Andemanalüüsi
konspekt:
Mõisteid
küsitakse eksamis: näidete
toomise , selgitamise, võrdlemise ja
analüüsimise tasandil.
Binaarne tunnus-
Järjestustunnus-
- kooli tüüp, 1-väga hea, 2- hea jne(NB!- Õpilaste hinnang koolile ),
- kui suured on klaassid- väga suured, suured jne,
- milline kooli maine- väga hea, hea jne,
- millisesse vahemikku jääb arv (0-200, 201-301 jne)
oluline oleks,
et
Display frequence ees oleks
linnuke , siis saab teha
sagedustabeli Intervalltunnus-
- 1-väga hea, 2-hea jne (NB!_- Kooli hoolekogu hinnang eelmise õppeaasta tulemustele?/ Kooli hoolekogu hinnang eelmise aasta juhtimisele?),
- hulk (n: minu klassi avatakse),
- vanus (keskmine vanus),
- kui kaugel asub kool millestki - km-tes,
Nimitunnus-
- millegi nimi, huviringude nimed, kooli nimi jne,
- kas koolis töötab nõustaja - ei tööta, töötab, mõlemad jne,
Kiire
ülevaade, palju on vastanud väärtusi: Analyse→
Missing Values Analysis paremklõps tunnusele: display Variable
Names /Display variable Labels→tõstan
vajamineva (N. Brutopalk) paremale väljale→ok!
Mean -
keskmine
Sugu-
mõistlik viia kategoriaalsele väljale- alumine siis (vahet väga
palju pole)
Vanus:
mingi osa ei vastanud- asendan missing →x
(katusel kriips)
Asendatakse
puuduvad vastused keskmisega: Transform→
replase missing values- (series mean-võetakse kõik andmed)
Vahemike
loomine: transform→recode
into
different variables/
visual binning?
....:
analyse→descriptive
statistic→frequncies
Märgistan
kõik: ctrl+ A
Valid percent - kes reaalselt ka vastasid
Percent-alati
kasulikum (kui valid percenti) seda kasutada
Haridustasemed
peab kõik välja
tooma Töötab-1,
õpib-2 jne nummerdamine- kõikidel gruppidele omad väärtused!
10
varianti- tahan muuta 5ks: transform- recode into dif. Valiables.
valim →teise
välja→name→
change →old
and new values (old: 1-
copy old values)
Transform-
compute variable
target variable??
Programmi SPSS kasutamine
View
– Value Labels:
näidata koodide asemel nimetusi
Utilites
– Variables:
muutujate/tunnuste sisu ülevaade
Muutuja /tunnuse
määrangute muutmine: topeltklõps selle nimel tabeli ülal. Nii
saab näiteks muutujale uut nime anda või väärtuste nimetusi
muuta.
Output-
aknast saab tabeleid ja graafikuid Word’i tõsta need
valides ja siis
Copy
ning
Word’is
Paste .
Sagedustabeli
koostamine- vanuse puhul, kui väärtusi kiiga palju, siis ei
kasutata sagedustabelit
Seal
esitatakse tunnuse väärtused (valid), nende
esinemissagedus (frequence) ning
protsendid (percent).
Sagedustabeli
järjestamiseks sagduste järgi: uus tabel: analyze/ferquences .
tunnus
perekonnaseis varialbel väljale ning klõpsame nupule
format .
Descending
counts linnuke.
Kui
tunnusel on aga palju erinevaid väärtuseid, näiteks sissetulekud
on kõikidel vastajatel tõenäoliselt erinevad, siis
sagedustabel andmete kokkuvõtmiseks ei sobi.
Andmestikus
kultuur.sav on
selliseks tunnuseks vanus. Koostades vanuse
väärtustest sagedustabeli, on see liiga mahukas, et seda andmete
esitamiseks kasutada.
Statistics
– Summarize – Frequencies
Variable(s):
millistest muutujatest sagedustabelit soovitakse
Statistics:
võimalus
tellida muutuja(te) kohta statistikuid (kvartiile-min/max,
keskmist, standardhälvet jne) – ainult
rangelt arvandmete korral!
Charts:
võimalus
tellida muutuja kohta graafikuid (histogrammi)
Format:
peamiselt muutujate järjestus (ei taha koos histogrammiga
töötada):
Ascending
values:
muutuja väärtuste kasvavas järjekorras
Descending
values: sama
kahanevas järjekorras
Ascending
counts:
muutujad esinemissageduste suurenevas järjekorras
Descending
counts:
sama kahanevas järjekorras
Tulemuseks
saame Output-
aknasse taolised
tabelid :
Märkused:
Frequency : muutuja väärtuste sagedus
Percent: protsent
Valid Percent: protsent ilma puuduvate väärtusteta
Cumulative Percent: kumulatiivne protsent (liidetuna eelmiste väärtustega)
Graafikuid saab muuta topeltklõpsutades selle peal.
Risttabelite koostamine
Statistics – Summarize – Crosstabs
Row(s): reamuutuja(d)
Column (s): veerumuutuja(d)
Statistics: saab tellida erinevaid statistikuid (näiteks Chi-
Square )
Cells: mida SPSS lahtritesse trükib:
Observed: lahtrisse kuuluvate objektide (küsitletute) arv
Expected : kui palju objekte kuuluks lahtrisse kui rea- ja veerumuutujate vahel puuduks igasugune seos
Percentages:Row: reaprotsendid (mitu % sellesse ritta kuuluvatest
objektidest on
lahtris )
Column: veeruprotsendid (mitu % sellesse
veergu kuuluvatest objektidest on lahtris)
Total : koguprotsendid (mitu % kõigist tabelisse kuuluvatest objektidest on lahtris)
Tulemuseks saame Output-aknasse taolised tabelid:
- Kui risttabel on liiga suur (palju tühje või väikeste väärtustega lahtreid) võib neid kokku tõmmata kas andmeid filtreerides või uusi muutujaid moodustades (vt allpool).
- Hii-ruut statistik ise ei näita seost veeru - ja reamuutuja vahel, selle suurus sõltub tabeli suurusest . Seosele viitab väike ( Pearsoni kordaja (tavaliselt)
Kendall
• Vähemalt järjestustunnused
• Samasuunaliste ja vastassuunaliste paaride analüüs.
Crameri V
• Nimitunnuste seose tugevuse uurimiseks.
• Kordaja ei näita seose suunda, ainult tugevust.
Sagedustabeli koostamine
järjestustunnus
Esmalt üldine ülevaade vastajate vastustest jne
Nimitunnus
Intervalltunnus
Binaarne tunnus
Erinevate kategooriate/tunnuste võrdlemine
Gruppida võrdlemise juhul kui keskväärtuste arvutada ei saa.
Diskrimineeritud :
Tunnuse väärtuste järjestamine
Tekstitunnuse muutmine numbriliseks
Arvutame vastava sissetuleku, liites kokku palga ja lisatasu
Tunnse väärtuste jagamine gruppidesse
Väärtuste selekteerimine
Andmestiku jagamine osadeks
Ankeet , küsimus, mille vastus on nr
Küsimus, mille vastus on komakohaga nr
Ühe vastusevariandiga küsimus
Mitme vastusevariandiga küsimus
Avatud vastusega (teksti) küsimus, mille vastused eeldatavalt erinevad üksteisest väga palju N: email
Põhimõisted:
Andmeteisendused, andmete ümberkodeerimine, harjutused
Tunnusetüübid, andmete esitamine, andmete esitamine tekstina
Andmete esitamine tabelitena, sagedustabel,
Harjutused, andmete jagamine osadeks,
Sagedustabel, risttabel,
Koonstabel, harjutused, üldine ülevaade vastajatest
Andmete graafiline esitamine, histogramm (peab olema numbriline, tunnusel peab olema piisavalt palju erinevaod väärtusi, Ei sobi: bvanus 19, 29 jne)
Histogrammi kujundamine
Histogrammi sisu
Üldised võimalused graafikute redigeerimisel, graafiku suuruse muutmine, diagrammide kopeerimine
Sektordiagramm - tunnus peab olema kvalitatiivne või järjestus või numbriline, millel on vähe erinevaid väärtusi (ei sobi: sissetulek, keskmine hinne, kui on palju erinevaid vastuse varaiante)
tulpdiagramm
Võrdlevad tulpdiagrammid
Andmete esitamine kirjeldavate arvnäitajate abil
korrelatsioonianalüüs
Enam kui kahe runnuse vahelise seose uurimine , reliaablus
Vastavalt sellele, mida me uurida tahame, kogume me andmeid kas inimeste, koolide, valgete hiirte ,
kalendrikuude, kartulipõldude vms kohta. Kõiki selliseid indiviide või üksusi, kelle/mille käest või kohta on
me andmeid kogume, nimetatakse statistilises andmeanalüüsis objektideks. Andmeid koguma asudes oleme
valmis mõelnud mingid neid objekte iseloomustavad omadused, mis meid huvitavad, näiteks: värvus, vanus,
hind, kaal, arvamus millegi suhtes, jne – selliseid omadusi nimetatakse muutujateks. Omadusi, mida saab
mõõta nii (või mis on juba kokku võetud nii), et iga objekti jaoks saadakse ainult üks vastus ehk üks ühik
infot nimetatakse tunnusteks. Objektid ja tunnused peavad olema valitud enne andmete kogumist ning
andmete kogumise käigus püüame saada tulemuse või vastuse iga objekti kohta kõigi meid huvitavate
tunnuste lõikes - statistika terminoloogiast lähtudes on need väärtused. Nii võivad tunnuse „ haridus “
võimalikud väärtused olla näiteks „algharidus“, „ põhiharidus “, „ keskharidus “ ja „ kõrgharidus “, aga tunnuse
„vanus“ väärtused näiteks arvud „12“, „27“, „6“, jne. (Arvuti kasutamine uurimistöös ( http://aku.opetaja.ee/ ))
Andmete analüüsi kontekstis on oluline teha vahet nelja erineva tunnuse tüübi vahel:
! Nimitunnused – tunnused, mille väärtused moodustavad kategooriad, kuid neid kategooriaid ei saa
omavahel järjestada. Nt. rahvus (eestlane, venelane , soomlane , muu); eriala ( psühholoogia , informaatika ,
matemaatika , geoökoloogia, sotsioloogia).
! Binaarsed tunnused – tunnused, millel on vaid kaks väärtust. Nt. sugu (mees, naine); nõustumine (olen
nõus, ei ole nõus).
! Järjestustunnused – tunnused, mille väärtused moodustavad kategooriad ning neid saab omavahel
järjestada. Samas ei ole nende väärtuste vahemikud võrdsed. Nt. hinnang (väga hea, hea, rahuldav)
! Intervalltunnused (sh arvtunnused ) – väärtused on järjestatavad ning nende väärtuste vahemikud on
võrdsed. Nt. sissetulek (123€, 125€, 130€, 1500€jne.);
SPSS programmis saab sisestatud andmeid jagada kolme tüübi/skaala vahel: nimitunnus ( Nominal ),
järjestustunnus (Ordinal) ning intervalltunnus (Interval). Binaarsed tunnused kuuluvad nimitunnuste alla.
Sektordiagramm- sobib niisuguste andmete esitamiseks, mille väärtused moodustavad kokku terviku e 100%
Ebaõnnestunud sektordiagrammid, sektordiagrammi koostamine, järjestustunnus, nimitunnus,
Binaarne tunnus, intervalltunnus, millel ei ole palju erinevaid arvväärtuseid
Sektordiagrammi kujundamine, andmesiltide lisamine
Ühe sektori eemaldamine/välja tõstmine, sektorite kokkuliitmine
Sektorite järjestamine
1. Sissejuhatus
On olemas kolme tüüpi valesid: valed, alatud valed ja statistika.
-Disraeli
Tõepoolest , kasutades statistilisi meetodeid aru saamata nende sisust või siis, halvemal juhul,
arvestades kuulajate /lugejate asjatundmatust, on statistika abil valet vanduda küllalt lihtne. Kuid
kas selles on õige süüdistada statistikat?
Paljud statistika õpikud algavad lubadusega, et lugejad ei pea matemaatikast rohkem teadma,
kui oskama lihtsalt liita, lahutada, korrutada ja jagada ning asendada toodud valemites tähed
õigete numbritega. Sellegipoolest on õpilased, kes pole kõrgema matemaatikaga kokku
puutunud, päris kohkunud nähes, et suurem hulk lehtedest on täidetud valemite, võrrandite ja
arvutustega. Pahatihti osutuvad arvutuslikud üksikasjad niivõrd aega ja tähelepanu nõudvateks,
et õpilased unustavad sootuks üldised ideed, mida need arvutused illustreerima peaks. Lugejatel
on raske näha arvutuslike puude taga statistilist metsa.
Seepärast ei pöörata kogu järgnevas käsitluses tähelepanu mitte valemitele ühe või teise
statistiku arvutamiseks vaid püütakse selgitada statistiliste ideede (kontseptsioonide) olemust
sõnade, näidete ja jooniste abil.
Loengumaterjalide koostamisel on kasutatud D. Rowntree raamatut "Statistics without tears".
Mis on statistika?
2.1 Statistiline mõtteviis.
Statistiline mõtteviis on meile kõigile igapäevasest elust tuttav ja omane.
Võtame ühe lihtsa näite: ma ütlen teile, et ma lähen täna teatrisse kahe kolleegiga, kusjuures
üks neist on 190 cm pikk ja teine 165 cm pikk.
Millise järelduse te võite kummagi kolleegi soo kohta kõige kindlamini teha, kui teil rohkem
mingit informatsiooni ei ole?
Ma arvan, et te võisite päris veendunult väita, et üks mu kolleegidest , 190 cm pikkune , on
mees ja teine, 165 cm pikkune, on naine. Loomulikult võisite te eksida, kuid teil on igapäevasest
elust kogemus, et 190 cm pikkuseid naisi on küllalt vähe. Muidugi ei ole te näinud kõiki mehi
või kõiki naisi ning te olete märganud, et paljud naised on paljudest meestest pikemad ; kuid
ometi võite te nähtud meeste ja naiste põhjal küllalt julgelt teha üldistuse ja väita, et üldiselt on
mehed pikemad kui naised. Niisiis , enama informatsiooni puudumisel, tundub teile väga
tõenäoline, et pikk täiskasvanu on mees ja lühike on naine.
Selliseid lihtsaid näiteid statistilise mõtteviisi kasutamisest võib tuua veel mitmeid. Iga kord,
kui te kasutate fraase nagu: “Ma käin kinos keskmiselt kaks korda kuus” või “Sügisel on oodata
palju vihma” või “Mida varem sa kordama hakkad, seda paremini sul eksamil läheb”, teete te
statistilise avalduse, kuigi te ei ole sooritanud ühtegi arvutust . Esimeses näites on tehtud
kokkuvõte varasematest kogemustest. Teises ja kolmandas näites on aga varasemaid kogemusi
üldistatud ning tehtud ennustus üksiku aasta või siis õpilase kohta.
Tihtipeale on meil aga vaja kirjeldada mingeid nähtusi või nähtuste vahelisi seoseid palju
täpsemini, kui me seda teeme igapäevases vestluses.
Oma tähelepanekute põhjal kujunenud oletuste (statistilises sõnastuses HÜPOTEESIDE)
kinnitamiseks peame me läbi viima uurimuse, mis sisaldab ANDMETE kogumist antud nähtuse
kohta, kogutud andmete töötlemist ning põhjendatud järelduste tegemist.
Statistilise maailmavaate keskseks mõisteks on TÕENÄOSUS, s.t. statistika ei anna meile
kunagi 100% kindlust, eriti kui tegeldakse üksiku inimese või sündmusega, vaid lubab määrata,
kui suur on võimalus selle sündmuse toimumiseks.
Statistiline mõtteviis on mõistmine, et meie vaatlused (mõõtmised) ei saa kunagi olla täiesti
täpsed ning, et meie oletus ( hüpotees ) võib kehtida näiteks 95-l (või 99-l) juhul 100-st, kuid mitte
kunagi 100-l juhul 100-st.
Näiteks laps, kelle pikkuseks me oleme mõõtnud 162 cm, ei ole täpselt nii pikk - tema pikkus
võib olla kuskil 161,75 cm ja 162,25 cm vahel, kuid mitte täpselt 162 cm. Ning kui me kasutame
olemasolevaid vaatlusandmeid järelduste tegemiseks teiste (mitte mõõdetud) objektide kohta, siis
on meil võimalus eksida veel palju suurem. Näiteks juhul, kui me tahame ennustada ühes klassis
käivate laste mõõtmisel saadud keskmise pikkuse põhjal teises klassis käivate laste keskmist
pikkust.
Seepärast ei saa me olla täiesti täpsed, kuid statistika võimaldab meil määrata oma vigade
ulatuse .
Seega me võime peaaegu täpselt väita, et lapse pikkus on vahemikus 162 ± 0,25 cm; ning me
võime arvutada, et 99-l juhul 100-st on laste keskmine pikkus teises klassis näiteks vahemikus
162 ± 3 cm.
Kirjeldav ja järeldav statistika. Üldkogum ja valim.
Enamuses statistika käsitlustes tõmmatakse selge piir kahe statistika valdkonna vahele:
1. KIRJELDAV STATISTIKA, mis pakub meetodeid ( vaatlus )andmetest kokkuvõtete
tegemiseks ja nende kirjeldamiseks ning
2. JÄRELDAV STATISTIKA, mis kasutab kogutud ( vaatlus )andmeid baasina hinnangute
ja prognooside tegemiseks (veel) mitte vaadeldud situatsioonide kohta.
Vaatame veelkord neid lauseid igapäevasest elust, mida ma eelpool mainisin . Milliseid
nendest on “ kirjeldavad ” ja millised “järeldavad”, kui silmas pidada ülal mainitud tähendust?
“Ma käin kinos keskmiselt kaks korda kuus”
“Sügisel on oodata palju vihma”
“Mida varem sa kordama hakkad, seda paremini sul eksamil läheb”
* * *
Esimene lause on kirjeldav, teine ja kolmas aga ei piirdu vaid kogetu kokkuvõtmisega, vaid
nendes tehakse järeldus selle kohta, mis tulevikus tõenäoliselt juhtub.
Selline kahe statistika valdkonna eristamine on tihedalt seotud kahe väga tähtsa mõistega
(statistikas): VALIM ja ÜLDKOGUM.
Üldkogumi (ehk populatsiooni) all mõeldakse kõiki juhtumeid või situatsioone, mille kohta
meie poolt püstitatud järeldused, oletused või prognoosid kehtivad.
Näiteks võivad erinevad teadlased teha järeldusi (kõigi) valgete hiirte õppimisvõime kohta;
ära arvata erinevatel eksamitel läbipääsevate õpilaste (üld)arvu; ennustada viljasaaki (kõigil) uue
väetisega väetatavatel põldudel; uurida (kõigi) Tallinna koolilaste õpimotivatsiooni jne.
Nagu te näete, ei mõelda üldkogumi all mitte ainult inimesi, vaid üldkogumi võib moodustada
mistahes meid huvitavate sarnaste objektide hulk.
On aga selge, et tegelikus elus ei ole võimalik vaadelda (mõõta, loendada, küsitleda jne.) kõiki
meid huvitavaid objekte. Seepärast peab uurija välja valima suhteliselt väikese osa üldkogumist,
et selle põhjal teha järeldus kogu üldkogumi kohta. Sellist uurimiseks valitud väikest objektide
gruppi nimetataksegi VALIMIKS.
Näiteks psühholoog , kes uurib valgete hiirte õppimisvõimet, loodab, et saavutatud tulemused
ning seega ka järeldused kehtivad kõigi valgete hiirte puhul - mitte ainult praegu olemasolevate,
vaid ka veel sündimata hiirte puhul ning ta võib isegi loota, et tema tulemusi võib sedavõrd
üldistada , et need selgitaks inimese õppimist.
Seega paljud teadlased ületavad kättesaadava informatsiooni piiri: nad üldistavad tulemusi
valimilt üldkogumile, nähtult ja kogetult mittenähtule ja mittekogetule.
Tulles tagasi kirjeldava ja järeldava statistika mõistete juurde, võime öelda, et kirjeldav
statistika tegeleb valimi (vaatlemisel saadud andmete) resümeerimise ja kirjeldamisega, järeldava
statistika ülesanne on aga üldistuste tegemine laiema objektide hulga - üldkogumi - kohta.
