1. Algoritm . Algoritmi keerukus . Ajalise keerukuse asümptootiline hinnang. Erinevad keerukusklassid: kirjeldus, näited. 1.1 Algoritm • Mingi meetod probleemi lahendamiseks, mida saab realiseerida arvutiprogrogrammi abil.
• Algoritm on õige, kui kõigi sisendite korral, mis vastavalt algoritmi kirjeldusele on lubatud,
lõpetab ta töö ja annab tulemuse, mis
rahuldab ülesande tingimusi. Öeldakse, et algoritm lahendab
arvutusülesande.
• Selline programm, mis annab probleemile õige vastuse piiratud aja jooksul.
• Kindlalt piiritletud sisendi korral vastab ta järgmistele kriteeriumitele:
o lõpetab töö piiratud aja jooksul;
o kasutab piiratud hulka mälu;
o annab probleemile õige vastuse.
•
Parameetrid , mille järgi hinnata algoritmide headust:
o vastava mälu hulk;
o töötamise kiirus ehk vajatava aja hulk.
Omadused:
1.
Lõpplikkus – töö peab lõppema peale lõpliku arvu sammude läbimist.
2.
Määratletus – iga samm peab olema nii täpselt määratud (
rangelt ja ühemõtteliselt), et seda
suudaks täita isegi arvuti. Kui täidetavaid samme on liiga palju, siis algoritm ei ole praktiliselt
täidetav.
3.
Sisend – algoritmil on sisendandmed, mis pärinevad alati kindlat liiki objektide hulgast. Nende
hulk võib olla ka null. Mida rohkem andmeid, seda rohkem aega kulub nende töötlemiseks.
4.
Väljund – üks või mitu töötulemust.
5.
Efektiivsus a.
Korrektne – peab andma õige tulemuse
b. Efektiivne – peab leidma vastuse mõistliku
ajaga c. Programmi efektiivsusele hinnangu andmist nim. algoritmi keerukuse uurimiseks
i. Ajaline
ii. Mahuline
6.
Korrektsus – lahendab etteantud ülesande õigesti.
Algoritmi
tegelik tööaeg ja
efektiivsus sõltub andmete hulgast, protsessori kiirusest, arvutist,
kompilaatorist jne.
Algoritmid ja andmestruktuurid 2015 1
1.2 Algoritmi keerukus • On hinnang sellele, kuidas algoritmi poolt esitatavad nõudmised ajale muutuvad näiteks siis, kui
probleemi mõõt kasvab. Keerukus mõjutab jõudlust, kuid mitte vastupidi.
•
On põhioperatsioonide arvu sõltuvusfunktsioon sisendi suurusest .
•
Põhioperatsioon: üks tehe , üks tsüklitingimus või üks rida
• Keerukusprobleemidega tegeleb vastav teadus –
arvutuslik keerukusteooria. Ajalise keerukuse uurimine Mahulise keerukuse uurimine
algoritmi alusel koostatud programi
tööaja programmi tööks
kasutatava mälu mahu hindamine hindamine •
Keerukusfunktsiooni kasvukiirus – kui kiiresti kasvab antud algoritmi järgi koostatud
programmi ressursivajadus töödeldavate andmete mahu suurenemisel.
•
Keerukusfunktsiooni leidmiseks on võimalik kokku arvutada kõik sammud, mida arvuti teeb
ülesande lahendamiseks. Pole võimalik väljendada konkreetse arvuga, vaid andmete hulgast (n)
sõltuva valemina.
Algoritmi keerukus
halvimal juhul
Algoritmi
keskmine Algoritmi keerukus
parimal juhul
keerukus
Teatud algandmete komplekti juures
Igasuguste halvemate ja
Mingi algandmete komplekti
võib kuluda aega tunduvalt rohkem
paremate juhuste
puhul võib algoritm töötada
keskmisest; selgitakse välja, millised
keskmine, mis aga
tunduvalt kiiremini. Need juhused
on halvimad variandid ja kui tihti
tavaliselt kipub suvaliselt
on huvitav väljaselgitada, paraku
nad esinevad.
Kriitilistel juhtudel tekkivate andmete puhul
pakub see enamasti vaid
peetakse õigeks arvestada ennekõike
olema halvimale üsna
teoreetilist huvi, sest kasutada
just halvima juhu keerukusega.
lähedal.
saab seda teadmist harva.
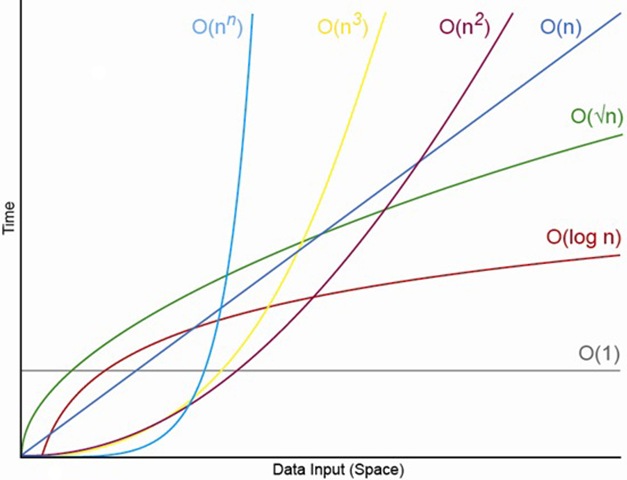
1.3 Ajalise keerukuse asümptootiline hinnang Asümptootiline hinnanguga väljendatakse funktsiooni väärtuse muutumise üldist trendi – funktsiooni
kasvamise kiirust.
Asümptoot on sirge, millele funktsiooni
graafik lõpmatult läheneb, kuid millega ta ei
lõiku.
Suure O tähistust kasutakse algoritmide keerukuse tähistamiseks. Reeglina antakse hinnang
halvima juhu jaoks ja tegelik tööaeg peaks olema parem. Suure O järgi
saab hinnata algoritmi tööaja suhtelist kasvu andmehulga suurenemisel. Kuna hinnang on
ligikaudne kaob mõte täpselt kõiki tehteid
üle lugeda. Oluline on N-i järk (kus
N on töödeldavate andmete hulk ehk probleemi mõõt).
Hinnangud hakkavad kehtima alles N-i suurte väärtuste korral.
O. def: Funktsioon g(N) on O(f(N)), kui leiduvad konstandid C0 ja N0, nii et g(N)N0
korral
• O(g(n)) on funksioonide hulk, mis ei kasva kiiremini kui g(n).
