Andmebaasid 1.9Teema
1 - Erinevat tüüpi andmemudelite ( hierarhiline , relatsiooniline , objekt-orienteeritud) ja vastavate andmebaasisüsteemide väljatöötamise kronoloogiline järjekord (kõigepealt hierarhilisel mudelil põhinevad andmebaasisü steemid - puustruktuuriga hierarhiline mudel, kus tekivad anomaaliad andmete lisamisel ja kustutamisel ning on palju liiasust; seejärel relatsioonilisel mudelil põhinevad - on relatsioonid ehk tabelid , millel on atribuudid ehk veerud ja andmed esitatakse korteežidena ehk ridadena; kõige viimaks objekt-orienteeritud andmebaasisüsteemid - neis saab hoida objekt-oritenteeritud keeles kirjutatud objekte, kapseldada ja polümorfismi kasutada).
Teema
2•
Andmebaaside
valdkonnas tuntud inimesed ja millega nad on end ajalukku
jäädvustanud –
E. F. Codd (relatsioonilise mudeli "isa"), P. Chen
(olemi-suhte diagrammi väljamõtleja), C. J. Date ja H. Darwen
(Kolmanda Manifesti autorid).
•
Kuidas
nimetatakse aastal 1995 avaldatud dokumenti, milles esitatakse C.J.
Date ja H. Darwen poolt relatsioonilise mudeli täiendatud ja
parandatud kirjelduse?
(The Third Manifesto –
Kolmas Manifest)
•
Milline
on Kolmandas Manifestis kirjeldatud andmebaasikeele nimi?
(D)
•
Mida
tähendavad
akronüümid ERD, UML, CASE ja SQL? (Entity-
Relationship Diagram, Unified Modeling Language, Computer
Aided/Assisted Software/System
Engineering ja Structured Query
Language).
- Võtmed relatsioonilises mudelis:
primaarvõti - veerg /veerud, mis on valitud relatisooni kirjete unikaalsust tagama;
kandidaatvõti - veergude hulk, millele vastavad väärtusete kominatsioonid on igas reas unikaalsed . Ei tohi sisaldada liiasusi (et mõne veeru kustutamisel säilib unikaalsus). Võtme read on järjestatud, nende järjekorra muutmisel saame uue võtme.
alternatiivvõti - kandidaatvõti, mis pole valitud primaarvõtmeks,
lihtvõti - ainult 1 veerg,
liitvõti - mitu veergu,
supervõti - veerud, mis tagavad relatsiooni kirjete unikaalsuse ja kui mõni veerg ära võtta, siis endiselt tagavad unikaalsuse,
intelligentne võti ehk sisulise tähendusega võti - nt riigi kood, omab ka reaalses elus mingit tähendust antud kirje kohta,
kattuv võti - liitvõtmed, millel vähemalt 1 atribuut langeb kokku,
välisvõti - võti, mis seob tabelit mingi teise tabeliga. Välisvõti (veerg) seotakse kandidaatvõtmega (teise tabeli veerg). Veergude nimed ei pea olema samad. Iga välisvõtme väärtus peab vastama seotud tabeli kandidaatvõtme väärtusele või olema NULL.
surrogaatvõti - genereetitakse automaatselt nt mingi ID.
•
Relvari
(relatsioonilise muutuja ) supervõtmete arvu leidmine. Supervõtmed
on kõik atribuutide komplektid, mis tagavad relatsiooni kirjete
unikaalsuse. Supervõtmed võivad sisaldada atribuute, mille
eemaldamisel säilib unikaalsuse omadus. Seega supervõtmeid on nii
palju, kui on kandidaatvõtmeid ja lisaks veel muid atribuute.
•
Relatsioonilise
mudeli põhimõ isted :
relatsiooniline muutuja (relvar) - muutuja, mis on oma tüübilt
relatsioon ja mille väärtuseks on korteežide hulk;
relatsioon -
relatsiooni tüüpi väärtus, mis koosneb tüübile vastavast
päisest ja kehandist, mis koosneb korteežidest;
tüüp e
domeen - nime omav lõplik väärtuste hulk.
•
Milline
on ainus skalaarne tüüp, mida iga relatsiooniline
andmebaasisü steem igal juhul peab toetama?
(BOOLEAN)
•
Mida
tähendab,
et andmebaasisü steemis on tüüp/operaator süsteemi-defineeritud?
(see on loodud andmebaasisüsteemi
loojate poolt)
•
Relatsiooni/tabeli
aste ja võimsus.
(aste on atribuutide/veergude arv ja
võimsus on korteežide/ridade
arv)
•
M
illise
andmemudeli alusel loodud andmebaas on ja milline ei olenavigatsiooniline
andmebaas?
(relatsiooniline ei ole, kuid võrkmudelil ja
hierarhilisel
mudelil põhinevad on, sest kasutavad viitasid kirjete vaheliste
seoste loomisel)
- Olemi terviklikkuse reegel ja viidete terviklikkuse reegel. Olemi terviklikkus : igal baasrelatsiooni primaarvõtmel peavad kõik atribuudid väärtustatud olema. Viidete terviklikkus: igale välisvõtmele peab vastama seotud tabelis mingi kandidaatvõti, mis pole NULL.
•
Kuidas
moodustuvad relatsioonilises mudelis andmete vahelised seosed?(välisvõtmetesse
kuuluvate atribuutide väärtuste abil. Relatsioonid on seotud
välisvõtmetega. Ühes tabelis on välisvõti ja teises sellega
seotud kandidaatvõti)
•
Suletud
maailma eeldus.
(Iga antud ajahetkel relatsioonis asuv korteež,
esitab
sellel ajahetkel tõest
väidet. Kui
antud ajahetkel võiks relatsioonis sisalduda mingi korteež, kuid
see korteež seal tegelikult ei sisaldu, siis järelikult
see korteež
esitab vale väite.)
•
Informatsiooni
ühtse esitamise printsiip.
(kogu relatsioonilises andmebaasis hoitav informatsioon esitatakse
vaid ühel viisil – relatsiooni atribuutide väärtustena)
Teema
3 (relatsioonialgebra) - Relatsioonialgebra põhimõisted.
Relatsioonialgebra on relatsioonide kui operandidega teostatavate operatsioonide kogum.