Kui täpsed on aga sellised üldistused osalt tervikule? See ongi küsimus, millega statistika laias laastus tegeleb: ta määrab meie eksimise tõenäosuse.
Statistilised tunnused. Tunnuste tüübid.
Vastavalt sellele, mida me uurida tahame, koosneb meie valim kas üksikutest inimestest,
valgetest hiirtest, kalendrikuudest, mingitest toodetest, kartulipõldudest või millest tahes. Kõiki
valimisse kuuluvaid indiviide nimetatakse statistikas OBJEKTIDEKS. Kõigil ühte valimisse
kuuluvatel objektidel on mingid iseloomulikud TUNNUSED, mis meid huvitavad, näiteks: värv,
sugu, hind, kaal jne. Iga üksik valimi liige erineb teistest mõne tunnuse VÄÄRTUSE poolest:
mõned objektidest on ühte värvi, mõned teist; mõned on naised, teised mehed; mõned on
kallimad, teised odavamad jne. Statistilised tunnused on vahendiks, mis lubab meil üksikuid
objekte üksteisest eristada.
Oletame näiteks, et te tahate osta kasutatud jalgratast. Millised on need tunnused, mille põhjal
te oma valiku teeksite ehk, milliseid andmeid te tahaksite erinevate rataste kohta teada, et neist
endale sobiv välja valida?
* * *
Toon mõned tunnused, mis oleks minu jaoks olulised. Teie nimekiri võib olla pikem või
lühem, sisaldada osasid toodud tunnustest või kõiki jne:
Jalgratta tüüp (N. naiste-, meeste-, laste-, sportratas jne.)
Valmistaja riik
Värvus
Seisukord (N. hea, rahuldav, halb)
Vanus
Hind
Käikude arv
Iga üksik jalgratas, pakutavate hulgast, erineb teistest mõne tunnuse väärtuse poolest. See,
kuidas me aga erinevaid jalgrattaid nende tunnuste põjal hindame, sõltub tunnuse tüübist.
Tunnusega "jalgratta tüüp" jagame me pakutavad jalgrattad kategooriatesse kasutades lihtsalt
nende nime, N. naisterattad, lasterattad, meesterattad jne. Kõiki selliseid tunnuseid, mis liigitavad
üksikud objektid mingitesse klassidesse (kategooriatesse), kasutades selleks sõnu, nimetataksegi
KATEGORIAALSETEKS e KVALITATIIVSETEKS TUNNUSTEKS.
Millised tunnused ülaltoodutest on sinu arvates veel kategoriaalsed?
* * *
Täpselt! 'Valmistaja riik' ja 'värvus' on kategoriaalsed tunnused. Esimese puhul nendest on
kategooriateks erinevad riigid N. Venemaa, Soome, Saksa jne. ning teise puhul jagatakse rattad
klassidesse nende värvi põhjal. Selliseid tunnuseid nimetatakse tihti ka NOMINAALSETEKS
TUNNUSTEKS (ladina k. nominalis = nimi).
Kuid samuti on tunnus "seisukord" kategoriaalne, sest ta jagab jalgrattad kolme gruppi: heas,
rahuldavas ja halvas korras olevateks. Kas sa märkad erinevust kahe eelneva tunnuse ja selle
tunnuse vahel?
* * *
Tõepoolest, tunnuse "seisukord" abil võime me öelda, et ühed jalgrattad on teistest paremad:
seega, me võime jalgrattad selle tunnuse põhjal järjekorda seada. Kõiki selliseid tunnuseid, mille
puhul me saame öelda, et üks valimi liige on teistest parem või suurem või kiirem - ühesõnaga,
saame objekte järjestada, nimetatakse JÄRJESTUS- ehk ORDINAALSETEKS TUNNUSTEKS.
Pane tähele, et järjestustunnuse väärtusteks võivad olla ka numbrid (näiteks võime me kümme
pakutavat jalgratast panna seisukorra järgi täielikku järjekorda: 1-kõige parem, 2-järgmine,
...,10-kõige halvem ), kuid siin me kasutame numbreid tähenduses: esimene, teine, kolmas jne.
Me ei saa öelda, et esimene jalgratas on täpselt kaks korda parem kui teine või kümnes täpselt
kümme korda halvem kui esimene.
Teise põhilise tunnuste tüübi moodustavad kõik need tunnused, mille väärtusteks on numbrid.
Siin me saame öelda, kui palju erineb iga üksik objekt teisest; me saame seda erinevust täpselt
mõõta (või loendada). Millised eelpool toodud tunnustest sa paigutaksid sellesse tüüpi?
* * *
Jalgrataste "vanus", "hind" ja "käikude arv" on kirjeldatavad konkreetsete numbriliste
suurustega. Me saame öelda täpselt, mitu korda on üks jalgratas teisest kallim või kui palju on
üks ratas teisest vanem ning ka käikude arv erinevatel ratastel on täpselt võrreldav. Kõiki
tunnuseid, mille väärtusi me saame täpselt mõõta või loendada, nimetatakse
KVANTITATIIVSETEKS TUNNUSTEKS.
Kuid samuti, nagu kategoriaalsete tunnuste puhul on ka kvantitatiivseid tunnuseid kahte tüüpi:
DISKREETSED ja PIDEVAD TUNNUSED. Diskreetne on tunnus, mille võimalikud väärtused
on üksteisest selgelt eraldatud. Klassikaline näide sellisest tunnusest on laste arv peres: peres
võib olla 1 laps või 2 last või 3 või 4 või jne.
Pidevate tunnuste puhul on aga vastupidi: võttes millised tahes kaks võimalikku väärtust,
võime me alati leida väärtusi nende vahel, mis on samuti võimalikud. Mäletate näidet laste
pikkuse mõõtmisest? Laps võib olla praegu 149 cm pikk, kuid aasta möödudes on tema pikkus
155 cm. Kuid vahepeal pole tema pikkus olnud mitte ainult 150 cm, 151 cm, jne. vaid ka näiteks
151.5 cm, 153.3754 cm jne. Seega, laps ei kasva 1 sentimeeter või pool sentimeetrit korraga vaid
tema pikkus suureneb pidevalt.
Üldiselt peame me diskreetsete tunnuste väärtuste leidmiseks kasutama loendamist ning
pidevate tunnuste puhul mõõtmist. Millised meie jalgrataste tunnustest on diskreetsed ja millised
pidevad?
* * *
'Käikude arv' on tõesti diskreetne tunnus. Jalgrattal võib olla, kas 1, 3, 4, 5, 8 või 10 käiku ,
kuid vahepealsed väärtused ei ole võimalikud. 'Vanus' on aga pidev tunnus: me võime vanust
mõõta kuitahes täpselt (st. me saame alati leida vanuse, mis on näiteks 3 aasta 9 kuu ja 3 aasta 10
kuu vahel jne.). Tavaliselt tekitab vaidlusi tunnuse 'hind' paigutamine ühte või teise tunnuse
tüüpi. Kui me aga mõtleme eelmiste näidete peale, siis näeme, et 'hind' on diskreetne tunnus, sest
ei saa leida reaalselt võimalikku hinda näiteks 90 ja 95 sendi vahel. (NB! isegi täisarvuline hind
92 senti ei ole võimalik!) Ka eestikeelne väljend : raha lugema, näitab, et tegemist on diskreetse
tunnusega. Me loeme raha, mitte ei mõõda.
Järgnev joonis illustreerib seost erinevate tunnuse tüüpide vahel:
Oluline on teada, et statistikas tuleb erinevatesse tunnuse tüüpidesse kuuluvaid andmeid
käsitleda erinevalt. Kõige suurem vahe, mida tuleb andmete käsitlemisel silmas pidada, on vahe
kategoriaalsete ja kvantitatiivsete tunnuste vahel.
Selle punkti lõpetuseks tahaks veel mainida, et kõiki kvantitatiivseid tunnuseid on võimalik
muuta kategoriaalseteks. Näiteks võime me jagada inimesed pikkuse põhjal klassidesse: väga
pikad, pikad, keskmised, lühikesed ja väga lühikesed. Nii tehes kaotame me aga informatsiooni,
ning algandmete puudumisel me vastupidist teisendust (kategoriaalsest tunnusest
kvantitatiivseks) teha ei saa. Selline kategoriseerimine on aga vajalik, kui me tahame erinevaid
gruppe omavahel võrrelda. Gruppide moodustamist kasutatakse vahel ka selleks, et lihtsustada
andmete käsitlemist.
Andmete kirjeldamine ehk kuidas saada kogutud andmetest
paremat ülevaadet.
3.1 Tabelid ja diagrammid .
Jättes vahele andmete kogumise etapi, oletame nüüd, et teie käsutuses on hulk pabereid täis
vaatlustel saadud tulemusi (ehk andmeid). Esimene asi, mis teil tuleb teha, on need andmed
korrastada nii, et teie ise ning ka teised inimesed saaksid kogutud vaatlustulemustest selge
ülevaate.
Võtame jällegi ühe lihtsa näite: kõrgkool viis läbi uurimuse, kus viiekümne tudengi käest
küsiti muuhulgas ka seda, millist transpordi liiki ta kooli jõudmiseks kasutab.
Kõige klassikalisem viis selliste andmete korrastamiseks on koostada SAGEDUSTABEL:
Kuid tavaliselt huvitavad meid valimi puhul mitte niivõrd ühe või teise kategooria sageduse
absoluutarvud vaid proportsioonid. Seetõttu on mõistlik sagedustabel järjestada kategooriate
suuruse järgi ning välja arvutada ka protsendid:
Kooli jõudmiseks kasutatavad transpordivahendid
Tänapäeval, kus andmete käsitlemisel kasutatakse üha laiemalt arvuteid, hakkavad eelpool
mainitud tabelid aga tasapisi kasutusest kõrvale jääma , sest arvuti võimaldab ühe sammuga lisaks
proportsioonide väljaarvutamisele koostada ka diagrammi , mis neid proportsioone illustreerib.
Koostame TULPDIAGRAMMI, kus iga tulba kõrgus on proportsionaalne vastavasse
kategooriasse kuuluvate õpilaste arvuga:
Kategoriaalsete andmete proportsioonide illustreerimiseks kasutatakse ka
SEKTORDIAGRAMMI. Siin on ring jagatud sektoriteks nii, et iga sektori suurus on
proportsionaalne antud kategooria sagedusega.
Tulpdiagramm on ülevaatlikum juhul, kui me tahame võrrelda erinevate kategooriate sagedusi
omavahel, sektordiagramm aga juhul, kui me tahame näha iga üksiku kategooria osa tervikus.
Statistika loengumaterjale
Koostanud: Katrin Niglas TPÜ, informaatika õppetool
10
Oletame nüüd, et meid huvitab kas? ja kuidas? erinevad meeste ja naiste poolt eelistatavad
kooli jõudmise meetodid. Selleks tuleks koostada nn. RISTTABEL, kus naiste ja meeste
sagedused on toodud erinevates ridades:
Sellised risttabeleid on võimalik koostada mistahes kahe tunnuse jaoks.
Vaatame nüüd kuidas kokku võtta numbrilisi andmeid , st. andmeid, mis kuuluvad
kvantitatiivsesse tunnuse tüüpi. Meil on olemas andmed 50 õpilase pulsisageduse kohta. Toome
tulemused sellises järjekorras, nagu nad mõõtmisel saadi:
Ma arvan, et te ei vaidle mulle vastu, kui ma ütlen, et sellisel kujul on nendest numbritest
peaaegu võimatu midagi välja lugeda. Kas te saate ülevaate õpilaste pulsisagedusest? Kui kerge
on leida kõige kõrgemat ja kõige madalamat pulsisagedust? Kas pulsisagedused on jagunenud
ühtlaselt minimaalse ja maksimaalse väärtuse vahel või on mõned pulsisagedused tihedamini
esinevad kui teised?
Neile küsimustele oleks palju lihtsam vastata, kui meie pulsisagedused oleks järjestatud
suuruse järgi. Teeme seda:
50 tudengi pulsisagedused ( lööki minutis ):
Sellist rida, kus me oleme kvantitatiivse tunnuse väärtused järjestanud nende suuruse järgi
nimetatakse VARIATSIOONIREAKS e.JAOTUSEKS.
Nüüd on meil lihtne leida minimaalne ja maksimaalne pulsisagedus : 62 ja 96 lööki minutis.
Need väärtused võimaldavad meil lihtsalt leida jaotuse ULATUSE, milleks on maksimaalse ja
minimaalse väärtuse vahe. Meil 96 miinus 62 annab ulatuseks 34 lööki minutis.
Sellisest kasvavas järjekorras antud vaatlustulemuste reast on kerge leida ka jaotuse keskel
paiknevat väärtust ehk MEDIAANI . Mediaan on selline väärtus, mis jagab vaatlustulemused
kahte ossa nii, et pooled vaatlustulemused on mediaanist väiksemad ja pooled suuremad. Seega,
kui meil on teada seitsme üliõpilase kohta nende keskmine raamatukogus töötamise aeg nädalas
( tundides ):
0 2 3 4 6 6 10
siis saame öelda, et mediaan on 4 (tundi nädalas).
Kui meil on aga paaris arv vaatlustulemusi, siis ei saa me nende hulgast leida ühte, millest
oleks võrdne arv väiksemaid ja suuremaid väärtusi. Seepärast leitakse sel juhul väärtus, mis asub
täpselt kahe keskmise väärtuse vahel. Meie näites tudengite pulsisageduste kohta on 25-es
väärtus 79 ning 26-es 80. Et leida täpselt nende vahel paiknevat väärtust, tuleb need väärtused
kokku liita ning jagada kahega:
Seega mediaaniks on 79.5 lööki minutis.
Mediaan on üks statistikas kasutatavaid keskmist tendentsi väljendavaid suurusi. Kuid märksa
sagedamini kasutatakse ARITMEETILIST KESKMIST, mida tavaliselt kutsutaksegi lihtsalt
keskmiseks või siis keskväärtuseks. Aritmeetilise keskmise leidmiseks tuleb kõik
vaatlustulemused kokku liita ning saadud summa jagada vaatlustulemuste arvuga. Leiame nüüd
tudengite raamatukogus töötamise aja aritmeetilise keskmise:
Et mitte tülitada teid 50 pulsisageduse kokkuliitmisega ning saadud summa 50-ga jagamisega,
siis ütlen teile, et tudengite keskmine pulsisagedus (ehk pulsisageduste aritmeetiline keskmine)
on 79.1 lööki minutis. Kui te nüüd võrdlete kahte erinevat keskmist tendentsi väljendavat
suurust: mediaani ja aritmeetilist keskmist, siis te näete, et nad on natuke erinevad. Hiljem
näeme, millisel juhul on kasulikum ühte või teist näitajat kasutada.
Oleme nüüd vaadanud mitut erinevat võimalust oma andmete kirjeldamiseks, kuid kas meil on
praegu ettekujutus jaotuse üldisest kujust st. kas me saame seniste sammude põhjal vastata ka
viimasel küsimusele, mis puudutas pulsisageduste paiknemist minimaalse ja maksimaalse
väärtuse vahel?
* * *
Tõepoolest, selget pilti pulsisageduste paiknemisest variatsioonireale pealevaadates ei saa. Kui
me aga koostame “punkt-diagrammi”, st. märgime skaalal iga mõõdetud väärtuse punktiga, siis
näeme, et palju sagedamini esinevad pulsisagedused, mis on lähedal (ulatuse) keskpunktile.
Pulsisagedus 78 on mõõdetud kolmel tudengil (sagedus=3), kahel tudengil on pulsisagedus 90
ning mitte kellelgi ei ole mõõdetud pulsisageduseks 69 lööki minutis.
Milline väärtus esineb kõige sagedamini ehk millise väärtuse esinemise sagedus on kõige
suurem?
* * *
Kõige rohkem (neljal korral) on pulsisageduseks mõõdetud 80 ja 81 lööki minutis. Sellist
jaotuse väärtust, mis esineb kõige sagedamini nimetatakse MOODIKS. Antud näites toodud
jaotusel on seega kaks moodi: 80 ja 81 (need pulsisagedused on kõige “moodsamad” ehk kõige
sagedamini esinevad).
Moodi kasutatakse kõige rohkem kategoriaalsete tunnuste iseloomustamiseks. Oletame
näiteks, et 50-st küsitletust 27 olid abielus, 15 vallalised ning 8 lahutatud. Modaalne klass (ehk
kategooria) on siin kahtlemata “abielus”. Pange tähele, et kategoriaalsete tunnuste puhul me
aritmeetilist keskmist ega tavaliselt ka mediaani arvutada ei saa!
Pöördume nüüd tagasi meie pulsisageduste näite juurde. Sageli (eriti suurte andmehulkade
puhul) on aga kasulik vaatlusandmed grupeerida . Näiteks võime me küsida mitu
mõõtmistulemust on vahemikus 60-st 64-ni, mitu 65-st 69-ni, mitu 70-st 74-ni jne. Kui me oma
andmeid niimoodi grupeerime, saame järgmise tabeli:
Sellest tabelist on jaotuse üldine kuju veelgi selgemalt näha - meie näites “kuhjuvad”
vaatlusandmed jaotuse keskel. Kuid selline grupeerimine toob endaga paratamatult kaasa
informatsiooni kao. Jaotuse üldise kuju selgitamisel tuuakse ohvriks üksikud väärtused.
Ülaltoodud tabeli graafiliseks esituseks on HISTOGRAMM. See on tulpdiagramm, kus iga
väärtuste vahemikku tähistab ristkülik , mille kõrguseks on vastava vahemiku sagedus (või
osakaal protsentides).
Histogramm, vahemiku osakaal protsentides, sagedustabel
Keskimist tendentsi väljendavad arvkarakteristikud (keskmine /keskmised).
Hajuvust väljendavad arvkarakteristikud
Jaotuse kuju, asümmeetrilised jaotused,
Normaaljaotuse idee
Proportsioonid normaaljaotuskõvera all
Valimilt üldkogumile ehk järleduste tegemine üldkogumi kohta valimi põhjal
Valimi moodustamine
Järeldamine statistikas
Valimite keskväärtuste jaotus
Üldkogumi keskväärtuste hindamine
Teiste üldkogumi parameetrite hindamine
Valimite võrdlemine, kaks valimit: kas samast või erinevatest üldkogumistest. T.-test
Olulised testid,
Ühe- ja kahepoolsed (olulisus) testid
z-testid ja t-testid
I ja II tüüpi viga
Mitteparameetrilised meetodid, x2-test
Nähtustevahelised seosed, korrelatsioon
Korrelatsioonikordaja statistiline olulisus
Tulpdiagrammide koostamine
Üksikväärtuste analüüs
Tulpdiagramm koostamine (tulba kõrgus vastavalt arvule või %) järjestustunnus, nimitunnus
Binaarne tunnus, intervalltunnus, millel on palju erinevaid arvväärtusi
Tulpdiagrammide kujundamine, tulpade kujundamine
Teksti kujundamine, andmesiltide lisamine
Abijoonte kuvamine , telgede vahetamine
Tulpade järjestamine
Kirjeldav statistika, üldistav statistika
Millest sõltub andmeanalüüsimeetodi valik, andmete tüübid, üldistava statistika meetodite kontekst
Vea hindamine,
Normaaljaotuse PROPORTSIOONID
Normaaljaotuse põhjal saame järeldada, väärtuste standardiseerimine
Statistiline järeldamine, stattistiline üldistamine
Vahemikhinnang , usaldusintervall, korrelatsioonianalüüs
Korrelatsioonikordajad, pearsoni r,
Spearmani roo
Korrelatsioonikordajad, crameri V, , milline kordaja valida,
Tulemuste esitamine, rakenduslik uurimus, empiiriline uuring, uurimistüüpide omavahelised seosed
Andmekogumismeetodid, pilootuuring , küsimustik , üldine skeem, millest sõltub andmeanalüüsi valik,
Tunnuse tüübid, eeltöö -andmestiku korrastamine, sugu, vanus, kool, õppevaldkond,
Tegevusala ,
Andmeanalüüsi vahendid, andmeanalüüsi küsimus, esmane analüüs
Esmane ülevaade andmetest, sagedustabel, tabeli (ridade) järjestamine, järelduse koostamine
Järeldustes ...., statistiliste andmete esitamine,
Andmete esitamine- tekstina, tulpdiagramm, joondiagramm , tilpdiagramm ei võrdu histogramm, kirjeldavad arvnäitajad
Aritmeetiline keskmine e keskväärtus , ualtus e haar , kvartiilid,
Karpdiagramm, standardhälve ,
Asümeetria, tulemuste esitamine, andmeanalüüsi küsimus,
Erinevuste uurimine, keskväärtuse kaudu,
Korrelatsioonanalüüs, korrelatsioonikordaja,
1. Mõisted
1.1. Keskmist taset kirjeldavad arvnäitajad.
Mood – tunnuse enamlevinud väärtus (väärtus, mida esineb kõige sagedamini)
Mediaan – variatsioonirea keskel paiknev väärtus, mis jagab vaatlustulemused kahte ossa, pooled on
mediaanist suuremad ja pooled väiksemad.
