MAINORI KÕRGKOOL
Juhtimise instituut
Annika Krutto
ANDMEANALÜÜS
SOTSIAALTEADUSTES Loengukonspekt
Tartu 2009
SISUKORD
SISSEJUHATUS 31. ANDMEANALÜÜSI põhimõisted 31.1 Üldkogum ja
valim 3
1.2. Valimi valikumeetodid 4
1.3. Mõõtmismeetod ja mõõtmisvahend 5
1.4.
Andmetabel 7
2. Valimit kirjeldav statistika 72.1. Andmete
graafiline kirjeldus 8
2.2. Andmete
arvuline kirjeldus 9
2.2.1. Paiknemiskarakteristikud 9
2.2.2. Hajuvuskarakteristikud 10
3. Kahe tunnuse ühine käitumine 113.1. Statistiline sõltuvus 11
3.2.
Monotoonne sõltuvus 12
3.3. Korrelatiivne sõltuvus 12
3.4. Lineaarne ühe argumendiga regressioonmudel 13
4. Üldkogumile tulemuste leidmine (üldistamine) 144.1.
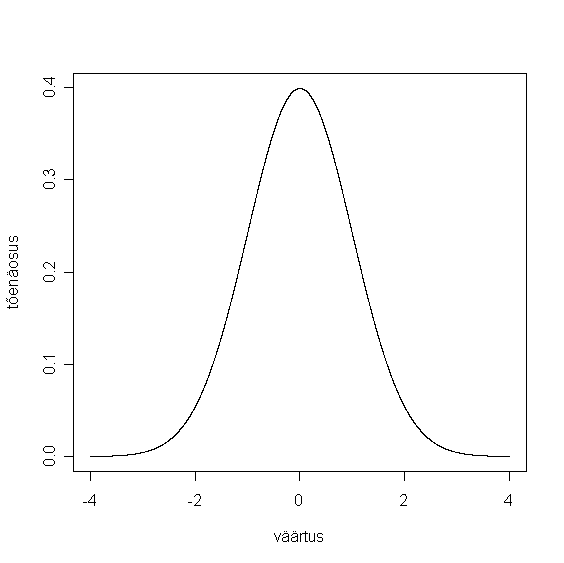
Normaaljaotus 14
4.2. Keskväärtuse (keskmise)
usaldusvahemik 16
4.3. Statistiliste hüpoteeside kontrollimine 16
4.3.1. Hüpoteesid ühe üldkogumi keskväärtusele 17
4.3.2. Hüpoteesid ühe üldkogumi
binaarse tunnuse väärtuse osakaalule 18
4.3.3. Hüpoteesid kahes sõltumatus üldkogumis keskväärtuste võrdlemiseks 18
4.3.4. Hüpoteesid kahes sõltuvas üldkogumis keskväärtuste võrdlemiseks 19
4.3.5. Hüpoteesid kahes üldkogumis binaarse tunnuse väärtuse osakaaludele 19
Lisa 1. Kriteeriumid sisuka hüpoteeside kontrollimiseks 20Lisa 2. Valik Studenti t-jaotuse täiendkvantiilide väärtuseid 20 SISSEJUHATUS
Käesolevas kursuses käsitletakse uuringus kogutud andmete
graafilist ja arvulist kirjeldamist, tunnustevahelise seoseid (korrelatsioon, regressioon ) ning selgitatakse, kuidas saadud
tulemusi üldistada üldkogumile. Seega kursuse läbinu peab oskama
1) kirjeldada kokkuvõtvalt uuringu käigus kogutud andmeid ja
2) anda selle põhjal statistiliselt usaldusväärseid üldistatud
tulemusi.
1. ANDMEANALÜÜSI põhimõisted
(Valik)uuringu läbiviimisel on kindlad etapid, iga etapp kasutab ja
vajab umbes kolmandiku uuringu ressurssidest:
Planeerimise alla kuuluvad järgmised mõisted ja etapid - probleemülesanne, statistiline ülesanne, üldkogum, loend , valim, tunnused, mõõtmismeetod ja -vahend;
Andmete kogumise all mõtleme andmete kogumist, kodeerimist jms, sisestamist, korrigeerimist;
Andmetöötlus on andmete statistiline töötlus, analüüs (interpretatsioon), uuringu väärtustamine, publitseerimine (esitamine).
1.1 Üldkogum ja valim
Vastavalt uurija eesmärgile määratletakse üldine uurimisobjekt
ehk üldkogum. Üldkogumiks on kõik objektid (näiteks
isikud, ettevõtted, riigid, taimed, linnud jne), kelle kohta uurija
soovib järeldusi teha. Üldkogum määratletakse nii ruumis kui
ajas, vastavalt uurimisülesandele. Üldjuhul üldkogum ei ole
täielikult kättesaadav (ajalistel, rahalistel või muudel
põhjustel), kuid väiksemates uuringutes võib see olla võimalik.
Valim on üldkogumist kaasatud üksikobjektid ehk isikud, keda
on vaadeldud, küsitletud, testitud , mõõdetud. Üldkogumi ja valimi
tähistamiseks ja kirjeldamiseks on levinud sümbolid - üldkogumi
mahtu (objektide arvu) märgitakse N, valimi mahtu
(uuritute arvu) märgitakse n.
Kui üldkogumiks on näiteks 20 000 elanikku, siis kirjutame N=20
000 ja kui võtame üldkogumist valimisse 1000 elanikku, siis
kirjutame n=1000. Alati me ei tea üldkogumi mahtu,
näiteks Lõuna-Eesti jäneste puhul on N määramata, sest
kõigi jäneste arvu ei saa me kunagi määrata. Valimimaht n
võib olla sel juhul suvaline arv, kui näiteks 61 kinnipüütud
jänest, n=61.
Kui üldkogum ja valim kattuvad, siis räägime kõiksest statistikast ehk kõiksest uuringust. Kõikses uuringus
kogutakse andmed üldkogumi kõikidelt objektidelt (isikutelt).