Operatsioonid jagunevad: hulgateoreetilised operatsioonid ja spetsiaaloperatsioonid.
Relatsioonialgebra operatsiooni tulemus on relatsioon.
Iga operatsiooni jaoks on vajalik operaator.
•
Relatsioonialgebra
operatsioonid:
projektsioon -
SELECT x FROM X,
piirang - SELECT * FROM X WHERE x=1,
lõige
- INTERSECT korteežid, mis on nii relatsioonis S kui ka relatsioonis
R,
vahe - EXCEPT korteežid, mis on relatsioonis S, kuid puuduvad
relatsioonis R,
hulgateoreetiline
summa - UNION
ilma duplikaatideta ehk kõik korteežid S-ist ja ka R-ist,
ü
hendamine - JOIN igasuguste tingimustega “a teeta b” (teeta-ühendamine),
kus teeta on = (siis on equijoin) või , , (siis on non-equijoin) või hoopis NATURAL JOIN, mille puhul
ühendatakse tabelid ühesuguste nimedega veergude põhjal;
otsekorrutis - iga R-i korteež on ühendatud iga S-i korteežiga,
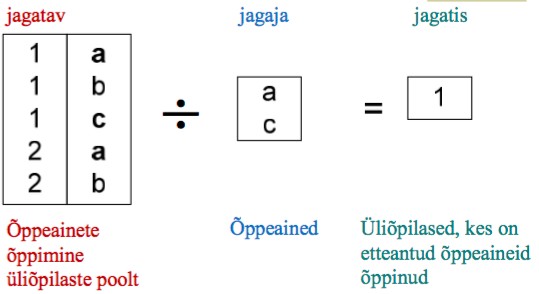
jagamine - nt leida töötajate ja osakondade vastavuse tabelist
töötajad, kes töötavad osakondades 2 ja 3.
•
Relatsioonialgebra
operatsioonide kommutatiivsuse ja assotsiatiivsuseomadus.
(Hulgateoreetilise vahe
operatsioon ei ole kommutatiivne ja
assotsiatiivne, kõik teised on mõlemat)
- Unaarsed ja binaarsed relatsioonialgebra operatsioonid.
Unaarsed
spetsiaaloperatsioonid: Piirang ja Projektsioon
Binaarsed
spetsiaaloperatsioonid: Ühendamine
ja Jagamine
Unaarsed
hulgateoreetilised operatsioonid: Ümbernimetamine
Binaarsed
hulgateoreetilised operatsioonid: Hulgateoreetiline
summa,
Hulgateoreetiline vahe, Lõige
ja Otsekorrutis
•
Identiteedi
projektsioon –
projektsioon, mille tulemuses on kõik algse
relatsiooni
atribuudid.
•
Identiteedi
piirang –
piirang, mille tulemuses on kõik algse relatsiooni
korteežid.
•
Täiendavad
relatsioonialgebra operatsioonid
–
- poolühendamine
- SEMIJOIN defineerib relatsiooni, mis sisaldab selliseid kirjeid
relatsioonist R, mis osalevad relatsioonide R ja S ühendamise
tulemusel saadavas relatsioonis;
- poolvahe leidmine -
SEMIDIFFERENCE defineerib relatsiooni, milles on kõik
korteežid
relatsioonist R, millele ei leidu vastavad korteeži relatsioonis S;
- vasakpoolne välisühendamine
- S LEFT JOIN R võtab vastusesse S JOIN R ja veel need read R-ist,
millele S-is vastavaid ridu ei leitud,
- laiendamine
- EXTEND lisatakse tabelisse veerg, mis kopeeritakse või arvutatakse
mingi olemasoleva veeru põhjal,
-
kokkuvõtmine - SUMMARIZE kasutab funktsioone AVG, COUNT, MIN, MAX,
SUM, et võtta mingid read kokku ja nende kohta midagi arvutada,
-
koostamine - COMPOSE võtab vastusesse S JOIN R väljaarvatud need
veerud, mis on S-il ja R-il ühised,
-
grupeerimine - GROUP mingi tabeli ühte veergu grupeeritaksse terve
teine tabel sisse,
-
mässimine
- WRAP terve tabel tehakse üheks veeruks ehk siis pannakse lihtsalt
ühine
päis .
•
Mida
tähendab,
et keel on relatsiooniliselt täielik? Andmebaasikeel
L on relatsiooniliselt täielik, kui kõiki
relatsioone, mida saab kirjeldada kasutades relatsioonialgebra
avaldisi, saab kirjeldada ka keeles L kirjutatud avaldiste abil.
Teema
3–5 (SQL)•
Milliseid
funktsioone tuleb SQL standardi alusel kasutada hetke kuupäeva,kellaaja
ning kuupäeva + kellaaja leidmiseks
(CURRENT_DATE,
CURRENT_TIME,
CURRENT_TIMESTAMP).
•
Mis
aastal avaldati esimene SQL standardi versioon?
(1986)
•
Milline
on hetkel kehtiv SQL standardi versioon? (SQL:2011)
•
Stringide
konkatenatsioon. Milline on standardses SQLis selle operaatori esitamiseks kasutatav sümbol?
(||, Accessis &)
•
Väärtuste
mittevõrdsus. Milline on standardses SQLis selle operaatoriesitamiseks
kasutatav sümbol?
()
•
LIKE
predikaat ja selles SQL standardi järgi kasutatavad mustri
sümbolid.(%
lubab enne/pärast 0 v mitu suvalist sümbolit ja
_ lubab täpselt ühe
suvalise sümboli)
- Alampäringud: ei tohi sisaldada ORDER BY, ei saa nendega teha AVG, SUM, MAX jne
Üks kord täidetav alampäring -
SELECT *
FROM
Tootaja
WHERE
palk >(SELECT palk FROM Tootaja WHERE tootaja_kood =1);
Korreleeruv
alampäring - samale tabelile viidates kasutatakse aliast,
alampäringut ei saa eraldiseisvalt käivitada
SELECT nimi
FROM
Tootaja AS X
WHERE
palk >(SELECT Avg(palk) FROM Tootaja AS Y WHERE
X.osakonna_nr
= Y.osakonna_nr);
Skalaarne
alampäring -
tagastab alati ühe rea ja ühe veeru. Kui pole midagi tagastada, on
see lahter NULL.