Aritmeetiline keskmine (keskväärtus) kirjeldab jaotuse keskmist taset. Moonutatud pilti keskmisest tasemest
näitab siis kui jaotusel esinevad erandlikud väärtused. Sel juhul tuleks koos keskväärtusega keskmise
taseme kirjeldamiseks kasutada ka mediaani.
1.2. Andmete paiknemist kirjeldavad arvnäitajad.
Kvartiilid - jagavad vaatlustulemused nelja võrdsesse ossa.
Standardhälve – hajuvuse näitaja, mis arvestab kõiki vaatlustulemusi ning näitab kui palju üksikud
tulemused erinevad keskmisest. Mida suurem on hajuvus , seda rohkem nad erinevad ning seda suurem on
standardhälve. Kui kõik vaatlustulemused on ühesugused (Nt. kõik tudengid said kontrolltööl 15 palli), siis
hajuvust ei ole ja standardhälve on 0. (standardhälve ei ületa tavaliselt poolt jaotuse ulatusest)
2. Kirjeldavate arvnäitajate arvutamine programmis SPSS
Arvutame tunnuse koolikäidud aastate arv kohta kirjeldavad arvnäitajad.
Vali Analyze/Descriptive Statistics/Frequencies...
Vii tunnus kooliskäidud aastate arv Variable(s) väljale ning klpsa nupul Statistics ja vali soovitud statistikud:
Mean – keskväärtus
Median – mediaan
Mode – mood
Minimum – minimaalne
väärtus
Maximum –
maksimaalne väärtus
Std. deviation –
standardhälve
Range – ulatus
Kirjeldavate arvnäitajate arvutamine ja tõlgendamine 2012
Tulemuseks kuvatakse järgmine tabel:
Statistics
Koolis. Mitu aastat olete kooliharidust
saanud, koolides õppinud ?
N Valid 1497
Missing 6
Mean 12,83
Median 12,00
Mode 11
Std. Deviation 3,122
Range 29
Minimum 2
Maximum 31
Sagedustabeli koostamine ja kujundamine 2012
Koostatud juhend on mõeldud lisamaterjalina kasutamiseks „Andmeanalüüsi“ kursuse kuulajatele.
Näidiste ning õpetuste loomisel on kasutatud uuringu „Mina, Maailm ja Meedia 2008“ andmeid. Kõik näited
põhinevad statistikapaketi SPSS versioonil 18.0. Juhendi koostas K. Osula .
SAGEDUSTABELI KOOSTAMINE
Anname ülevaate ühe tunnuse väärtustest nende kokkuloendamise teel.
1. Koostame ülevaate tunnuse haridustase vastustest.
Valime Analyze/Frequencies
Vali tunnus Harudustase ja
vii see Variable(s) väljale.
Oluline on, et Display
frequency tables ees oleks
linnuke – siis koostatakse
sagedustabel.
Tulemus kuvatakse tulemuste (Output) faili.
Esmalt antakse üldine
ülevaade (Statistics)
vastajate vastustest (kui
paljud vastasid Valid ja kui
palju ei vastanud sellele
küsimusele Missing)
Sagedustabelis esitatakse
tunnuse väärtused (Valid),
nende esinemissagedused
(Frequency) ning
protsendid (Percent).
JÄRJESTUS-TUNNUS
Sagedustabeli koostamine ja kujundamine 2012
Tabeli kujundamiseks (sõnade muutmiseks, osa kustutamiseks) tee selle peal topeltklõps.
Peale tabeli valimist (topeltklõps tabeli peal) leiad lisavahendeid Format menüüst. Näiteks Table Looks
võimaldab kujundada tabelit (värvilahendused).
Kujundatud lõpptulemus võiks välja näha näiteks selline:
Tabel 1. Vastajate kõrgem omandatud haridustase
Vastajate arv Osakaal
Algharidus 47 3,1%
Põhiharidus 228 15,1%
Kutseharidus (ilma keskhariduseta) 83 5,5%
Keskharidus 401 26,6%
Kutseharidus + keskharidus 367 24,4%
Rakenduslik kõrgharidus 170 11,3%
Ülikooliharidus, kraadiharidus 211 14,0%
KOKKU 1507 100,0
2. Koostame ülevaate tunnuse perekonnaseis vastustest.
Valime Analyze/Frequencies
Viime tunnuse Perekonnaseis Variable(s) väljale ning kinnitame oma valiku.
Esialgne tulemus on selline:
Juhul kui tabelis toodud kategooriad
ei ole sisuliselt tähenduslikus
järjekorras, siis järjestatakse tabeli
read sageduste/osakaalude järgi.
Sagedustabeli järjestamiseks sageduste järgi koostame uue sagedustabeli. Valime Analyze/Frequencies
Viime tunnuse Perekonnaseis Variable(s) väljale ning klõpsame nupul Format.
Määrame loodava tabeli
järjestatavuse ( Order by) nii, et
tulemused esitatakse sageduste
kahanevas järjekorras (kõige
suuremad väärtused ülal,
väiksemad allpool)
NIMITUNNUS
Sagedustabeli koostamine ja kujundamine 2012
Kujundatud lõpptulemus võiks välja näha näiteks selline:
Tabel 2. Perekonnaseis
Vastajate arv Osakaal
Ametlikus abielus 603 40,0%
Üksik (pole olnud abielus) 331 22,0%
Vabaabielus (elan koos partneriga) 288 19,1%
Lahutatud / Elan lahus 170 11,3%
Lesk 112 7,4%
Vastamata 2 ,1%
Kokku 1506 99,9%
Vastus puudub 1 ,1%
KOKKU 1507 100,0%
3. Intervalltunnuse puhul tuleb vahet teha, kas tunnusel on vähe või palju
erinevaid väärtuseid.
Väheste erinevate väärtustega tunnuse korral järgi näidet nr 1 (haridustase).
Kui tunnusel on aga palju
erinevaid väärtuseid,
näiteks sissetulekud on
kõikidel vastajatel tõenäoliselt erinevad,
siis sagedustabel andmete
kokkuvõtmiseks ei sobi.
Andmestikus kultuur.sav on selliseks
tunnuseks vanus. Koostades vanuse
väärtustest sagedustabeli, on see liiga
mahukas, et seda andmete esitamiseks
kasutada.
Kui on aga tingimata vaja esitada paljude
erinevate väärtustega intervalltunnuse
tulemusi tabeli kujul, siis tuleks kaaluda
andmete koondamist väiksematesse
gruppidesse (Transform/Visual Binning)
ning koostada sagedustabel grupeeritud
väärtustest.
INTERVALL -TUNNUS
Sagedustabeli koostamine ja kujundamine 2012
Grupeerime tunnuse vanus väärtused (Transform/Visual Binning) ning moodustame järgmised vahemikud:
Koostades grupeeritud tunnuse väärtuste kohta sagedustabeli, võiks kujundatud lõpptulemus välja näha
näiteks selline:
Tabel 3. Vanus
Vastajate arv Osakaal
Z
Descending– kahanevas järjekorras: 9 8 7 ... 1 või Z->A
Uue tunnuse väärtuste arvutamine. Transform/Compute Variable
Target Variable– uue tunnuse nimi
Type & Label– uue tunnuse kirjeldamine
Numeric Expression– avaldis, mille järgi uued väärtused
arvutatakse.
Andmete ümberkodeerimine. Transform/Recode
... Into Same Variables – väärtuste väljavahetaminesamas tunnuses.
... Into Different Variables – uued väärtused paigutatakse uue tunnusena.
Old Value– väärtus(ed), millele soovid uut väärtust omistada.
value – üksik muudetav väärtus
system-missing – tühi lahter
range – väärtuste piirkond
all other values – kõik ülejäänud väärtused
New Values– uus väärtus või Copy old value(s), kui soovid, et uude tunnusesse kopeeritakse
praegused väärtused.
1.4. Harjutused
1. Ekspordi SPSS-i Exceli tabel: rahvastik .xls (rahvastiku ülevaade, 1. jaanuar 2003)
2. Defineeri tunnused. (linn – 1, vald - 2)
Mitu linna, mitu valda on Eestis?
3. Arvuta rahvaarv igas linnas, vallas.
Millises vallas elab kõige vähem inimesi?
4. Arvuta iga linna, valla asustustihedus (mitu inimest elab 1 km
2
).
Millises linnas on see suurim, millises kõige väiksem?
5. Leia naiste arv 10 mehe kohta.
Kus on naiste arv 10 mehe kohta kõige väiksem ja kui palju see on?
6. Jaga vastajad gruppidesse järgmiselt: „naisi rohkem“, „mehi rohkem“,
„naisi mehi võrdselt“. Mitmes Eesti linnas/vallas on mehi naisi võrdselt?
ANDMEANALÜÜS : statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -4-
1.5. Tunnusetüübid
Vastavalt sellele, mida või keda me uurime, koosnebmeie valim objektidest ja kõigil valimisse kuuluvatel
objektidel on mingid iseloomulikud tunnused. Näiteks värv, hind, sugu, kaal.
Numbrilised tunnusedon näiteks: vanus, pikkus. Kõik sellised tunnused,mida saab arvuliselt mõõta.
Mittenumbrilised on: juuste värv, elukoht. Neid ei saa mõõta arvuliselt, võivad väljendada hinnangut .
2. Andmete esitamine
Vali esitluseks TABEL, kui on vajalik anda edasi täpset arvulist infotvõi kui võrreldavate arvnäitajate
suurusjärgud on väga erinevad
Vali esitluseks DIAGRAMM, kui soovid eelkõige anda kiiret ülevaadet üldtendentsi(de)st ja
suundumus (te)st
Vali arvulise info edastusviisiks TEKST, kui korraga on vaja esitada vaid üks-kaks arvulist näitajat
K.Niglas
Sõltuvalt uurimistöö iseloomust valitakse sobiv tulemuste esitamise vorm, kusjuures joonised ei tohiks
tabelites sisalduvat dubleerida ja vastupidi. Mahukamad ja eriti algandmeid sisaldavad tabelid võib
paigutada uurimistöö lõpus esitatavate lisade hulka. Oluline on, et jooniste, tabelite jm esitatud andmed
oleksid tekstis kirjeldatud, analüüsitud ja sissejuhatavas osas toodud probleemiga loogiliselt seostatud .
Tulemuste kirjeldamisega liitub arutelu, millest peaks muuhulgas selgesti välja tulema üliõpilase isiklik osa
antud probleemi lahendamisel. http://www.med.ut.ee/
3. Andmete esitamine tekstina
Kui vastajaid on vähem kui 100, siis kasuta andmete esitamisel tekstina sagedusi.
Eksamil osalenud 39-st üliõpilasest ligi kolmandik (15) oli osalenud kõikides loengutes; kõikides
praktikumides osalemise vastav arv oli 10.
Küsimustiku täitis 34 vastajat , kellest 4 olid üliõpilased, 10 alamastmejuhid, 2 tippjuhid, 6 pensionärid, 3
reatöötajad, 1 vabakutseline ning 8 töötud .
Kui vastajaid on rohkem kui 100, siis kasuta andmete esitamisel tekstina protsente.
Seisuga 30 aprill 2007 on 1.6% vanemahüvitise saajatest mehed.
TUNNUSTE TÜÜBID
KVANTITATIIVSED KVALITATIIVSED
Palju erinevaid
väärtuseid
Vähe erinevaid
väärtuseid
Järjestustunnused Nimitunnused
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -5-
4. Andmete esitamine tabelitena
4.1. SAGEDUSTABEL (Analyze/Descriptive Statistics/Frequencies)
Tabel 1. Kui huvitatud te poliitikast olete?
Frequency Percent
Valid
Percent
Cumulative
Percent
Valid väga huvitatud
139 8,4 8,4 8,4
üsna huvitatud
606 36,5 36,7 45,1
vähe huvitatud
700 42,1 42,3 87,4
üldse ei tunne huvi
208 12,5 12,6 100,0
Total
1653 99,5 100,0
Missing ei oska öelda
6 ,4
vastus puudub
2 ,1
Total
8 ,5
Total
1661 100,0
Tabel 1A. Kui huvitatud te poliitikast olete?
Vastajate arv %
väga huvitatud
139 8,4
üsna huvitatud
606 36,5
vähe huvitatud
700 42,1
üldse ei tunne huvi
208 12,5
ei oska öelda
6 ,4
vastus puudub
2 ,1
KOKKU
1661 100,0
Tabel 2. Millise erakonna poolt Te 2007.a. toimunud Riigikogu valimistel hääletasite?
Vastajate
arv %
Reformierakond 294 17,7
Keskerakond 237 14,3
Erakond Isamaa ja Res Publica
Liit
133 8,0
Sotsiaaldemokraatlik Erakond 81 4,9
Eestimaa Rohelised 69 4,2
Rahvaliit 46 2,8
Muu 12 ,8
Ei saanud vastata 719 43,4
Vastamata 70 4,2
KOKKU 1661 100,0
Tabel 3. Kuivõrd te usaldate poliitikuid
Kas Teie osalesite viimastel valimistel?
Frequency– vastajate arv
Percent- %
Valid percent– osakaal
mittepuuduvatest väärtustest
(protsent vastanutest)
Cumulative Percent–
kumulatiivne protsent:
poliitikast väga huvitatuid on 8,4%;
väga huvitatuid ja üsna huvitatuid
on 45,1% (8,4+36,5) jne.
Tabeli kujundamine
Topeltklõps tabeli peal (aktiveerib muutmise režiimi)
Veerud kitsamaks, laiemaks
Andmete kustutamisel kaob veerg automaatselt
Format/Table Looks...
Format/Rotate Inner Column Labels
Pivot /Transpose Rows and Columns
2007.a. Riigikogu valimiste tulemused[vikipeedia]:
27,8% Reformierakond
26,1% Keskerakond
17,9% Isamaa ja Res Publica Liit
10,6% Sotsiaaldemokraatlik Erakond
7,1% Rahvaliit; 7,1% Erakond Eestimaa Rohelised
Pikkade tabelite puhul tuleks andmeid grupeerida või
esitada tabelid töö lisades.
Mõtle ka enne andmete kogumist nende esitamisele,
vältimaks olukorda, kus kogutud andmeid on keeruline
soovitud kujul esitada.
Tabel 3A.Kuivõrd te usaldate poliitikuid
Vastajate arv %
Ei usalda
877 54,3
Nii ja naa 602 36,3
Usaldab
135 8,2
Vastamata
47 2,8
KOKKU
1661 100,0
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -6-
4.2. Harjutused.
Kopeeri küsimuse: „Kui tihti tundub poliitika Teile nii keerulisena, et Te ei saa päriselt aru, mis toimub?“
vastused tabelina tekstidokumenti kolmel erineval kujul (formaatimata tekst, formaaditud tekst, pilt)
Kui tihti tundub poliitika Teile nii keerulisena, et Te
ei saa päriselt aru, mis toimub?
99 6,0
335 20,2
701 42,2
345 20,8
158 9,5
1638 98,6
21 1,3
2 ,1
23 1,4
1661 100,0
Mitte kunagi
Harva
Vahetevahel
Sageli
Väga sageli
Total
Valid
Ei oska öelda
Vastus puudub
Total
Missing
Total
Frequency Percent
Kopeeri tekstidokumenti kõik loodud sagedustabelid (Copy
Objects)
Ekspordi tekstifailiks (Text Filevõi Word/RTF File) kõik
loodud objektid
Ekspordi esitlusfailiks (Powerpoint File) ainult tulemused
(visible objects)
4.3. ANDMESTIKU JAGAMINE OSADEKS.
1. Jagame andmestiku osadeks (tunnuse sugupõhjal)
2. Tellime sagedustabeli küsimuse „Kas Teie osalesite viimastel valimistel?“ tulemuste kohta.
3. Taastame esialgse olukorra (eemaldame osadeks jagamise ).
Tabel 4A. Kas Teie osalesite viimastel valimistel?
Mees Naine
Vastajate
arv
Vastajate
arv
Jah 367 52,1 573 59,9
Ei 240 34,1 273 28,5
Pole
valmisõigust
88 12,5 106 11,1
Vastamata 9 1,3 5 ,5
KOKKU 704 100,0 957 100,0
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -7-
4.4. SAGEDUSTABEL (Analyze/Tables/Tables of Frequencies)
Tabel 5. Kui huvitatud te poliitikast olete?
Vastajate arv %
väga huvitatud
139 8,4%
üsna huvitatud
606 36,7%
vähe huvitatud
700 42,3%
üldse ei tunne huvi
208 12,6%
KOKKU
1653 100,0%
Tabel 6.Mitme küsimuse ( ühesuguste vastusevariantidega) vastused koos. Üldine rahulolu...
riigi majandusliku
olukorraga valitsuse tööga
hariduse olukorraga
riigis
tervishoiusüsteemiga
riigis
Sagedus % Sagedus % Sagedus % Sagedus %
Üldse mitte rahul 205 12,6% 209 12,9% 28 1,8% 45 2,8%
1
128 7,9% 134 8,3% 22 1,4% 52 3,2%
2
199 12,2% 211 13,1% 60 3,8% 137 8,4%
3
310 19,0% 279 17,3% 133 8,4% 210 12,9%
4
231 14,2% 216 13,4% 134 8,4% 203 12,4%
5
248 15,2% 259 16,0% 267 16,8% 265 16,2%
6
131 8,0% 132 8,2% 239 15,1% 208 12,8%
7
108 6,6% 92 5,7% 320 20,2% 262 16,1%
8
45 2,8% 60 3,7% 270 17,0% 176 10,8%
9
14 ,9% 8 ,5% 85 5,4% 51 3,1%
Väga rahul
11 ,7% 16 1,0% 28 1,8% 22 1,3%
KOKKU
1630 100,0% 1616 100,0% 1586 100,0% 1631 100,0%
4.5. RISTTABEL (Analyze/Descriptive Statistics/Crosstabs)
Tabel 7. Kui huvitatud te poliitikast olete?
väga huvitatud üsna huvitatud vähe huvitatud üldse ei tunne huvi KOKKU
Sugu Mees Arv
61 286 270 82 699
% 8,7% 40,9% 38,6% 11,7% 100,0%
Naine Arv
78 320 430 126 954
% 8,2% 33,5% 45,1% 13,2% 100,0%
KOKKU Arv
139 606 700 208 1653
% 8,4% 36,7% 42,3% 12,6% 100,0%
Tabel 8. Kas Teie osalesite viimastel valimistel?
Kas Teie osalesite viimastel valimistel?
KOKKU Jah Ei Pole valimisõigust
Sugu Mees Arv
367 240 88 695
% 52,8% 34,5% 12,7% 100,0%
Naine Arv
573 273 106 952
% 60,2% 28,7% 11,1% 100,0%
KOKKU Arv
940 513 194 1647
% 57,1% 31,1% 11,8% 100,0%
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -8-
4.6. KOONDTABEL (Analyze/Tables/ Basic Tables)
Tabel 9. Erinevate institutsioonide usaldamine
Sugu
Mees Naine
Vastajate
arv Keskväärtus
Vastajate
arv Keskväärtus
Kuivõrd te usaldate valitsust 704 3,88 957 3,88
Kuivõrd te usaldate õigussüsteemi
704 4,89 957 4,81
Kuivõrd te usaldate politseid 704 6,00 957 6,09
Kuivõrd te usaldate poliitikuid
704 3,25 957 3,32
Kuivõrd te usaldate poliitilisi parteisid ja erakondi
704 3,15 957 3,30
Kuivõrd te usaldate Euroopa parlamenti
704 4,90 957 5,10
Kuivõrd te usaldate Ühinenud Rahvaste Organisatsiooni
704 5,26 957 5,32
Summaries – Kuivõrd...