Kõikse uuringu puhul võime rääkida vahetustest
tulemustest üldkogumi kohta, valikuuringu
puhul räägime valimi põhjal saadud hinnangutest
üldkogumi kohta. Üldtuntuim kõikne uuring on rahvaloendus , kuid
olemas on ka äriregister, hooneregister, koolide register ,
juhilubade register… Kõikse uuringu eeliseks on tulemuste
täpsus, puudusteks on tavaliselt tunnuste vähesus ja uuringu
ülesehituse fikseeritus ning raske teostamine ja suur maksumus.
Valikuuringu eeliseks kõikse uuringu ees on odavus ja
objektide kättesaadavus, kuid puuduseks tulemuste ebatäpsus.
Eelneva põhjal tundub loogiline, et mida suurem on valim, seda
täpsemad on uuringu tulemused ka üldkogumile hinnangute andmiseks.
Tegelikult on valimimahust olulisemgi valimi valikumeetod.
Valimi maht ja valimi valikumeetod kokku määravad
valimi esinduslikkuse, mis määrab valikuuringu tulemuste
täpsuse ja üldistamisolulise üldkogumi jaoks. Jättes uuringu
planeerimisel uurimisobjekti ehk üldkogumi selgelt määramata võib
kogu valikuuringu tulemus osutuda kasutuskõlbmatuks (üldistavaid
järeldusi ei ole võimalik teha), sõltumata valimi mahust ja
valikumetoodikast.
1.2. Valimi valikumeetodid
Valimi esinduslikuks valikuks on mitmeid erinevaid meetodeid ,
statistika teoorias on koguni eraldi uurimisvaldkond valikuuring
(sampling theory), kus käsitletakse põhjalikult üldkogumi,
valimi mõisteid ja erinevate valikumeetodite omadusi. Valimi
valikumeetodid jagatakse kaheks, tõenäosuslikud ja empiirilised valikud :
- Tõenäosuslikud valikud eeldavad, et iga üldkogumi indiviidi kohta on teada tema valimisse sattusime tõenäosus. Tõenäosuslik valik eeldab loendi olemasolu (N on teada), millest uurija mingi valikueeskirja alusel kaasab uuritavad.
- Lihtne juhuvalik tähendab, et igal üldkogumi indiviidil on võrdne võimalus valimisse sattuda, vastav lihtsaim korrektne valikumeetod on süstemaatiline juhuslik valik mingist registrist, näiteks äriregistrist iga 100. ettevõtte, telefoniraamatust iga 50. elanik jm. Teine sobiv lahendus on valitavate objektide järjekorranumbri määramine juhuslike arvude genereerimisega. Tõenäosuslike valikute probleemiks on üldkogumi jaoks registri olemasolu ja sellele juurdepääs ning seejärel valitud objektidega koostöö saavutamine.
- Empiiriliste valikute puhul üldkogumi objektide valimisse sattumise tõenäosuses ei ole teada, seega sobib ka juhtudel, kus me ei tea N väärtust. Empiiriliste valikute korral on probleemiks tulemuste usaldusväärsus, valim ei ole juhuslik, saadud tulemused sõltuvad objektidest , keda uurija (ekspert) suudab või soovib valimisse kaasata. Valikuuuringu teoorias kuuluvad siia alla tuntumatest näiteks kvootide meetod ja ekspertvalik. Kvootide meetodis määratakse soovitava valimi struktuur tausttunnuste järgi (näiteks asutuse tüüp), ekspertvalikus on objektide valik täiesti subjektiivne, selle teeb ekspert. Praktikas, ennekõike sotsiaalteadustes on levinud lihtsamad empiirilised valikuviisid mugavusvalim ja lumepalli meetod:
- Mugavusvalimis, vahel nimetatakse ka haaramis- või võimalusvalim, kaasatakse objektid valimisse suvalisel ja mittesüstemaatilisel viisil (uurijale „mugavad”, kättesaadavad objektid), tavaliselt moodustavad valimisse need isikud, kes ise tahavad/viitsivad vastata.. Kuigi seda metoodikat ei saa rangelt võttes statistiliseks valikumeetodiks lugeda, on see praktikas üks kõige enam levinud valimi kogumise viise.
- Lumepalli meetodi idee on sarnane, erinevus on uurija poolt kaasatud objektide kasutamine valimisse rohkemate objektide värbamiseks („vasta ise ja jaga edasi ka sõpradele” meetod), seega valim kasvab nagu veerev lumepall. Selline metoodika on sageli kasutusel varjatud üldkogumi haaramiseks, kus uurijal on raske objektideni ise jõuda, näiteks narkomaanid, hasartmängusõltlased, prostituudid.
Ei saa tuua üheselt piisavat valimimahtu ehk uuringusse
kaasatavate isikute arvu, see sõltub ennekõike uuritavast
üldkogumist. Üldjuhul loetakse statistikas suureks valimid , kus
n>60, kuid statistiliselt ei saa nimetada konkreetset arvu
n, mis oleks alati „õige” (piisav) valimimaht. Teatud
eeldustel (etteantud vea täpsus vm) saab vajaliku n arvutada
moodustades vastava võrrandi minimaalselt nõutava valimimahu
määramiseks. Võib osutuda, et arvutustel põhinev valimimaht on
suurem kui üldkogumi maht, sel juhul peab soovitud täpsust
vähendama.
1.3. Mõõtmismeetod ja mõõtmisvahend
Mõõtmismeetod on viis, kuidas uurija kogub andmeid
ehk kasutab mõõtmisvahendit. Kuna sotsiaalvallas on
mõõtmisvahendiks enamasti ankeet -küsimustik, siis
mõõtmismeetoditest võib näiteks tuua ankeedi edastamine postiga ,
elektroonselt, käest-kätte jagades (või kuskile jätmine), vahetu
vestluse või telefonivestlus abil ja muud meetodid. Mõõtmismeetodi
valik sõltub uurija ajalistest ja rahalistest võimalustest.
