuslikkust hinnata, Shapiro-Wilkiga on see juba enne tehtud.
Kui S-W ei kinnita normaaljaotuslikkust, saab seda kontrollida ka vastata uue tulba
loomise kaudu (mõõtmistulemuste lahutustehe).
Mitteparameetrilised testid
Järjestustunnuste (nt Likerti skaala tulemused), normaaljaotusest erineva jaotuse ja
väga väikeste valimite puhul (<30) tuleks eelistada mitte-parameetrilisi analooge.
Test
Statistic
df
p
Effect
Size
matemaatik
a
Student
9.253 1348.000 < .001 0.506
Welch
9.110 1198.429 < .001 0.502
Mann-
Whitney
287893.50
0
< .001 0.276
Group Descriptives
Group N Mean SD
SE
matemaatika Mees 608 9.461 4.516
0.183
Naine 742 7.352 3.856
0.142
Sõltumatu t-testi asemel nt Mann-Whitney test
Sõltumatu ANOVA asemel nt Kruskal-Wallis test
Sõltuvate rühmade t-testi asemel nt Wilcoxoni test
Sõltuva ANOVA asemel nt Friedmani test
Võrreldakse järjestusi, tavaliselt peamine mõõtmisalus keskmise asemel mediaan
Dispersioonanalüüs ehk ANOVA
Rohkem kui kahe võrreldava grupi vahel tehakse mõõtmised ANOVAga (ANalysis Of
VAriance)
Sõltumatute gruppidega
( between subjects
)
ANOVA
Ühefaktoriline dispersioonanalüüs (One-Way ANOVA)
On 1
sõltumatu
muutuja, millel on mitu taset
(nt akadeemilise testi tulemused
keskharidusega, bakalaureuse kraadi ja magistri kraadiga inimeste vahel).
Leiab, kas üldse leidub rühmade vahel statistiliselt olulisi erinevusi ning kui, siis
milliste.
Nullhüpotees H0: μ1= μ 2=….= μn , ehk alamkogumite keskväärtused ei erine
Sisukas hüpotees H1: leidub vähemalt üks alamkogumite paar, mille korral μi≠ μ j
Sõltuv tunnus peab olema vähemalt intervallskaalal, grupeeriv tunnus kategooriline
(mitte pidev).
Tunnuse hajuvused võrreldavates gruppides võiks olla sarnased (Levene’i test)
Tunnuse jaotus (gruppides eraldi võetuna) peaks olema ligilähedane
normaaljaotusele.
Mitmefaktoriline dispersioonianalüüs (Two-Way ANOVA)
Kasutatakse, kui meil on üks arvuline sõltuv muutuja, aga mitu kategoorilist
sõltumatut muutujat (tavaliselt 2 või 3), millel on omakorda mitu taset (nt sugu ja
haridustase).
Sõltuvate gruppide (
within-subject
) ehk korduvmõõtmiste (
repeated measures
) ANOVA
Kasutatakse siis, kui sõltumatud muutujad on mõõdetud samal valimil. Ka siin võib
faktoreid olla üks või mitu.
Näiteks uuritakse, kas inimeste sooritus tähelepanuülesandes (sõltuv muutuja) on
erinev sõltuvalt sellest, kas talle mängitakse kõrvaklappidest klaverimuusikat, rokk-
muusikat või valget müra (I faktor, 3 taset) - iga inimene teeb ülesanded läbi kolm
korda erineva taustamuusikaga.
Segatüüpi dispersioonanalüüs (
mixed
- model
) ANOVA
Korduvmõõtmiste ANOVA, millel on lisaks sõltuvate gruppide faktorile (within-
subjects) ka mõni sõltumatute gruppide faktor (between-subjects)
Näiteks uuritakse, kas lisaks taustamuusikale (I faktor, 3 taset, sõltuvad grupid) võiks
sooritust tähelepanuülesandes mõjutada ka katseisiku sugu (II faktor, 2 taset,
sõltumatud grupid).
ANOVA tulemuste tõlgendamine
Esmalt vaja üldse uurida, kas grupid on normaaljaotuslikud (asümmeetria- ja
järsakuskordaja [-2;2]/ Shapiro-Wilk p>0,05)
p-väärtus – kui p<0,05, siis seletavad grupid ära mingi olulise osa andmete
varieeruvusest, kuid ei täpsusta, millised grupid. On vaja teha post-hoc analüüs!
η² (eeta ruut) – näitab ANOVA puhul efektisuurust; varieerub 0-1, näitab, mitu
protsenti varieeruvusest meie faktor selgitab.
Vaja uurida ka
homogeensust (JASP Assumption checks);
Levene test p>0,05, kui
hajuvused on homogeensed. (Kui hajuvused ei ole homogeensed, kasutada Welchi
testi)
Post-hoc analüüs – kas p-väärtus <0,05? Kui jah, siis on erinevused tulemuste
vahel statistiliselt olulised.
Tulemuste raporteerimine:
ANOVA - mood.gain
Cases Sum of Squares df
Mean Square
F
p
η²
drug
3.453
2
1.727
18.611
< .001 0.713
Residuals
1.392
15
0.093
Post Hoc Comparisons - drug
Mean Difference
SE
t
p tukey
p holm
anxifree joyzepam
-0.767
0.176
-
4.360
0.002
0.001
placebo
0.267
0.176
1.516
0.312
0.150
joyzepam placebo
1.033
0.176
5.876
< .001
< .001
Ühesuunaline dispersioonanalüüs (One-Way ANOVA) näitas, et ärevuse hinnang erines
oluliselt gruppide vahel
(F(2,15) = 18,6; p < .01, η2 =0,71). Post-hoc keskmiste võrdlused
näitasid, et joyzepami manustanud uuritavate keskmine raporteeritud meeleolu oli kõrgeim
(M = 1,48; SD = 0,21), erinedes statistiliselt nii platseebost
(p < 0,01; M = 0,45; SD = 0,28)
kui anxifreest
(p < 0,001; M = 0,71; SD = 0,39). Anxifree ja platseebo vaheline võrdlus ei
osutunud statistiliselt oluliseks
(p = 0,150).II sõltumatu muutuja lisamine:
NÄIDE: Eksperimentaatorid jagasid katsealused gruppidesse selliselt, et igasse
ravimi gruppi (platseebo, anxifree ja joyzepam) sattus sama palju inimesi, kes käisid
teraapias ja kui neid, kes ei käinud. Sellise katse disainist kõnelemisel võidakse
öelda, et tegu oli
3 (platseebo, anxifree ja joyzepam)
x 2 (teraapia, mitte teraapia)
eksperimendiga, milles sõltuvaks muutujaks oli uuringus osalejate meeleolu.