Across– Sugu
Statistics– count , mean
4.7. Harjutused
1. Kas võime väita, et nende seas, kes on mõne poliitilise partei või erakonna liikmed, oli valimistel
osalemise protsent kõrgem kui teistel?
2. Kas elukoht ja poliitikast huvitatus on seotud?
3. Kui palju on vastajate hulgas neid, kellele tundub poliitika Teile nii keerulisena, et ta ei saa päriselt aru,
mis toimub? Kuidas on jagunenud need arvamused naiste-meeste vahel?
4. Võrrelge naiste-meeste vastuseid rahulolu küsimustele (y4, y5, y6, y8, y9). Mida saate järeldada?
5. Mis keelt kõneleva vastajaskonna valimistel osalemise protsent oli kõige suurem?
5. Üldine ülevaade vastajatest
Nr. Tunnus Kuidas saate vastuse Mil viisil esitate tulemuse oma töös?
Vastajate üldarv
Meeste, naiste jaotus
Regioon
Riigi kodanik
Kodune keel
Vanuseline jaotus
Haridustase
Elukoht
Leibkonna suurus
Kodus elavaid lapsi
Tegevus
Sissetulek
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -9-
6. Andmete graafiline esitamine
Kasuta - tulpdiagrammi, kui tahad võrrelda erinevate kategooriate sagedusi omavahel.
- sektordiagrammi, kui tahad esile tuua osa tervikust
- joondiagrammi, kui tahad esitada nähtuse muutumist ajas
- histogrammi, kui tunnusel on palju erinevaid väärtusi
6.1. HISTOGRAMM (Graphs/ Histogram ...)
tunnus peab olema numbriline
tunnusel peab olema piisavalt palju erinevaid väärtusi (EI SOBI: vanus: 19,20,21)
Joonisel 1. on tehtud tulpdiagramm.
Paremini sobiks histogramm, mis koondaks andmed vahemikesse ja
tulemus oleks ülevaatlikum.
Joonis 3.
Joonisel 2. on tehtud histogramm.
Paremini sobiks tulpdiagramm, kuna tunnusel on ainult kolm erinevat
vastusevarianti (ja neid kolme vastust ei ole vaja gruppidesse jagada).
Joonis 4.
Millised järgnevatest tunnustest võimaldaksid koostada histogrammi?
Piirkond (Eesti)
Olete riigi kodanik?
Kodune keel
sugu
sünniaasta
vanus (arvutatud)
Elukoht
Perekonnaseis
Kas teil on kodus elavaid lapsi
Leibkonna suurus
Haridustase
Kooliskäidud aastate arv
Joonis 5. Histogramm vanuselisest jaotusestJoonis 5A. Histogramm vanuselisest jaotusest
EELISTUS
321
Frequency
6
5
4
3
2
1
0
321 321
SISSETULEK
10001-15000 5001-10000 1001-5000
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -10-
6.1.1. Histogrammi kujundamine
Tulpade/ tausta
värvi
muutmine
1. Märgista tulbad/taust
2. Vali Propertiesaknast
Fill & Border
3. Vali värv
4. Kinnita valik Apply
nupuga
Vahemiku
laiuse
muutmine
1. Märgista tulbad
2. Vali Propertiesaknast
Histogram Options
3. Bin Sizes/Interval width
Skaala
muutmine
1. Märgista skaala (x-telje
skaala numbrid)
2. Vali Propertiesaknast
Scale
3. Major Increment –
vaheühiku laius
Abijoonte
lisamine
1. Märgista y-telje skaala numbrid
2. Vali Optionsmenüüst Show
Gridlines
Kui jätsid skaala numbrid valimata,
saad abijooned nii x- kui ka y-teljelt.
Neid saab eemaldada kustutades kui
ka eemaldades (Hide Gridlines)
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -11-
6.1.2. Histogrammi sisu
Joonis 6.Mitu tundi te oma töökohal tavaliselt töötasite (koos ületundidega)?
Kas selliste andmete esitamiseks sobib histogramm?
Millise küsimuse vastuseid saab illustreerida histogrammi abil:
Joonis 7. Vastaja haridus (kõrgeim omandatud haridustase) Joonis 7A. Koolis käidud aastate arv
1 2 3 4 5 6 7 8 9
10
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -12-
6.2. ÜLDISED VÕIMALUSED GRAAFIKUTE REDIGEERIMISEL
1. Panel by
Grupeeriv
tunnus
(sugu)
paigutatud
ritta (row)
Grupeeriv
tunnus
(sugu)
paigutatud
veergu
(column)
2. Graafiku suuruse muutmine
Graafiku suurust tuleb muuta redigeerimisaknas ( Chart Editor ) programmis SPSS.
Kui kopeerite originaalsuuruses graafiku tekstitöötlus-programmi, muutub graafiku tekst vähendades suhteliselt
loetamatuks.
3. Diagrammide kopeerimine
Vali Paste Special /Bitmap
10 8 6 4 2 0
koormustesti tulemus
300
250
200
150
100
50
0
Vastajate arv
10 8 6 4 2 0
koormustesti
tulemus
300
250
200
150
100
50
0
Vastajate arv
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -13-
6.3. SEKTORDIAGRAMM
tunnus peab olema kvalitatiivne ( nominaalne või järjestus) või numbriline, millel on vähe erinevaid
väärtuseid (EI SOBI: sissetulek, keskmine hinne; kui on palju erinevaid vastuse variante )
980
905
900
887
868
860
850
845
842
840
830
824
822
800
795
794
790
788
780
777
770
760
755
750
747
742
739
735
730
728
725
720
714
712
710
702
700
689
660
655
650
640
626
620
618
610
607
600
599
590
586
583
581
580
575
570
565
561
560
558
557
555
553
552
551
550
549
547
545
542
540
539
532
530
529
528
526
524
520
519
518
517
515
514
512
511
510
509
504
502
501
500
498
495
487
485
482
480
479
478
475
473
471
470
469
468
465
460
459
458
455
453
450
449
445
444
440
439
435
434
433
430
429
420
418
409
408
401
400
399
397
395
390
385
380
373
372
369
366
360
350
345
335
330
325
320
315
300
295
290
285
280
275
270
256
240
234
230
205
200
195
180
179
162
160
128
100
90
87
84
80
75
60
8
0
sissetulek
viimasel kuul
Millised järgnevatest tunnustest võimaldaksid koostada histogrammi?
Piirkond (Eesti)
Olete riigi kodanik?
Kodune keel
sugu
sünniaasta
vanus (arvutatud)
Elukoht
Perekonnaseis
Kas teil on kodus elavaid lapsi
Leibkonna suurus
Haridustase
Kooliskäidud aastate arv
Sektordiagrammi kujundamine
Ühe sektori
välja tõstmine
märgista 1 sektor ja vali
Elements/ Explode Slice
Andmesiltide
lisamine
märgista sektorid ja vali
Elements/Show Data Labels
7
3
364
625
115
448
Sektorite
ühendamine
märgista sektorid ja vali
Categories lehelt
Collapse (sum) catogories...
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -14-
6.4. TULPDIAGRAMM. Bar…
6.4.1. Vasta järgmistele küsimustele:
a) Kirjelda, milliste andmete esitamiseks sobiks tulpdiagramm
b) Too näide tunnusest, mille väärtuste esitamiseksei sobiks tulpdiagramm
c) Selgita histogrammi ja tulpdiagrammi erinevusi (visuaalseid, sisulisi)
d) Mida peaks silmas pidama tulpdiagrammi kujundamisel
Vaata lisaks: Statistikaameti materjali tulpdiagrammi koostamise kohta:
http://www.stat.ee/files/koolinurk/abiks/graafiline/tulpdiagramm.php
Esmalt tuleb valida 3 ülemise variandi seast:
Simple – tavaline (iga tulp kirjeldab ühte
tunnust või gruppi)
Clustered– võrdlev (tulbad üksteise kõrval)
Stacked– võrdlev liidetud diagramm
Seejärel tuleb valida 3 alumise variandi seast:
Summaries for groups of cases - Kokkuvõtted objektide
gruppide kohta
Summaries of separate variables- Kokkuvõtted
erinevate tunnuste kohta
Values of individual cases- Üksikväärtuste analüüs
6.4.2. Tavalised tulpdiagrammid: SIMPLE ; SUMMARIES FOR GROUPS OF CASES
Uuritav tunnus paigutage Category Axis väljale
Tulba kõrguseks valige vastajate arv (N of cases)
Joonis 5.Vastajate elukoht
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -15-
6.4.3. Diagrammi kujundamine
Tulpade
järjestamine
Märgista tulbad ja vali
Categories/Sort by...
x-telje teksti
kujundamine
Märgista x-telje tekst
ning vali
Labels&Ticks/ Labels
Orientation
(see, et sa oskad ei
tähenda, et sa seda
kasutama pead!)
Telgede
vahetamine
Options/Transpose
Chart
Joonis 6. Joonis 7.
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -16-
6.4.4. Tavalised tulpdiagrammid: SIMPLE; SUMMARIES OF SEPARATE VARIABLES
Teeme kokkuvõtted mitme erineva tunnuse vastustest
A. Tunnuste väärtustest saab arvutada keskväärtust
Joonis 8. Kuidas suurem osa inimestest hindaks ... aastastes inimeste staatust?
B. Tunnuste väärtustest ei saa arvutada keskväärtust
Peale pereliikmete , kui palju on Teil ligikaudu sõpru, kes on nooremad kui
30 aastased?
Peale pereliikmete, kui palju on Teil ligikaudu sõpru, kes on vanemad kui
70 aastased?
Loeme kokku need, kes vastasid:
6-9
10 või rohkem
Seega loeme kokku vastuseid, mis on suuremad numbrist 3.
Joonis 9. Kuidas suurem osa inimestest hindaks ... aastastes inimeste staatust?
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -17-
6.4.5. Võrdlevad tulpdiagrammid: CLUSTERED; SUMMARIES OF SEPARATE VARIABLES
Teeme kokkuvõtted mitme erineva tunnuse vastustest (valitud gruppide kohta)
Joonis 10. Kuidas on jagunenud sõprade arv meeste naiste vahel.
6.4.5. Võrdlevad tulpdiagrammid: CLUSTERED; SUMMARIES OF GROUPS OF CASES
Kui vana te olete * Üldine tervislik seisund Crosstabulation
85 216 75 10 2 388
21,9% 55,7% 19,3% 2,6% ,5% 100,0%
76 382 613 163 37 1271
6,0% 30,1% 48,2% 12,8% 2,9% 100,0%
161 598 688 173 39 1659
9,7% 36,0% 41,5% 10,4% 2,4% 100,0%
Count
% within Kui vana te olete
Count
% within Kui vana te olete
Count
% within Kui vana te olete
29 või noorem
30 või vanem
Kui vana
te olete
Total
Väga hea Hea Rahuldav Halb Väga halb
Üldine tervislik seisund
Total
Joonis 11.
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -18-
7. Andmete esitamine kirjeldavate arvnäitajate abil
A. Märgi, mis tüüpi andmete korral tabelis antud arvnäitajaid arvutada saab.
Statistik NR, palju erinevaid
väärtuseid
NR, vähe erinevaid
väärtuseid
nimitunnus järjestustunnus
MOOD
MEDIAAN
KESKVÄÄRTUS
B. Märgi joonisele statistikud ja nende vahele jäävate andmete protsendid
C . _______________________________________________on statistiline väärtus, mis näitab, kui palju
väärtused erinevad keskmisest väärtusest.
Näiteks kui on kaks aktsiaportfelli, mis mõlemad onkeskmiselt teeninud kasumit 10 % aastas ning kui portfelli A standardhälve on
väiksem kui portfelli B oma, siis see tähendab, et esimene portfell on olnud stabiilsem ning vastupidiselt teise portfelli väärtus on
rohkem kõikunud. Suurem kõikuvus viitab suuremale riskisusele. (www.tarkinvestor.ee)
Tabel 10.
Mitu tundi oma põhitöökohal tavaliselt nädalas
töötate / töötasite, kui võtate arvesse ka kõik
tasustatud ja tasustamata ületunnid?
N Valid 1417
Missing 244
Mean 41,59
Median 40,00
Mode 40
Std. Deviation 10,405
Skewness ,213
Std. Error of Skewness ,065
Range 99
Minimum 1
Maximum 100
Percentiles 25 40,00
50 40,00
75 45,00
Joonis 12. Töötundide arv nädalas
Kokku koguti vastuseid _____________________
respondendilt, kellest _______________ keeldus
vastamast või ei teadnud vastust
Vastajate keskmine töötundide arv nädalas oli
_____________ tundi.
Pooled vastajatest märkisid tööajaks vähem ja
pooled rohkem kui ___________________ tundi.
Kuna mediaan ja keskväärtus on väga sarnased,
võime järeldada, et andmete jaotus on
____________________ ning keskmise tendentsi
kirjeldamiseks võib kasutada ________________.
Suur osa vastajatest töötab nädalas __________
tundi, mis on ühtlasi ka jaotuse ______________.
Antud tunnuse korral on/ei ole see hea näitaja,
sest____________________________________.
Töötundide standardhälve oli ________________
(ühe väärtuse korral ei ole võimalik võrrelda, kas
hajuvus on suur või väike).
Kõige vähem märgiti tööajaks ___________ tundi
ja kõige rohkem _________________ tundi.
Asümmeetria kordaja oli _______________, mille
põhjal saame järeldada, et vastuste jaotus on
________________________________________
Ülemise kvartiili väärtus oli _________________,
millest järeldub, et _________________________
_______________________________________.
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -19-
8. Korrelatsioonanalüüs
Kordaja
absoluutväärtus
Seose tugevus
0-0,09
0,1-0,19
0,2-0,19
0,3-0,69
0,7-0,89
0,9-1,0
__________________________________________
Mõlemad tunnused numbrilised, on tundlik erandite
suhtes.
__________________________________________
Üks või mõlemad tunnused järjestustunnus(ed), vähendab
erandite mõju, kuna kordaja leidmisel kasutatakse
astakuid, mitte konkreetseid väärtuseid.
__________________________________________
Üks või mõlemad tunnused järjestustunnus(ed), ei ole
tundlik erandite suhtes kuna vaadeldakse objektide paare.
8.1. Näited
A.
Tunnused on
numbrilised
Erandlikud
väärtused
puuduvad
Tööaeg (ilma
lisatundideta)
Tööaeg (koos
lisatundidega)
Tabel 11.
Töötunnid
nädalas
Töötunnid
nädalas koos
ületundidega
Töötunnid nädalas Pearson
Correlation
1 ,783(**)
Sig. (2- tailed ) ,000
N 1514 1414
Töötunnid nädalas
koos ületundidega
Pearson
Correlation
,783(**) 1
Sig. (2-tailed) ,000
N
1414 1417
** Correlation is significant at the 0.01 level (2-tailed).
Seose kordaja on 0,78
Uuritud tunnuste vahel on tugev positiivne seos. Mida rohkem oli vastajal töötunde, seda suurem oli
tema koormus koos ületundidega ja vastupidi, mida vähem oli vastajal töötunde nädalas, seda väiksem
oli tema töökoormus.
Tunnuste vahelise seose determinatsioonikordaja (d=r
2
) on 0,61.
Seost saab üldistada üldkogumile, olulisusnivool 0,01
KORRELATSIOON-ANALÜÜS
Tunnused on
numbrilised
Vähemalt üks tunnustest
on järjestustunnus
Vähemalt üks tunnustest
on nominaalne
Erandlikud väärtused
puuduvad
Vähemalt ühel tunnusel
esinevad erandlikud
väärtused
___________________
kordaja
___________________
kordaja
___________________
kordaja
___________________
kordaja
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -20-
B.
Tunnused on
numbrilised
Erandlikud
väärtused
puuduvad
Vanus
Kooliskäidud
aastate arv
Tabel 12.
vanus
(arvutatud)
Kooliskäidud
aastate arv
vanus (arvutatud) Pearson
Correlation
1 -,188(**)
Sig. (2-tailed)
,000
N 1661 1643
Kooliskäidud aastate
arv
Pearson
Correlation
-,188(**) 1
Sig. (2-tailed)
,000
N 1643 1643
** Correlation is significant at the 0.01 level (2-tailed).
Tabel 13.
vanus
(arvutatud)
Kooliskäidud
aastate arv
Spearman's
rho
vanus
(arvutatud)
Correlation
Coefficient
1,000 -,153(**)
Sig. (2-tailed)
. ,000
N 1661 1643
Kooliskäidud
aastate arv
Correlation
Coefficient
-,153(**) 1,000
Sig. (2-tailed)
,000 .
N
1643 1643
** Correlation is significant at the 0.01 level (2-tailed).
Seose kordaja on -0,19
Uuritud tunnuste vahel on väga nõrk negatiivne seos. Mida vanem on vastaja, seda vähem on ta koolis
käinud ja vastupidi, mida noorem on vastaja seda rohkem on tal kooliskäidud aastaid.
Olematute, väga nõrkade ja nõrkade seoste korral determinatsioonikordaja leidmine ei ole mõtekas.
Seost saab üldistada üldkogumile, olulisusnivool 0,01
C.
Tunnused on
numbrilised
Erandlikud
väärtused
puuduvad
Kooliskäidud
aastate ja
töötundide arv
nädalas (koos
lisatundidega).
Tabel 14.
Kooliskäidud
aastate arv
Töötundide
arv nädalas
(koos
lisatundidega)
Kooliskäidud aastate
arv
Pearson
Correlation
1 -,034
Sig. (2-tailed)
,207
N
1643 1409
Töötundide arv
nädalas (koos
lisatundidega)
Pearson
Correlation
-,034 1
Sig. (2-tailed)
,207
N 1409 1417
Tabel 15.
Kooliskäidud
aastate arv
Töötundide
arv nädalas
(koos
lisatundidega)
Spearman's
rho
Kooliskäidud
aastate arv
Correlation
Coefficient
1,000 -,033
Seose kordaja on 0,03
Uuritud tunnused ei ole omavahel seotud.
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -21-
D.
Tunnused on
numbrilised
Vähemalt ühel
tunnusel
esinevad
erandlikud
väärtused
Vanus
Millal (mis
aastal) olite
viimati tasulisel
tööl?
Tabel 16.
vanus
(arvutatud)
Mis aastal Te
viimati olite
tasulisel tööl?
vanus (arvutatud) Pearson Correlation
1 -,623(**)
Sig. (2-tailed)
,000
N
1661 588
Mis aastal Te
viimati olite tasulisel
tööl?
Pearson Correlation
-,623(**) 1
Sig. (2-tailed)
,000
N
588 588
** Correlation is significant at the 0.01 level (2-tailed).
Tabel 17.
vanus
(arvutatud)
Mis aastal
Te viimati
olite
tasulisel
tööl?
Spearman's
rho
vanus
(arvutatud)
Correlation
Coefficient
1,000 -,744(**)
Sig. (2-tailed)
. ,000
N
1661 588
Mis aastal Te
viimati olite
tasulisel tööl?
Correlation
Coefficient
-,744(**) 1,000
Sig. (2-tailed)
,000 .
N
588 588
** Correlation is significant at the 0.01 level (2-tailed).
Seose kordaja on -0,74
Uuritud tunnuste vahel on tugev negatiivne seos.
Seost saab üldistada üldkogumile, olulisusnivool 0,01
E.
Vähemalt üks
tunnustest on
järjestustunnus
Kooliskäidud
aastate arv
Sissetulek
(vastused
esiatud
vahemikena)
Tabel 18.
Kooliskäidud
aastate arv
Leibkonna
sissetulek
kokku
(kuus)
Spearman's
rho
Kooliskäidud
aastate arv
Correlation
Coefficient
1,000 ,361(**)
Sig. (2-tailed)
. ,000
N
1643 1407
Leibkonna
sissetulek
kokku (kuus)
Correlation
Coefficient
,361(**) 1,000
Sig. (2-tailed)
,000 .