IN ja EXISTS alampäringuid saab kasutada
relatsioonialgebra operatsiooni "lõige"
realiseerimiseks. NOT
IN ja NOT EXISTS alampäringuid
saab kasutada relatsioonialgebra operatsiooni "vahe"
realiseerimiseks.
•
Mitmevalentset
loogikat kasutab relatsiooniline mudel? (kahevalentset
- TRUE või FALSE)
•
Mitmevalentset
loogikat kasutab SQL? (kolmevalentset
- NULL, TRUE
või
FALSE)
•
Milline
on loogikaoperaatorite rakendamise järjekord SQLis?
(NOT, AND,
OR)
•
Millist
loogikaoperaatorit võimaldab
realiseerida union
(OR)
ja millist join(AND)?
•
Andmebaasiobjektide
nimetamine ISO SQL standardi järgi.
(nimi on
maksimaalselt
128 märki pikk. Nimi ei tohi alata numbriga, sisaldada tühikut
ja
olla reserveeritud sõna, kui tegu pole just
piiritletud identifikaatoriga.)
•
Mis
asi on "piiritletud identifikaator "?
(identifikaator on jutumärkides: “nimi”, siis eristatakse suur-
ja väiketähti ja võib kasutada erilisis sõnu nagu “Table”).
•
Millised
on SQL standardis nimetatud andmetüübid?
(nt
CURRENCY,
MONEY,
AUTOINCREMENT,
SERIAL, HYPERLINK ei kuulu SQL standardisse)
Kuuluvad: CHARACTER,
VARCHAR, BINARY, BOOLEAN, VARBINARY, INTEGER, SMALLINT, INTEGER,
BIGINT, DECIMAL, NUMERIC, FLOAT,
DATE,
TIME, TIMESTAMP, INTERVAL, ARRAY, MULTISET, XML
•
Kuupäeva
ja kellaaja formaat SQL standardi järgi.
('YYYY-MM-DD
HH24:MI:SS')
•
Millist
tüüpi
objektide loomise võ imaluse näeb
ette SQL standard (nendeloomiseks
on CREATE lause)?
(
SCHEMA , TABLE, VIEW, DOMAIN, TYPE,
ASSERTION,
ROLE, TRIGGER, PROCEDURE, SEQUENCE, ....)
•
Millist
tüüpi
objekte SQL standard ei kirjelda (nende loomiseks ei oleCREATE
lauset)?
(DATABASE, INDEX, USER, TABLESPACE, ...)
•
Millisest
SQL standardi versioonist alates on ühe
või
teise andmebaasiobjekti loomise võimalus kirjeldatud SQL
standardis? (Protseduur,
funktsioon – Alates
SQL:1992 täiendusest
(aastast 1996); Triger, Kasutaja-defineeritud
tüüp, Roll
– Alates
SQL:1999;
Arvujada generaator – Alates
SQL:2003)
•
Mis
on tabeli päise ja tabeli
ridade semantika? (päis –
predikaat ehk üldistatud
väide
reaalse maailma kohta, rida tõene väide reaalse maailma kohta)
•
Kas
nimega tabelis võib
olla mitu sama nimega veergu või
nimetuid veerge?
(ei, ei)
Kas
kahes erinevas nimega tabelis võib
olla sama nimega veerg?(jah)
•
Tabelite
loomisel kirjeldatavad erinevad kitsendused e piirangud. Millisedneed
on, kuidas neid kirjeldada ja kuidas nad mõjutavad tabelisse
andmete lisamist ja andmete muutmist .
CONSTRAINT
pk PRIMARY KEY (x) - x on
primaarvõti ehk
unikaalne , kohustuslik ja
indekseeritud veerg
CONSTRAINT
ak
UNIQUE (x) - x on alternatiivvõti ehk unikaalne ja kohustuslik
veerg
CONSTRAINT fk FOREIGN KEY (x) REFERENCES Y(y) - tabel on
nüüd veeru x abil
seotud
veeruga y tabelist Y.
•
Milline
on erinevate võtmete arv, mida baastabelis saab kirjeldada
(primaarvõti
– 0 või 1;
alternatiivvõti ja välisvõti
– 0 või
rohkem).
•
Kui
mitu veergu peab SQLi baastabeli võtmes
minimaalselt olema? (1)
•
Kas
primaarvõtme
kitsenduse deklareerimine veerule tagab automaatselt, et veerus peavad olema unikaalsed väärtused
ja veerus peab vää rtus
kohustuslikult olema? (jah,
jah)
•
Kui
mitu veergu peab võtmes
minimaalselt olema relatsioonilise mudeli kohaselt?
(0)
•
Veerutaseme
kitsendused vs. tabelitaseme kitsendused. (Tabelitaseme
kitsendust
tuleb kasutada, kui kitsendus hõlmab rohkem kui ühte
veergu,
tabelitaseme kitsendused
kirjutatakse tabelit luues kõige lõppu,
aga veerukitsendused kirjutatakse kohe peale veeru defineerimist).
•
Mida
tähendab,
et veerg on mittekohustuslik? (lubab
NULLe)
•
Kompenseerivad
tegevused, mida saab mää rata välisvõtme
kitsenduses jamis
mää ravad andmebaasisüsteemi
käitumise
viidete terviklikkuse vea korral. Kuidas nad toimivad , millises
olukorras nende kontroll käivitatakse ja millises mitte?ON
DELETE
NO ACTION :
Pärast kustutamist kontrollib. Kui üritada kustutada
PrimaryTable’ist
rida, millega on seotud mõni rida SõltuvTable’is,
siis ei lubata seda.
ON
DELETE
RESTRICT :
Enne kustutamist kontrollib.
Kui üritada
kustutada PrimaryTable’ist rida, millega on seotud mõni
rida SõltuvTable’is,
siis ei lubata seda.
ON
DELETE
CASCADE:
Kui kustutada PrimaryTable’ist rida, millega on seotud mõni
rida SõltuvTable’is,
siis kustutatakse kohe ka see rida SõltuvTable’ist.
Seda peaks kasutama, kui olemitüüpide vahel on kompostitsiooni
(
sõrm on käe komponent) või üldistusseos (isik võib olla
klient või
töötaja ).