Seda tüüpi katseplaani puhul räägitakse ka
peaefektidest ja
interaktsioonist (koosmõjust). Eelnevalt toodud näite puhul tähendaks peaefekt näiteks, et uuringus
osalejate raporteeritud meeleolu sõltus oluliselt ravimi tüübist (sõltumata sellest, kas
teraapias osaleti või mitte). Sellisel juhul oleks tegemist
ravimitüübi peaefektiga.
Võib olla aga ka nii, et uuringus osalejate meeleolu hinnangud sõltusid teraapias
käimisest (sõltumata sellest, kas ravimit võeti või mitte), so
teraapia peaefekt. Võib
olla ka nii, et kummalgi faktoril oli oma sõltumatu panus meeleolu hinnangule. Sellisel
juhul räägiksime
kahest peaefektist (ravimi ja teraapia omast). Neljas võimalus on,
et ühe faktori mõju sõltub teisest faktorist (
interaktsioon)
ANOVA - mood.gain
Cases
Sum of Squares df Mean Square F
p
η²
drug
3.453 2
1.727
31.71
4
< .001 0.713
therapy
0.467 1
0.467 8.582 0.013 0.096
drug ✻ therapy
0.271 2
0.136 2.490 0.125 0.056
1. Ravimi mõju on statistiliselt oluline (p< .001) ning on vastutav 71,3% muutuste eest
patsientide meeleolus.
2. Teraapia mõju on statistiliselt oluline (p=0,013), kuid see on vastutav vaid 9,6%
muutuste eest.
3. Ravimite ja teraapia vahel puudub statistiliselt oluline seos (p=0,125).
Mitteparameetrilise analoogina Kruskal-Wallis test; taas oluline ennekõike p-väärtus
(<0,05 – erinevus on oluline)
Mitteparameetrilise post-hoc analüüsi puhul Dunni meetod.
Korduvmõõtmiste ANOVA tulemuste tõlgendamine
Esmalt tähelepanu p-väärtusele, et määrata, kas tulemus on statistiliselt oluline.
Vaadata faktortasemete vahede hajuvuse sarnasust ehk sfäärilisust (assumptions
check JASPis); Kui Mauchly testi p-väärtus on <0.05, siis on eeldus rikutud ja seega
peaksime kasutama F-statistiku raporteerimisel kohandatud vabadusastmete väärtusi
ja p-väärtust. Kui
Greenhouse-Geisseri väärtus on väiksem kui 0.75, siis
kasutatakse kokkuleppeliselt Greenhouse-Geisseri korrektsiooni. Vastasel korral
Huynh-Feldti nimelist korrektsiooni.
Saadud tulemuste raporteerimisel saab otsustada, kas esitada korrigeeritud
vabadusastmed: F(dfkorrigeeritud; dfresid.korrigeeritud) = X; p < X, η2 = X või raporteerida
korrigeerimata vabadusastmed koos Greenhouse-Geisseri väärtusega: F(dfalgne, dfresid.
algne
) = X; p < X, η2 = X, GG=X (vabadusastmed korrigeerimata). Korrigeeritud
vabadusastmed ise ütlevad vähe, kuid esitatuna koos GG väärtusega, on võimalik
lihtsalt GG-a läbi korrutada.
Korrelatsioon
Uurib, kas eksisteerib seos kahe pideva muutuja vahel (muutuja intervall- või
suhteskaalal)
Näitab seose suunda (pos – muutujad kasvavad koos, neg – ühe kasvades teine
kahaneb) ja tugevust.
Korrelatsioonikordaja on sisuliselt ka efekti suuruse ning mudeli seletusvõime näitaja
Pearsoni korrelatsioon r
o Varieerub [-1;1], kus 1/-1 on täiuslik pos/neg seos ning 0 on seose puudumine
o Skaala on ordinaarne, mitte lineaarne (ehk seos 0,2 ei ole 2x suurem kui seos
0,1)
o Et saada aru, kui palju ühe muutuja varieeruvus seletab teise muutuja
varieeruvust, on vaja arvutada
determinatsioonikordaja ehk r-ruut
o Kui r=0,1, siis r
2 =0,01 ehk 1% ühe muutuja varieeruvusest on selgitatav teise
muutuja avrieeruvusega. r=0,5 puhul on r2=0,25 ehk juba 25% varieeruvusest!
Alternatiivsed korrelatsioonid:
o Astakkorrelatsioon Spearmani roo (Spearman rank correlation): kui muutujad
on ordinaalsed. Kasutatakse mitteparameetrilistel testidel. (Paneb paika
väärtuste järjekorra ja siis arvutab Pearsoni korrelatsioon)
o Kui üks muutuja on binaarne ja teine on pidev: punkt-biseriaalne (point-
biserial).