Algoritmid ja andmestruktuurid 2015 2
• g(n) on funktsioon, mis kirjeldab algoritmi saamude arvu ja sellest tulenevalt tööaja seost sisendi
mahuga (n). Näiteks võib funktsiooniks g(n) olla n, n2 jms
Konstant C0-ga:
• püütakse
likvideerida vead, mis tekivad matemaatiliselt sammude väljaarvutamisel või programmi
analüüsides ebaoluliste lausete vahelejätmise tõttu
• et võimaldada klassifitseerida algoritmid tööaja ülemise piiri järgi
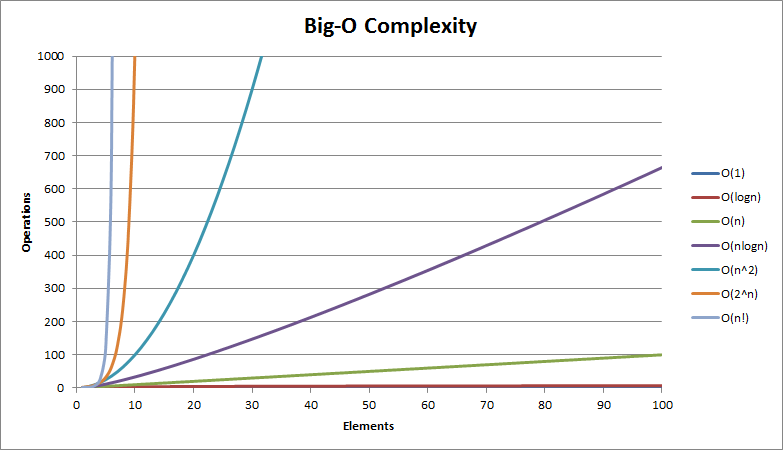
1.4 Erinevad keerukusklassid: kirjeldus, näited Tööaja hindamiseks on vaja peamist tähelepanu pöörata kasutavatele keelekonstruktsioonidele – st
algoritmi või programmi struktuurile.
O(1)
O(log2n) või O(log n)
O(n)
O(n log2n) või O(n log n)
Konstantne Logaritmiline
Lineaarne
Linearitmeetiline?
• Andmehulgast ei
• Tööaeg kasvab väga
• Kui N kasvab 2 korda, • Tavaliselt tähendab seda, et
sõltu algoritmi
aeglaselt N-i kasvades.
kasvab ka tööaeg 2
lineaarses algoritmis on log2n
tööaeg.
• Log n kasvab vaid 2
korda
algoritm.
• Kõiki programmi
korda kui n2.
• Iga elementi on vaja
• Algoritm lahendab probleemi
lauseid täidetakse
• Probleemi lahendakse
töödelda mingil määral.
nii, et alguses tükeldab
üks kord.
selle järkjärgulisel
väiksemateks osadeks.
• Lahendamiseks on
vähendamisel kordades
• Kui kõik nn alamprobleemid
tavaliselt olemas
või muutmisel
on
lahendatud , siis kogu
valem.
väiksemaks probleemiks
lahenduse saamiseks need
ühendatakse kokku.
Paisksalvestus;
Kahendotsimine – otsitav
Lineaarne otsimine (leida
Poolitussortimine,
tuvastamaks, kas
piirkond aheneb igal
kõige väiksem number
kiirsortimine, mestimisega
täisarv on paaris või
sammul 2 korda,
massiivis)
sorteerimine, kuhjaga
paaritu
Parallelsed ja jagatud
Vektorite
sisestamine ,
sorteerimine, timsort
algoritmid
väljastamine,
liitmine ,
lahutamine ja
skalaarkorrutis
O(n2)
O(n3)
O(2n)
O(n!)
Ruutkeerukus
Kuupkeerukus
Eksponentsiaalne
Faktoriaalne
• Andmehulga kasvamisel 10 korda
Enamasti 3 tsüklit
• Kui N=10 on aeg 1000,
suureneb tööaeg 100 korda.
üksteise sees, mis
• Suurendades N-i 20
• Enamasti 2 tsüklit üksteise see ja
kõik sõltuvad
korda, kasvab tööaeg
mõlemad sõltuvad algandmete
algandmete hulgast.
1000000-ni.
hulgast.
• Ebapraktiline algoritm.
Algoritmid ja andmestruktuurid 2015 3
• Sobilik on selline algoritm suhteliselt • Sobilik vaid
Jõumeetodil lahendused,
n elemendi kõigi
väikest mõõtu probleemide
väikeste
kõigi variantide
võimalike
lahendamiseks.
andmetehulkade
täisläbivaatused.
järjestuste leidmine
• Nullsortimine, valiksortimine,
korral.
maatriksite sisestamine,
• Maatriksite
väljastamine, liitmine ja lahuta...
korrutamine.
Arvuti töökiirus
Probleemi mõõt 10^6
(
operatsioonid sekundis)
O(n)
O(n log n)
O(n2)
10^6
tunnid tunnid
lootusetu
10^9
sekundid sekundid
aastad
10^12
kohe
kohe
nädalad
Algoritmid ja andmestruktuurid 2015 4
2. Algoritmimise strateegiate lühike iseloomustus ja kasutamise näide ( Brute -force ehk jõumeetod , Greedy method ehk ahne algoritm, Divide and Conquer ehk jaga ja valitse). 2.1 Brute-force ehk jõumeetod • Leiab lahenduse
ebaefektiivselt, tavaliselt vaadates
läbi kõikvõimalikud lahendused ja teed
•
Kergesti arusaadav ja väljamõeldav • Sõltub
lähteandmete iseloomust, hulgast ja sellest, mida otsitakse, kas selline meetod on sobiv
• Tuleb läbi proovida
kõik võimalused ja valida välja
parim 2.1.1 Nõrgad küljed: • Enamasti on tegemist
aeglase meetodiga
•
Nõuavad paljude sammude sooritamist
•
Tihti võimatu täita, sest keerukusklass võib kerkida O(N!)-ni
2.1.2 Tugevad küljed: • Jõumeetodil lahenduse uurimine viib tavaliselt
probleemist parema arusaamise juurde ehk ta on kui mõtlemise strateegia. •
Väikeste algandmete hulga juures võib sellist
lahendust paberil läbi mängida ja muutub
probleem arusaadavaks
• Jõumeetodil töötavad algoritmid on
lihtsad, paremini arusaadavad, kergemini realiseeritavada ja veakindlamad Algoritmid ja andmestruktuurid 2015 5
2.1.3 Näide: Valiksorteerimine, mullisosrteerimine, Sequential search
Leida arvu 625 kõik tegurid. Lahenduskäik: alustatades 1-st ja lõpetades 625 jagada arv läbi kõigi
arvudega. Kui arv jagub (
jääk on 0), siis on järgmine tegur leitud.
2.2 Greedy method ehk ahne algoritm • Algoritmitüüp on sobiv
optimiseerimisülesannete lahendamiseks.
• Optimiseerimisül. Otsib kõigi kandidaatide hulgast mingit alamhulka (valitute hulka), mis
rahuldaks teatud tingimusi. Tingimuseks on enamasti
mingi max või min väärtuse leidmine ja
vastavalt on ka tehtud valikufunktsioon.
2.2.1 Nõrgad küljed: •
Ei anna alati vastuseks optimaalset tulemust ja kui tulemus on ka optimaalne, on seda väga
raske tõestada.
2.2.2 Tugevad küljed: • Paljudel juhtudel on teda kergem koostada
• Töötab kiiremini kui DP algoritm
Optimiseerimise juures on vajalikud teatud tingimused:
1. Kandidaatide hulk (
graafi tipud , teede pikkused, rahatähtede suurused...)