N
1407 1416
** Correlation is significant at the 0.01 level (2-tailed).
Seose kordaja on 0,36
Uuritud tunnuste vahel on keskmise tugevusega positiivne seos. Mida kauem on vastaja koolis käinud,
seda kõrgem on tema pere sissetulek ja vastupidi.
Seost saab üldistada üldkogumile, olulisusnivool 0,01
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -22-
F.
Vähemalt üks
tunnustest on
järjestustunnus
Meie riigis ei
ole piisavalt
toetusi, et
aidata inimesi,
kes tegelikult
puudust
kannatavad.
Sissetulek
Tabel 19.
Leibkonna
sissetulek
kokku
(kuus)
Meie
riigis ei
ole
piisavalt
toetusi, ...
Spearman's
rho
Leibkonna
sissetulek
kokku (kuus)
Correlation
Coefficient
1,000 ,118(**)
Sig. (2-tailed)
. ,000
N
1416 1350
Meie riigis ei
ole piisavalt
toetusi, ...
Correlation
Coefficient
,118(**) 1,000
Sig. (2-tailed)
,000 .
N
1350 1570
** Correlation is significant at the 0.01 level (2-tailed).
Seose kordaja on 0,12
Uuritud tunnuste vahel on väga nõrk positiivne seos.
Mida kõrgem on vastaja sissetulek, seda vähem ta selle
väitega nõus on. Mida madalam on vastaja sissetulek, seda
rohkem ta on nõus, et meie riigis ei ole piisavalattoetusi, et
aidata neid, kes tegelikult puudust kannatavad.
Seost saab üldistada üldkogumile, olulisusnivool 0,01
G.
Vähemalt üks
tunnustest on
nominaalne
Sugu
Sissetulek
Tabel 20.
0-3799
3800-4599
4600-6499 ...
24200
ja
enam Total
sugu Mees Count
28 30 38 ... 98 587
% 4,8% 5,1% 6,5% ... 16,7% 100,0%
Naine Count
38 86 117 ... 75 829
% 4,6% 10,4% 14,1% ... 9,0% 100,0%
Total Count
66 116 155 ... 173 1416
% 4,7% 8,2% 10,9% ... 12,2% 100,0%
Tabel 21.
Value
Nominal by Interval Eta sugu Dependent
,186
Leibkonna sissetulek
kokku (kuus) Dependent
,143
8.2. Vasta küsimustele:
Milline korrelatsioonikordaja annab numbriliste tunnuste korral (kui erandlikud väärtused puuduvad)
kõige tugevama seose?
Milline kordaja annab järjestustunnuste korral kõige tugevama seose?
Mida tahendab negatiivne kordaja?
Too näide tunnustest, mille korral ei saa arvutadaPearsoni ega Spearmani korrelatsioonikordajat.
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -23-
8.3. Enam kui kahe tunnuse vahelise seose uurimine
Lisaks kahe tunnuse uurimisele on võimalik leida korrelatsioonimaatriksit ka kolme ja enama tunnuse
jaoks. Sellisel juhul tuuakse tabelist valja kõige tugevamad seosed (ei uurita kõikide tunnuste seoseid
omavahel).
9. Reliaablus
Uurimuseks koostatud küsimustik sai hea tagasiside.Lisaks toetab seda ka asjaolu, et enamuste
alaskaalade sisemist reliaablust kinnitav Cronbach’i αoli ümardatult 0,80 – mis on üldtunnustatud
piirväärtuseks sotsiaalteadustes (www.pare.ee).
Sisemist reliaablustväljendab Cronbach'i α
(tulemust peetakse rahuldavaks kui α> 0.7 ja heaks kui α> 0.8).
Näide. Alapunktis 8.3 toodud küsimuste vastuste reliaablus
Case Processing Summary
1525 91,8
136 8,2
1661 100,0
Valid
Excluded
a
Total
Cases
N %
Listwise deletion based on all
variables in the procedure.
a.
Reliability Statistics
,768 5
Cronbach's
Alpha N of Items
ANDMEANALÜÜS: statistiline andmestik ja kirjeldav statistika. 2010/11 K.Osula -24-
15.02.14
Protsessi alusel
KVANTITATIIVNE UURING
– Kui palju? (probleemi kirjeldamine)
– Miks?(probleemi põhjuste tuvastamine )
– Tulemused üldistatakse üldkogumile,
mõnikord küsitav (või mittevajalik)
– Üldistamine tugineb arvulisele
argumendile
– Seoste uurimine (ei näita põhjuslikku
seost)
– Hüpoteeside testimine
– Eelneb mahukas planeerimisfaas
KVALITATIIVNE UURING
– Kuidas? (probleemi kirjeldamine)
– Milleks? (probleemi põhjuste tuvastamine)
– Tulemuste analüüs töömahukas
– Uuritavate hulk väike(üldistamine pigem
ennustamise, seaduspärasuste/trendide
väljatoomine)
– uuritakse tõlgendusi, hoiakuid ning
arvamusi (koos põhjendustega)
– Saab töötada välja efektiivseid lahendusi
konkreetsetele isikutele, mille laiemat mõju
saab hiljem uurida kvantitatiivsete
meetoditega
Kirjeldav statistika
Uuringutüüpe saab klassifitseerida
järgmiselt:
• Avastav
• Kirjeldav
• Analüütiline
• Ennustav
Eesmärgi
( purpose ) alusel
• Teoreetiline
• Empiiriline
• Rakenduslik
Uuringu
lähenemise
(approach) alusel
• Kvalitatiivne
• Kvantitatiivne
• Kombineeritud
Protsessi alusel
Kirjeldav statistika
Uuringu lähenemise põhjal
Kirjeldav statistika
Eesmärk Olemasoleva teabe/uuringute analüüs
Erinevate teooriate kriitiline analüüs (võrreldakse ühe eeliseid
teisega )
Autor peab näitama, milline on tema panus uute teadmiste otsingul,
kasutamisel , süstematiseerimisel ja hindamisel.
Näited Filosoofilised küsimused
Puhta matemaatika teoreemid
Ajaloolised uuringud
Arvutikasutuseeetika (loogiline arutelu ja seisukohad).
Tarkvara võrdlev analüüs
Referaat (?)
Seminaritöö kui referaat
(teoreetiliste uuringute KÕIGE välimisem kiht)
Teoreetiline uurimus
15.02.14
3
Kirjeldav statistika
Näited Personaalne arendusprojekt (või selle osa)
Õppematerjalide loomine
Probleemi analüüs (vajadused, eesmärgid, olemasolev teave)
Disaini protsess (tööjaotus, ajakava, meetodid)
Disaini protsessi resultaat ( rakenduse visandid, vaheversioonid,
lõplik rakendus )
Hindamine e. evalvatsioon (rakenduse testimine, hindamine lähtuvalt
standarditest, kasutajate tagasiside)
Rakenduslik uurimus
Kirjeldav statistika
§ Uurimisprobleem
– küsimus, hüpotees, eesmärk
§ Valikumeetod
– juhuslik valim, üks juhtum, mitu juhtumit
§ Andmekogumis meetod(id)
– struktureeritud ankeet, struktureerimata intervjuu , ...
§ Andmeanalüüsi meetodid
– statistilised meetodid, kodeerimine
§ Tulemused/järeldused
– kirjeldused, empiirilised üldistused, seaduspärasused,...
K.Niglas
Empiiriline uuring
Kirjeldav statistika
§ Igas uuringu põhiskeemis on teatud alametappidel vajalik rakendada
kõrvalolevatele uuringutüüpidele omaseid mõtlemis- või
tegutsemisviise.
– näiteks on hea arendusuuringu lahutamatuks osaks
• valdkonnaga seotud teooriate läbitöötamine
• empiirilise andmestiku kogumine
• ja analüüs vajaduste selgekstegemise
ja/või rakenduse testimise etapis
Uuringutüüpide omavaheline seotus
Kirjeldav statistika
§ Uurimisprobleem
– küsimus, hüpotees, eesmärk
§ Valikumeetod
– juhuslik valim, üks juhtum, mitu juhtumit
§ Andmekogumis meetod(id)
– struktureeritud ankeet, struktureerimata intervjuu, ...
§ Andmeanalüüsi meetodid
– statistilised meetodid, kodeerimine
§ Tulemused/järeldused
– kirjeldused, empiirilised üldistused, seaduspärasused,...
K.Niglas
Empiiriline uuring
Kirjeldav statistika
Andmekogumismeetodid
struktureeritud või
poolstruktureeritud
INTERVJUUD (küsitlused)
DOKUMENTEERIMINE
koondandmete talletamine
struktureerimata andmete
kodeerimine -
KONTENTANALÜÜS
psühholoogilisi ja sotsiaalseid
aspekte mõõtvad TESTID
(väärtushinnangute skaalad )
( standardiseeritud )
võimekus– ja sooritusTESTID
struktureeritud või
poolstruktureeritud
ANKEEDID (küsimusBkud)
VAATLUS
Kirjeldav statistika
§ Testib idee toimet reaalsetes tingimustes, kuid vähendatud
mahus .
– Küsimustiku uuringueelne kontrollimine
– Vähendab probleemide ja vigade tekkimist reaalse
andmekogumise käigus
– Vähe vastajaid
N: reklaamplakatid, loterii, soodushind
esmalt ühes kaupluses, reklaami väljapanek ühes geograafilises
piirkonnas
Nende põhjal tehakse omakorda järeldused täiendamisvajaduse
ning edasise rakendamise kohta kogu sihtturul.
Pilootuuring
15.02.14
4
Kirjeldav statistika
Küsimustik
§ Hea küsimustik on:
– selge sõnastusega,
– kergesti ja üheselt mõistetavate küsimustega,
– kompaktne ja kiiresti vastatav,
– vormistuselt korrektne ;
– koostatud nii, et oleks minimiseeritud vastajate ja andmete töötlejate
poolt potentsiaalselt tehtavate vigade hulk.
§ Hoiduda tuleks sellistest küsimustest nagu:
– suunavad küsimused;
– teaduslikult täpse, kuid pika ja keeruka sõnastusega küsimused;
– mitmeti mõistetavad küsimused;
– ärritavad küsimused (sh küsimusega mittesobivad vastusevariandid ).
Kirjeldav statistika
Küsimustik
§ Küsimuste/mõõdikute kavandamisel mõtle ja otsi infot järgneva
kohta:
– kas saab uuritavat nähtust mõõta otse või läbi indikaatori(te)?
– kas antud nähtust on eelnevates uuringutes mõõdetud ning kas vastav
kirjandus on usaldusväärne ?
– kas saab juba olemasolevaid mõõdikuid kohandada või tuleb välja
töötada uued mõõdikud/küsimused?
( pööra tähelepanu: kultuurilised ja kontekstuaalsed erinevused;
võrreldavus eelnevate uuringute tulemustega, jne)
– kas peaks kasutama piloteerimist ning järelkontrolli?
K.Niglas
Kirjeldav statistika
Üldine skeem
Sissejuhatavad, lihtsad küsimused
KONTAKTI LOOMINE
Küsimused teema kohta.
k.a. kontrollküsimused, provotseerivad
(spontaansuse suurendamiseks )
Kommentaaride lisamisvõimalus
Vähemalt lõpus!
Taustaküsimused
Ainult uuringu jaoks olulised!
Kirjeldav statistika
Millest sõltub andmeanalüüsimeetodi valik?
• Uurimisküsimus : laiem
• Analüüsiküsimus: nt. kas kaks gruppi on erinevad/seotud?
Küsimuse tüübist
• Nimitunnused
• Nimitunnuse väärtuseid ei saa järjestada, järjestustunnusel saab
• Järjestustunnused
• Arvtunnuse skaalavahemikud on võrdsed, järjestustunnusel mitte
• Arvtunnused
• Arvtunnuse korral saame arvutada keskväärtust, st.hälvet; binaarse tunnuse korral
mitte
• Binaarsed tunnused
Andmete tüübist (väärtuste järjestatavus, skaalavahemike võrdsus)
• Uurija teadmised/oskused
• Kellele esitab, kuidas?
Sihtrühmast
Kirjeldav statistika
Tunnuse tüübid
Nimitunnuse väärtuseid ei saa järjestada
Järjestustunnuste väärtuseid saab
järjestada
Skaalavahemikud ei ole võrdsed
Skaalavahemikud on võrdsed
Vähe erinevaid väärtuseid
Palju võimalikke väärtuseid
Kaks võimalikku väärtust
Järjestatavus ja skaalavahemike võrdsus ei
ole probleem
Arvestame
järjestatavust, skaalavahemike võrdsust
Nimitunnused
Järjestustunnused
Intervalltunnused
Binaarsed tunnused
Kirjeldav statistika
Eeltöö – andmestiku korrastamine
§ Puuduvad väärtused - kui palju neid on, mida teha tühjade
lahtritega?
§ Andmesisestusvead
§ Andmete grupeerimine (vajadusel)
§ Skaalade pööramine (vajadusel)
15.02.14
5
Kirjeldav statistika
Sugu
Kirjeldav statistika
Vanus
Kirjeldav statistika
Kool
Kirjeldav statistika
Õppevaldkond
Kirjeldav statistika
Tegevusala
Kirjeldav statistika
15.02.14
6
Kirjeldav statistika
Kuivõrd aitasid praeguse töökoha saamisele kaasa: omandatud (pea)eriala/erialad
Frequency Percent Valid Percent Cumulative Percent
Valid Nõustun täiesti 1016 46.5 62.3 62.3
Pigem nõustun 352 16.1 21.6 83.8
Pigem ei nõustu 146 6.7 8.9 92.8
Ei nõustu üldse 118 5.4 7.2 100.0
Total 1632 74.7 100.0
Missing System 554 25.3
Total 2186 100.0
Kirjeldav statistika
Andmeanalüüsi vahendid
Kirjeldav statistika
Andmeanalüüsi küsimus
KIRJELDAV
(esmane analüüs)
VÕRDLEV
(erinevused gruppide vahel)
KORRELATSIOON
(seosed tunnuste vahel)
KIRJELDAV
(esmane analüüs)
■ tekst
■ tabel
■ diagramm
Kirjeldav statistika
§ Eesmärk
– uuritava nähtuse süstemaatilinekirjeldamine protsentjaotuste ja
keskväärtuste kaudu, tabelite ja graafikute vormis.
§ Vaadeldakse vaid üksiktunnuseid
– Kõrvale jäetakse tunnuste omavahelised seosed.
Esmane analüüs
KIRJELDAV
(esmane analüüs)
VÕRDLEV
(erinevused gruppide vahel)
KORRELATSIOON
(seosed tunnuste vahel)
Kirjeldav statistika
Esmane ülevaade andmetest
„Kui suur osa õpilasi kasutab Facebooki iga päev?“,
„Kas ja kui palju leidub neid õpilasi, kes Facebooki üldse ei kasuta?“
„Mis on kõige tüüpilisem kasutussagedus ehk millise
vastusevariantidest on valinud kõige suurem osa õpilastest?“.
Kirjeldav statistika
Sagedustabel
§ Frequency - vastajate arv
§ Percent - osakaal
§ Valid percent - osakaal mittepuuduvatest väärtustest
§ Cumulative percent - kumulatiivne protsent
vanuse_grupid
43 4,9 5,0 5,0
147 16,7 17,0 21,9
174 19,7 20,1 42,0
162 18,4 18,7 60,7
160 18,1 18,5 79,1
181 20,5 20,9 100,0
867 98,3 100,0
15 1,7
882 100,0
kuni 20
21-30
31-40
41-50
51-60
üle 61
Total
Valid
System Missing
Total
Frequency Percent Valid Percent
Cumulative
Percent
15.02.14
7
Kirjeldav statistika
Sagedustabel
Kirjeldav statistika
Tabeli (ridade) järjestamine
§ Internetikasutuse osakaalud 2008.aastal erinevates riikides
6.-17. aastaste laste seas.
§ Juhul kui tabelis
toodud kategooriad
ei olesisuliselt
tähenduslikus
järjekorras, siis
järjestatakse tabeli read sageduste/osakaalude järgi (Tabel 2B).
Kirjeldav statistika
Järelduse koostamine
§ Tabeli 10. põhjal näeme, et 15 vastajat (38,5%) hindas
ettevalmistust ebapiisavaks; 9 vastajat (23,1%) enam-vähem
piisavaks ning 15 vastajat (38,5%) täiesti piisavaks.
Kirjeldav statistika
Järeldustes...
§ Ei tohi liialdada ebamääraste väljenditega
• Enamasti
• Sageli
• Suuremas osas
• Harva
• Mõnikord
• Kohati.
Need tekitavad küsimusi , kui sageli, kui harva, mis tingimustel jne.
§ Paremad on täpsemad väljendid
• alla poole (46%)
• ligi kolmandikul juhtudest
• peaaegu kolmveerand näidetest jne.
Kirjeldav statistika
§ Üldine reegel TEKSTI SEES
TOODUD
ARVUDENA
TABELINA
ARVJOONISE e
DIAGRAMMINA
Vali arvulise info
edastusviisiks tekst,
kui korraga on vaja
esitada vaid üks-kaks
arvulist näitajat
Vali esitluseks tabel,
kui on vajalik anda edasi
täpset arvulist infot või
kui võrreldavate
arvnäitajate
suurusjärgud on väga
erinevad
Vali esitluseks diagramm,
kui soovid eelkõige anda
kiiret ülevaadet
üldtendentsi(de)st ja
suundumus(te)st
Esitlusviis peaks toetama
parimal viisil tulemuste
sisust kiiret ja õiget
arusaamist ning olema
kompaktne.
Statistiliste andmete esitamine
Kirjeldav statistika
TNS Emori läbiviidud heategevusliku käitumise
uuringu tulemused.
Milline nendest on parem viis
andmete esitamiseks suulises
eZekandes ja uurimistöö
kirjalikus raporBs.
15.02.14
8
Kirjeldav statistika
Andmete esitamine - tekstina
§ Vastajaid vähem kui 100
– 23.03.09 toimunud kirjeldava statistika osa eksamil osales 39 üliõpilast.
– Eksamil osalenud 39-st üliõpilasest ligi kolmandik (15) oli osalenud
kõikides loengutes; kõikides praktikumides osalemise vastav arv oli 10.
§ Soovi korral võib ülevaatlikkuse tõstmiseks sagedusele sulgudes
lisada osakaalu
– Uuringus osales 17 inimest, kellest 4 (23%) olid teinud rahalisi annetusi
eelmise aasta jooksul.
§ Vastajaid rohkem kui 100
– Seisuga30 aprill2007 on 1.6% vanemahüvitise saajatest mehed.
Kirjeldav statistika
Tulpdiagramm
Tulba kõrgus näitab vastajate
arvu või protsenB
* Võrdleb erinevaid kategooriaid
* Pika teksB korral teljed ära
vahetada
* Tulbad võiks paigutada suuruse
järjekorda (kui ei ole sisulist
järjestust)
Kirjeldav statistika
Keda sooviksite näha järgmise
peaministrina?
Turu-uuringute AS küsitles 16-17.02
telefoni teel 305 valimisõiguslikku EesB
elanikku.
Küsitluse valim on representaBivne ning
üldistatav valimisõiguslike EesB elanike
suhtes.
Kirjeldav statistika
Joondiagramm
Ajas muutuvate andmete kirjeldamine
Õppijaid haridusastmete järgi, 1996-2004
(aasta alguses, tuhat )
0
10
20
30
40
50
60
70
80
1996 1997 1998 1999 2000 2001 2002 2003 2004
Kõrgharidus
Üldkeskharidus
(gümnaasiumiklassid)
Kutseharidus
tuhat
Kirjeldav statistika
Tulpdiagramm ≠Histogramm
Kirjeldav statistika
Kirjeldavad arvnäitajad
Keskmine tase
Mood
Mediaan
Aritmeetiline keskmine
Geomeetriline keskmine
Harmooniline keskmine
Ruutkeskmine
Kaalutud keskmine
Hajuvus
Ulatus
Kvartiilid
Protsentiilid
Dispersioon
Standardhälve
Jaotuse kuju
Asümmeetria
Ekstsess
15.02.14
9
Kirjeldav statistika
Aritmeetiline keskmine e keskväärtus
§ ...võimaldab suurt hulka numbrilisi andmeid koondada ja välja tuua
üldtendentse.