Korrelatsiooni leidmine:
Esmalt uurida, kas andmed on pideva jaotusega ja normaaljaotuslikud (et otsustada,
kas vaadata Pearsoni r-i või Spearmani roo-d)
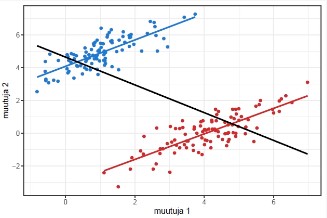
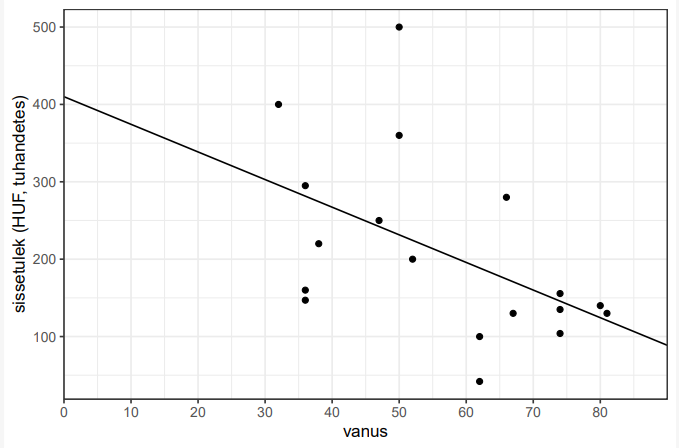
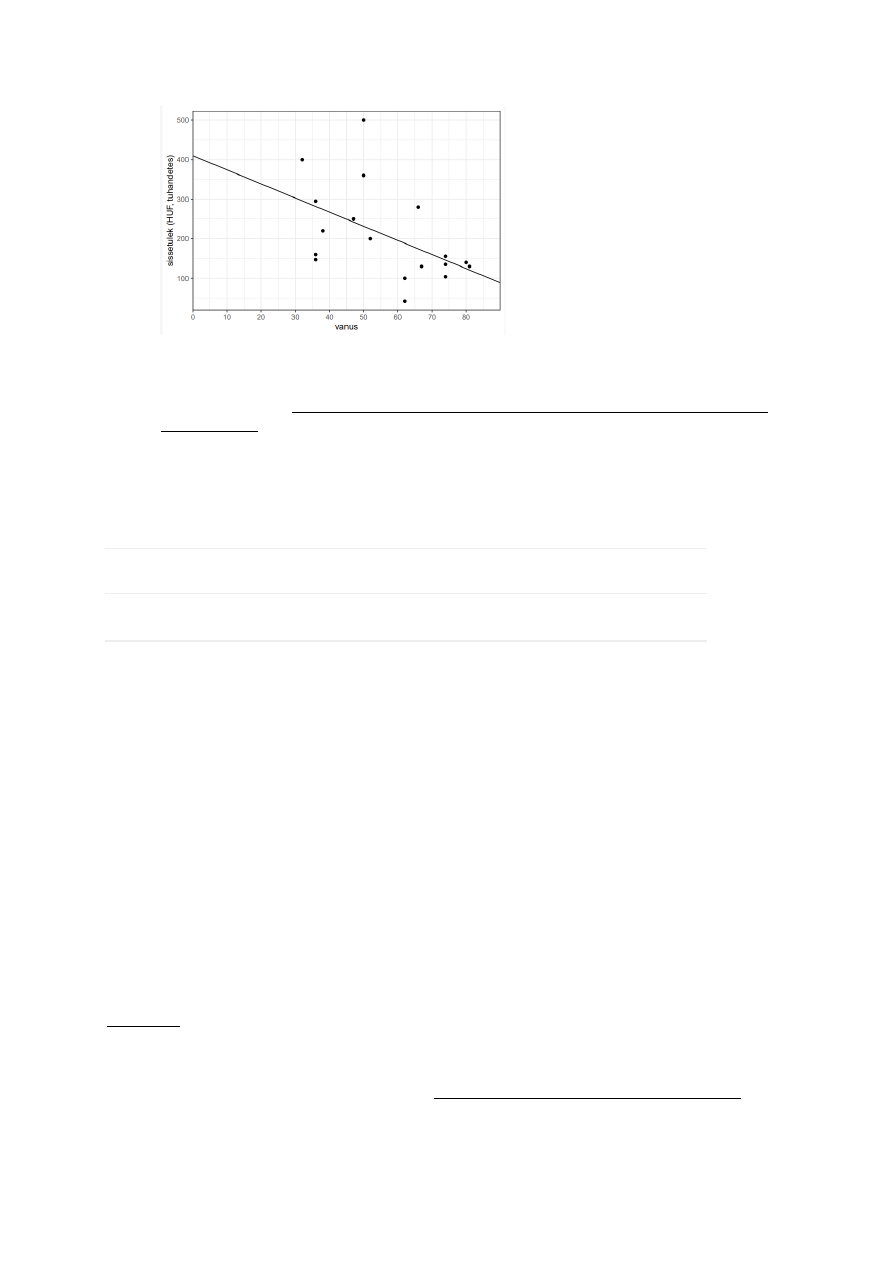
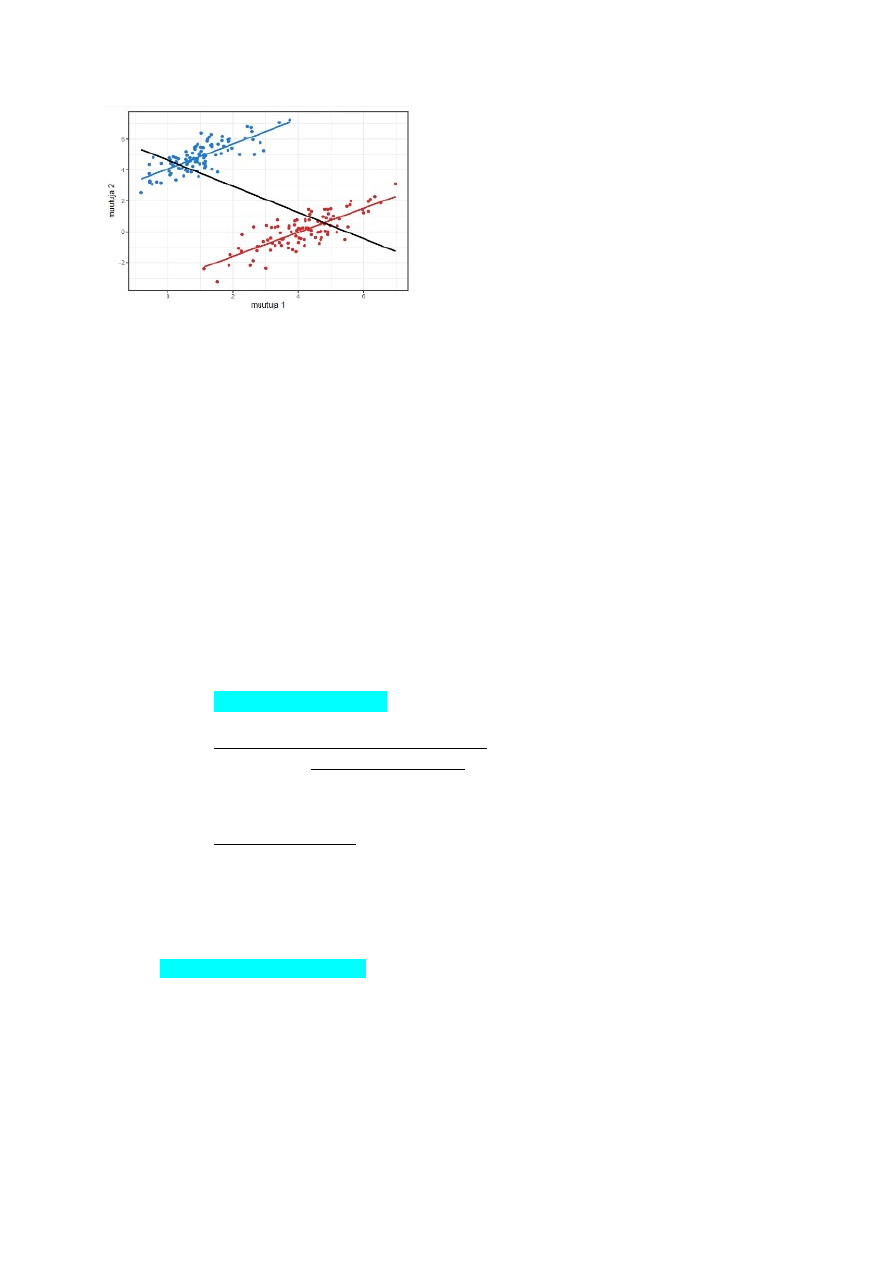
Uurida, kas andmetes on mingeid suuri erandeid (hea vaadata jooniselt; scatter
plots); vahel on õigustatud andmete välja viskamine (nt on vanuseks pandud 500 –
tegemist on selgelt trükiveaga)
Vaadates täpsemalt korrelatsiooni, oleks oluline vaadata ka olulisust (report
significance)
Tulemuste raporteerimine: Korrelatsioonanalüüs näitas, et PISA tulemuste ja
demokraatiaindeksi vahel on tugev positiivne korrelatsioon (r = .79, p < .001).
Regressioon
Lihtsustatult: joonevõrrandi leidmine
y=ax + b
o y – sõltuva muutuja väärtus
o x – sõltumatu muutuja väärtus
o a – tõus
o b – vabaliige
Üritab leida, milline oleks nö kõige parem joon läbi tulemuste pilve, mis ennustaks
kõige rohkem tulemusi ja teeks kõige vähem vigu.
Nimetatakse ka Ordinary Least Squares OLS, kuna leitakse selle järgi, millisel juhul
on ruutvigade summa kõige väiksem.
Lineaarne- ehk paarisregressioon
Eeldused:
Sõltuva muutuja andmed on intervall- või suhteskaalal (st on pidevtunnus);
Vaatluste sõltumatus;
Muutujatevaheline suhe on lineaarne – kontrollime hajuvusdiagrammiga;
Puuduvad märkimisväärsed erindid (outliers) – kontrollime hajuvusdiagrammiga;
Koostamine JASPis:
Valige Regression - Linear Regression.
Tõstke sõltuv muutuja kasti nimega Dependent Variable ja sõltumatu muutuja ehk
prediktor kasti nimega Covariate.
Tulemuste tõlgendamine:
o Regressioonivõrrand: sissetulek = −3.57 × vanus + 409,98
a näitab, kui palju muutub y ühe x-ühiku muutumise korral (iga aastaga
sissetulek väheneb 3,57 võrra)
Oluline on R2 ehk kui suure osa kogu ennustatava muutuja variatiivsusest kirjeldab