Mõõtmisvahend on abivahend uurijat huvitavate
näitajate hindamiseks. Mõõtmisvahendiks on vahetult mõõdetavate
näitajate ehk mittelatentsete tunnuste puhul näiteks kaal,
termomeeter, joonlaud , kuid vahetult mittemõõdetavate näitajate
ehk latentsete tunnuste (näiteks rahulolu, motiveeritus) puhul
enamasti küsimustik. Ankeet-küsimustik koosneb
igapäevakeeles erinevatest küsimusest, kuid statistilises mõttes
moodustuvad tunnused, kusjuures tunnuseid võib tekkida rohkem kui
oli ankeedis küsimusi. Latentsete tunnuste hindamine ankeedi abil
tõstatab alati küsimuse tulemuste adekvaatsusest ehk küsimustiku
kui mõõtmisvahendi valiidsusest ja reliaablusest. Valiidsus ( validity ) tähistab metoodika (mõõtmisvahendi)
paikapidavust, kehtivust või adekvaatsust. Valiidsus näitab,
missugusel määral mõõdab metoodika seda, mida ta on plaanitud
mõõtma. Reliaabluse (reliability) all mõistetakse
kasutatava metoodika (mõõtmisvahendi) stabiilsust, järjekindlust,
kooskõla või töökindlust. Reliaablust hinnatakse nii ühe
metoodika korduval kasutamisel ühe uurija poolt kui ka ühe
metoodika ühekordsel kasutamisel erinevate uurijate poolt. Seega on
üliõpilase jaoks uue küsimustiku või testi koostamine alati
seotud probleemiga, kas loodud mõõtmisvahend on valiidne ja
reliaabne. Sellele küsimusele vastamine nõuab eraldi uurimist ja
põhimõtteliselt ei ole vaid ühe vaatluse ehk uuringu põhjal
võimalik vastust anda, seega on mõistlik kasutada olemasolevaid ja
üldise heakskiidu saanud küsimustikke. Lisaks eeltoodule ning
üldistele viisakus ja vormistusnõuetele peab ankeedi koostamisel
peab silmas pidama järgmisi ohtusid:
- Arvulistele küsimustele pigem ei anta vastusevariante, näiteks ei ole ankeedis mõistlik ette anda vanusevahemikku, staaživahemikku, see ebatäpsustab uuringu tulemusi. Arvtunnuste puhul on õige kasutada lahtiseid küsimusi kuid koos sobiva mõõtühikuga (aasta, tund, kg, …). Lahtise küsimuse puhul vastusevariandid puuduvad, kinnise küsimuse puhul on vastusevariandid ette antud.
- Arvulise küsimuse oodatava vastuse peab selgelt määratlemata, see peab olema võimalikult üheselt vastav, näiteks ei sobi „Kui tihti te spordite?” vaid pigem „Mitmel päeval nädalas tavaliselt tegelete spordiga?” või „Mitu tundi päevas te keskmiselt tegelete spordiga (füüsilise koormusega)?“ .
- Mittearvulistele küsimustele pigem peab ette andma vastusevariandid, muidu võime saada liiga palju või segaseid vastusevariante (näiteks hobina võib vastata nii sport , korvpall kui tugitoolisport).
- Hinnangute küsimisel on ohtlik vastusevariant „ei oska öelda”, võimalusel tasuks sellest hoiduda, sest vastaja võib seda erinevalt mõista (ei viitsi vastata, kardab vastata, jättis ükskõikseks, ei saa küsimusest aru või ei osalenud hinnataval tegevusel).
Lisaks
eeltoodud tunnuste jaotusele ( latentsed -mittelatentsed,
kinnised- lahtised ) eristatakse veel sisulisi, abi- ja
tausttunnused. Sisulised tunnused aitavad kaasa probleemülesande
(latentse näitaja) lahendamisele, abitunnused aitavad määrata
vastaja isikuandmeid (näiteks amet, sugu, vanus) ning tausttunnused
uuringu üldandmeid (uuringu läbiviimise koht, aeg jms).
Andmeanalüüsis jagatakse vastavalt võimalikele vastusevariantidele
ehk väärtustele tunnused järgmistesse klassidesse:
1.4. Andmetabel
Kõik uuringus kogutud andmed tuleb analüüsimiseks sisestada
tabelina nii, et iga objekti puhul saame üheselt leida kõigi talle
vastavate tunnuste väärtused. Saadud andmetabelis (objekt-tunnus maatriks ) iga rida esindab ühte uuritavat objekti
(mõõtmistulemusi) ja iga veerg (tulp) esindab ühte tunnust
(küsimust). Andmetabel aitab saada üldpildi tulemustusest,
samuti võimalikest sisestusvigadest ja puuduvatest vastustest.
Levinud on sõnalised vastusevariandid andmetabelis kodeerida,
näiteks rahuoluküsimused kodeeritakse 5-palli (7-palli vm)
skaalaks. Järjestustunnuste puhul ongi kodeerimine mõistlik,
sest saame teha kõkkuvõtvaid arvutusi (keskmine rahuolu , keskmine
haridustase), kuid analüüsija ei tohi tulemuste interpreteerimisel
kaotada seost tegelike vastusevariantidega. Nominaalsete ja
binaarsete tunnuste puhul on kodeerimine küll mugav kuid tekib
oht andmete töötlemisel automaatselt sõnu „kokku
arvutada”, näiteks esitatakse analüüsis lemmikhobi või soo
keskmine, mis ei oma aga mingit sisulist tähendust.