ON
DELETE
SET
NULL: Saab
kasutada, kui PrimaryTable’is
Kandidaatvõti pole NOT NULL. Kui kustutada PrimaryTable’ist
rida, siis
kustutatakse automaatselt vastav Välisvõtme väärtus
SõltuvTable’ist.
ON
DELETE
SET
DEFAULT: Kui
kustutada PrimaryTable’ist
Kandidaatvõtmeveerust
rida, siis muudetakse
vastav Välisvõtmeveeru väärtus SõltuvTable’is
veeru DEFAULT väärtuseks.
ON
UPDATE
CASCADE:
Kui muuta PrimaryTable’is
Kandidaatvõtmeveerus väärtust, muutub see väärtus ka
SõltuvTable’i Välisvõtmeveerus.
ON
UPDATE
SET NULL:
Kui muuta PrimaryTable’is
Kandidaatvõtmeveerus väärtust, kustutatakse see väärtus
SõltuvTable’i Välisvõtmeveerus (pannakse asemele NULL).
ON
UPDATE
SET DEFAULT:
Kui muuta PrimaryTable’is
Kandidaatvõtmeveerus väärtust, muudetakse see väärtus
SõltuvTable’i Välisvõtmeveerus veeru DEFAULT väärtuseks.
-
Need määrangud
määravad
andmebaasisüsteemi
käitumise
viidete terviklikkuse vea korral. Kui viidete terviklikkuse viga ei
teki, pole vaja ka kompenseerivaid tegevusi läbi viia ja
andmemuudatus täidetakse ilma andmebaasisüsteemi poolse
vahelesegamiseta.
•
Deklaratiivne
vs. protseduurne terviklikkuse reeglite tagamine
(Deklaratiivsed kitsendused esitatakse CREATE TABLE või
ALTER TABLE lausetes, kuid protseduurne terviklikkuse reeglite
tagamine tähendab
trigerite ja andmebaasiserveris talletatud rutiinide loomist).
•
Mida
tähendab
RESTRICT või
CASCADE määrang andmebaasiobjekti kustutamise lauses ? (RESTRICT
– objekti ei
kustutata, kui on sellest sõltuvaid objekte; CASCADE – objekt
kustutatakse koos sõltuvate objektidega)
•
Vaated,
nende omadused ja kasutusvõimalused. Läbi milliste vaadete saab
baastabelites andmeid muuta? Vaade
on nimega vituaalne tabel, mis on tehtud baastabelite põhjal.
Vaated, mille põhjal tahetakse teha muudatusi andmebaasis, peavad
olema tehtud kasutades lauset WITH CHECK OPTION. Vaated kapseldavad
andmebaasi, sest peidavad kasutaja eest andmebaasi struktuuri.
Vaadetega saab andmeid esitada endale
sobivas formaadis.
•
Millise
lausega luuakse SQLis virtuaalseid tabeleid?
(CREATE VIEW)
•
Mida
tähendab
WITH CHECK OPTION määrangu
kasutamine vaadete kirjeldamise juures? (andmemuudatused
läbi vaadete peavad vastama vaate alampäringu tingimustele).
Teema
6•
Milliseid
SQL lauseid kasutatakse õiguste/rollide
jagamiseks ja äravõtmiseks kasutajatelt/rollidelt?
(GRANT/REVOKE)
- Mida tähendavad WITH GRANT OPTION ja WITH ADMIN OPTION määrangud GRANT lauses? (õiguse/rolli saaja saab seda teistele kasutajatele või rollidele edasi anda)
•
Mille
poolest erineb SQL keel ja selle aluseks olev andmemudel
relatsioonilisest andmemudelist? SQL
lubab NULLe ehk on kolmevalentne, relatsiooniline andmemudel on
kahevalentne. SQL ei kasuta termineid relvar, relatsioon, korteež,
atribuut, vaid tabel, rida, veerg. SQLi
aluseks on relatsiooniline andmemudel, aga mitte täpselt. SQL lubab
vaates mitut sama nimega veergu ja alati mitut samasugust rida,
NULLE.
•
Milline
on relatsioonilise mudeli ja SQLi vaheline seos?
(SQL andmebaasikeele väljatöötamisel
on lähtutud relatsioonilisest mudelist, kuid tulemuseks saadud
andmebaasikeel ei järgi täies
mahus relatsioonilise mudeli
nõudmisi)
Teema
7•
Infosüsteemi
arendamise etappide järjekord
klassikalises (kaskaadses) infosüsteemide
arendamise protsessis. Milline etapp eelneb ja järgneb
vahetult millisele teisele etapile. (strateegiline
analüüs,
detailanalüüs,
disain, ehitamine, rakendamine, hooldamine)
•
Strateegiline
analüüs:
eesmärgid
- määrata skoop,
allsüsteemid, arhitektuur, arendamise kava
tegevused
- allsüsteemide
tekstikirjelduste ja diagrammide visandamine, allsüsteemide
kasutusjuhtude mudelid, domeenimudel, registrite
kontseptuaalsed andmemudelid
dokumendid
- eesmärgid,
lausendid, põhiojektid ja -protsessid, tegutsejad, pädevusalad,
asukohad, tükeldus allsüsteemideks ja registriteks, allsüsteemide
eskiismudelid, registri eskiismudelid, ärireeglid.
tulemused
- tükeldus
allsüsteemideks, süsteemi ülevaade, mittetehniline lahendus ehk
kontseptuaalne andmemudel (nõuded süsteemile)
•
Detailanalüüs:
eesmärgid
- allsüsteemide täpsem analüüs ja modelleerimine ja disaini
ettevalmistus; Luua mittetehniline lahendus.
tegevused
- kasutusjuhtude mudeli tegemine, lepingute kirjutamine, CRUD
maatriksi koostamine
dokumendid
- kasutusjuhtude mudel, operatsioonide
lepingud , registrite
kontseptuaalsed andmemudelid
tulemused
- allsüsteemide ja nende poolt vajatavate registrite detailanalüüs,
CRUD
maatriks - Peab teadma, millised dokumendid koostatakse mingi allsüsteemi kirjeldamisel (pädevusala, funktsionaalne allsüsteem, register - need kõik detailanalüüsis), mingis infosüsteemi arendamise etapis.