ära prediktor.
ANOVA tabelis ennekõike oluline p-väärtus <0,05, mis näitab, kas mudel on
statistiliselt oluline.
Koefitsentide tabeli põhjal saab ehitada regressioonivõrrandi
(Uuring nr 2:)
Coefficients
Mode
l
Unstandardized Standard Error Standardized
t
p
H
₁
(Intercept)
331.581
1.883
176.120 < .001
AGE_R
-1.021
0.044
-0.345 -23.115 < .001
Vanuse regressioonikordaja ehk tõus on -1,02 ehk kui vanus suureneb ühe ühiku
võrra, väheneb probleemilahendusoskus 1,02 punkti võrra.
Standardiseeritud ühikutes on tõus -0,345 ehk kui vanus suureneb ühe ühiku võrra,
väheneb probleemilahendusoskus 0,345 standardhälbe võrra.
p< .001 ehk prediktor on statistiliselt oluline.
Vabaliige on 331,58
Saab kirjutada standardiseerimata regressioonivõrrandi: y(probleemilahendusoskus)
=-1.02x(vanus)
+331,58
Standardiseeritud võrrandis taandatakse vabaliige välja ning tõus märgitakse
standardiseeritud kujul.
Mitmene regressioon
Paarisregressiooni puhul üks sõltumatu muutuja ehk prediktor,
mitmese
regressiooni puhul mitu prediktorit.
Kasutusel endiselt determinatsiooni kordaja, kuid tähistatakse D, mis koosneb
prediktorite r2-dest.
Tulemused esitatakse standardiseeritud kujul, kuna iga prediktori kohta on eraldi
vabaliige ning nende esitamine ei ole mõistlik.
Eeldused:
Seoste lineaarsus (saab joonena väljendada)
Vaatluste sõltumatus
Sõltumatud muutujad ehk prediktorid ei tohi omavahel olla väga tugevalt seotud (üle
0,8), vastasel juhul nimetatakse seda
multikollineaarsuseks.
Pidevad või binaarsed muutujad (kodeeritud 1 ja 0)
Ei ole ekstreemseid juhtumeid
Kõik relevantsed muutujad on mudelis
Regressioonimudeli jäägid peavad olema normaaljaotuslikud.
o Kui ei ole normaaljaotuslik, siis tõenäoliselt seletavad sõltumatud muutujad
paremini vaid ühte osa sellest valimist
Läbi viimine (JASP)
Tuleks kontrollida prediktorite omavahelisi seoseid (korrelatsiooni tabelid)
Regressioni alt Linear Regression.