2. Valitute hulk, mis või kes on juba
kasutatud (
sobivaks tunnistatud , tagasi antud rahatähed,
läbitud graafi tipud...)
3. Eeldatav lahendus, otsitav summa vms, mille järgi saab otsustada, kas välja valitud kandidaadid
moodustavad lahendused (ei pruugi olla optimaalne)
4. Jätkamise näitaja, mille järgi saab otsustada, kas kandidaatide hulka saab suurendada, et
lahendust leida.
5. Valikufunktsioon, mille abil valitakse uusi kandidaate väljavalitute hulka
6. Vastusefunktsioon, mis annab lõpliku väärtuse lahendusele
2.2.3 Näide kasutamisest: Ahnet algoritmi on sobiv kasutada siis, kui
alamülesannete optimaalsed lahendused annavad
tulemuseks
kogu probleemi optimaalse lahenduse.
Valiksorteerimise algoritm (igal sammul otsitakse
vähimat arvu, mida sorteerimata massiiviosa
algusesse tõsta).
Seljakoti probleem. Varga eesmärk on
seljakotti sisse panna võimalikult suure summa eest kraami. (kaks variatsiooni: diskreetne – asju ei ole
võimalik tükeldada ja pidev – osade kaupa)
Algoritmid ja andmestruktuurid 2015 6
2.3 Divide and Conquer ehk jaga ja valitse Kogu meetod on oma olemuselt rekkursiivne (st jaga ülesanne tükkideks ja tükid omakorda tükkideks kuni saadakse sobiva suursega tükid, mida on paras lahendada) • Probleem jagatakse mitmeks alamprobleemiks, mis lahendatakse üksteisest sõltumatult.
• Seejärel ühendateakse alamprobleemide lahendused nö alt üles ja saadakse lahendus kogu
probleemile.
2.3.1 Omadused: •
Minimaalne sisendi mõõt n0 – kui probleemi suurs on alla selle ei hakata probleemi jagama.
•
Alamprobleemi suurus, milleks kogu probleem jagatakse – milline suurus on paras?
• Jagamisel saadavate
alamprobleemide arv – liiga palju alamprobleeme pole ka hea
•
Algoritm, mida kasutakse alamprobleemide lahenduste ühendamiseks, sellest sõltub ka lahenduse
efektiivsus
2.3.2 Tugevad küljed: • Konseptuaalselt raskete probleemide lahendamine
• Paralleelsus – mitmetuumaliste
protsessorite rakendamisel
• Aitab
avastada efektiivseid algoritme
• Cachemälu kasutamine on efektiivsem
2.3.3 Nõrgad küljed: • Tugevate külgede vastandid
2.3.4 Näide kasutamisest: •
Kiirsorteerimine ja
mestimisega sorteerimine. Mõlemad algoritmid on rekursiivsed ja jaotavad
mingi skeemi järgi kogu ülesannet tükkideks, et need sorteerida ja hiljem osad ühendada.
• Jaga ja valitse tüüpi strateegiat kasutavad ka
otsimiskahendpuu ja
kahendotsimise algoritmis.
3. Andmestruktuur. Andmestruktuuri loogiline tase ja realisatsiooni tase. 3.1 Andmestruktuur •
Andmete talletamise ja organiseerimise viis
• Vahend
suure hulga andmete organiseerimiseks ja salvestamiseks arvutis ning neile efektiivse
juurdepääsu tagamiseks
• Andmestruktuurid jaotuvad üldise ülesehituse järgi:
lineaarsed ja mittelineaarsed. Nad
tuginevad arvuti võimetele
salvestada ja võtta andmeid
mälust aadressi järgi. • Lineaarsed andmestruktuurid on loendid, kus
elementide vahel on järgnevussuhe •
Lihtsaim füüsiline struktuur andmete mälus hoidmiseks
on masiiv(id). Algoritmid ja andmestruktuurid 2015 7
•
Loogiliseks struktuuriks on
andmete jada – andmed on järjestatud, lineaarsed, igale
andmeelemendile eelneb ja järgnev alati üks element. On oluline, kes või mis on jadas esimene ja
viimane jne.
• Ühemõõtmeline
massiiv , kus on üliõpilaste nimekiri (
loend ): seoseks võib olla järjestus
tähestistiku alusel.
Oluline on vahet teha andmestruktuuri kahel aspektil: loogilisel ja realisatsiooni tasemel. Andmestruktuuri elemendi jaoks kasutatakse tavaliselt järgmisi mõisteid:
•
Sõlm ( node ) – andmeelement tabelis,
üldisemalt struktuuris (ka
kirje,
objekt, element). Koosneb
ühest või mitmest
infoväljast ja ühest või mitmest
viidaväljast. •
Väli (võtme- ja infoväli)
– sõlm koosneb mitmest baidist arvutimälus ja loogilisel tasemel mitmest
väljast info hoidmiseks. Lisaks on vajalikud väljad, et
luua seoseid struktuuri teiste elementidega.
•
Võtmeväli – selle järgi saab näiteks
sorteerida ja otsida, vastavalt
eesmärgile võib võtmeväljaks
olla kord üks ja kord teine
infoväli.
•
Sõlme aadress (ka
link ,
viit sõlmele) – sõlme esimese baidi aadress arvuti mälus. *
Mummuga nool sümboliseerib aadressi, mumm peaks paiknema seal, kuhu aadress kirjutatud on. 3.2 Andmestruktuuri loogiline tase •
Teatud omadustega struktuur: o Andmete järjestus (eelmine, järgmine, ...)
o Operatsioonid (elemendi lisamine, eemaldamine, ...)
• Kirjeldab struktuuri
loogilist ülesehitust ja selle
esitamiseks sobivad hästi nooled, kastid jms
graadfilised võtted.
•
Operatsioonide selgitamiseks aga
pseudokood või muud üldised vahendid algoritmi
üleskirjutamiseks.
• On kirjeldus struktuuri käitumisest ja sellest, kuidas me teda
tajume.
3.3 Realisatsiooni tase – andmestruktuuri füüsiline esitus • Näitab, kuidas vastav struktuur tegelikult arvutis üles ehitatakse ja kuidas tegelikult toimuvad
tema peal vajalikud operatsioonid.
• Sama loogilist struktuuri saab tihti
realiseerida mitmel erineval viisil ning sõltub keelest ja
olukorrast, milline variant on otstarbekam.