•
Peab
teadma iseseisvas töös
koostatud dokumentide kohta, mis informatsiooni nad edasi annavad ja
milleks neid kasutatakse
(kasutusjuhtude mudel, kontseptuaalne andmemudel, seisundidiagramm,
tegevusdiagramm , andmebaasioperatsioonide lepingud, CRUD maatriks)
ning milline mudel on aluseks millise teise mudeli loomisele
(näiteks põhiobjektide järgi
leian funktsionaalsed allsüsteemid
ja registrid; seisundidiagrammi järgi leian paljud kasutusjuhud ja
paljude andmebaasioperatsioonide nimed).
•
Millist
UMLi diagrammi tüüpi
saab kasutada olemi-suhte diagrammi jaandmebaasi
diagrammi koostamiseks?
(klassidiagrammi)
•
Olemi-suhte
diagramm ja temaga seotud mõisted.•
Milline
on aine projektile mõeldes kasutusjuhtude ja seisundidiagrammiseos?
Iga
seisundiüleminek juhtub mingi kasutusjuhu käigus.
•
Milline
on aine projektile mõeldes operatsiooni lepingute jaseisundidiagrammi
seos?
Lepingud
kirjeldavad objekti seisundite muutmise korda. Kõik seisundid on
esitatud seisundidiagrammil. Üldiselt vastab igale seisundi
üleminekule oma operatsioon, mille kohta tehakse leping.
•
Milline
on aine projektile mõeldes operatsiooni lepingute ja kasutusjuhtudeseos?
Kasutusjuhud
toimivad vastavalt operatsioonide lepingutele.
•
Milline
on aine projektile mõeldes operatsiooni lepingute ja kontseptuaalseandmemudeli
seos? Kontseptuaalne
andmemudel kirjeldab nõudeid andmebaasis olevatele andmetele,
operatsioonid on nende nõuetega kooskõlas.
•
Mis
on klassifikaator? Millised on tuntud klassifikaatorid? (riigid,
inimkeeled,
valuutad,
töökohad,
soo tä
hised )
Klassifikaator on täpselt kirjeldatud, üksteist välistavate
ning number- või
tähtkoodiga
tähistatud
kategooriate põhjalik
ja korrastatud süsteem.
•
Millised
on rahvusvahelise klassifikaatori "ISO 5218 – Information technology -- Codes for the representation of human sexes" kirjeldatavad
võimalikud
väärtused?
(0-not known, 1-male, 2-
female , 9-not applicable)
Teema
9•
Mis
on kasutusjuhtude mudelis üldise kokkuvõtva kasutusjuhu
täpsemate teemadega kasutusjuhtudega asendamise analoog
andmebaaside maailmas? (tä
iendav normaliseerimine)
•
Normaliseerimine.-
Atribuutide hulkade vaheliste sõltuvuste tüübid
Funktsionaalne
sõltuvus A=>B
kus
A on determinant.
Funktsionaalne
sõltuvus on
triviaalne , kui ü=>B.
Multiväärtuslik
sõltuvus A=>=>B,
kus on kolm atribuutide gruppi A, B ja C ning igale AC väärtusele
vastab B, mis sõltub A-st, aga mitte C-st.
Ühendamissõltuvus
- kui relvari atribuutide hulkade R1…Rn projektsioonid saab
taasühendada ja saada esialgse relvari. Ühendamissõltuvus on
triviaalne, kui üks atribuutide hulkadest ongi terve relvar.
-
Täielik
funktsionaalne sõltuvus
- kui A=>B
puhul B sõltub funktsionaalselt A-st, aga ei sõltu A mingist
alamhulgast ning A sisaldab 1 või rohkem atribuuti ja B ainult ühte.
- Tegevused igale normaalkujule üleminekul.
1:
liiasuse tekitamine, et igasse lahtrisse
jääks 1 väärtus
2:
tuleb eemaldada
sõltuvused kandidaatvõtme
osadest, teha nt kaheks tabeliks, kus üks on teisega seotud
välisvõtme kaudu
3:
tuleb eemaldada ülekanduvad sõltuvused ja nende kohta teha eraldi
tabelid, mis oleks seotud välisvõtmete kaudu
Boyce/Codd:
tuleb eemaldada sõltuvused mõne kandidaatvõtme mingist osast
4:
tuleb luua vajalikud vahetabelid iga kuuluvuse jaoks eraldi mitte üks
vahetabel kõigi kuuluvuste jaoks
5:
ühendamissõltuvused tuleb teha eraldi tabeliteks, et poleks andmete
lisamise ja kustutamise anomaaliaid. Nt kolme veeruga tabelist teha
kolm eraldi kaheveerulist tabelit.
6:
vaadata, et oleks kõigis relvarites peale primaarvõtme (mis võib
olla mitu veergu) max 1 atribuut.
-
Kõigi
normaalkujude definitsioonid.
Nõudmised, millele
peab relvar vastama peale teatud normaalkujule viimist.Esimesel
normaalkujul - relvari iga legaalse väärtuse igas korteežis on iga
atribuudi kohta täpselt
üks
väärtus, mis
on selle atribuudi tüüpi. (igas lahtris 1 väärtus)
Teisel
normaalkujul - relvar on esimesel normaalkujul ja iga
mitte-primaarvõtme
atribuut on täielikult
funktsionaalselt sõltuv
primaarvõtmest.
Kolmandal
normaalkujul - relvar on teisel normaalkujul ja mitte ükski
mitte-primaarvõtme
atribuut pole ülekanduvate
sõltuvuste
kaudu seotud primaarvõtmega
(mitte-primaarvõti ei sõltu teisest
mitte-primaarvõtmest).
Boyce/Coddi normaalkuju (kui on mitu
kandidaatvõtit, mis on osaliselt kattuvad) - kui iga relvari
atribuut
sõltub
iga kandidaatvõtme
korral täielikult
kandidaatvõtmest,
kogu kandidaatvõtmest
ja ainult kandidaatvõtmest.
Neljandal
normaalkujul - kui mistahes relvaris oleva mittetriviaalse
multiväärtusliku sõltuvuse
X->->Y puhul on X relvari supervõti.