Dependent Variable on sõltuv muutuja ning Covariates on prediktorid; standartne
meetod on „
Enter
“.
o Enter – kõik muutujad pannakse sisse samal ajal. Muutujate valik peab olema
teoreetiliselt põhjendatud;
o Stepwise – programm valib välja, millised prediktoritest lisatakse mudelisse, ja
teeb seda järjestikuselt (prediktori ennustusvõime järgi);
o Remove – programm võtab prediktoreid välja;
o Backward – programm võtab järjest kõiki prediktoreid hõlmavast mudelist välja
nõrgema ennustusvõimega prediktoreid;
o Forward – programm alustab kõige tugevamale prediktoritele nõrgemate
prediktorite lisamist.
Kollineaarsust saab testida ka Collineary diagnosticsiga – kui selle tolerance näitaja
on <0,1 või VIF>10, on tegemist problemaatilisel tasemel prediktorite-vahelise
seotusega.
Uurida ka mudeli jääke (Residuals) (normaaljaotuslikkus ja ekstreemsed juhtumid)
o Casewide diagnostics, valida Standard residuals valikusse 2SD ühikut, mille
sisse jääb >95% normaaljaotuse andmetest. Kontrollida, kas antud andmete
hulk jääb <5% kogu andmestikust.
o Standardized Residuals Histogram – jälgida, et andmed oleksid koondunud
nulli ümber ja mõlemale poole nulli langeb enam-vähem võrdselt jääke.
Ühtlasi: residual: statistics min, max ja mean selle hindamiseks.
o Q-Q Plot Standardized Residuals - niinimetatud tõenäosuspaber ehk kvantiil-
kvantiil diagramm (ingl. k. Q-Q plot). Sirge joon esindab normaaljaotust ja
punktid jääke. Täiusliku normaaljaotuse korral oleksid kõik punktid joone peal.
Kõrvalekalded joonest on tavalised otstes, kuid keskel ei tohiks neid esineda.
o Cook’s distance > 1 tähistab oluliselt erinevaid andmeid, mis tõmbavad
ülejäänud mudelit enda poole.
Andmete tõlgendamine
Model Summary tabel, kus ennekõike tähtis kohandatud R2, mis näitab, kui suure osa
sõltuvast muutujast kirjeldavad ära prediktorid.
ANOVA tabel - annab tulemused mudeli olulisuse hindamiseks (p-väärtus)
Koefitsientide tabeli - näitab prediktori väärtust ning olulisust mudelis. Kui prediktori p-
väärtus on alla 0.05, siis on selle prediktori mõju statistiliselt oluline.
Tulemuste raporteerimine:
Model Summary - PVNUM1
Mode
l
R
R²
Adjuste
d R²
RMSE
H
₁
0.279
0.07
8
0.077
54.02
3
ANOVA
Model
Sum of Squares
df
Mean Square
F
p
H
₁
Regression
1.095e +6
3
365069.781
125.088 < .001
Residual
1.301e +7
4458
2918.511
Total
1.411e +7 4461
Note. The intercept model is omitted, as no meaningful information can be shown.
Coefficients
Collinearity
Statistics
Mode
l
Unstandardize
d
Standar
d Error
Standardize
d
t
p
Toleranc
e
VIF
H
₁
(Intercept
)
254.753
2.723
93.56
9
< .001
H_Q03b
-6.197
0.817
-0.128 -7.581 < .001
0.725
1.37
9
H_Q03c
14.140
0.861
0.299
16.43
0
< .001
0.626
1.59
7
H_Q03d
2.491
0.881
0.047 2.827 0.005
0.763
1.31
0
Lineaarne regressioon näitas, et kuludega arveldamine (calculating costs or budgets;
β = -
0.128, p < .001), murdude ja protsentide arvutamine (use or calculate fractions or
precentages;
β = 0.299, p < .001), kalkulaatori kasutamine (use a calculator;
β = 0.047, p
< .05) ennustasid numbrilist võimekust statistiliselt olulisel määral. Mudel seletas
7.7%
variatiivsusest numbrilise võimekuse tulemusest,
kohandatud R 2 = 0.077, F(3, 4458) =
125.088, p < .001.
Regressioon binaarse muutujaga
Regressioon, kus sõltumatu muutuja on binaarne väärtus (nt sugu)
Muutujad tähistatakse kui 0 ja 1, 0 on referentsmuutuja
Sisuliselt saaks samad tulemused t-testi puhul
Simpsoni paradoks – esineb, kui juhtumid on jagatud mingi tunnuse poolest gruppideks.
Logistiline regressioon
Sõltuv muutuja on dihhotoomne väärtus (nt jah/ei, on/ei ole, 0/1); see eeldab ka
vastavat muutuja kodeerimist (st kujule 0 ja 1), sest arvutatakse sündmuse
asetleidmise tõenäosust
On üks või rohkem sõltumatut muutujat.
Omavahel sõltumatud ja mitte kollineaarsed vaatlused.
Šansid (odds) – tõenäosus, et midagi juhtub, jagatud tõenäosusega, et see sama asi
ei juhtu (eeldades, et need kaks on ainsad võimalikud variandid).
o Šansid=P(y=1) / 1−P(y=1)
o Kui
šansid on 1, peavad murrujoone pooled olema võrdsed ehk tõenäosus
(probability)
P=50%
o Järelikult: kui šansid<1, on mitte-juhtumise tõenäosus suurem kui juhtumise
Pr; kui šansid>1, on juhtumiste Pr suurem kui mitte-juhtumise Pr.
o Šansid [0; ∞] (varieeruvad 0st lõpmatuseni)
o Riskitõenäosus: šanss 1 on keskmine juhuslik, šanss üle 1 räägib grupi
kuuluvuse kasuks, alla 1 selle kahjuks.