•
Tavaliselt staatiline või dünaamiline ; lähtub mäluaadresside kasutamisest
•
Aadressid arvutakse välja või salvestatakse koos
andmetega Algoritmid ja andmestruktuurid 2015 8
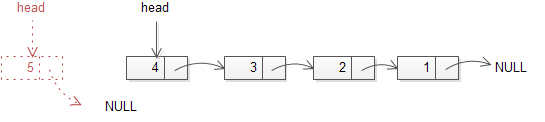
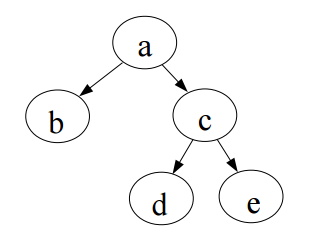
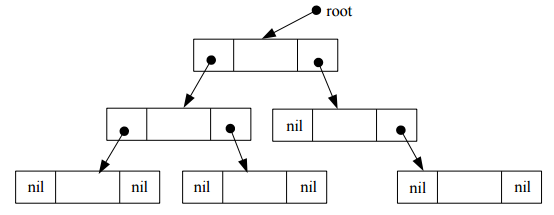
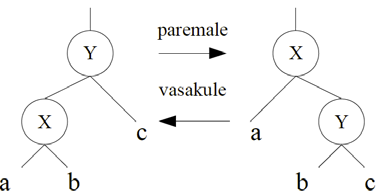
4. Ühe viidaga ahelad . Peamised tegevused ahelaga: elemendi lisamine, elemendi kustutamine, ahela läbimine - tekstiline ja pildiline kirjeldus. 4.1 Ühe viidaga ahelad Ahel on madala taseme struktuur, mis koosneb viitade abil ühendatud elementidest (nn sõlmedest) Ahela abil saab ehitada lineaarse loendit dünaamiliselt . Ühe viidaga ahel koosneb
peast (head), mis
viitab ahela esimesele elemendile ja selle külge aheldatud
ning omavahel seotud
ahela ülejäänud elementidest.
Joonis 1 Pildiline kirjeldus ühe viidaga ahelast ning selle läbimisest. •
Esimene sõlm: pea (head), viimane sõlm ( tail ).
• Ahela kohta on teada
esimese sõlme aadress, järgmised
sõlmed saadakse kätte
esimesest sõlmest
lähtudes.
• Viimase elemendi (saba) viidaväljas on
tühi aadress (NIL või Null), selle järgi saab tuvastada
ahela lõppemisest. • Seega viidaväljade abil ühendatakse sõlmed ühte struktuuri: ahelasse.
4.2 Ahela läbimine 4.2.1 Tekstiline Alustades ahela peast liigutakse sõlm haaval ahela lõpuni. Vajaduse korral tehakse iga sõlmega midagi
(uuritakse võtmevälja väärtust vms). Abimuutuja
current peab olema viidatüüpi. Ta tuleb kasutusele
võtta selleks, et kogu ahelale viitav
Head kaotsi ei läheks.
4.2.2 Pildiline Joonis 1 Pildiline kirjeldus ühe viidaga ahelast ning selle läbimisest.
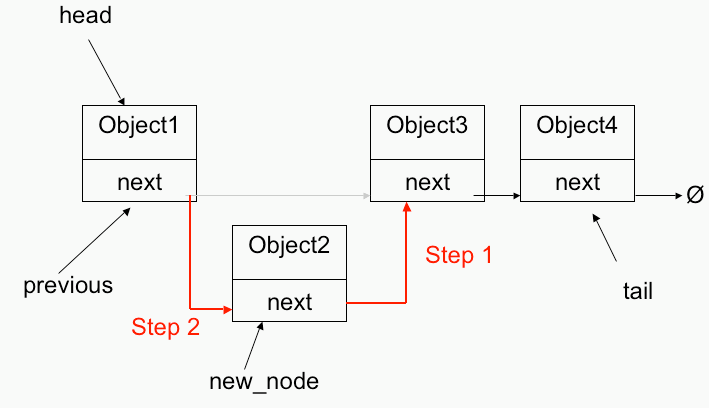
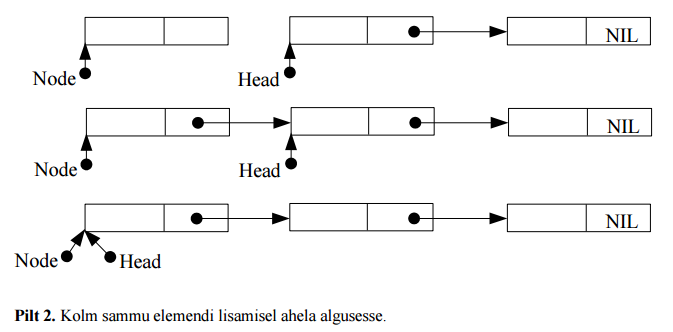
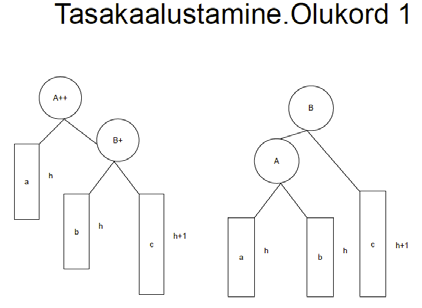
4.3 Elemendi (sõlme) lisamine 4.3.1 Tekstiline Sõlme lisamine võib toimuda ahela algusesse, keskele või lõppu:
•
Esimese elemendi lisamisel muutub
ahela pea väärtus (kõige lihtsam ja kiirem)
• Elemendi
keskele lisamisel tuleb jälgida, et
ahel ei katkeks (kui on vaja säilitada näiteks
sorteeritud
järjekorda )
o Abiks tuleb võtta üks või kaks
viita ja läbida ahel õige kohani
Algoritmid ja andmestruktuurid 2015 9
o Võib abiks võtta 2 viita: Current ja
Prev . Viimane on pidevalt ühe elemendi võrra
Curr -ist
tagapoolt. Lisamine toimub Prev-i ja Current-i vahele.
•
Viimase elemendi lisamisel tuleb uue sõlme
viidavälja NIL kirjutada
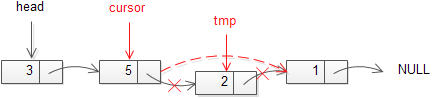
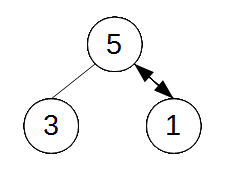
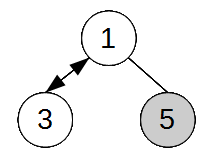
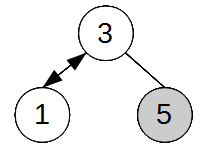
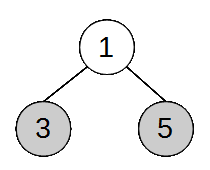
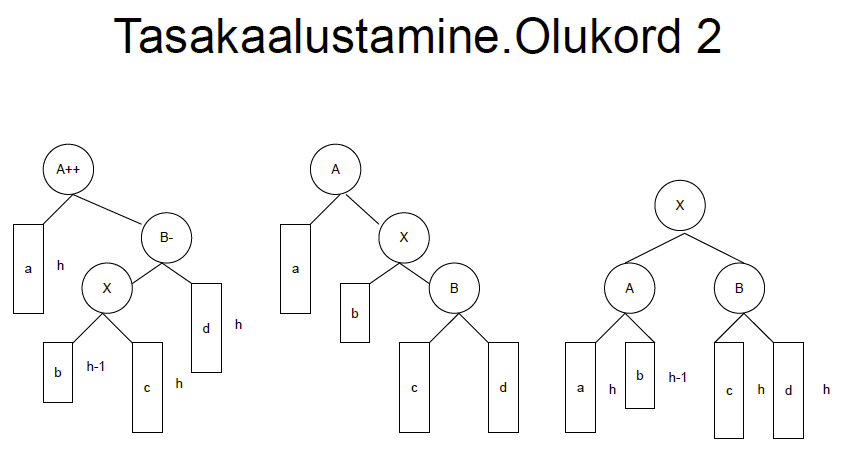
4.3.2 Pildiline 4.4 Elemendi kustutamine Kustutav sõlm otsitakse tavaliselt üles infovälja või võtmevälja väärtuse järgi. Mugavam on
kustutada kasutades kahte abiviita
(sarnaselt lisamisele) We point the head to the next node and
remove the node that the head pointed to.