Viiendal
normaalkujul - kui iga selles oleva mittetriviaalse ühendamissõ
korral on iga R1, R2, …,
Rn relvari R supervõtmed.
Kuuendal
normaalkujul - kui relvarit pole võimalik kadudeta dekomponeerida.
Relvar peab olema 5ndal normaalkujul, tal peab olema kandidaatvõti V
ja 1 atribuut, mis ei sisaldu V-s.
Kadudeta
dekompositsiooni omadus: R1…Rn ühendamine annab tulemuseks R,
kusjuures R taastamiseks on vajalikud kõik
relvarid R1…Rn.
-
Milline on
kõige madalam normaalkuju, mille omamise korral võib
relvarikohta
ö elda ,
et see on "normaliseeritud"?
(esimene normaalkuju)
-
Mida
tähendab,
et relatsiooniline andmebaas on täielikult
normaliseeritud?
(kõik selles olevad relvarid on vä
hemalt viiendal normaalkujul)
-
Kas
normaalkujul N olev relatsioon on alati ka normaalkujul N+1? (ei)
-
Kas
normaalkujul N olev relatsioon on alati ka normaalkujul N-1? (jah)
- Heathi ja Fagini teoreemid.
Heath :
relvaris on atribuutide hulgad A, B ja C. Kui eksisteerib
funktsionaalne
sõltuvus A=>B, on relvar AB ja AC ühendamise
tulemus. A on kandidaatvõti.
Fagin: relvaris on atribuutide
hulgad A, B ja C. Relvar on AB ja AC ühendamise tulemus siis, kui on
multiväärtuslikud sõltuvused A =>=>B / C
-
Lihtsad reeglid normaalkuju määramiseks.1.
Kui relvar on Boyce/Coddi normaalkujul ja mõni
tema kandidaatvõti
on lihtne (1 atribuut), siis on see relvar ka neljandal normaalkujul
(aga ei pruugi olla viiendal normaalkujul).
2.
Kui relvar on kolmandal normaalkujul ja iga tema kandidaatvõti on
lihtne, siis on see relvar ka viiendal normaalkujul.
- Kuidas aitab andmebaasi disaini parandada ortogonaalse andmebaasi disaini printsiibi rakendamine? (Ortogonaalne disain - tehakse paljude asemel üks kokkuvõttev kasututsjuht, mis ühendatakase teda sisaldavate kasutusjuhtudega include seoste abil. Vähendab andmete liiasust üle erinevate tabelite/relatsiooniliste muutujate)
•
Kas
normaliseerimise ja ortogonaalse printsiibi rakendamine aitab vabaneda igasugusest andmete liiasusest?
(ei)
•
Kas
hea andmebaasi disaini põhimõ tete kohaselt peab igasugune andmete liiasus olema kontrollitud või
kontrollimata?
(kontrollitud)
Teema
10•
Kontseptuaalse
andmemudeli teisendusreeglid loogilise disaini andmemudeliks 1:1
mõlemad kohustuslikud: luua 1 tabel
1:1 üks kohustuslik, teine
mitte: luua 2 tabelit, välisvõti sinna, kus on kohustuslik
1:1
mõlemad mittekohustuslikud: luua 2 tabelit, välisvõti sinna, kuhu
lisatakse andmeid hiljem
1:M
: luua 2 tabelit, välisvõti sinna, kus on 1
M:N : luua vahetabel
koos välisvõtmete ja kitsendustega
rekursiivne
seosetüüp : iseendaga ühenduses, välisvõti
viitab sama tabeli
primaarvõtmele.
üldistussuhted : Optional (ei pea alati
kuuluma alamgruppi) või Mandatory (peab alati kuuluma alamgruppi), And (võib
kuuluda mitmesse alamgruppi) või Or (võib kuuluda ainult ühte
alamgruppi).
kaar
: ülemelement peab olema seotud ühe või teise alamelemendiga, aga
mitte mõlemaga korraga
- täielik/tõeline kaar - kaks
mittekohustuslikku välisvõtit, mida peab jälgima, et üks oleks
täidetud.
- lõhutud kaar - kaks eraldi ülemelementi, üks
kummagi alamelemendi jaoks
-
ühine/üldine kaar - tabelis on iga elemendi juures märge (veerg),
kumba alamgruppi ta kuulub.
•
Loogiline
disain:
eesmärgid
- Luua tehniline kirjeldus, mis arvestab andmebaasi aluseks oleva
andmemudeliga; saavutada valitud vahenditega lahendus, mis võimalikul
täpselt
rahuldab kujundatava keskkonna subjektide vajadusi.
tegevused
- struktuuri väljatöötamine pöörates tähelepanu konkreetsele
andmemudelile, kuid mitte platvormile (andmebaasisüsteemile).
Täiendav normaliseerimine, ortogonaalse disaini kasutamine, liiasus
minimaalseks ja kontrollituks Sisendiks on kontseptuaalne andmemudel
ja andmebaasioperatsioonide lepingud.
dokumendid
- lahenduse kirjeldus, täiendatud lepingud
tulemused
- loogiline andmemudel (tehniline lahendus, arvestab andmemudeliga nt
relatsiooniline), loogilise andmebaasiskeemi kirjeldus, täiendatud
lepingud (viited tabelitele ja veergudele). Loogilise disaini
tulemusena on tabelid viiendal normaalkujul.
•
Millised
on hea relatsiooni võtme
omadused?
(
tuttavlikkus - tal on tähendus, lihtsus - võimalikult vähe
komponente, stabiilsus - muutub vähe või üldse mitte, ei sisalda
kodeeritud informatsiooni)
•
Mis
on reaalsed kasutusjuhud, millal ja milleks neid luuakse? (reaalsed
kasutusjuhud on kasutajaliidesega kooskõlas ja kirjeldavad täpselt
seda, mida kasutaja teeb ja mis selle peale juhtub; luuakse DISAINI
käigus)
Teema
11•
Mis
vahe on loogilisel ja füüsilisel andmete sõltumatusel (mõisted
andmebaasisüsteemi
arhitektuurist)? Loogiline
andmete sõltumatus - andmebaasi kontseptuaalses skeemis tehtud
muudatus ei muuda kasutajale väljapaistvaid skeeme. Füüsiline
andmete sõltumatus - andmebaasi sisemises skeemis tehtud muudatus ei
muuda kontseptuaalset skeemi.