§ Puuduseks tundlikkus äärmuslike väärtustesuhtes,kasutatakse eelkõige
väikese hajuvuse korral keskväärtuse suhtes.
§ Nt keskmine vanus 44 ei ütle midagi selle kohta, kuipalju on alla 20-aastaseid.
§ Mood ja mediaan – muutuvad siis, kui esineb olulisi muutusi andmetes
§ Aritmeetiline keskmine– muutub siis, kui muutub kasvõi üks rea liige
§ Keskväärtus on võrreldes teiste näitajatega kõige stabiilsem
§ Kõigile teada tuntud arvnäitaja (kõik teavad ja oskavad arvutada)
Kirjeldav statistika
Ulatus e haar (Range)
§ ... maksimaalse ja minimaalse väärtuse vahe e. vahemiku laius, milles
andmed paiknevad
§ Milliste maakondade tulemused
hajuvad kõige rohkem?
+ lihtsamini leitav
- sõltub äärmistest väärtustest,
mis võivad olla ekstreemsed!!
100 10 90
95 15 80
100 10 90
100 10 90
100 10 90
100 10 90
100 15 85
100 10 90
100 10 90
95 15 80
95 10 85
100 0 100
100 15 85
100 10 90
100 0 100
Harjumaa
Hiiumaa
Ida-Viru
Jõgevama
Järvamaa
Lääne-Vi
Läänemaa
Põlvamaa
Pärnumaa
Raplamaa
Saaremaa
Tartumaa
Valgamaa
Viljandi
Võrumaa
Maximum Minimum Range
Kirjeldav statistika
Kvartiilid
§ Kvartiilid jagavad variatsioonirea nelja võrdsesse ossa
Kirjeldav statistika
Karpdiagramm
Alumine kvarBil
Ülemine kvarBil
Mediaan
Kõige väiksem väärtus
Kõige suurem väärtus
25% andmetest
50% andmetest
25% andmetest
Kirjeldav statistika
Standardhälve
§ Kui palju üksikud tulemused erinevad keskmisest?
Kui andmed on ühesugused => st.hälve=0
Mida rohkem nad erinevad => suurem on st.hälve
21,86
17,81
22,05
21,10
18,49
18,81
19,58
19,74
20,05
17,61
18,38
22,27
20,41
20,40
21,19
Harjumaa
Hiiumaa
Ida-Viru
Jõgevama
Järvamaa
Lääne-Vi
Läänemaa
Põlvamaa
Pärnumaa
Raplamaa
Saaremaa
Tartumaa
Valgamaa
Viljandi
Võrumaa
Std Deviation
100 10 90
95 15 80
100 10 90
100 10 90
100 10 90
100 10 90
100 15 85
100 10 90
100 10 90
95 15 80
95 10 85
100 0 100
100 15 85
100 10 90
100 0 100
Harjumaa
Hiiumaa
Ida-Viru
Jõgevama
Järvamaa
Lääne-Vi
Läänemaa
Põlvamaa
Pärnumaa
Raplamaa
Saaremaa
Tartumaa
Valgamaa
Viljandi
Võrumaa
Maximum Minimum Range
Kirjeldav statistika
Standardhälve
1 2 3 4 5
5
4
3
2
1
0
1 2 3 4 5
5
4
3
2
1
0
1.õppejõud
M=2,6
SD=0,55
2.õppejõud
M=2,6
SD=1,82
15.02.14
10
Kirjeldav statistika
asümmeetria
§ Jaotus on väljavenitatud paremalt poolt
§ Jaotuse “saba” on paremal pool
§ Skaalal väiksemaid väärtuseid rohkem
• PosiBivne asümmeetria (skewness)
1900 1910 1920 1930 1940 1950 1960
Kirjeldav statistika
asümmeetria
§ Jaotus on väljavenitatud vasakult poolt
§ Jaotuse “saba” on vasakul poolt
§ Skaalal suuremaid väärtuseid rohkem
• NegaBivne asümmeetria (skewness)
1950 1960 1970 1980 1990 2000 2010
Kirjeldav statistika
Tulemuste esitamine
§ Uurimuses osalejate kommunikatsiooniga rahulolu määra
hindamiseks arvutati välja üldise kommunikatsiooniga rahulolu
keskmine näitaja M=4,82 (SD=0,94), mida suurem on saadud
tulemus, seda kõrgem on rahulolu tase (1 – väga rahulolematu, 7 –
väga rahul). Keskmise põhjal võib väita, et uuringus osalenud
inimesed on oma organisatsioonide kommunikatsiooniga keskmisest
rahulolevamad.
§ .
Kirjeldav statistika
Andmeanalüüsi küsimus
KIRJELDAV
(esmane analüüs)
VÕRDLEV
(erinevused gruppide vahel)
KORRELATSIOON
(seosed tunnuste vahel)
KIRJELDAV
(esmane analüüs)
VÕRDLEV
(erinevused gruppide vahel)
■ tekst
■ tabel
■ diagramm
■ tekst
■ tabel
■ diagramm
■ keskväärtuste kaudu
■ proportsioonide
kaudu
Kirjeldav statistika
Erinevuste uurimine
§ Keskväärtuste arvutamise kaudu
§ Milline on vastajate keskmine sissetulek? Kas mehed või naised
teenivad keskmiselt rohkem?
§ Kuidas sõltub sissetuleku suurus omandatud haridustasemest?
§ ...
Kirjeldav statistika
Erinevuste uurimine
§ Keskväärtustekaudu
15.02.14
11
Kirjeldav statistika
Erinevuste uurimine
§ Tunnused: nimitunnus, binaarne tunnus, järjestustunnus
§ Millise haridustasemega vastajate seas on enam lahutatud isikuid?
• Kui keskväärtust arvutada ei saa
Kirjeldav statistika
Erinevuste uurimine
§ Millise haridustasemega vastajate
seas on enam lahutatud isikuid?
§ võrdlev sagedustabel e RISTTABEL
• Kui keskväärtust arvutada ei saa
Kirjeldav statistika
Andmeanalüüsi küsimus
KIRJELDAV
(esmane analüüs)
VÕRDLEV
(erinevused gruppide vahel)
KORRELATSIOON
(seosed tunnuste vahel)
KIRJELDAV
(esmane analüüs)
VÕRDLEV
(erinevused gruppide vahel)
■ tekst
■ tabel
■ diagramm
■ tekst
■ tabel
■ diagramm
■ keskväärtuste kaudu
■ proportsioonide
kaudu
KORRELATSIOON
(seosed tunnuste vahel)
■ tekst
■ tabel
■ diagramm
Kirjeldav statistika
Korrelatsioonanalüüs
Seose analüütiline hindamine
Seose visuaalne hindamine
Kirjeldav statistika
Korrelatsioonikordajad
§ Pearson’s r
§ Standardiseeritud kahe tunnuse vahelise
seose kordaja
§ Pearsoni kordaja puudused
– lineaarne seos: tunneb punktipilve, mis
on venitatud piki sirget.
– tundlik erandite suhtes: paar üksikut
erandit väikeses valimis võivad
kahekordistada kordaja väärtust.
Kirjeldav statistika
KORRELATSIOONANALÜÜS
§ Kuidas on seotud vanus ja majapidamistöödeks kuluv aeg?
Correlations
1 ,198**
, ,000
882 873
,198** 1
,000 ,
873 873
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
vanus
Tunde
majapidamistöödeks
(tööpäeviti)
vanus
Tunde
majapidami
stöödeks
(tööpäeviti)
Correlation is significant at the 0.01 level (2-tailed). **.
15.02.14
12
Kirjeldav statistika
Korrelatsioonikordajad
§ Spearman’s ρ
§ MPAR korrelatsioonikordaja
§ Astakkorrelatsioonikordaja
– intervalltunnused ei vasta
normaaljaotusele
(ka erandlikud väärtused)
– Järjestustunnus(ed)
– asendab väärtused järjekorra-numbritega ning kasutab Pearsoni
kordaja valemit =>
Spearmani kordaja kordaja (üldjuhul)
Kirjeldav statistika
korrelatsioonanalüüs
§ Spearmani kordaja
Correlations
1,000 -,357**
, ,000
829 821
-,357** 1,000
,000 ,
821 873
Correlation Coefficient
Sig. (2-tailed)
N
Correlation Coefficient
Sig. (2-tailed)
N
sissetulek viimasel kuul
Tunde
majapidamistöödeks
(tööpäeviti)
Spearman's rho
sissetulek
viimasel kuul
Tunde
majapidami
stöödeks
(tööpäeviti)
Correlation is significant at the .01 level (2-tailed). **.
Kirjeldav statistika
Korrelatsioonikordajad
§ Kendall’s τ
§ MPAR korrelatsioonikordaja
§ Astakkorrelatsioonikordaja
– kui on vähe andmeid ja palju
sarnaseid väärtuseid
Kirjeldav statistika
Korrelatsioonikordajad
§ Cramer ’s V
– Nimitunnuste seose
tugevuse uurimiseks.
– Kordaja ei näita
seose suunda,
ainult tugevust.
N: Eriala ja tööl käimise
seos V=,45
§ Phi
– 2x2 binaarsete tunnuste korral
– Ruutjuur hii-ruudu väärtuse jagatisest valimi suurusega
Kirjeldav statistika
Milline kordaja valida?
KORDAJA ANDMED LISATINGIMUS
PEARSON I + I Seose kuju – lineaarne
Erandlikud väärtused puuduvad (ei domineeri )
SPEARMAN I + I, I + J, J + J Seose kuju ei ole lineaarne ja jaotusel on
erandlikud väärtused (I + I)
KENDALL J + J Väike valim ja palju sarnaseid väärtuseid
CRAMER I + N, I + B, N + B,
N + N, N + J, B + J
Tõlgendatakse vaid seose tugevust, miZe
suunda
PHI B + B Tõlgendatakse vaid seose tugevust, miZe
suunda
Kirjeldav statistika
Tulemuste esitamine
§ Tajutud stressi taseme ja enesetõhususe vahelise suhte analüüsil
ilmnes oluline negatiivne korrelatsioon, mille kohaselt madalama
enesetõhususega õpetajad tajusid stressi kõrgemalt (r=-.37, p=.
010).
§ Laste väliskeskkonna mängu ja vanemate soovide vahel ilmnes
tugev negatiivne seos (r=-0,713; p=0,05), mille põhjal võib väita, et
vanemate soov oma lapsi näha teatud tegevustes ja olemuses
erineb sellest (ootused on lapse mängulisusele on kõrgemad),
millised on lapsed väljas mängides tegelikult. Tunnuse väärtuste järjestamine
Tee tunnuse nime peal hiire parem klõps ning vali:
Sort Ascending: kasvavas järjekorras järjestamiseks (1, 2, 3, 4, ... jne)
Sort Descending: kahanevas järjekorras järjestamiseks (9, 8, 7, 6, ... jne)
Enamlevinumad andme- ja failiteisendused 2012
2. Tekstitunnuse muutmine numbriliseks
Tunnuse Sugu väärtused olid Exceli andmestikus esitatud sõnadena (mitte kodeeritult). Andmestiku SPSS-i
ületoomisel loodi tekstitüüpi ( String ) tunnus. See saada takistuseks edasise andmeanalüüsi tegemisel,
seega teisendame tekstitüüpi (String) tunnuse numbriliseks (Numeric) tunnuseks.
Vali Transform/Automatic Recode
Vali tunnus sugu ning vii see
Variable lahtrisse.
Kuna teisenduse käigus
luuakse uus tunnus, siis on
vaja sellele panna nimi.
Sisesta loodava tunnuse nimi
lahtrisse New Name ning
klõpsa Add New Name nupul.
Muuta on veel võimalik seda,
kas kodeerimist alustatakse
kasvavas järjestuses (Lowest
value) või kahanevas
järjestuses ( Highest value).
Koodide määramisel on
aluseks vastusevariantide
tähestikuline järjestus.
Kasvav järjestus (Lowest
value) on näiteks selline:
Mees - 1
Naine - 2
Teisenduse tulemusena loodi SPSS-i tabelisse (kõige lõppu) uus tunnus sugu1:
Enamlevinumad andme- ja failiteisendused 2012
3. Arvutamine
Arvutame vastajate sissetuleku, liites kokku palga ja lisatasu
Vali Transform/Compute
Arvutuse tulemusena loodi SPSS-i tabelisse (kõige lõppu) uus tunnus sissetulek:
Sisesta Target Variable lahtrisse uue
loodava) tunnuse nimi (ilma tühikuteta).
Numeric Expression lahtrisse too (ära kirjuta
tunnuse nimesid , lohista hiirega või kasuta
noole klahvi) tunnused, nende vahele sisesta
+ märk.
Enamlevinumad andme- ja failiteisendused 2012
4. Tunnuse väärtuste jagamine gruppidesse
Jagame loodud tunnuse sissetulek väärtuse vahemikesse.
Vali Transform/Visual Binning
Vali tunnus sissetulek ja vii see
Variables to Bin väljale.
Jätkamiseks klõpsa nupul Continue
Vahemike loomiseks klõpsa Make Cutpoints nupul.
Sisestame loodavate
vahemike laiuse Width väljale
ning esimese vahemiku
lõpppunkti asukoha First
Cutpoint Location lahtrisse.
Klõpsa kursor kolmandasse,
veel tühja lahtrisse (Number
of Cutpoints), mille sisu täidab
programm automaatselt.
Sisesta Binned Variable lahtrisse uue
loodava) tunnuse nimi (ilma tühikuteta).
Andmesiltide loomiseks klõpsa Make Labels
nupul. Andmesildid luuakse automaatselt
vastavalt eelnevalt määratud intervalli
laiusele.
Enamlevinumad andme- ja failiteisendused 2012
Vahemikeks jagamise tulemusena loodi SPSS-i tabelisse (kõige lõppu) uus tunnus sissetulek1:
5. Väärtuste selekteerimine
Oletame, et me soovime uurida mingis analüüsi osas ainult neid, kellel on 1 laps.
Seega me soovime, et meie andmetabelis oleks vaid need vastajad, kellel on 1 laps.
Vali Data/ Select Cases
Kasutame
selekteerimiseks If
tingimust.
Need väärtused, mis peaksid andmetabelisse jääma, kirjeldame ära tingimuses: lastearv=1
Selekteerimise tulemusena kasutatakse edaspidi analüüsis vaid neid vastajaid, kellel on 1 laps. Teistele
objektidele tõmmati „joon peale“ ning nende vastused analüüsis ei sisaldu.
Enamlevinumad andme- ja failiteisendused 2012
Kõikide andmete analüüsimiseks e selekteeringu eemaldamiseks kustuta andmetabelist tunnus filter_$
6. Andmestiku jagamine osadeks.
Oletame, et me soovime tellida analüüsi erinevate andmegruppide kohta (nt. meeste ja naiste jaoks eraldi).
Selleks tuleb järgida skeemi:
* jagame andmestiku osadeks (Split File)
Vali Data/Split File
Vali Compare groups või
Organize output by groups. Vt.
erinevust lehe alumises osas
paiknevas tabelis.
Vii tunnus, mille põhjal
andmestik osadeks jagatakse,
väljale Groups Based on
väljale.
* tellime vajaliku analüüsi (sagedustabeli, diagrammi vms)
* eemaldame gruppideks jagamise (Split File) Analyze all cases, do not create groups
ERINEVATE KATEGOORIATE/TUNNUSTE VÕRDLEMINE
Gruppide võrdlemine juhul kui KESKVÄÄRTUST SAAB ARVUTADA.
Uuritav tunnus: intervalltunnus (arvud, Likerti skaala)
Näide 1. Võrdleme meeste naiste hinnanguid järgmistes küsimustes:
o2 Tähtis olla rikas, omada raha ja kalleid asju
o5 Tähtis elada turvalises ümbruskonnas
o12 Tähtis aidata inimesi ja hoolitseda nende heaolu eest
o13 Tähtis olla edukas
A. Analyze/Compare Means /Means...
Mees Naine
N M SD N M SD
Tähtis olla rikas, omada raha ja kalleid asju 2348 3,73 1,402 3164 4,04 1,405
Tähtis elada turvalises ümbruskonnas 2352 2,48 1,215 3164 2,09 1,103
Tähtis aidata inimesi ja hoolitseda nende heaolu eest 2342 2,61 1,008 3154 2,32 ,979
Tähtis olla edukas 2348 2,97 1,301 3152 3,18 1,381
* Tabeli ridade veergude vahetamiseks märgista tabel ning vali Pivot/Transpose Rows and Columns
B. Graps/Legacy Dialogs/Bar...
Simple/Summaries of Separate Variables Clustered/Summaries of Separate Variables
Ülesanne 1. Võrrelge kolme riigi keskmiseid hinnanguid rahulolu eri aspektidele. Tõlgendage saadud tulemust.
y4 Üldine rahulolu eluga
y5 Üldine rahulolu riigi majandusliku olukorraga
y6 Üldine rahulolu valitsuse tööga
y8 Üldine rahulolu hariduse olukorraga riigis
y9 Üldine rahulolu tervishoiusüsteemiga riigis
Ülesanne 2. Kas võime väita, et mida kõrgem on vastaja igakuine (leibkonna) sissetulek, seda olulisem on tema jaoks
olla rikas, omada raha ja kalleid asju?
Ülesanne 3. Võrrelge vabalt valitud gruppide vastuseid järgmistes küsimustes:
o7 Tähtis teha seda, mida on räägitud ja järgida reegleid
o9 Tähtis olla alandlik ja tagasihoidlik
o16 Tähtis käituda korralikult
o18 Tähtis olla ustav ja pühendunud lähedastele
o20 Oluline järgida traditsioone ja kombeid
Esmane
analüüs
Gruppide
vahelised
erinevused
Korrelatsioon
analüüs
Gruppide võrdlemine juhul kui KESKVÄÄRTUST ARVUTADA EI SAA.
Uuritav tunnus: nimitunnus, binaarne tunnus, järjestustunnus
Näide 2. Millises riigis on kõige rohkem vastajaid, keda nende enda arvates diskrimineeritakse?
Kas Te enda arvates kuulute mõnda gruppi, mida siin riigis
diskrimineeritakse? (Jah, Ei)
A. Analyze/Descriptive Statistics/Crosstabs...
Cells/Percentages (grupeeriva tunnuse protsendid)
Näites võrdleme eri riikide vastajaid, seega valime protsendid nii,
et iga riigi vastajad moodustaksid kokku 100% e rea protsendid.
B. Analyze/Graphs/Legacy Dialogs/Bar...
Clustered/Summaries for groups of cases
% of cases
Kuna võrreldavate gruppide
suurused ei ole võrdsed,
võrdleme gruppide
protsentuaalseid jaotuseid (nagu
risttabelis).
Category Axis - uuritav tunnus
Define Clusters by – tunnus,
mille gruppe me võrdleme
Näide 3. Võrdleme usuga seotud teenistustel käimise sagedust tegevuste lõikes.
u6 Kõrvale jättes erilised sündmused nagu näiteks laulatused ja matused, kui tihti käite käesoleval ajal usuga seotud teenistustel?
Ülesanne 4. Andke ülevaade küsimuse „Kui tihti, kui üldse, võtate osa usuga seotud rituaalidest või palvetate?“
vastustest. Võrrelge vastuseid erinevate gruppide lõikes (sugu, haridus jne.).
Ülesanne 5. Kuivõrd on Eesti, Läti ja Soome vastajate sissetulekute jaotused erinevad?
Näide 4. Millisel põhjusel on kõige enam vastajaid diskrimineeritud?
u10 Diskrimineerimise põhjus: nahavärv
u13 Diskrimineerimise põhjus: religioon
u16 Diskrimineerimise põhjus: vanus
u17 Diskrimineerimise põhjus: sugu
u18 Diskrimineerimise põhjus: seksuaalne orientatsioon
Analyze/Graphs/Legacy Dialogs/Bar...
Simple/Summaries of Separate Variables
KORDAMISÜLESANDED – GRUPPIDE VÕRDLEMINE
Andmeanalüüsi ülesanne: anda ülevaade meeste-naiste jaotumisest rahvuste lõikes.