To remove a node from the
back of the
linked list, we need to:
• Use two pointers: cursor and back to track the node.
• Start from the
first node
until the cursor pointer reaches the last node and the back pointer reaches
the node before the last node.
• Set the next pointer of the back to NULL and delete the node that the cursor points to.
• If the node has only 1 element, set the head pointer to NULL before removing the node.
Algoritmid ja andmestruktuurid 2015 10
5. Pinu : omadused, operatsioonid. Näited pinu kasutamisest. Pinu realiseerimine arvutis. 5.1 Pinu: omadused, operatsioonid. Magasin ehk
pinu (stack) on lineaarloend, kuhu elemente lisatakse ja kust elemente kustutatakse ühest ja
samast otsast, pinu tipust (top). Andmete kättesaamine toimub reeglina sel teel, et element eemaldatakse
pinust.
• Omadus: mis esimesena sisse pandi, saab kätte kōige viimasena ja vastupidi – viimasena
paigaldatud eseme saab kätte esimesena.(
LIFO)
• Operatsioonid.
o Elemendi
lisamine pinusse (
push )
o Elemendi
eemaldamine pinust (pop)
o Uue pinu
loomine.
o
Kontroll, kas pinu on
tühi.
o
Kontroll, kas pinu on
täis (ruum uute elementide lisamiseks on otsa saanud).
5.2 Näited pinu kasutamisest • Funktsioonide
väljakutse organiseerimine
•
Avaldiste teisendamine, kontrollimine, arvutamine ja muu aritmeetiliste avaldiste töötlemine
(
sulge mugavalt uurda)
• Igasuguse info
tagurpidi pööramiseks
• Abivahend andmete hoidmisel, kus viimati listud väärtust tuleb kohe töötlema hakata
• Alamprogrammide väljakutse organiseerimine arvutis
o Uue alamprogrammi väljakutse tähendab seda, et programmi täitmine jääb teatud kohas
pooleli ja peab peale alamprogrammi töö lõppemist jätkuma samalt kohalt. Selleks
pannakse pooleli jäänud alamprogramm pinusse koos oma muutujate komplektiga. Kui
momendil töötav alamprogramm oma töö lõpetab, võetakse pinust välja kõige peal olev
alamprogramm ja kogu väljakutse
loogika on just selline, et see on see õige, millega edasi
minna.
5.3 Pinu realiseerimine arvutis 5.3.1 Staatiline meetod kasutades massiivi • Pinu maht
piiratud • Pinu tipu meeles pidamiseks tuleb arvet pidada täidetud massiivelementide üle
•
Staatiline mälukasutusega
• Elemendid on
füüsiliselt järjestikku
• Massiivi
lahter sisaldab infot ühe pinu elemendi kohta
Algoritmid ja andmestruktuurid 2015 11
5.3.2 Dünaamiline meetod kasutades ühe viidaga ahelat • Tuleb otsustada,
kumba pidi viidad jooksevad, et
push ja
pop protseduure lihtsam kirjutada
oleks
•
Piisab ühest viidast pinu tipule, et temaga peamisi operatsioone teha
• Ei pea paiknema füüsiliselt järjestikku, vaid järgnevusseose määravad viidad
• Elemendid võiksid viidata olemasoleva pinu poole (nö alla poole)
6. Postfiks avaldis ehk Pööratud Poola kuju (Reverse Polish Notation). Mis see on, kuidas teisendatakse tavaliseks infiks avaldiseks ja vastupidi. Nii loogika kui ka aritmeetikaavaldisi saab kirja panna kolmel erineval kujul:
prefiks (+ab , Poola kuju,
operandid on avaldises ees.),
postfks (ab+ , pööratud poola kuju, operandid järel) ja
infiks (a+b) kujul.
6.1 Postfiks avaldis ehk pööratud Poola kuju – (ab+) viis kuidas panna kirja loogikaavaldisi
sulge kasutamata.
Operatorid pannakse operandide järele.
Avaldise postfiks kujule teisendamine (teisendusalgoritm eeldab, et kõigi tehete
järjekord on määratud
sulgudega):
• Arv kirjuta väljundisse
• Vasakut sulgu ignoreeri
• Operaator (tehtemärk) pane pinusse
• Parempoolse sulu puhul võta operaator pinust ja kirjuta väljundisse
Postfiksilt infiks kujule: • Postfikskujul avaldis kirjutada pinusse (vasakpoolseim liige pinusse kõige ülemiseks(top) ja
parempoolseim liige kõige alumiseks(bottom))
• Võtta pinust ülevalt poolt järjest operande ning kirjutada välja(nii kaua kui tuleb operaator)
• Kui tuleb operaator, kirjutada see kahe viimati väljakirjutatud operandi vahele, ning lisada sulud
ümber
• Jätka tegevust
Algoritmid ja andmestruktuurid 2015 12
(5*((9*8)+(7*(4+6))))
Väljund
Pinu
1. samm 5
2. samm 5
push3. samm 59
4. samm 59
**
push5. samm 598
pop6. samm 598*
7. samm 598*
*+
push8. samm 598*7
9. samm 598*74
*+*
push10. samm 598*74
*+*+
push11. samm 598*746
*+*+
pop12. samm 598*746+
*+*
pop13. samm 598*746+*
pop14. samm 598*746+*+
pop15. samm 598*746+*+*
1. samm 598*746+*+*
2. samm 98*746+*+*
5
3. samm 8*746+*+*
5,9
4. samm *746+*+*
5,9,8
5. samm 746+*+*
5,(9*8)
6. samm 46+*+*
5,(9*8),7
7. samm 6+*+*
5,(9*8),7,4
8. samm +*+*
5,(9*8),7,4,6
9. samm *+*
5,(9*8),7,(4+6)
10. samm +*
5,(9*8),(7*(4+6))
11. samm *
(5*((9*8)+(7*(4+6))))
Algoritmid ja andmestruktuurid 2015 13
7. Järjekord: omadused, operatsioonid. Näited järjekorra kasutamisest. Järjekorra realiseerimine arvutis. 7.1 Järjekord: omadused •
Lineaarloend, kus elementide lisamine toimub alati loendi ühes otsas ja elementide eemaldamine
teisest otsast
•
Andmete vaatamiseks pääseb ligi vaid selles otsas, kust toimub eemaldamine
•
FIFO, kes esimesena järjekorda lisatakse, see võetakse ka välja esimesena
7.2 Peamised operatsioonid 1.
Lisada element järjekorra lõppu
2.