Logaritm – ühe arvu väljendamine teise arvu astmena
o logb(x) = y ehk
b
y = x
o Nt arvust 1 logaritm, mille baas on 10
: log10(1) = mis astmele tuleks 10 tõsta,
et saada 1? (Iga arv astmel 0 on 1)
o Logaritmida saab ainult positiivseid arve (logaritmi baas suurem 0st)
o Naturaallogaritmi
ln
baas on e (ehk ümardatult umbes 2,71)
o Šansside logaritm ehk logit on
ln(P(y=1) / 1−P(y=1))
Logistiline regressioon on nagu tavaline regression, kus me ennustame
šanside logaritmi läbi pidevate või binaarsete sõltumatute muutujate.
ln(P(y=1) / 1−P(y=1))=ax+b
šansid =
p / 1−p ja
p = šansid / 1+šansid
Näide:
o logit(hääletamine) = 0.283 + 0.019 × vanus
o Kui vanus on 50, siis logit(hääletamine)=1,223
o logit(h)=ln(h)=loge(h)=1,223; järelikult hääletamise šansid on e1,223=3,4
o Kui šansid hääletada on 3,4, siis järelikult on hääletamise tõenäosus:
p= 3,4/1+3,4=0,77 s.o.
77% tõenäosus, et 50-aastane kodanik
läheb hääletama.
Logistilise regressiooni puhul ei mõtle me sõltuvast muutujast kui binaarsest
tunnusest vaid pigem kui vastavatesse gruppidesse kuulumise šansside logaritmist.
Mudeli sobivuse hindamisel kasutatakse
pseudo R2
Üritame saada mudeli, mis klassifitseerib korrektselt, kas meie juhtumid kuuluvad
gruppi (1) või ei kuulu (0).
Logistilise regressioonianalüüsi läbi viimine (JASP)
Võiks vaadata üle sõltuva muutuja grupisuuruste jaotuvuse, ideaalis on grupid
võrdsed, kui ei ole, tasub seda järelduste tegemisel arvesse võtta.
Regression - Logistic Regression
o Dependent variable – sõltuv binaarne muutuja (nt suitsetaja-mittesuitsetaja)
o Method – „Enter“
o Covariates – pideval skaalal olevad sõltumatud muutujad (nt kaal)
o Factors – nominaalsel skaalal olevad sõltumatud muutujad (nt sugu)
Model summary tabelist oluline pöörata tähelepanu p väärtusele, et teada, kas mudel
on statistiliselt oluline. X2 ehk hiiruut test võrdleb tulemust nullmudeliga.
Samuti võib vaadata pseudo r2-te (sageli raporteeritakse Cox&Snell ja Nagelkerke
tulemuste vahemik)
Tuleks valida ka odds ratio, mis näitab riskitõenäosust. Kui see suhe on üle 1, siis see
ütleb, et
kui prediktori väärtus suureneb ühe ühiku võrra, kasvab šanss nii palju,
et aset leiab ennustatav sündmus. Kui aga väärtus on alla 1, siis see näitab, et
sündmuse asetleidmise šanss väheneb (kirjeldab nt kaalu muutumise ühikut)
Samuti oluline Coefficients tabelist p-väärtused, mis kirjeldavad individuaalselt iga
teguri statistilist olulisust.
Kui Wald statistic on nullist erinev, ja seda statistiliselt oluliselt (p), siis me võime
öelda, et prediktori panus mudeli ennustusvõimesse on oluline.
Tabeli all ütleb JASP, mis on valitud kummaks kategooriaks (öeldud 1, 0 on
baaskategooria)
Alamenüüst Statistics Confusion matrix ja Proportions.
o Vaadates maatriksi peadiagonaali (ülevalt vasakult alla paremale), näeb
mudeli ennustusvõimet ning neid liites saab teada, mitu vaatlust ennustab
mudel õigesti.
Sensitivity/Recall ja Specificity.
o Sensitiivsus näitab
korrektselt klassifitseeritud positiivsete tulemuste
(true positives) osakaalu. Spetsiifilisus näitab korrektselt klassifitseeritud
negatiivsete tulemuste (true negatives) osakaalu.
o Hea mudel suudab tuvastada nii positiivseid kui negatiivseid tulemusi.
Tulemuste raporteerimine
Model Summary - smoke
Model
Deviance
AIC BIC df Χ²
p
McFadd
en R²
Nagelkerke
R²
Tjur R²
Cox
&
Sne
ll
R²
H
₀
188.769
190.7
69
194.2
54
24
0
H
₁
176.638
184.6
38
198.5
77
23
7
12.1
31
0.0
07
0.06
4
0.090
0.0
63
0.0
49
Performance metrics
Value
Sensitivity
0.995
Specificity
0.000
Coefficients
Wald Test
Estimate
Standard
Error
Odds
Ratio
z
Wald
Statis
tic
df
p
weight
0.0
37
0.018
1.03
8
2.035
4.14
0
1
0.0
42
healthra
te
0.3
60
0.114
1.43
3
3.158
9.97
5
1
0.0
02
Note. smoke level 'no' coded as class 1.
Logistiline regressioon tehti, et hinnata, kas sugu, tervisele antud hinnang ja kaal ennustavad
seda, kas inimene suitsetab või ei suitseta. Logistilise regressiooni mudel oli statistiliselt
oluline,
χ2 (37) = 21.257, p < .001, R2 = 4.9-9.1% (Cox & Snelli ja Nagelkerke), sensitivity
= 99.5%, specificity = 0%. Mitte-suitsetamist ennustas kaalu suurenemine
(Exp(B) = 1.038,
p < .05). Samuti ennustas suitsetamist tervisele antud hinnang
(Exp(B) = 1.440, p < .05) –
kui tervisele antud hinnang suurenes, siis vastaja suurema tõenäosusega ei suitsetanud.
Faktoranalüüs
Analüüsimeetod tunnuste omavaheliste seoste uurimiseks
Faktor ehk mingi latentne konstrukt, mida ei saa otseselt mõõta (nt intelligentsus,
motivatsioon)
Faktorite arvutamine kaudsete mõõtmiste kaudu (nt küsimustikud) – põhineb
korrelatsioonimaatriksil ehk tugineb muutujate omavahelistele seostele.