Andmetabelis võib olla erinevaid vigu, toome siin välja
süstemaatilised ja juhuslikud vead. Süstemaatiline viga on üldjuhul
mõõtmisvahendi viga, see tähendab, et kõikidel vastajatel on
vastused mingi süstemaatilise veaga. Juhuslikud vead võivad tekkida
kas vastaja või andmete sisestaja hajameelsusest. Parandada saab
andmetabelis üldjuhul vaid sisestaja vigu, selleks peab andmete
algallika kindlasti andmetabelis vastajaga siduma, ankeet-küsitluse
puhul tähendab see ankeetide nummerdamist ning andmetabelisse
vastava järjekorranumbri lisamist.
2. Valimit kirjeldav statistika
Üldiselt, kindlasti suuremate valimite puhul, ei ole andmetabel
loomulikult informatiivne, kogutud andmetest ülevaate saamiseks
kasutame kirjeldavat statistikat. Andmete esitamiseks
kokkuvõtlikul, sisutihedal, ülevaatlikul kujul kasutatakse
graafilisi vahendeid ( tabelid , diagrammid) ja arvulisi näitajaid
(keskmine, standardhälve jm).
2.1. Andmete graafiline kirjeldus
Graafilise kirjelduse eesmärk on lihtsustada info lugemist või
esitada uudne kokkuvõtte. Tabel või diagramm, mis on annab
samaväärse info juba esitatud tekstiga, ei oma mõtet. Töös ei esitata elementaarseid tabeleid ja diagramme (info, mis tekstina
oleks lühem või samaväärne), samuti peaks vältima info kordamist
ehk töö „venitamist“. Iga tabeli, diagrammi ees on tavaliselt
sissejuhatav lause ning järel sisukas (eriline väärtus, huvitav
seos vms) kommentaar, mitte ümberjutustus.
Sagedustabel võtab andmetabelist tunnuse jaoks kokku mitmel
objektil mingit tunnuse väärtust esineb ehk esitab vastava
sageduse. Sagedustabeli koostamiseks peame teadma milliseid
väärtusi tunnus võib omandada ja kui sageli iga väärtus esines
(näiteks mitmel üliõpilasel on hallid silmad). Sagedustabelis
esitatakse tavaliselt absoluutne sagedus (sagedus) ehk
väärtusele vastav objektide arv; suhteline sagedus
(osakaal) ehk absoluutne sagedus jagatakse objektide koguarvuga ja kumulatiivne sagedus (sageduste summa), kus absoluutsed sagedused liidetakse, sobib kõige paremini arvtunnuste korral.
Sagedustabeli võib koostada nii ühe, kahe kui ka kolme tunnuse
jaoks. Kui tegemist on pideva arvtunnusega, siis kasutame
sagedustabeli koostamisel väärtuste grupeerimisest. Tunnuse
väärtuste grupeerimisel on sobiv valida:
- klasside pikkused võrdsetena (vajadusel võib otsmised klassid jätta lahtiseks);
- klassipiirideks ümmargused arvud;
- klasside arvuks suurusjärk ruutjuur objektide arvust, aga mitte rohkem kui 20 klassi;
- klasside sagedused võrreldavatena.
Tabelites toodud infot saab näidata ka diagrammidena, mõistlik
on esitada kas tabel või diagramm, mitte mõlemaid järjest. Tabeli
või diagrammi valikul peab arvestama, kumb on lugejale ülevaatlikum
ja paremini infot edastav, kusjuures esitatavad tabelid, diagrammid
ei tohi olla liiga vähest infot sisaldavad (näiteks ainult
vastanute soo kirjeldamiseks pole mõtet ei tabelit ega diagrammi
tuua). Levinud on ringdiagramm, kus ring kui tervik on
vastavalt tunnuse väärtuste esinemistele jaotatud sektoriteks,
tulpdiagramm, kus ühel teljel on tunnuse väärtused
(väärtuste grupid) ning teisel teljel vastav sagedus (osakaal).
Tulpdiagrammi võime teha ka osadele tunnuste võimalikele
väärtustele, kuid ringdiagramm näitab alati terviku jaotumist osadeks ehk väärtuste jaotumist kogu valimi kohta. Pidevale
tunnusele saame ring- või tulpdiagrammi teha vaid gruppidele,
mitte tunnusele väärtustele. Keskmiste illustreerimiseks sobib
ennekõike joondiagramm, kus vertikaaltelg esitab mingit
keskmist või ka protsenti (muutus, osatähtsus või indeks), samas
kui horisontaalteljel on kas mingi sõnalise tunnuse väärtused või
ajaühikud.
2.2. Andmete arvuline kirjeldus
Lisaks (sagedus)tabelitele ja graafikutele kasutakse ennekõike
arvtunnuste kokkuvõtvaks kirjeldamiseks arvulisi näitajaid.
Karakteristikuid, mis annavad kokkuvõtvat infot valimi väärtustest
(väärtuste paiknemisest arvteljel ) nimetatakse
paiknemiskarakteristikuteks, karakteristikuid, mis annavad infot
valimi väärtuste omavaheliselt paiknemisest (erinevustest,
sarnasustest), nimetatakse hajuvuskarakteristikuteks.
2.2.1. Paiknemiskarakteristikud
Mood on tunnuse suurima sagedusega väärtus (“moodsaim”).
Moodi on võimalik leida iga tüüpi tunnuse puhul. Mood võib
olla nii arvuline kui mittearvuline, mood võib tunnusel ka
puududa, kui moode on kaks, siis on tunnus bimodaalne . Pideva tunnuse
puhul saab määrata moodklassi, pidevale tunnusele
ühearvulist moodi leida ei saa (ei ole mõtet). Miinimum ja
maksimum on vastavalt valimis esinenud tunnuse väikseim
ja suurim väärtus.