Teie ülesanded:
a) leida igast seeriast (risttabelid, võrdlevad tulpdiagrammid, kihtdiagrammid, sektordiagrammid)
statistiliselt/sisuliselt korrektne tulem, mis vastab püstitatud andmeanalüüsi küsimusele.
b) Otsustada, milline valitud õigetest tulemitest on parim antud tulemuste esitamiseks
SEERIA 1. Risttabelid
Tabel 1.
Rahvus
Total Eestlane Venelane Muu
Sugu Mees Count 462 197 39 698
% of Total 30,7% 13,1% 2,6% 46,3%
Naine Count 528 246 35 809
% of Total 35,0% 16,3% 2,3% 53,7%
Total Count 990 443 74 1507
% of Total 65,7% 29,4% 4,9% 100,0%
Tabel 2.
Rahvus
Total Eestlane Venelane Muu
Sugu Mees Count 462 197 39 698
% within Sugu 66,2% 28,2% 5,6% 100,0%
Naine Count 528 246 35 809
% within Sugu 65,3% 30,4% 4,3% 100,0%
Total Count 990 443 74 1507
% within Sugu 65,7% 29,4% 4,9% 100,0%
Tabel 3.
Rahvus
Total Eestlane Venelane Muu
Sugu Mees Count 462 197 39 698
% within Rahvus 46,7% 44,5% 52,7% 46,3%
Naine Count 528 246 35 809
% within Rahvus 53,3% 55,5% 47,3% 53,7%
Total Count 990 443 74 1507
% within Rahvus 100,0% 100,0% 100,0% 100,0%
SEERIA 2. Võrdlevad tulpdiagrammid
Joonis 1.
Joonis 2.
Joonis 3.
SEERIA 3. Kihtdiagrammid
Joonis 4. HISTOGRAMM
Histogramm sobib arvtunnuse (millel on palju erinevaid väärtuseid) väärtuste kokkuvõtmiseks/esitamiseks.
Kui tulpdiagrammi puhul esitatakse ühes tulbas ühe kategooria väärtused, siis histogrammi ühte tulpa
koondatakse kokku teatavas vahemikus esinevad väärtused.
Joonis 1. Tulpdiagramm vastajate vanuselisest jaotusest. Iga tulp esitab vastava vanusega vastajate
esinemissagedust.
Joonis 2. Histogramm eelpool toodud vastajate vanuselisest jaotusest. Vanused on koondatud gruppidesse
ning iga tulp kirjeldab vastava vahemiku esinemissagedust.
Ebaõnnestunud histogrammid.
0
2
4
6
8
10
12
14
16
18
19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
0
10
20
30
40
50
60
…-20 21-25 26-30 31-35 36-40 41-45 46-50
1. Sektordiagramm
Sektordiagramm sobib niisuguste andmete
esitamiseks, mille väärtused moodustavad
kokku terviku e 100%.
Iga sektor näitab vastava kategooria osa
tervikust.
www.aripaev.ee
1.1. Üldised kujundamisreeglid:
Kokku võiks sektordiagramm koosneda 7-9 sektorist. Kindlasti mitte koostada diagrammi juhul kui
tunnusel on 1 või 2 kategooriat.
Ühe sektori eemaldamisega (välja tõstmisega) rõhutame seda kategooriat/ sektorit . Kõiki sektoreid välja
tõsta ei ole otstarbekas.
Sektorid võib järjestada kahanevasse järjekorda, kui tunnuse väärtused ei ole sisulises järjekorras
(järjestustunnus või intervalltunnus).
3D kujundid on küll vahvad, kuid võivad moonutada tulemust ( eespool olevad sektorid paistavad
suuremad, teised väiksemad).
Sektordiagrammi koostamise ja kujundamise juhend 2012
1.2. Ebaõnnestunud sektordiagrammid
2. Sektordiagrammi koostamine
1. Koostame sektordiagrammi tunnuse haridustase vastustest.
Valime Graphs/Legacy Dialogs/Pie...
Vali tunnus Haridustase ja vii
see Define Slices by: väljale.
NB! Järjestustunnusest koostatud sektordiagrammi kujundamisel ei tohi sektoreid suuruse järgi järjekorda
seada, kuna tunnuse väärtustel on sisuline järjestus olemas.
2. Koostame sektordiagrammi tunnuse perekonnaseis vastustest.
Valime Graphs/Legacy Dialogs/Pie...
NB! Nimitunnusest koostatud sektordiagrammi kujundamisel võib parema
ülevaate saamiseks sektorid suuruse järgi järjekorda seada.
18%
10%
10%
15%
10%
16%
10%
11%
26,39%
73,61%
mees
naine
sugu
JÄRJESTUS-TUNNUS
NIMITUNNUS
Sektordiagrammi koostamise ja kujundamise juhend 2012
3. Koostame sektordiagrammi tunnuse sugu vastustest.
Valime Graphs/Legacy Dialogs/Pie...
NB! Binaarsel tunnuse on kaks
võimalikku väärtust, seega ei sobi
nende esitamiseks sektordiagramm, sest
esitatavat infot on liiga vähe. Parem viis nende andmete esitamiseks on tekst.
4. Koostame sektordiagrammi tunnuse vanus vastustest.
NB! Kui tunnusel on rohkem
kui 9 erinevat
väärtust/kategooriat, siis selle
tunnuse väärtustest ülevaate
andmiseks sektordiagramm ei sobi. Parem on
koostada histogramm.
NB! Kui intervalltunnusel on vähe (maksimaalselt 9) erinevaid väärtuseid, siis sektordiagramm sobib
andmetest ülevaate andmiseks.
Sektorite järjekorda seadmine ei ole lubatud kuna tunnuse väärtustel on sisuline järjestus olemas.
Lisavõimalus (Panel by...) eraldi sektordiagrammide koostamiseks valitud kategooriate kohta
(Alates versioonist 14.0)
Panel by pakub lisavõimalusi valitud tunnuse kategooriate kohta sektordiagrammi koostamiseks. Kui me
näiteks paneme tunnuse „sugu“...
...Rows väljale, saame me kaks erinevat
sektordiagrammi, ühe meeste ja teise naiste vastuste
kohta. Loodavad diagrammid paigutatakse üksteise alla
(ridadesse).
... Columns väljale, saame me taaskord kaks
sektordiagrammi, mis on paigutatud üksteise kõrvale
(veergudesse).
BINAARNE
TUNNUS
INTERVALLTUNNUS,
MILLEL ON PALJU
ERINEVAID
ARVVÄÄRTUSEID
Sektordiagrammi koostamise ja kujundamise juhend 2012
3. Sektordiagrammi kujundamine
Tulemus kuvatakse tulemuste (Output) faili.
Tulemi kujundamiseks tee diagrammil topeltklõps ning rakenda soovitud muudatusi Chart Editor aknas .
3.1. Andmesiltide lisamine
Märgista sektorid
Tee paremklõps sektorite peal ning vali loendist Show
Data Labels
Koos andmesiltidega muutus ka Properties akna sisu, sinna ilmus vaheleht Data Value Labels
Displayed väljale vii need sildid, mida soovid diagrammil kuvada.
Hetkel on sektoritel kuvatud vastava kategooria osakaal
protsentides ning kategooria nimetus.
Kui kõik andmesildid ära ei mahu (tekst liiga pikk või sektoreid
liiga palju), kuvab SPSS ainult need, mis ära mahuvad. Kõikide
andmesiltide kuvamiseks: Suppress overlapping labels
Sektordiagrammi koostamise ja kujundamise juhend 2012
Andmesiltidel esitatava teksti suuruse muutmiseks vali andmesildid, ava Properties aknas
Text Style vaheleht ning määra soovitud kirja suurus ( Preferred Size).
Andmesiltidel esitatud numbrite komakohtade
muutmiseks vali andmesiltidel esitatud numbrid või
protsendid, ava Properties aknas Number Format
vaheleht ning muuda kuvatavate komakohtade arv
(Decimal Places ).
3.2. Ühe sektori eemaldamine (välja tõstmine)
Märgista üks sektor. Selleks klõpsa ühe sektori peal kaks korda
(väikese vahepausiga) e tee „aeglane topeltklõps“.
Sektori eemaldamiseks tee sellel paremklõps ning vali valikust
Explode Slice
Võid kasutada ka nupureal olevat nuppu:
Sektori tagasiviimiseks vali Return Slice
3.3. Sektorite kokkuliitmine
Koostame sektordiagrammi tunnuse leibkonna suurus tulemuste illustreerimiseks.
Koostatud sektordiagrammist näeme, et tunnusel on
mitu väikest sektorit.
Sama tulemuseni jõuame ka tunnuse väärtuste kohta
koostatud sagedustabeli põhjal.
Koondame (liidame) väikesed sektorid kokku,
moodustades ühe suurema sektori.
Sektordiagrammi koostamise ja kujundamise juhend 2012
Selleks vali sektorid ning ava Properties aknas Categories vaheleht.
Märgista valik:
Collapse (sum) categories
less than ... %
Kusjuures osakaalu on võimalik
ise määrata/muuta.
Kokkuliidetud väärtustest moodustatud uue sektori
nime muutmiseks, tee sellel nimel (Other) paremklõps
ning sisesta uus kategooria nimetus (näiteks „6 ja
enam“).
3.4. Sektorite järjestamine
Koostame sektordiagrammi tunnuse perekonnaseis väärtustest.
Sektorite järjestamiseks suuruse järgi valime sektorid ning avame Properties aknas Categories vahelehe.
Sektordiagrammi koostamise ja kujundamise juhend 2012
Määrame, et sektordiagrammi sektorid järjestatakse nende suuruse järgi (Statistics) kahanevas järjestuses
(Descending) ning kinnitame valiku (Apply).
Tulemus on järgmine:
1. Tulpdiagramm
Tulpdiagramm sobib nii ühe tunnuse kategooriate võrdlemiseks kui ka mitme tunnuse omavaheliseks
võrdlemiseks.
1.1. Üldised kujundamisreeglid
Väga pikkade andmesiltide korral annab parema tulemuse telgede ära vahetamine.
Tulbad võib järjestada kahanevasse järjekorda, kui tunnuse väärtused ei ole sisulises järjekorras
(järjestustunnus või intervalltunnus).
Tulpdiagrammi koostamise ja kujundamise juhend 2012
1.2. Ebaõnnestunud tulpdiagrammid
2. Tulpdiagrammi koostamine
Tulpdigarammi koostamisel tuleks eelnevalt läbi mõelda, milliseid andmeid sellel esitada soovitakse.
Tulpdiagrammi koostamiseks vali Graphs/Legacy Dialogs/Bar...
Esmalt tuleb valida 3 ülemise variandi seast:
Simple – tavaline (iga tulp esitab ühe tunnuse kokkuvõtet või
ühe tunnuse ühte kategooriat)
Clustered – võrdlev (tulbad üksteise kõrval)
Stacked – kihtdiagramm
Seejärel tuleb valida 3 alumise variandi seast:
Summaries for groups of cases - kokkuvõtted tehakse objektide
gruppide kohta
Summaries of separate variables - kokkuvõtted tehakse
erinevate tunnuste kohta
Values of individual cases - üksikväärtuste analüüs
Tulpdiagrammi koostamise ja kujundamise juhend 2012
2.1. Üksikväärtuste analüüs
Seda valikut kasutatakse praktikas ilmselt kõige harvemini, sest see eeldab juba eelnevalt kokkuvõetud
andmeid.
Olgu meil näiteks X kooli kohta teada 10-ndate, 11-ndate ja 12-ndate
klasside õpilaste arvutatud keskmine hinne.
Tavapärasest andmestikust erineb näiteandmestik seetõttu, et näites
ei ole üksikute õpilaste keskmiseid hindeid vaid välja on arvutatud
klasside keskmised hinded.
Näites toodud andmete esitamiseks tulpdiagrammi abil, valime Graphs/Legacy Dialogs/Bar...
Dialoogiaknas valime:
Simple
Values of individual cases
Edasi viime Bars Represent väljale tunnuse
keskmine_hinne ning kategooriate esitamiseks viime
tunnuse klass Category Labels/Variable väljale.
Tulemuseks saame tunnuse üksikväärtustest moodustatud tulpdiagrammi.
Kui me koostaksime üksikväärtustest
tulpdiagrammi mahuka (mitte eelnevalt
kokkuvõetud) andmestiku korral, saaksime
tulemuseks (olenevalt objektide arvust) täiesti
loetamatu ning kasutu tulpdiagrammi.
Tulpdiagrammi koostamise ja kujundamise juhend 2012
2.2. Tulpdiagrammi koostamine (tulba kõrgus vastajate arv või %)
1. Koostame tulpdiagrammi tunnuse sissetulek vastustest.
Valime Graphs/Legacy Dialogs/Bar...
Vali tunnus Sissetulek ja vii see Category Axis: väljale
Tulemuseks saime diagrammi,
mille iga tulp esitab vastava
kategooria esinemissagedust.
Näiteks kuni 160€ teenivate
vastajate arv oli natuke alla 200.
NB! Järjestustunnusest koostatud
tulpdiagrammi kujundamisel ei tohi
tulpasid suuruse järgi järjekorda
paigutada, kuna tunnuse
väärtustel on sisuline järjestus
olemas.
2. Koostame tulpdiagrammi tunnuse perekonnaseis vastustest.
Valime Graphs/Legacy Dialogs/Bar...
NB! Nimitunnusest koostatud tulpdiagrammi kujundamisel võib parema
ülevaate saamiseks tulbad suuruse järgi järjekorda seada.
JÄRJESTUS-TUNNUS
NIMITUNNUS
Tulpdiagrammi koostamise ja kujundamise juhend 2012
3. Koostame tulpdiagrammi tunnuse sugu vastustest.
Valime Graphs/Legacy Dialogs/Bar...
Tunnusel sugu e binaarsel
tunnusel on ainult kaks
võimalikku väärtust, seega ei sobi
nende esitamiseks tulpdiagramm, sest esitatavat infot on liiga vähe.
Parem viis nendest andmetest ülevaate koostamiseks on esitada
tulemused tekstilisel kujul.
4. Koostame tulpdiagrammi tunnuse vanus vastustest.
NB! Kui tunnusel on palju
erinevaid arvväärtuseid, siis nende
väärtuste kokkuvõtmiseks ning esitamiseks sobib histogramm,
mitte tulpdiagramm.
2.3. Lihtsa tulpdiagrammi koostamine (tulba kõrgus arvutatud mingi muu tunnuse väärtuste kaudu)
Koostame tulpdiagrammi, mille tulba kõrgus ei väljenda enam vastajate arvu või osakaalu vaid on esitab
näiteks sellesse kategooriasse kuuluvate isikute keskmist vanust.
Uurime järgnevalt, kas erinevates organisatsioonides töötavate isikute keskmine vanus on erinev.
Oodatav tulemus on tulpdiagramm, kus igas organisatsioonis töötavate isikute kohta on arvutatud nende
keskmine vanus (ja see on välja toodud tulba kõrgusena).
BINAARNE
TUNNUS
INTERVALLTUNNUS, MILLEL
ON PALJU ERINEVAID
ARVVÄÄRTUSEID
Tulpdiagrammi koostamise ja kujundamise juhend 2012
Valime Graphs/Legacy Dialogs/Bar...
Vali tunnus Töökoht ja vii see Category Axis: väljale.
Tulpade sisu määrame Bars Represent alajaotuses ning märgistame valiku Other statistic ja viime tunnuse
Vanus Variable väljale.
3. Tulpdiagrammi kujundamine
Diagrammi kujundamine toimub Chart Editor aknas (avamiseks tee koostatud diagrammi peal topeltklõps).
Koos Chart Editor akna avamisega
peaks avanema ka Properties aken.
Properties akna avamiseks tee Chart
Editor režiimis diagrammi peal
topeltklõps.
3.1. Tulpade kujundamine
Märgista tulpdiagrammi tulbad ning rakenda muudatusi Properties akna Fill & Border vahelehel.
Fill – sisu värv
Border – raami värv
Pattern – tulba muster
Border Style – raami kujundamine
Kinnita muudatused Apply nupule
vajutamisega.
Tulpdiagrammi koostamise ja kujundamise juhend 2012
3.2. Teksti kujundamine
Teksti muutmiseks tee soovitud teksti peal aeglane topeltklõps.
3.3. Andmesiltide lisamine
Märgista tulbad ning tee paremklõps tulpade peal ja vali ripploendist Show Data Labels
Koos andmesiltidega muutus ka Properties akna sisu, sinna ilmus vaheleht Data Value Labels
Displayed väljale vii need sildid, mida soovid diagrammil kuvada. Näitena on tulpadel kuvatud vastava
kategooria keskmine vanus.
Kui kõik andmesildid ära ei mahu (tekst liiga pikk või on tulpasid liiga palju), kuvab SPSS ainult need, mis ära
mahuvad. Kõikide andmesiltide kuvamiseks: Suppress overlapping labels
Andmesiltidel esitatava teksti suuruse muutmiseks vali andmesildid, ava Properties aknas
Text Style vaheleht ning määra soovitud kirja suurus (Preferred Size).
Andmesiltidel esitatud numbrite komakohtade muutmiseks vali andmesiltidel esitatud numbrid või
protsendid, ava Properties aknas Number Format vaheleht ning muuda kuvatavate komakohtade arv
(Decimal Places).
Tulpdiagrammi koostamise ja kujundamise juhend 2012
3.3. Abijoonte kuvamine
Abijoonte lisamiseks märgista y-telje skaala numbrid.
Tee skaala numbrite peal paremklõps ning vali
ripploendist Show Grid Lines.
Lisatud abijooni saad kujundada Properties aknas.
Major ticks only – jooned kuvatakse hõredama jaotuse järgi
(skaala punktides)
Minor tick only – jooned kuvatakse tihedama jaotuse järgi
(skaala vahepealsetes punktides)
Both major and minor ticks – kuvatakse nii tihedama kui ka
hõredama jaotuse abijooned.
3.4. Telgede vahetamine
Kui kategooriaid kirjeldav tekst on liiga pikk, paigutab SPSS selle vertikaalsest või kaldu. Ülevaatlikuma pildi
saamiseks oleks sellisel juhul vaja tulpdiagrammi teljed ära vahetada (et teksti oleks parem lugeda).
Telgede vahetamiseks tee tulpdiagrammi peal paremklõps ning vali ripploendist Transpose Chart.
Horisontaalselt paigutatud teksti poolitamiseks klõpsa kursor
sobivasse kohta tekstis ning kasuta klahvide Shift + Enter
kombinatsiooni .
Tulpdiagrammi koostamise ja kujundamise juhend 2012
3.5. Tulpade järjestamine
Tulbad võib järjestada kahanevasse järjekorda, kui tunnuse väärtused ei ole sisulises järjekorras
(järjestustunnus või intervalltunnus).
Koostatud tulpdiagrammil ei tohi tulpasid
suuruse järjekorda paigutada, sest
tunnuse väärtustel on sisuline järjestus.
Parema ja ülevaatlikuma pildid saamiseks tunnuse
väärtuste esinemisest, võiks/peaks tulbad järjestama
kahanevasse järjekorda.
Tulpade järjestamiseks vali tulbad ning ava Properties aknas Categories vaheleht.
Vali tulpade järjestamine nende suuruse järgi (Sort by: Statistics) kahanevas järjestuses (Direction: Descending).
07.04.14
1
Kirjeldav statistika
Korrelatsioonanalüüs
Seose analüütiline hindamine
Seose visuaalne hindamine
Kirjeldav statistika
Korrelatsioonikordajad
§ Pearson’s r
§ Standardiseeritud kahe tunnuse vahelise
seose kordaja
§ Pearsoni kordaja puudused
– lineaarne seos: tunneb punktipilve, mis
on venitatud piki sirget.
– tundlik erandite suhtes: paar üksikut
erandit väikeses valimis võivad
kahekordistada kordaja väärtust.
Kirjeldav statistika
Pearsoni r (intervall + intervall)
§ Kuidas on seotud kooliskäidudaastate arv ja hinnang
arvutikasutusoskusele?