•
Millised
on töölaua-
ja serveri andmebaasisüsteemide
sarnasused ja erinevused?•
Mida
saab ja ei saa teha andmebaasisüsteemis MS Access (2013), kus on
kasutusel traditsiooniline Jet andmebaasimootor?
Kas seal saab või
ei saa luua tabeleid
(jah),
vaateid
(ei, aga salvestatud select
laused tegelikult loovad vaated),
indekseid
(jah),
trigereid
(ei),
salvestatud
protseduure
(ei, ainult 1 sql lausega)?
Kas seal saab
või ei saa luua ekraanivorme (jah),
trükiseid
(jah),
makroid(jah)?
Näiteks ei saa MS Accessis (2013) kasutada CREATE TRIGGER lauset
SQL trigerite loomiseks. Samas on alates MS Access (2013) võ
imalik siduda tabelitega andmete makrosid, mis võimaldavad
lahendada samu probleeme nagu SQL trigerid. Samuti ei saa seal luua
eraldi arvujada generaatori objekti (sequence generator) nagu nt
Oracles või
PostgreSQLs. Tuleb kasutada autonumber andmetüüpi.
MS Accessis pole võimalik
luua uusi tüüpe ja domeene (süsteem ei toeta CREATE TYPE ja
CREATE DOMAIN lauseid). MS Accessis saab luua baastabeleid, vaateid,
indekseid. MS Accessis saab ka luua CREATE PROCEDURE lausega lihtsaid
protseduure, mis sisaldavad ühte SQL lauset.
•
Kas
andmebaas ja andmebaasisüsteem
on sünonüümid?
(ei. Andmebaasisüsteem
on tarkvarasüsteem,
mis kontrollib kogu juurdepääsu
ühele
või
mitmele andmebaasile.)
•
Andmebaasisüsteemi
süsteemikataloog
–
kuidas seda kasutada ja kuidas seal andmed uuenevad?
(andmebaasisüsteem
uuendab seal andmeid
automaatselt,
kohe peale andmekirjelduskeele lause käivitamist
ehk kui mõni
kasutaja muudab andmebaasi struktuuri/käitumist või
annab/muudab/kustutab kasutajate/rollide õigused.
Süsteemikataloog on andmesõnastik ehk andmebaas andmebaasi kohta.)
•
SQL
lause töötlemine
enne täitmist – millistest sammudest see koosneb, millises
jä rjekorras neid samme läbitakse ning kes või mis neid samme
läbiviib?
Analüüs - lause
parsimine, analüüsi puu, semantiline analüüs, täpsustatud
analüüsi puu; Täitmisplaani koostamine - loogilise täitmisplaani
koostamine, füüsilise täitmisplaani koostamine; Täitmine.
•
Milline
on ü ldine strateegia loogilise täitmisplaani
optimeerimiseks?Andmete
hulka piiravad operatsioonid (projektsioon, piirang) üritatakse
teha
enne
ühendamise (joini) operatsiooni.
•
Millist
nime kannab SQL standardi järgi skeem, mis sisaldabsüsteemikataloogi
põhjal
tehtud vaateid? (INFORMATION_SCHEMA)
- Millised on tuntud andmebaasisüsteemid (kaubamärgid)?
Oracle ,
IBM DB2m Informix, MS SQL Server,
MySQL , MS Access, PostgreSQL
•
Andmebaasisüsteemide
ühisnimetajadTöölaua:
MS
Access, LibreOffice Base, Oracle
Database
Personal
Edition , Paradox
Väikesed
andmehulgad, 1 kasutaja korraga, toetab vähe OS-e.
Ülemineku:
Oracle
Express Edition (Oracle XE),
MS
SQL Server Express, Microsoft Data Engine e Microsoft SQL Server
Desktop Engine (MSDE).
Eesmärgiga
meelitada tavakasutajad serveriomasid kasutama, kahe vahel,
tasuta.
Serveri:
Oracle
Enterprise Edition,
MS
SQL Server, IBM DB2, Teradata, PostgreSQL, MySQL, MaxDB, Firebird,
Postgres Plus Advanced Server.
Rohkem
andmebaasiobjekti tüüpe, suuremad andmehulgad, arenenud
paralleeltöötlus, mitu kasutajat korraga, palju OS-e.
Teemad
12–13•
Füüsiline
disain:
eesmärgid
- Luua tehniline
kirjeldus, mis arvestab andmebaasisüsteemiga, mille abil andmebaas
realiseeritakse.
tegevused
- Andmebaasiobjektide
nimede, tüüpide täpsustamine, kitsenduste realiseerise vahendite
valimine, realisatsiooni kavandamine, transaktsioonianalüüs,
salvestusviiside valimine, valikuline denormaliseerimine,
turvameetmete kavandamine. Võib denormaliseerida.
dokumendid
- Tehniline
kirjeldus
tulemused
- Füüsiline
andmemudel ehk tehniline lahendus, mis arvestab andmebaasisüsteemiga.
- Korteeži loogiline aadress (relvari nimi, kandidaatvõtme hõlmatud atribuutide nimed, kandidaatvõtme väärtus).
•
Indekseerimine.
Millises olukorras on neid võimalik ja õige kasutada ja millises
mitte? (B-puu
indeksi loomist võib kaaluda veergude korral, kus on suhteliselt
palju unikaalseid väärtuseid ning mida kasutatakse sageli
päringute
tingimustes, aga
muudetakse harva, kui tabel on suur, aga päringud tagastavad
tavaliselt väga vähe ridu. Bitmap indeksit on kõige parem
kasutada suure andmemahuga (kuna indeksi andmemaht kujuneb
väikeseks), harva muudetavates tabelites. Bitmap indeksit tuleks
kasutada veergudel, kus on vähe erinevaid väärtuseid.)
•
Kas
andmebaasisüsteem
peaks alati eelistama päringule
vastamiseks indeksi kasutamist?
(ei, andmebaasisüsteem
peaks eelistama tabeli läbiskaneerimist
kui: tabel on väga
väike
– indeksi
lugemine ei vähenda oluliselt loetavate plokkide arvu või kui
tabel on suur. Päring tagastab suure hulga tabeli ridadest –
indeksi lugemise tõttu loetakse ühte
plokki korduvalt.)