Järjestades objektide tunnuse väärtused miinimumist maksimumini
saame tunnusele variatsioonrea. Seega saame variatsioonrea
leida vaid arv- ja järjestustunnustele. Variatsioonrea keskpunkti nimetame mediaaniks. Kui objektide arv on paaritu, siis on
mediaaniks variatsioonrea keskel asuv liige (järjekorranumbriga
(n+1)/2). Kui objekte on paarisarv, siis on mediaaniks
variatsioonrea keskel asuvate liikmete poolsumma (nende vahel asuv
väärtus). Mediaan jaotab variatsioonrea kaheks osaks: alumiseks
(siia kuuluvad mediaanist väiksemad väärtused) ja ülemiseks (kuhu
kuuluvad mediaanist suuremad väärtused). Variatsioonrea alumise
poole mediaani nimetatakse alumiseks ehk esimeseks kvartiiliks,
variatsioonrea ülemise poole mediaani ülemiseks ehk kolmandaks kvartiiliks. Mediaan ja kvartiilid jaotavad variatsioonrea neljaks osaks, millest igasse kuulub (ligikaudu) neljandik kõigist
variatsioonrea liikmetest. Lisaks kvartiilide kasutatakse (põhiliselt
majanduses) ka kvintiile ja detsiile, kvintiilid
jagavad variatsioonrea viieks võrdseks osaks, detsiilid jagavad
variatsioonrea kümneks võrdseks osaks.
Aritmeetilise keskmise leidmisel liidetakse kõikide objektide
tunnuse väärtused ning jagatakse objektide arvuga. Aritmeetiline
keskmine on väga tundlik üksikute erandlike väärtuste suhtes,
seetõttu peab alati kommenteerima lisaks vähemalt standardhälbe
(variatsioonkordaja). Praktikas vähemlevinud kuid aritmeetilisest
keskmisest täpsem on geomeetrilise keskmine, mille leidmiseks
korrutatakse kõik väärtused (n väärtust) omavahel ja
võetakse saadud korrutisest n- juur . Aritmeetilise keskmine on
üldisema kaalutud keskmise erijuht , mille puhul iga korrutame
talle antud kaaluga, liidame kõik korrutised ning jagame kaalude summaga. Valemid vastavate keskmiste leidmiseks on järgmised:
Aritmeetiline keskmine
Geomeetriline keskmine
Kaalutud keskmine
Tulemuste kommenteerimisel võib arvestada, mida sarnasemad on
aritmeetiline keskmine, mediaan ja mood, seda sarnasemad on suurem
osa tunnuse väärtuseid ja seda rohkem võime uskuda ka
aritmeetilist keskmist. Ka miinimum, alumine kvartiil, ülemine
kvartiil ja maksimum aitavad hinnata andmete ühtsust ning otsustada,
kas valimis on üksikuid erandlike väärtusi (erindeid). Kui
valimis on uuritaval tunnusel üksikuid erindeid või kõik
väärtused liiga erinevad, siis võib valim olla üldkogumile
järelduste tegemiseks, üldistamiseks liiga ebaühtlane. Hindamaks
konkreetselt uuritava tunnuse ebaühtlust või hajusust on kasutusele
võetud vastavad hajuvuskarateristikud.
2.2.2. Hajuvuskarakteristikud
Kõige
lihtsam tunnuse väärtuste hajuvust kirjeldav näitaja on haare .
Haare on tunnuse maksimumi ja miinimumi vahe. Lisaks haardele
leitakse sageli ka kvartiilidevaheline haare, mis on tunnuse
ülemise ja alumise kvartiili vahe. Kvartiilidevahelist haaret
kasutakse erandlike väärtuste mõju kindlaks tegemisel. Mida
väiksem on haare (kvartiilidevaheline haare), seda sarnasemad ehk
vähemhajusad on tunnuse väärtused. Kõige levinum valimi hajuvuse hindaja on valimi standardhälve, mis näitab, kui erinevad on
tunnuse väärtused valimi erinevatel objektidel. Standardhälve
on tunnetuslikult tajutav kui tunnuse üksikväärtuste keskmine
erinevus tunnuse aritmeetilisest keskmisest. Mida rohkem on
tunnusel keskmisest erinevaid (hälbivaid) väärtusi ja mida
suuremad on need hälbed, seda suurem on tunnuse standardhälve ja
vastupidi. Kui kõigil objektidel on samad tunnuse väärtused, siis
on tunnuse standardhälve 0. Standardhälbe arvutatakse järgmiselt:
Normaalseks peetakse hajuvust, kui standardhälve on alla poole
vastavast aritmeetilisest keskmisest, kui standardhälve on üle
poole, siis öeldakse, et tunnuse väärtused on hajusad (ei ole
aritmeetilise keskmise lähedal). Kui standardhälve on tugevasti
alla poole aritmeetilisest keskmisest, siis on tunnuse väärtused
vähehajusad ehk väga sarnased (ka aritmeetilise keskmisega).
Kirjeldatud põhimõtte alusel on hajuvusnäitajana kasutusel
variatsioonkordaja
mis leitaks standardhälbe ja aritmeetilise keskmise suhtena ja
üldiselt avaldatakse %-na. Kui variatsioonkordaja on kuni 50%, siis
tunnus normaalse hajuvusega (keskmine kirjeldab tegelikku , tüüpilist
väärtust), kui tunduvalt üle 50%, siis tunnus liiga hajus.
3. Kahe tunnuse ühine käitumine
Lisaks tunnuste ühekaupa uurimisele võivad uurijat huvitada
tunnustevahelised seosed ehk kas ühe tunnuse käitumine mõjutab
teist tunnust, näiteks kas koolituskulude kasvades suurendab
töötajate rahuolu või vastupidi kas rahuolu väheneb näiteks
tööruumides müra suurenedes. Üldiselt, sõltuvate ehk seotud
tunnustega puhul on ühe tunnuse käitumise järgi võimalik hinnata
teise tunnuse käitumist. Sõltuvuse puhul tekivad küsimused, kui
tugev on sõltuvus, mis suunas on sõltuvus, kui oluline on sõltuvus
ja kuidas seda sõltuvust matemaatilise seosena avaldada?