Tüübid:
o
Uuriv faktoranalüüs (exploratory FA) – eesmärk otsida andmetest ühiseid
latentseid faktoreid; kõige levinum ja kõige enam kasutatud ka seminaritöödes
o
Kinnitav faktoranalüüs (confirmatory FA) – tahame teada, kas hüpoteetiline
mudel on parem kui mõni alternatiivne mudel
o
Peakomponentide analüüs (principal components analysis) – eesmärk on
välja selgitada väiksem hulk komponente, mis vastutavad esialgsete
muutujate varieeruvuse eest. Nimetatakse ka andmete taandamiseks.
Faktoranalüüs proovib seletada ühist osa varieeruvusest ning peakomponentide
analüüs proovib seletada kogu variatiivsust.
Nii uuriv faktoranalüüs kui ka kinnitav faktoranalüüs põhinevad mõlemad nn
ühisfaktori mudelil (common factor model).
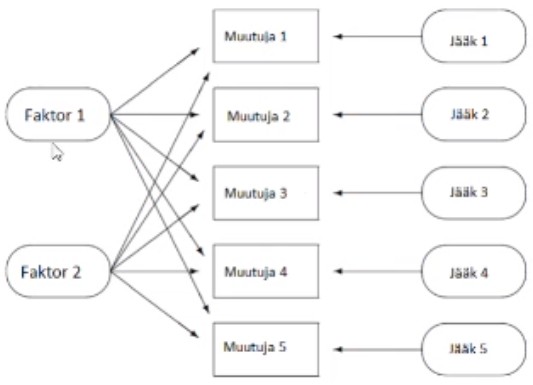
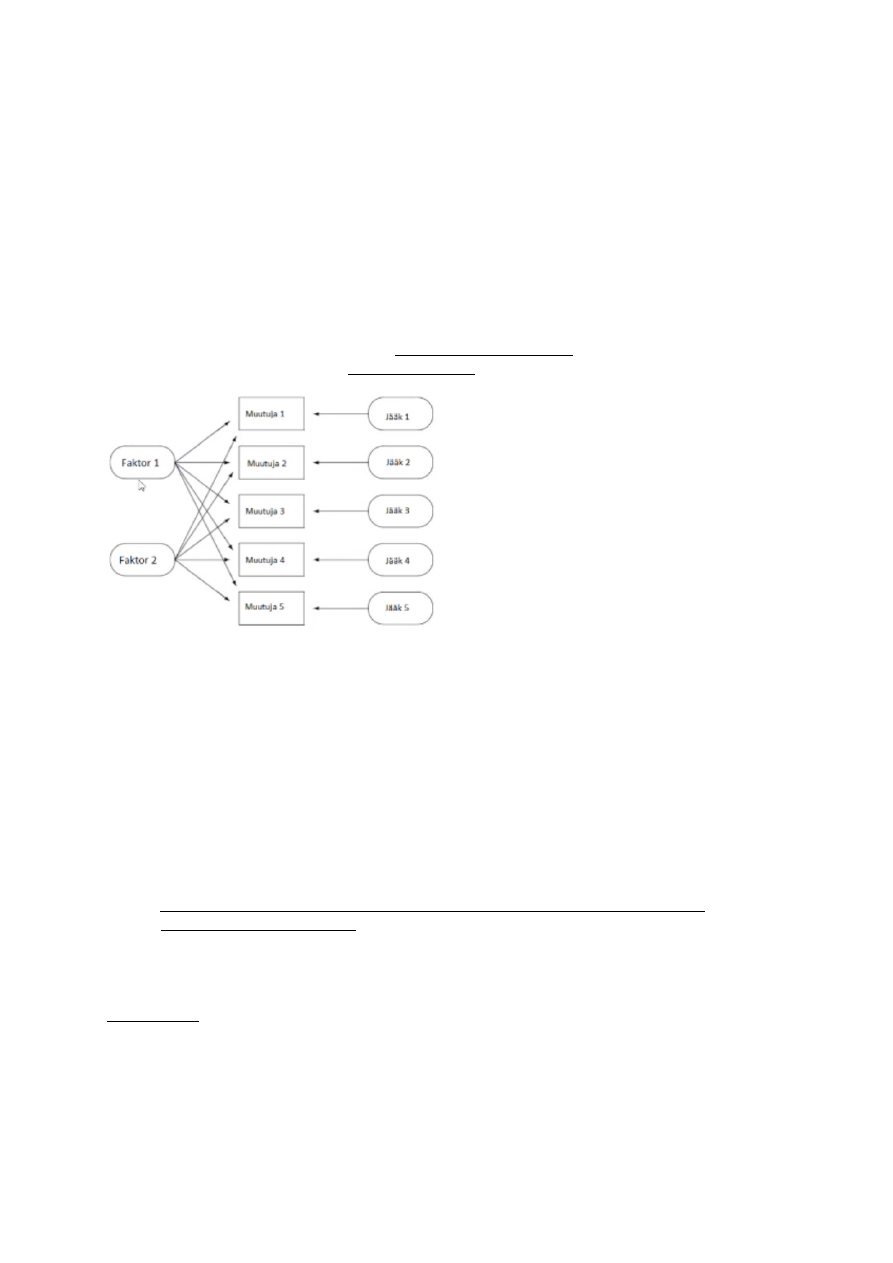
Joonisel 1 On kujutatud ühisfaktori mudel: kõik mõõdetud muutujad (Muutuja 1-
Muutuja 5) on mõjutatud osaliselt ühiste faktorite (Faktor 1 ja Faktor 2) ja osaliselt
unikaalsete komponentide (Jääk 1-Jääk 5 poolt).
Uuriv faktoranalüüs püüab kindlaks teha mõõdetud tunnuste “taga” oleva
faktorstruktuuri. Kinnitav faktoranalüüs võimaldab teha kindlaks, kas hüpoteetiline
mudel kinnitub andmetele
o
Peakomponentide analüüsis toimub vastupidine protsess: eeldatakse, et
muutujatest tekib uus komponent (joonisel nooled vastupidised).
o EFA käigus eeldatakse, et mõõdetud muutujate varieeruvuse eest vastutavad
tekkivad ühisfaktorid ja unikaalsed faktorid. PCA käigus tekitatakse uued
muutujad lihtsalt kui lineaarkombinatsioonid mõõdetud muutujatest
Faktoranalüüs eeldab, et latentne tunnus on vaadeldud tunnuste vaheliste
korrelatsioonide põhjuseks
FA ei tõesta siiski põhjuslike seoseid.