Kirjeldav statistika
Korrelatsioonikordajad
§ Spearman’s ρ
§ MPAR korrelatsioonikordaja
§ Astakkorrelatsioonikordaja
– intervalltunnused ei vasta
normaaljaotusele
(ka erandlikud väärtused)
– Järjestustunnus(ed)
– asendab väärtused järjekorra-numbritega ning kasutab Pearsoni
kordaja valemit =>
Spearmani kordaja kordaja (üldjuhul)
Kirjeldav statistika
Spearmani roo (järjestus + järjestus)
§ Kuidas on seotud arvutikasutamise aeg tööks ning
meelelahutuseks?
Kirjeldav statistika
Spearmani roo (järjestus + intervall)
§ Kuidas on seotud hinnang arvutikasutusoskusele ning see, kui palju
vastaja kasutab arvutit tööks?
07.04.14
2
Kirjeldav statistika
Spearmani roo (intervall + intervall)
ekstreemsed väärtused
§ Kuidas on seotud sissetulek ja kooliskäidudaastate arv?
Kirjeldav statistika
Korrelatsioonikordajad
§ Kendall’s τ
§ MPAR korrelatsioonikordaja
§ Astakkorrelatsioonikordaja
– kui on vähe andmeid ja palju
sarnaseid väärtuseid
Kirjeldav statistika
Korrelatsioonikordajad
§ Cramer’s V
– Nimitunnuste seose
tugevuse uurimiseks.
– Kordaja ei näita
seose suunda,
ainult tugevust.
N: Eriala ja tööl käimise
seos V=,45
§ Phi
– 2x2 binaarsete tunnuste korral
– Ruutjuur hii-ruudu väärtuse jagatisest valimi suurusega
Kirjeldav statistika
Crameri V (binaarne + binaarne)
Perekonnaseis + kas oled proovinud narkoo7kume?
V=0,22
Vanus + kas oled proovinud narkoo7kume?
V=0,382
Sissetulek + kas oled proovinud narkoo7kume?
V=0,809
Kirjeldav statistika
Milline kordaja valida?
KORDAJA ANDMED LISATINGIMUS
PEARSON I + I Seose kuju – lineaarne
Erandlikud väärtused puuduvad (ei domineeri)
SPEARMAN I + I, I + J, J + J Seose kuju ei ole lineaarne ja jaotusel on
erandlikud väärtused (I + I)
KENDALL J + J Väike valim ja palju sarnaseid väärtuseid
CRAMER I + N, I + B, N + B,
N + N, N + J, B + J
Tõlgendatakse vaid seose tugevust, miWe
suunda
PHI B + B Tõlgendatakse vaid seose tugevust, miWe
suunda
Kirjeldav statistika
Tulemuste esitamine
§ Tajutud stressi taseme ja enesetõhususe vahelise suhte analüüsil
ilmnes oluline negatiivne korrelatsioon, mille kohaselt madalama
enesetõhususega õpetajad tajusid stressi kõrgemalt (r=-.37, p=.
010).
§ Laste väliskeskkonna mängu ja vanemate soovide vahel ilmnes
tugev negatiivne seos (r=-0,713; p=0,05), mille põhjal võib väita, et
vanemate soov oma lapsi näha teatud tegevustes ja olemuses
erineb sellest (ootused on lapse mängulisusele on kõrgemad),
millised on lapsed väljas mängides tegelikult.
8.04.2012
1
KORRELATSIOONANALÜÜS
Kuidas on kaks tunnust seotud?
Reeglina
mõõdetakse seost kahe intervalltunnuse (või järjestustunnuse) vahel.
On oluline, et mõlemad mõõdetavad tunnused moodustaksid mingi
järjestuse.
Pikkus Kaal
176 68
176 70
178 75
179 76
180 78
182 86
184 88
184 90
190 85
0
10
20
30
40
50
60
70
80
90
100
175 180 185 190 195
Mida suurem kaal, seda pikem
JA vastupidi:
mida vähem vastaja kaalub, seda
lühem ta on.
KORRELATSIOONANALÜÜS
Seose visuaalne hindamine
Seose analüütiline hindamine
8.04.2012
2
KORDAJAD
Enamlevinud korrelatsioonikordajad
Pearsoni kordaja puudused
• Lineaarne seos: tunneb punktipilve, mis on venitatud piki sirget.
• Tundlik erandite suhtes: paar üksikut erandit väikeses valimis kahekordistavad
kordaja väärtust.
Spearman e. astakkorrelatsioonikordaja
• Pidevad tunnused ei ole normaaljaotusega (ka erandlikud väärtused)
• Järjestustunnus
• Spearmanni kordaja > Pearsoni kordaja (tavaliselt)
Kendall
• Vähemalt järjestustunnused
• Samasuunaliste ja vastassuunaliste paaride analüüs.
Crameri V
• Nimitunnuste seose tugevuse uurimiseks.
• Kordaja ei näita seose suunda, ainult tugevust.
Andmeanalüüs (2014)
Tunnuse tüübid
Vastavalt sellele, mida me uurida tahame, kogume me andmeid kas inimeste, koolide, valgete hiirte,
kalendrikuude, kartulipõldude vms kohta. Kõiki selliseid indiviide või üksusi, kelle/mille käest või kohta on
me andmeid kogume, nimetatakse statistilises andmeanalüüsis objektideks. Andmeid koguma asudes oleme
valmis mõelnud mingid neid objekte iseloomustavad omadused, mis meid huvitavad, näiteks: värvus, vanus,
hind, kaal, arvamus millegi suhtes, jne – selliseid omadusi nimetatakse muutujateks. Omadusi, mida saab
mõõta nii (või mis on juba kokku võetud nii), et iga objekti jaoks saadakse ainult üks vastus ehk üks ühik
infot nimetatakse tunnusteks. Objektid ja tunnused peavad olema valitud enne andmete kogumist ning
andmete kogumise käigus püüame saada tulemuse või vastuse iga objekti kohta kõigi meid huvitavate
tunnuste lõikes - statistika terminoloogiast lähtudes on need väärtused. Nii võivad tunnuse „haridus“
võimalikud väärtused olla näiteks „algharidus“, „põhiharidus“, „keskharidus“ ja „kõrgharidus“, aga tunnuse
„vanus“ väärtused näiteks arvud „12“, „27“, „6“, jne. (Arvuti kasutamine uurimistöös ( http://aku.opetaja.ee/ ))
Andmete analüüsi kontekstis on oluline teha vahet nelja erineva tunnuse tüübi vahel:
! Nimitunnused – tunnused, mille väärtused moodustavad kategooriad, kuid neid kategooriaid ei saa
omavahel järjestada. Nt. rahvus (eestlane, venelane, soomlane, muu); eriala (psühholoogia, informaatika,
matemaatika, geoökoloogia, sotsioloogia).
! Binaarsed tunnused – tunnused, millel on vaid kaks väärtust. Nt. sugu (mees, naine); nõustumine (olen
nõus, ei ole nõus).
! Järjestustunnused – tunnused, mille väärtused moodustavad kategooriad ning neid saab omavahel
järjestada. Samas ei ole nende väärtuste vahemikud võrdsed. Nt. hinnang (väga hea, hea, rahuldav)
! Intervalltunnused (sh arvtunnused) – väärtused on järjestatavad ning nende väärtuste vahemikud on
võrdsed. Nt. sissetulek (123€, 125€, 130€, 1500€jne.);
SPSS programmis saab sisestatud andmeid jagada kolme tüübi/skaala vahel: nimitunnus (Nominal),
järjestustunnus (Ordinal) ning intervalltunnus (Interval). Binaarsed tunnused kuuluvad nimitunnuste alla.
Ankeet
1. Vanus: __________
2. Sissetulek viimasel kuul: __________
3. Sugu: mees naine
4. Millised on sinu hobid (märgi kõik sobivad vastused):
käsitöö
muusika
sport
lugemine
muu hobi , milline: teatris/kinos käimine
5. Küsitlustulemuste saamiseks, sisesta oma e- maili aadress: __________
1. Küsimus, mille vastuseks on number
Nt. Vanus: 26
Name: tunnuse nimi (ei alga numbriga, ei sisalda tühikuid ja muid erimärke)
Type: mis tüüpi andmeid te andmetabelisse sisestama hakkate: numbreid (Numeric)
Width: numbriliste andmete korral ei ole oluline määrata mitmekohaline on sisestatav number. Seega võib
jääda vaikimisi lahtris olev väärtus 8.
Decimals: kuna vanusel komakohad puuduvad, asendame olemasoleva numbri 0-ga.
Label: tunnuse pikem selgitus , mis võib sisaldada nii erimärke kui ka tühikuid.
Tunnuste defineerimise juhend 2012
2. Küsimus, mille vastuseks on komakohaga number
Nt. Sissetulek viimasel kuul: 1356,85
Name: tunnuse nimi (ei alga numbriga, ei sisalda tühikuid ja muid erimärke)
Type: mis tüüpi andmeid te andmetabelisse sisestama hakkate: numbreid (Numeric)
Width: numbriliste andmete korral ei ole oluline määrata mitmekohaline on sisestatav number. Seega võib
jääda vaikimisi lahtris olev väärtus 8.
Decimals: kuna sissetulekul soovime sisestada k aks komakohta, jätame Decimals lahtrisse numbri 2.
Label: tunnuse pikem selgitus, mis võib sisaldada nii erimärke kui ka tühikuid.
3. Ühe vastusevariandiga küsimus
Nt. Sugu: mees naine
Name: tunnuse nimi (ei alga numbriga, ei sisalda tühikuid ja muid erimärke)
Type: mis tüüpi andmeid te andmetabelisse sisestama hakkate: numbreid (Numeric)
Kodeerime vastusevariandid (andmete sisestamise kiirendamiseks ja võimalike sisestusvigade
vähendamiseks) järgmiselt: 1 mees 2 naine
Andmetabelisse sisestame numbreid (1 või 2).
Width: numbriliste andmete korral ei ole oluline määrata mitmekohaline on sisestatav number. Seega võib
jääda vaikimisi lahtris olev väärtus 8.
Decimals: kuna me kodeerime tunnuse väärtused täisarvudeks, siis asendame olemasoleva numbri 0-ga.
Label: tunnuse pikem selgitus, mis võib sisaldada nii erimärke kui ka tühikuid.
Values: kasutame kodeerimiseeskirja sisestamiseks (Value: kood; Label: kirjeldus)
Tunnuste defineerimise juhend 2012
4. Mitme vastusevariandiga küsimus
Nt. Millised on sinu hobid (märgi kõik sobivad vastused):
käsitöö
muusika
sport
lugemine
muu hobi, milline: teatris/kinos käimine
Iga vastusevariandi jaoks loome eraldi tunnuse.
Nt: Kas käsitöö on märgitud hobiks? jah ei
Nt: Kas muusika on märgitud hobiks? jah ei
Nt: Kas sport on märgitud hobiks? jah ei
Nt: Kas lugemine on märgitud hobiks? jah ei
Nt: Kas on märgitud muu hobi? (Muud hobid kodeerime näite 3 järgi)
Name: tunnuse nimi (ei alga numbriga, ei sisalda tühikuid ja muid erimärke)
Type: mis tüüpi andmeid te andmetabelisse sisestama hakkate: numbreid (Numeric)
Kodeerime vastusevariandid (andmete sisestamise kiirendamiseks ja võimalike sisestusvigade
vähendamiseks) järgmiselt: 1 jah 2 ei
Andmetabelisse sisestame numbreid (1 või 2).
Width: numbriliste andmete korral ei ole oluline määrata mitmekohaline on sisestatav number. Seega võib
jääda vaikimisi lahtris olev väärtus 8.
Decimals: kuna me kodeerime tunnuse väärtused täisarvudeks, siis asendame olemasoleva numbri 0-ga.
Label: tunnuse pikem selgitus, mis võib sisaldada nii erimärke kui ka tühikuid.
Values: kasutame kodeerimiseeskirja sisestamiseks (Value: kood; Label: kirjeldus)
Tunnuste defineerimise juhend 2012
5. Avatud vastusega (teksti)küsimus, mille vastused eeldatavalt erinevad üksteisest väga palju.
Nt. Küsitlustulemuste saamiseks, sisesta oma e-maili aadress: [email protected]
Name: tunnuse nimi (ei alga numbriga, ei sisalda tühikuid ja muid erimärke)
Type: mis tüüpi andmeid te andmetabelisse sisestama hakkate: tekst (String)
Width: teksti puhul on oluline määrata võimalike sisestatavate tähemärkide arv. Kuna need tähed, mis
jäävad üle sisestatud numbri (laiuse) kustutatakse, tuleks laius määrata võimalikult suur.
Label: tunnuse pikem selgitus, mis võib sisaldada nii erimärke kui ka tühikuid .
07.04.14
1
Üldistav statistika
Andmeanalüüs
§ KIRJELDAV STATISTIKA
– Ühemõõtmeline analüüs (tekst, tabel, diagramm)
– Võrdlev analüüs (tekst, tabel, diagramm)
– Korrelatsioonanalüüs
§ ÜLDISTAV STATISTIKA
– Ühemõõtmeline analüüs
– Võrdlev analüüs
– Korrelatsioonanalüüs
Üldistav statistika
Andmete analüüs
Mitu gruppi: erinevused gruppide vahel Korrelatsioon
Ülevaade antud tunnuse/
grupi vastustest
PAR
Histogramm,
keskväärtus, st.hälve, jne
Võrreldavate gruppide arv
Vahemikhinnang
(ÜK keskväärtuse
hindamine)
1 grupp
Kas gruppide vastusedon erinevad/sarnased?
Kuidason kaks tunnust
omavahel seotud?
MPAR
Sagedustabel,
tulp- ja sektordiagramm
PAR
keskväärtus, st.hälve, jne
Vahemikhinnang
(ÜK proportsioonide
hindamine)
PAR
Pearsoni kordaja
St. olulisustest
MPAR
Spearmani kordaja
Crameri kordaja
St.olulisustest
PAR Parameetrilised meetodid eeldavad intervalltunnust
MPAR Mitteparameetrilised meetodid eeldavad nimi- või
järjestustunnust, ka intervalltunnus
3 ja rohkem 2
T-test
MPAR
Risttabel, vrdl tulpdiagramm
Hii ruuttest
PAR
keskväärtus, st.hälve, jne
ANOVA
MPAR
Risttabel, vrdl tulpdiagramm
Kruskal-Wallis
Üldistav statistika
Millest sõltub andmeanalüüsimeetodi valik?
• Uurija teadmised/oskused
• Kellele esitab, kuidas?
Sihtrühmast
• Uurimisküsimus: laiem
• Analüüsiküsimus: nt. kas kaks gruppi on erinevad/seotud?
Küsimuse tüübist
• Nimitunnused
• Nimitunnuse väärtuseid ei saa järjestada, järjestustunnusel saab
• Järjestustunnused
• Intervalltnnuse skaalavahemikud on võrdsed, järjestustunnusel mitte
• Intervalltunnused
• Intervalltunnuse korral saame arvutada keskväärtust, st.hälvet
• Binaarsed tunnused
Andmete tüübist (väärtuste järjestatavus, skaalavahemike võrdsus)
Üldistav statistika
Andmete tüübid
§ Nimitunnused
– väärtuseid ei saa järjestada, tekivad
kategooriad(!)
§ Järjestustunnused
– väärtuseid saab järjestada,
skaalavahemikud ei ole võrdse pikkusega
nt. Likerti skaalad
§ Intervalltunnused
– Arvud, võrdse jaotusega skaalad.
– Intervalltunnuse korral saame arvutada
keskväärtust, st.hälvet
§ Binaarsed tunnused
– Kaks võimalikku väärtust (nimitunnus,
intervalltunnus)
§ Kõrgem omandatud
haridustase
• Keskharidus
• Keskeri-haridus
• Kõrgharidus
§ Kõrgem omandatud
haridustase?
– Põhiharidus
– Keskharidus
– Kõrgharidus
§ Mitu aastat oled koolis
käinud/õppinud?
§ Kas sul on keskharidus?
Üldistav statistika
Üldistava statistika meetodite kontekst
§ Valikuuringud
– valim on tõenäosuslik( juhuvalim )
– valim esindab üldkogumit, piisavalt arvukas
– Idee: leian erinevuse/seose valimis ning küsin:
– Kas saadud erinevus on juhuslik või saame seda üldistada (erinevus
valimis on ülekantav ÜK-le.)
§ Eksperimentaalsed uuringud
– 2 rühma/gruppi
– “kohtleme” erinevalt ja vaatame, kas saame erinevad tulemused
– Kas saime erineva tulemuse, sest “kohtlesime” erinevalt või on saadud
erinevus juhuslik viga
Üldistav statistika
Põhiküsimus – vea hindamine
§ KIRJELDAV STATISTIKA
– Võimalikud vead?
• Andmete kogumisvead
• Meetodi kasutusviga
• Arvutamisvead
• Interpretatsioonivead
§ ÜLDISTAV STATISTIKA
ÜK – V – ÜK
Võimalikud vead?
07.04.14
2
Üldistav statistika
Vea hindamine (1) Uuring “Lapsed ja internet ”
www.turu-uuringute.ee (2006.a.)
Üldistav statistika
Normaaljaotuse PROPORTSIOONID
Üldistav statistika
Normaaljaotus e Gaussi jaotus
§ Kirjeldab numbrilise tunnuseväärtuseid (palju erinevaid)
§ Milline diagramm sobib andmete esitamiseks
(nr.tunnus, palju erinevaid väärtuseid)?
21-25 26-30 31-35 36-40 41-45 46-50 51-55
jaotuskõver
Mida rohkem objekte me vaatleme ,
seda siledamaks muutub jaotuskõver
Üldistav statistika
Normaaljaotuse põhjal saame järeldada
§ Jaotuse keskväärtus=170cm, standardhälve=5cm
§ Leili , kelle pikkus on 170 cm, asub jaotuse keskel
(temast lühemaid 50%)
Leili (170 cm) keskmine + 0·st.hälvet e z-väärtus = 0
§ Mari, kelle pikkus on 180 cm, temast lühemaid 97,5%
Mari (180 cm) keskmine + 2·st.hälvet e z-väärtus = 2
§ Virve(160cm)
keskmine -2·st.hälve
z-väärtus = -2
§ Tiiu (185cm)
Üldistav statistika
Väärtuste standardiseerimine
Üldistav statistika
Statistiline järeldamine
§ Standardvea põhjal saab üld-
kogumi vastava arvnäitaja
väärtusele hinnangu anda
vastavalt alltoodud reeglitele:
§ 68%tõenäosusega asub üldkogumi parameeter vahemikus:
valimi arvnäitaja väärtus ± 1 st.viga
§ 95% tõenäosusega asub üldkogumi parameeter vahemikus:
valimi arvnäitaja väärtus ± 2 st.viga
§ 99%tõenäosusega asub üldkogumi parameeter vahemikus:
valimi arvnäitaja väärtus ± 2,5 st.viga



























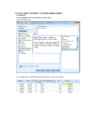





























































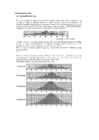







































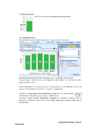























































































































































































































































































































































Kõik kommentaarid