Kõige üldisem seos, kus öeldakse vaid, kas on sõltuvus või
mitte, suunda ega tugevust ei saa leida, on statistiline sõltuvus.
Mittearvuliste nominaalsete tunnuste puhul saamegi rääkida vaid
statistilisest sõltuvusest. Arvuliste ja järjestustunnuste puhul
hindame monotoonsest ja selle erijuhtu , korrelatiivset
sõltuvusust. Monotoonset sõltuvuse tugevust ja suunda
iseloomustajana on levinuim Spearmani astak - korrelatsioonikordaja , korrelatiivsele seosele Pearsoni
ehk lineaarne korrelatsioonikordaja r. Regressioonanalüüs
tegeleb tunnustevaheliste seoste funktsionaalse kirjeldamisega (ehk
matemaatilise võrdusena kirja panemisega) ning selle seose täpsuse,
kasulikkuse ja olulisuse hindamisega.
3.1. Statistiline sõltuvus
Statistiline sõltuvus on kõige üldisem tunnustevaheline seos, mida
kasutatakse eelkõige nominaaltunnuste korral. Seose olemasolu
hindamiseks kasutatakse kahemõõtmelist sagedustabelit, mida
vaatasime valimi graafilise kirjeldamise juures. Tunnustevahelise
seose graafiliseks uurimiseks on mõistlik kasutada sagedustabelis
üldisi ja tinglike osakaale, sel juhul nimetatakse tabelit
jaotustabeliks. Kui tunnused on sõltumatud, siis peaksid suhtelised
sagedused olema jaotunud üle ridade või veergude ühtlaselt ehk
ridade suhtelised sagedused võrduma marginaalsete suhteliste sageduste reaga ja veergude suhtelised sagedused marginaalsete
suhteliste sageduste veeruga. Kui nii ei ole ja vastav erinevus
(ebaühtlus) on piisavalt oluline, siis on tegemist sõltuvate
tunnustega. Olulise hindamiseks kasutatakse hii-ruut
statistikut, tähis:
Selle statistiku kasutamiseks peab kehtima eeldus, et iga
lahtri oodatav absoluutne sagedus on vähemalt 5. Statistik
annab väärtuse seose olulisuse hindamiseks, kuid seose tugevuse
hindamiseks on levinuim näitaja Crameri V:
kus n on valimimaht, m on esimese tunnuse võimalike
väärtuste arv ning k on teise tunnuse võimalike väärtuste
arv. Crameri V väärtus on alati 0 ja 1 vahele, mida lähemal
on väärtus 1-le, seda tugevamalt on uuritavad tunnused seotud.
3.2. Monotoonne sõltuvus
Monotoonset sõltuvust saab määrata järjestus- ja arvtunnuste
puhul, seega ei sobi see nominaalsete ja binaarsete tunnuste jaoks.
Monotoone sõltuvus tähendab, et ühe tunnuse väärtuse kasvades
või kahanedes ka teise tunnuse väärtused kasvavad või kahanevad.
Monotoonset sõltuvust mõõtvad kordajad muutuvad vahemikus -1 kuni
1. Seosekordaja on positiivne, kui tunnused muutuvad samasuunaliselt – tegemist on positiivse monotoonse suhtega. Kordaja on negatiivne,
kui tunnused muutuvad vastassuunaliselt – tegemist on negatiivse
monotoonse suhtega. Kui seosekordaja on null, siis monotoonne
sõltuvus tunnuste vahel puudub. Mida suurem on seosekordaja
absoluutväärtus, seda tugevam on monotoonnse sõltuvus. Kordame, et
kordaja on sisutühi, kui vähemalt üks tunnustest on nominaalne või
binaarne. Levinuim monotoonse sõltuvuse hindaja on Spearmani
astak-korrelatsioonikordaja (Spearmanni rho),
vastav valem avaldub:
Selgitame, et kordaja arvutamisel järjestame objektid vastavalt ühe
tunnuse väärtuste kasvamisele (i), ning teeme selgeks,
missugune oleks igale väärtusele vastav teise tunnuse koht selle
tunnuse variatsioonreas (j(i)).
3.3. Korrelatiivne sõltuvus
Korrelatiivne lineaarne sõltuvus sobib ennekõike kahe pideva
(paljude väärtustega) arvtunnuse vahelise seos hindamiseks,
praktikas kasutatakse ka alates järjestustunnusest, millel vähemalt
5 võimalikku väärtust.
Korrelatsiooni puhul hinnatakse tunnuste vahel esinevat lineaarse
seose suunda ja tugevust, visuaalselt annab sellest ülevaate
hajuvusdiagramm (korrelatsiooniväli). Kui hajuvusdiagrammil punktid
paiknevad tõusvas või langevas “pilvekeses”, siis viitab see ühisele lineaarsele seosele tunnuste vahel. Täpsema
hinnangu seose tugevusesele ja suunale saame kas eelpool toodud
Spearmani astak-korrelatsioonikordaja või lineaarse ehk
Pearsoni korrelatsioonikordaja r abil, vastav
arvutusvalem avaldub:
Lineaarsel korrelatsioonikordajal on järgmised omadused:
- Väärtus asub –1 ja 1 vahel, -1≤ r ≤1.
- Kui tunnused on kasvavalt seotud, siis r>0, kui tunnused on kahanevalt seotud, siis r60 võime kasutada ka normaaljaotust, sest sel juhul
t-jaotus ja normaaljaotus praktiliselt kattuvad). T-jaotuse
täiendkvantiile (loengus antud tabelis) kasutades saame üldkogumi
keskväärtuse usaldusvahemiku alumise ja ülemise usalduspiiri
järgmiselt:
ja .
Toodud valemites
on vastavalt tunnuse keskmine valimis, t-jaotuse
olulisusnivoole a-le vastav täiendkvantiil, tunnuse
standardhälve valimis ja valimi suurus.