Eemaldada element järjekorra algusest
Lisaks:
3. Uue tühja järjekorra
loomine 4. Kontroll, kas järjekord on
tühi 5. Kontroll, kas järjekord on
täis 7.3 Näited järjekorra kasutamisest • Kui andmed saabuvad kindlas
ajalises järgnevuses ja saabumise järgnevus on oluline ka andmete
töötlemisel
o Näiteks
operatsioonisüsteem paneb saabunud käsud/päringus järjekorra lõppu ja võtab
neid järjekorra algusest täitmiseks.
o Näiteks lennuki
piletite broneerimissüsteem. Broneerimissoovid saabuvad erinevatel
ajahetkedel, samas järjekorras tuleks need
soovida ka rahuldada ja broneeringud teha.
• Eriliigid:
o Mitme teenindajaga järjekorrad
o Eelistusjärjekord – mõni peab saama teenindatud varem, kuid sama prioriteediga
tegelaste vahel kehitivad ikka järjekorra reeglid.
o Piiratud pikkusega järjekord
7.4 Järjekorra realiseerimine arvutis 7.4.1 Staatiline ehk kasutades massiivi • Massiivina realiseerimiseks peab järjekorra jaoks
meeles pidama kahte välist indeksit (algus
ja lõpp).
• Andmeid
listakse algusesse ja
eemaldatakse lõpust .
Algoritmid ja andmestruktuurid 2015 14
• Seega sarnaselt pinule muudetakse nii elemendi lisamisel kui ka
kustutamisel vastavaid indekseid.
• Kui algus ja lõpp on tagurpidi (lõpp > algus), siis on järjekord tühi
• Et massiiv otsa ei saaks, siis tuleb järjekord uuesti massiivi algusesse tuua, kui see on lõppu
jõudnud
7.4.2 Dünaamiline ehk kasutades ahelat • Kasulik ja vajalik, et
viitasid oleks kaks, mis viitaks ahela
esimesele ja
viimasele sõlmele. Nõnda
on lisamine kiira ja mugav.
• Põhjus on järjekorra eripäras, sest ligi on
vaja pääseda nii
järjekoora algusele kui ka
lõpule.
• Järjekorda on kasulikum hoida
nö tagurpidi, sest nii saab palju mugavamalt elementi eemaldada.
8. Puu. Üldine puu. Kahendpuu. Järjestatud (orienteeritud) ja järjestamata (orienteerimata) puu. Puuga seotud erinevad mõisted. Puu ülesmärkimine sulgavaldisena ja Dewey kümnendesitusena. Puu läbimise järjekorrad (pre-, post- ja inorder). Puu realiseerimine arvutis. 8.1 Puu. Üldine puu •
Graaf on mittelineaarne struktuur, mille abil saab modelleerida objektide hulgas paari-kaupa
esinevaid suhteid ja seoseid.
•
Puu on graafi
erivorm .
•
Puus ühendatakse andmeobjektid
hierhilisel viisil.
• Puu koosneb elementidest, mida nim.
tippudeks ehk
sõlmedeks (siia paigutakse andmed/info), ja
seosetest tippude (sõlmedes oleva info) vahel, mida nim.
kaarteks.
• Iga puu sõlm on juureks mõnele alampuule. Sõlme kõigi alampuude arvu nimetatakse selle sõlme
järguks. Sõlm, mille järk on 0, on
leht, Ülejäänud sõlmed on
hargnevad sõlmed. • Puu sõlmed jagunevad paiknemishierarhia järgi
tasemetesse. Juur on tasemel 0, juure
järglased on
tasemel 1 jne. Vastavalt tasemete arvule mõõdetakse ka
puu kõrgust.
•
Puu on täielik, kui tema kõigil tasemetel on max võimalik arv sõlmi ja kõik lehed paiknevad samal tasemel. •
Mitmed tegevused puus on O (log N) keerukusega. 8.2 Järjestamata ja järjestatud puud •
Järjestamata, kui ühe tipu laste omavaheline järjestuse ei ole oluline. Järjestamata puu on
orienteeritud, sest hierarhilised seosed on olulised.
•
Järjestatud,
kui ühe tipu järglaste järjestus on oluline, st räägitakse 1., 2., 3. jne pojast.
Algoritmid ja andmestruktuurid 2015 15
8.3 Puuga seotud erinevad mõisted •
Sõlm – element, millest puu koosneb ja kus paiknevad andmed
•
Kaar – seos tippude (sõlmedes oleva info) vahel
•
Juur – sõlm, millele ei
eelne mitte ühtegi sõlme ja seda on ainult üks.
•
Leht – sõlm, mille järk on 0 (talle ei järgne ühtegi sõlme)
•
Sõlme järk – sõlme alampuude arv
•
Puu järk – suurim võimalik sõlme järk antud puus
•
Vanemad – sõlmed, millel on lapsed/järglased
•
Üks vanem – igal sõlmel on ainult üks vanem
•
Lapsed – sõlmed, millel on vanemad
•
Lehed – sõlmed, millel järglased puuduvad
•
Vend – sõlm, millel on sama vanem
•
Eellased – kõik antud sõlmest kõrgemal (juure poole) olevad sõlmed
•
Järglased – kõik antud sõlmest allpool olevad sõlmed
•
Tee – ainus, lühim kaarte järgnevus, mis viib puu juurest leheni. Puu juure ja konkreetse lehe
vahel on alati ainult üks tee
•
Mets – järjestatud hulk, mis koosneb 0 või mitmest mittelõikuvast puust
•
n-järku puu – puu, mille kõigi sõlmede maksimaalne laste arv on piiratud arvuga n
8.4 Puu ülesmärkimine 8.4.1 Sulgavaldisena (a(b) (c(d) (e)))
8.4.2 Dewey kümnendesitusena 1 a; 1.1 b; 1.2 c; 1.2.1 d; 1.2.2 e
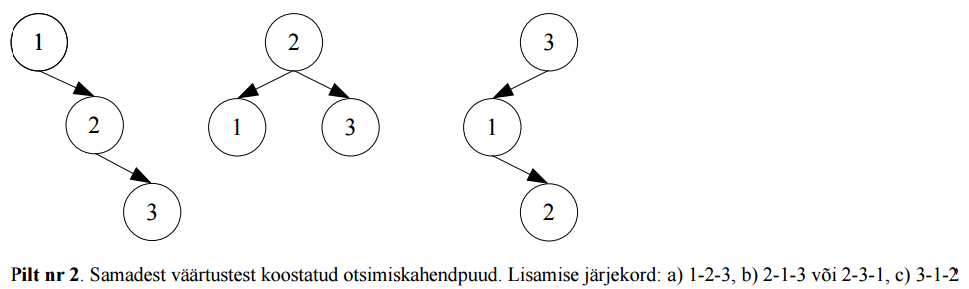
8.5 Kahendpuu • On
tippude lõplik hulk, mis on tühi või koosneb juurest ja
kahest mittelõikuvast alampuust,
mida nim vasakuks ja paremaks alampuuks.