Kui nt joonisel 1 oleks iga faktor seotud vaid oma enda muutujatega, nimetatakse
seda
lihtsaks faktorstruktuuriks.
FA eeldused:
Arvtunnused (võivad olla ka järjestusskaalal); saab arvutada korrelatsioone (r / rho)
Tunnuste vahel peaks olema märkimisväärseid lineaarseid seoseid (enne
korrelatsioonianalüüsiga kontrollida)
Andmeid valimis vähemalt 10x rohkem mõõdetud tunnuseid (valim võiks olla
hinnanguliselt vähemalt 200)
Olulised protsessid:
Faktorite eraldamise meetod (
kõige levinum on maximum likelyhood)
Faktorite pööramine – täisnurkne (orthogonal) või kaldnurkne (oblique); parandab
üldist faktorite seletusvõimet, kui on rohkem kui 1 faktor.
o Täisnurkne pööramine – lineaarsed kombinatsioonid on alati 90° nurga all
ning see eeldab, et faktorid ei ole omavahel korreleeritud
o Kaldnurkne pööramine – ei kehti eelnevad eeldused; psühholoogias
peamiselt kasutatav meetod!
Faktorite arvu eraldamine
o Kaiseri kriteerium – omaväärtused (Eigenvalues y-teljel; näitavad faktori
seletusvõimet) suuremad kui 1
o Catelli kriteerium – võetakse arvesse faktorid enne jõnksu (enne kui tekib
platoo); kohati subjektiivne.
o Paralleelanalüüs – programm simuleerib paralleelandmestiku, millega saadud
tulemusi võrrelda.
Mõitsed:
Faktorlaadung (factor loadings)– mõõdetud tunnuse ja faktori vahelised
korrelatsioonid; standardiseeritud kujul 0-1; tahetakse näha, et kõik tunnused nt
laaduvad tugevalt ühe, nõrgalt teiste tunnustega. (Kui nt mõni tunnus laadub kõigiga
0,3, tasub kaaluda selle tunnuse välja jätmist)
Omaväärtus (Eigenvalue)
– kui hästi faktor mudelisse sobib; kirjeldusaste, mida
suurem, seda parem (tasuks arvestada vaid neid, mis on suuremad kui 1 – Kaiseri
kriteerium!))
Kommunaliteet (communality) – kui suure osa tunnuse variatiivsusest seletab ära
faktormudel; mida suurem kommunaliteet, seda parem (kui vaja mingeid tunnuseid
välja jätta, tasuks vaadata suure faktorlaadungi ja väikese kommunaliteediga
tunnuseid).
Omapäraelemendid ehk jäägid (uniqueness) – 1-kommunaliteet; variatiivsus, mis
jääb faktorite poolt seletamata.
Läbiviimine JASPis
Exploratory FA – kõik huvipakkuvad andmed variables aknasse
JASP annab automaatselt Oblique pööramise meetodi (selle alt kõige levinum valik
oblimin – analüüsi raporteerides tuleb välja tuua). Kui on ainult 1 faktor, pole vaja
pöörata.
Estimation methodi alt kõige soovitatavam maximum likelyhood
Hea valida ka joonis (kui rohkem kui 1 faktor, vaja faktorkorrelatsiooni tabelit)
Valida faktorlaadungi meetod ja otsustada, mitu faktorit arvesse võtta võimalikest
(nõrkasid variante välja jättes on võimalik mudelit parandada)
Highlight valiku alt saab määrata faktorlaadungi piiri, alla mille ei näidata.
(Lisaks saab tellida eelduseid kontrollivad analüüsid KMO test ja Bartlett’s test. KMO
test ehk Kaiser-Meyer-Olkini test hindab andmete sobivust faktoranalüüsi
kasutamiseks ning võiks soovituslikult olla suurem kui 0.5. Bartletti test hindab valimi
sfäärilisust ning siin tuleks vaadata testi p-väärtust, mis võiks olla väiksem kui 0.05.
Tegemist soovituslike suurustega.)
(Additional fit indices – RMSEA võiks olla väiksem kui 0,08; TLI võiks olla suurem kui
0,9/0,95)
(Path diagrammi joonisel alati mõõdetud tunnused kastides ja latentsed tunnused
ringikestes)
Peakomponentide analüüs PCA
Peakomponentide analüüsi eesmärk on välja selgitada väiksem hulk komponente,
mis vastutavad esialgsete muutujate varieeruvuse eest. Faktoranalüüs ja
peakomponentide analüüs on matemaatilises mõttes erinevad. Faktoranalüüsi käigus
eeldatakse, et mõõdetud muutujate varieeruvuse eest vastutavad tekkivad
ühisfaktorid ja unikaalsed faktorid. Peakomponentide analüüsi käigus tekitatakse
uued muutujad lihtsalt kui lineaarkombinatsioonid mõõdetud muutujatest
Kinnitav faktoranalüüs (JASPis)
Saab kontrollida tunnuste kuuluvust faktorisse (eelnevate analüüside alusel)
Vaja teha valikud:
o Additonal OutpuI – Additional Fit Measures
Fit indices tabelist vaadata CFI ja TLI, mis võiks mõlemad olla üle
0,9/0,95
Other fit measures RMSEA ja SRMR võiks olla alla 0,06/0,08
o Plots – Model plots – Show parameters
Faktorlaadungid visuaalsel kujul
o Advanced – Standardization – All
Faktorlaadungid iga tunnuse kohta on nähtavad standardiseeritud
kujul, samuti saab näha nende p-väärtust.
Document Outline
- Andmetöötluse alused:
- Võrreldavate rühmade liigitamine (T-testid)
- Dispersioonanalüüs ehk ANOVA
- Korrelatsioon
- Regressioon
- Faktoranalüüs
































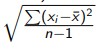

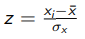




















Kõik kommentaarid