4.3. Statistiliste hüpoteeside kontrollimine
Üldkogumi kohta esitatud oletusi nimetame hüpoteesideks. Otsus,
kumb väide ehk hüpotees üldkogumis kehtib, langetatakse valimi
põhjal. Teaduste areng toimubki üldreeglina nii, et teoreetikud sõnastavad teoorial põhinevad hüpoteesid (teaduslikud oletused),
praktikud teevad vastavad mõõtmised ja püüavad neid hüpoteese
kas tõestada või kummutada. Selleks, et kasutada matemaatilise
statistika metoodikat erinevatest valdkondadest pärinevate
hüpoteeside kontrollimiseks, tuleb vastav hüpotees tõlkida
statistika keelde ehk sõnastada vastav statistiline hüpotees. Statistilised hüpoteesid esitatakse üksteist välistavate
väidete paaridena , seega alati saab neist kehtima jääda
vaid üks. Sisukaks hüpoteesiks (tähis H1) on
väide, mida soovime tõestada, nullhüpotees (tähis H0)
on sisukale hüpoteesile vastupidine väide. Peab meeles pidama, et
nullhüpoteesi ei saa kunagi tõestada, kui sisukas hüpotees
jääb tõestamata (vastu võtmata), siis peame jääma nullhüpoteesi
juurde (kuid ei loe seda tõestatuks).
Hüpoteeside kontrollimisel ehk otsuse vastuvõtmisel võime teha
vea, kuna valim on juhuslik ning valimi tulemus vaid hinnanguline. Otsustamisel tekkivad võimalused võime kokku võtta järgnevalt:
Tegelikkuses kehtib üldkogumis nullhüpotees
Tegelikkuses kehtib üldkogumis sisukas hüpotees
Meie loeme valimi põhjal õigeks nullhüpotees
Õige otsus
Teeme vea, mida nimetatakse teist liiki veaks , tähis β
Meie loeme valimi põhjal õigeks sisuka hüpotees
Teeme vea, mida nimetatakse esimest liiki veaks, tähis α
Õige otsus
Kõige ohtlikum variant on valimi põhjal sisuka hüpoteesi ehk mingi
kasuliku või riskantse väite tõestatuks lugemine, kui see
üldkogumis tegelikult ei kehti. Sellist eksimust nimetatakse esimest
liiki veaks, millele vastav suurim lubatud tõenäosus antakse
eelpool tutvustatud olulisusnivooga a. Kordame, et valimist
leitud tegelikku esimest liiki vea tegemise tõenäosust nimetatakse
olulisustõenäosuseks.
Hüpoteese saame, kas ühe üldkogumile keskväärtusele või
osakaalule mingi etteantud arvu suhtes või kahe erineva
üldkogumi keskväärtuste või osakaalude võrdlemiseks.
4.3.1. Hüpoteesid ühe üldkogumi keskväärtusele
Hüpoteese üldkogumi keskmisele võime sõnastada mingi uurija poolt
etteantud arvu suhtes või mingi kahe üldkogumi vahel. Väite
sõnastuse võib olla erinev, kas kahepoolsed hüpoteesid –
keskmine on/ei ole võrdne etteantud arvuga või ühepoolsed
hüpoteesid – keskmine on suurem/väiksem etteantud arvust.
Üldisemalt, tähistades keskväärtuse ja
uurija poolt etteantud arvu c, võime kirjutada kolm
hüpoteesipaari:
Kahepoolne hüpotees
Ühepoolsed hüpoteesid
Toodud ühepoolsetes hüpoteesipaarides võime nullhüpoteesis
kasutada ka lihtsalt võrdust, sest tulemusena huvitab meid vaid
sisuka hüpoteesi kehtimine või mittekehtimine. Keskväärtuse kohta
käivaid hüpoteese kontrollitakse t-jaotuse ehk
t-testi abil, vastav statistik arvutatakse
järgmiselt:
kus n,ja
s on vastavalt valimi maht, keskmine ja standardhälve ning c
on etteantud arv, mille suhtes sisukas hüpotees on püstitatud.
Lihtsustatult võime öelda, et kui arvutatud T on liiga
väike, siis jääb kehtima nullhüpotees, kui T on piisavalt
suur, siis saame vastu võtta sisuka hüpoteesi. Otsustamise
kriteeriumid esitame kokkuvõtvalt kõikidele hüpoteesiliikidele lisas 1 toodud tabelis, kus α on uuringu läbiviija poolt etteantud
lubatud eksimistõenäosus.
4.3.2. Hüpoteesid ühe üldkogumi binaarse tunnuse väärtuse osakaalule
Lisaks oletustele keskväärtuse kohta pakub sageli huvi mingi
tunnuse jaotumine üldkogumis, siin on oluline teada, et hüpoteeside
püstitamise eelduseks on suur valim, n>60. Hüpoteeside
püstituses tähistame binaarse tunnuse väärtuse osakaalu üldkogumis p ja uurija etteantud osakaalu c:
Kahepoolne hüpotees
Ühepoolsed hüpoteesid
Binaarse tunnuse väärtuse osakaalude kohta käivaid hüpoteese
kontrollitakse samuti t-jaotuse ehk t-testi
abil, vastav statistik arvutatakse järgmiselt:
kus
on valimis binaarse tunnuse väärtuse osakaal (soodsate tulemuste
arv k jagatud valimi mahuga n) ning c on
etteantud osakaal, mille suhtes hüpoteesi püstitame. Otsustamise
kriteeriumid esitame kokkuvõtvalt kõikidele hüpoteesiliikidele
lisas 1 toodud tabelis, kus α on uuringu läbiviija poolt etteantud
lubatud eksimistõenäosus.
4.3.3. Hüpoteesid kahes sõltumatus üldkogumis keskväärtuste võrdlemiseks
Kahes üldkogumis keskväärtuste võrdlemisel peame teadma, kas
tegemist on sõltumatute või sõltuvate valimitega (üldkogumitega).