• Kahendpuu igal sõlme on
max kaks alampuud (2-järku puu)
• Iga alampuu puhul on vahe, kas ta on vasakpoolne või parempoolne
• Võrreldes tavalise puuga, siis kahendpuu puhul peetakse ka
tühja alampuud puuks Algoritmid ja andmestruktuurid 2015 16
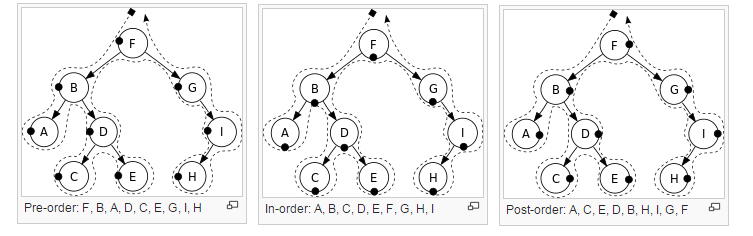
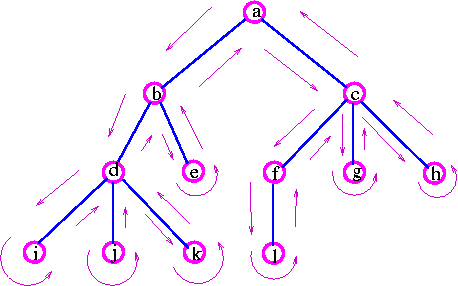
8.6 Puu läbimise järjekorrad (pre-, post- ja inorder) 8.6.1 Lõppjärjekord (Postorder e. Endorder) Vanema ja tema kahe järglase kohta kehtib järgmine läbimise järjestus:
vasak järglane, parem järglane, vanem 1. Läbi vasak alampuu.
2. Läbi parem alampuu.
3. Väljasta (töötle) juur (tegevust korratakse iga alampuu jaoks)
8.6.2 Eesjärjekord (Preorder) Vanema ja tema kahe järglase kohta kehtib järgmine läbimise järjestus
:
vanem, vasak järglane, parem järglane.
1. Väljasta (töötle) juur.
2. Läbi vasak alampuu.
3. Läbi parem alampuu (igal alampuul on oma juur, mida väljastada).
8.6.3 Keskjärjekord (Inorder) Vanema ja tema kahe järglase kohta kehtib järgmine läbimise järjestus:
vasak järglane, vanem, parem järglane. 1. Läbi vasak alampuu.
2. Väljasta (töötle) juur.
3. Läbi parem alampuu (loomulikult on igal alampuul jälle oma juur, mida väljastada).
8.7 Puu realiseerimine arvutis 8.7.1 Staatiliselt massiivina • Oluline on
indeksite olemasolu.
1. Massiivi elemendis hoida lisaks infole ka
kummagi järglase asukoha indeksit
Algoritmid ja andmestruktuurid 2015 17
2. Kastuda mingit reeglit laste ja vanemate indeksite väljaarvutamiseks. Tüüpilised reeglid i-nda
elemendi jaoks on järgmised:
2.1. Vasak laps – 2*i
2.2. Parem laps – 2*i +1
2.3. Vanem – i/2 (täisarvuline jagamine)
8.7.2 Dünaamiliselt ahelana • Dün.
realisatsioon on eelistatud, sest ei nõua esialgset
suurt mälu eraldamist ja on ka
loomulikum.
• Puu iga sõlm sisaldab lisaks infole
kahte viita: LLINK ja RLINK
• Puuga on seotud ka
nn puuviit ROOT • Kui puu on tühi: T = NULL, vastasel juhul on ROOT väärtuseks on puu juure aadress
• Kui mingi sõlme üks alampuudest on tühi, siis kirjutakse vastavasse viidaväljasse tühja viida tähis
NULL/nil
8.8 Puude kasutamine Kasutatakse arvuti mälus andmestruktuurina:
• Avaldised jt keele osad
süntaksipuuna.
• Erinevad
otsimispuud otsimise kiirendamiseks (kahendotsimispuu)
•
Kahenkuhi kiireks elementid paigutamiseks ja kättesaamiseks
• Ka
otsustamispuud,
koodipuud jne
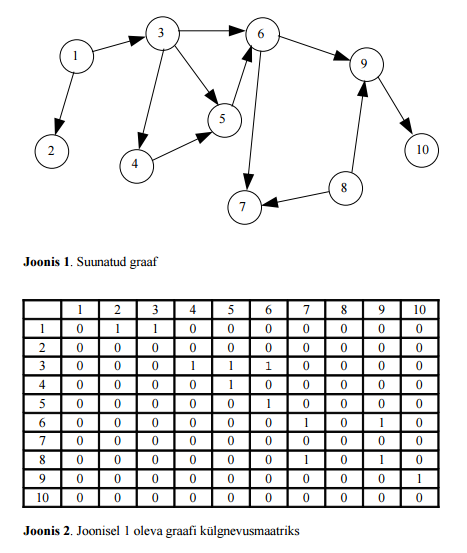
9. Graaf. Graafiga seotud mõisted. Suunatud ja suunamata graaf. Atsükliline graaf. Kaalutud graaf. Graafi ülesjoonistamine ja realiseerimine arvutis. Graafi algoritmid: topoloogiline sorteerimine, sügavuti otsimine, laiuti otsimine, lühim tee kaalutud graafis e Dijkstra algoritm): algoritmi kirjeldus koos väikese näitega. 9.1 Graaf • Graafi võib kirjeldada kui andmestruktuuri, mis
ei pea olema lineaarne.
• Graaf on kõige üldisem võimalus andmete vaheliste
seoste kujutamiseks • Graaf on
struktuur, mille abil saab modelleerida objektide hulgas
esinevaid paari-kaupa suhteid/seoseid. Algoritmid ja andmestruktuurid 2015 18
• Graaf koosneb
tippudest ja
tippe ühendavatest
kaartest (servadest). 9.2 Graafiga seotud mõisted •
Suunatud graaf (orienteeritud) – Graaf, mille kaartel
on suund, st iga kaare jaoks on määratud,
millisest tipust ta algab ja millises
tipus lõppeb.
Teisisõnu või öelda, et graafi tipud on paari kaupa
järjestatud.
•
Suunamata graaf (orienteerimata) – seos kahe tipu vahel on mõlemas suunas. See kehtib kõigi
graafi servade kohta. Joonisel nooli ei märgitata.
Tee saab minna läbi kaare mõlemat pidi. •
Tee ehk ahel
o Saab graafis leida ühest tipust teise tippu.
o Teel on
pikkus. o Selline kaarte järgnevus, kus ühe kaare lõpp-punkt on järgmise kaare alguspunktiks.
o Kaks tippu v ja u on
seotud, kui nende vahel on tee.
Kaks tippu on seotud
külgnevussuhtega, kui ühest tipust läheb kaar teise tippu
•
Elementaarahel – ahel, mis läheb igast
tipust vaid ühe korra.
•
Lihtahel – ahel mis läheb igast
servast vaid ühe korra.
•
Tsükkel – ahel, kus algus ja lõpp on samas tipus.
•
Hamiltoni tsükkel – elementaartsükkel (elementaarahel, mis lõppeb samas tipus), mis läbib
kõiki graafi tippe. •
Euleri tsükkel – lihttsükkel (lihtahel, mis lõppeb samas tipus), mis läbib
kõiki graafi servi ühe
korra.