•
Mida
tähendab
fraas "B-puu", kui räägime B-puu indeksitest?
(tasakaalustatud puu)
•
Millistele
veergudele loob enamik andmebaasisü steeme indeksi automaatselt? (primaarvõtme
või
unikaalsuse kitsenduse poolt hõlmatud)
•
Kas
indeksi loomine suurendab andmebaasi salvestamiseks vajalikukettaruumi
hulka? (jah)
•
Kuidas
kiirendada suure hulga ridade lisamist tabelisse? (kustutada
tabeliga
seotud
indeksid, lisada read, luua indeksid uuesti)
•
Mida
tähendab
ridade migreerumine andmebaasi sisemisel tasemel ja kassee
on töökiiruse seisukohast hea või
halb?
(Ridade migreerumine on see, kui rida ei mahu enam andmeplokki ära
ja läheb teise admeplokki, aga see on halb,
sest see muudab andmete otsimise aeglasemaks.)
•
Kuidas
mõjutab
andmete muutmise sagedus seda, kui tihedalt tulebandmeplokkidesse
sisemisel tasemel ridu paigutada?
Harva muudetavate
tabelite ja indeksite andmetele ei pea palju ruumi jätma, väga
sageli muudetavate tabelite ja indeksite andmed peaks olema
plokkides, kus on vaba ruumi 30%.
•
Millisesse
andmebaasi tasemesse (skeemi) kuuluvad erinevadandmebaasiobjektid?
(vaated välisesse,
baastabelid kontseptuaalsesse, indeksid sisemisse)
•
Kuidas
saab Oracles luua arvujada generaatorit (CREATE
SEQUENCE)
ja trigerit (CREATE
TRIGGER)?
•
Aktiivne,
sündmustele
reageeriv andmebaas –
millise
andmebaasiobjektiolemasolul
võib sellest rääkida?
(trigerid ja/või deklaratiivsed kitsendused)
•
Trigerid
(Oracle nä itel ).
Triger on andmebaasiobjekt, mis võimaldab andmebaasis toimunud
tegevuse mõjul käivitada mingid tegevused. Ei saa luua trigereid,
mis käivituks SELECT lause peale. Saab panna kas triger käivitub
BEFORE või AFTER muudatust. Lausetaseme triger sisaldab lauset FOR
EACH STATEMENT ja on ka vaikimisi. Reataseme triger
sisaldab lauset FOR EACH ROW
ja käivitub iga tabeli rea korral. OLD ja NEW näitavad muudatuse
algset ja hilisemat väärtust (ainult reataseme jaoks)
•
Millist
tüüpi
trigereid saab/ei saa Oracles kasutada? Milliste sündmuste
tulemusel triger käivitatakse ja millist tüüpi sündmustega ei
saa trigerit seostada?
(Pole olemas SELECT trigereid ega DURING trigereid.
Saab kasutada INSERT, UPDATE, DELETE korral.)
•
Oracles
trigeritega seotud "mutating table" probleem. (reataseme
trigeriga ei saa
SQL lauseid kasutades lugeda/muuta andmeid tabelis, mille muutmine
trigeri käivitas.
Lahenduseks on kasutada lausetaseme trigerit.)
•
Millise
fraasiga algab Oracles salvestatud protseduuri/trigeri/arvujadageneraatori
loomise lause? (CREATE
PROCEDURE / CREATE TRIGGER /
CREATE
SEQUENCE)
•
Kuidas
nimetatakse andmebaasisüsteemis
Oracle kasutatavatprotseduuride
keelt? (PL/SQL)
•
Millised
on hea disaini printsiibid pakettide (nagu neid saab näiteks
luua andmebaasisüsteemis Oracle) loomiseks ja neile vastutuste
jagamiseks? Tegemist on üldiste
hea tarkvara disaini printsiipidega (madal
sõltuvus –
low
coupling, kõrge
kokkukuuluvus – high
cohesion)
•
Milline
on kõige olulisem dokument, mille alusel leitakse
andmebaasiserveris talletatud rutiinid, mis tuleks andmebaasis luua?
(andmebaasioperatsioonide
lepingud)
•
Millised
on transaktsiooni neli põhilist omadust? (ACID
– atomaarsus,
terviklikkus, isoleeritus, kestvus/jätkuvus)
•
Milliste
käskudega
toimub SQLis transaktsioonide kinnitamine ja tühistamine? (COMMIT
ja ROLLBACK)
Teema
14•
Millistele
tingimustele vastavad tabelid on kõige
paremad denormaliseerimise kandidaadid?
(andmeid küsitakse
sageli, muudatusi tehakse harva)
- Milliseid tegevusi tehakse andmetabelite denormaliseerimise käigus ja mis on selle tulemus? 1:M seosetüübi puhul dubleeritakse mitte-võtmeveerge erinevates (baas)tabelites. Denormaliseerimise käigus dubleeritakse veerge või ühendatakse tabeleid, et vähendada päringutes vajalikku tabelite ühendamist. Denormaliseerimise jaoks annab kasulikku informatsiooni CRUD maatriks.
Võib kas asendada normaliseeritud tabelid denormaliseeritud tabelitega või lisada olemasolevasse normaliseeritud tabeleid sisaldavasse andmebaasi uued denormaliseeritud tabelid, mis täidetakse vastavalt vajadusele - siis kui neid on vaja kasutada.
- Milleks denormaliseerimist ette võetakse? (mõningate päringute kiirendamiseks)
•
Mitmendale
normaalkujule tuleks tabelid viia enne, kui kaaluda mõne
tabeli denormaliseerimist? (
viiendale normaalkujule)
•
Millised
on denormaliseerimise ohud? (pole
selge, millal tuleks lõpetada; põ
hjustab andmete muutmise
anomaaliate tekke; võib suurendada andmete muutmiseks kuluvat aega;
suurendab andmemahtu; võib minna vaja keerukamat süntaksit; võib
põ
hjustada vastuoluliste andmete sattumist andmebaasi; andmebaasi
kontseptuaalne skeem muutub kasutaja jaoks ebaselgemaks)































Kõik kommentaarid