Sõltumatud valimid saame, kui valimid võetakse kahest
omavahel mittekattuvast üldkogumist (soome elanikud, eesti elanikud
või ravimit manustanud/mittemanustanud patsiendid) või ühest
üldkogumist võetud valim jagatakse kaheks erinevaks grupiks (mehed,
naised või noored, vanad). Hüpoteeside püstituses tähistame ühe
üldkogumi keskväärtuse
ja teise üldkogumi keskväärtuse ,
seega:
Kahepoolne hüpotees
Ühepoolsed hüpoteesid
H0: .
H1: .
H0: .
H1: .
H0: .
H1: .
Kui mõlemas valimis on vähemalt 30 vastanut, siis võime sisuka
hüpoteesi tõestamiseks kasutada lisas 1 toodud kriteeriume, kus
vastav statistik T arvutatakse järgmiselt:
kus
on vastavalt tunnuse keskmised valimites, s1 ja s2
on vastavalt tunnuse standardhälbed valimites ning n1
ja n2 on vastavalt valimite mahud.
Kui ühes või mõlemas grupis on alla 30 vastanu, siis
eelmisest valemist ei piisa, kindlasti peame kontrollima järgmisi
eeltingimusi:
- Kas tunnuse väärtused väikeses valimis alluvad normaaljaotusele – kui see tingimus ei ole täidetud, ei tohi t-testi teha.
- Kas tunnuse dispersioonid valimites on võrdsed või mitte – see ei mõjuta t-testi lubatust, vaid kontrollimiseks kasutatav metoodika muutub.
Nende tingimuste kontroll teoreetiliselt on mahukas, seepärast
vaatame seda vaid praktikas MS Exceli abi, kus esimest
tingimust kontrollime visuaalselt tunnuse histogrammi abil ning teist
vastava testi abil (vartest).
4.3.4. Hüpoteesid kahes sõltuvas üldkogumis keskväärtuste võrdlemiseks
Sõltuvate valimitega (üldkogumitega) on tegemist kui uurime
samu isikuid kaks korda ehk teeme kordusmõõtmise, uurides
mingi muutuse ( ravim , koolitus, reklaamikampaania ) mõju. Oluline on,
et iga vastaja kohta peame teadma mingi näitaja väärtust enne ja
pärast, sest analüüsiks kasutame iga vastaja väärtuste erinevust
ehk vahet. Seega valimimaht on valimites täpselt sama, kuna uurime
täpselt samu objekte uuesti. Tähistades vahede keskmise
üldkogumis V saame püstitada kahepoolsed hüpoteesid,
kas muutust on olnud või ühepoolsed hüpoteesid, kas muutus
keskmiselt suurendas või vähendas tunnuse väärtusi:
Kahepoolne hüpotees
Ühepoolsed hüpoteesid
Sisuka hüpoteesi tõestamiseks võime kasutada lisas 1 toodud
kriteeriume, kus vastav statistik T arvutatakse järgmiselt:
kus
on vastanute vahede (erinevuste) keskmine ja standardhälve ning n
on vastanute arv.
4.3.5. Hüpoteesid kahes üldkogumis binaarse tunnuse väärtuse osakaaludele
Osakaalude võrdlemiseks eeldame, et uuritavad valimid on
sõltumatud ja suured, mõlemas vähemalt 30 vastanut. Tähistades
ühes üldkogumis binaarse tunnuse väärtuse osakaalu
ja teises üldkogumis sama väärtuse osakaalu ,
saame järgmised kahe- ja ühepoolsed hüpoteesid.
Kahepoolne hüpotees
Ühepoolsed hüpoteesid
Kontrollimiseks kasutatav statistik arvutatakse järgmiselt:
Toodud valemis n1 on esimese valimi maht ja k1
väärtuse sagedus esimeses valimis ning n2 on
teise valimi maht ja k2 väärtuse sagedus teises
valimis.
Lisa 1. Kriteeriumid sisuka hüpoteeside kontrollimiseks
Kontrollitav hüpoteesipaar
T-statistik
Kahepoolne hüpotees
Ühepoolsed hüpoteesid
Eeldame suurt valimit, n>60
Eeldame suuri valimeid n1,2>30
Eeldame suuri valimeid n1,2>30
Tingimus sisuka hüpoteesi H1 tõestamiseks
Lisa 2. Valik Studenti t-jaotuse täiendkvantiilide väärtuseid
Olulisusnivoo a ehk suurim lubatud eksimise tõenäosus
Vabadusastmete arv (n-1)
10%
5%
2,5%
1%
0,5%
1
3,08
6,31
12,71
31,82
63,66
2
1,89
2,92
4,30
6,96
9,92
3
1,64
2,35
3,18
4,54
5,84
4
1,53
2,13
2,78
3,75
4,60
5
1,48
2,02
2,57
3,36
4,03
6
1,44
1,94
2,45
3,14
3,71
7
1,41
1,89
2,36
3,00
3,50
8
1,40
1,86
2,31
2,90
3,36
9
1,38
1,83
2,26
2,82
3,25
10
1,37
1,81
2,23
2,76
3,17
12
1,36
1,78
2,18
2,68
3,05
14
1,35
1,76
2,14
2,62
2,98
16
1,34
1,75
2,12
2,58
2,92
18
1,33
1,73
2,10
2,55
2,88
20
1,33
1,72
2,09
2,53
2,85
25
1,32
1,71
2,06
2,49
2,79
30
1,31
1,70
2,04
2,46
2,75
40
1,30
1,68
2,02
2,42
2,70
60
1,30
1,67
2,00
2,39
2,66
120
1,29
1,66
1,98
2,36
2,62
100000
1,28
1,64
1,96
2,33
2,58






































Kõik kommentaarid