•
Atsükliline graaf – graaf, kus puudub tsükkel
•
Suunatud atsükliline graaf – graaf, kus puudub suunatud tsükkel
•
Graafi kaalud – kaartel olevad arvud, mis kannavad infot lisaks seoseinfole (nt: seoste tugevus,
pikkus vms)
Algoritmid ja andmestruktuurid 2015 19
•
Täielik – kui graafil on kaared kõigi
tippude vahe
9.3 Graafi ülesjoonistamine ja realiseerimine arvutis 9.3.1 Staatiline realisatsioon Esitab graafis olevaid tippudevahelise
seoseid
külgnevusmaatriksina. Veerud =
read = tipud. Igas
lahtris , kas 0 (False) või 1
(True).
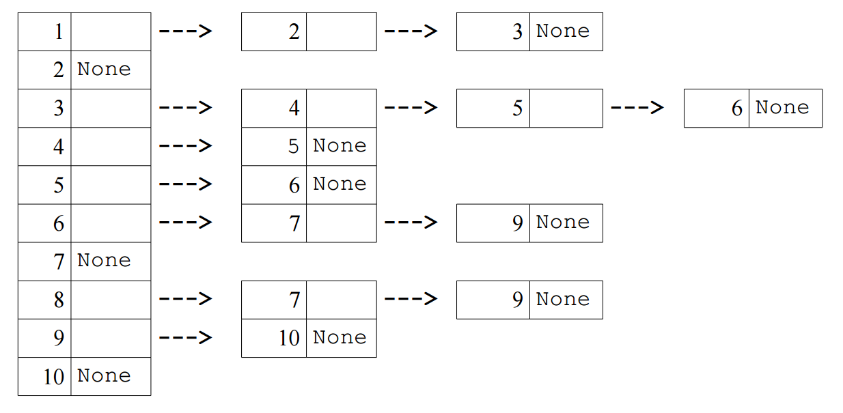
Programmeerides on vaja graafi jaoks deklareerida kahemõõtmeline massiiv, mille elemendi on kas täisarvud või ka boolean-tüüpi väärtused. 9.3.2 Dünaamiline realisatsioon • Hõredama graafi kujutamiseks
võetakse kasutusele
külgnevusloend • Graafi tippudest moodustatakse
massiiv
• Iga tipu jaoks on üks lahter
• Iga tipulahtri külge kinnitakse
lineaarahel
nendest tippudest, mis
külgnevad antud tipuga
• Loendi lõpus on tühi viit (None)
• Mälu hoitakse kokku sellega
9.4 Sügavuti otsimine •
Sarnane labürindi läbimisele
• Minnakse ühte teed pidi
nii sügavale, kui see võimalik on • Kui
naabrid otsas, siis minnakse tagasi ja
otsitakse uut teed
• Nii jätkatakse kuni leidub
veel uurimata tippe
• Kui sellisel viisil rohkemate tippude juurde ei
pääse, kuid on veel uurimata tippe, võetakse
neist
suvaline ja korratakse tegevust
Algoritmid ja andmestruktuurid 2015 20
• Iga tipp saab sattuda vaid ühte
otsimispuusse ja seega puud ei lõiku
• Algoritmi kasutamiseks sobib nii
orienteeritud kui ka
orienteerimata graaf
• Algoritm: nagugi laiuti otsimine
otsimisel tippe värvitakse kasutades kolme erinevat värvi:
valge, hall, must. Lisaks iga tipuga seotakse
kaks ajatemplit: märgitakse siis, kui tipp esimest korda
avastati ja siis, kui tipp on lõplikult töödeldud ja mustaks värvitud
9.4.1 Näide kasutamisest: • Saab kasutada graafis tsüklite leidmiseks
• Kahe tipu vahelise tee leidmiseks
• Min toespuu leidmiseks
9.5 Laiuti otsimine • Kasutada ülesannete puhul, kus otsitakse
parimat lahendust ja
see tuleks välja sõeluda paljude
võimaluste hulgast
• Kõige tüüpilisemaks ülesandeks on leida
lühimat teed kahe tipu vahel • Tippude vahele jäävaid kaarte arvu loetakse tee pikkuseks
• Kõiki lahendusvariante uuritakse paralleelse, mitte ei võrrelda hiljem
9.5.1 Lahenduskäik • Võetakse
lähtetipp •
Kõigepealt otsitakse tipud, kuhu saab
ühe kaare läbimisel, siis
kahe kaare läbimisel jne
• Kui järgmine tee on pikem, siis seda ei fikseerita
• Nii toimides läbitakse lõpuks kõik tipud ja saadakse teada kaarte arv algustipust
igasse tippu.
9.5.2 Algoritm •
Valge – tipuni pole veel jõutud
•
Hall – tipuni on jõutud, tema eellane on fikseeritud, kuid temaga külgnevad tipud pole veel kõik
läbi uuritud
•
Must – tipu järglased on läbi uuritud ja rohkem selle tipu kallale minna ei tohi
Algoritmid ja andmestruktuurid 2015 21
9.5.3 Näide kasutamisest Laiuti otsimiese algoritm on aluseks teiste algoritmide koostamisele graafiprobleemide lahendamiseks.
9.6 Topoloogiline sorteerimine • Graaf on
atsükliline ja
orieteeritud, siis on graafi tippude vahel olemas
osaline järjestus.
• Topoloogilise sorteerimise eesmärgiks on saada selline tippude järgnevus, kus
iga tippu töödeldakse enne kui neid tippe, millele ta osutab.
• Õigeks vastuseks tavaliselt mitu erinevat järgnevust.
o Kõigepealt tuleb leida üles need tipud, kuhu ühtegi kaart ei sisene. Parem on neid leida
külgnevusmaatriksist, liikudes selleks mööda veerge. Kui mõnes veerus 1-d puuduvad,
ongi eellasteta tipp leitud.
o Kui tipp on paigutatud sorteeritud jadasse, tuleb kõigilt tema järglastelt üks eellane maha
kustutada. (-1)
o Järgmisel sammul saab sorteeritud jadasse panna taas neid tippe, millel eellaste arv on 0.
Algoritmid ja andmestruktuurid 2015 22
0.
2
3
5
7
8
9 10 11
1. 71
0
0
0
2
2
2
2
2. 53. 31.
2
3
5
7
8
9 10 11
4.111
0
0
0
1
2
2
1
5. 86. 22.
2
3
5
7
8
9 10 11
7. 91
0
0
0
1
2
2
0
8.103.
2
3
5
7
8
9 10 11
topoloogiline sorteerimine
visuaalselt 1
0
0
0
0
2
1
0
vasakult-paremale ja ülevalt-alla
4.
2
3
5
7
8
9 10 11
0
0
0
0
0
1
0
0
5.
2
3
5
7
8
9 10 11
0
0
0
0
0
0
0
0
6.
2
3
5
7
8
9 10 11
0
0
0
0
0
0
0
0
7.
2
3
5
7
8
9 10 11
0
0
0
0
0
0
0
0
8.
2
3
5
7
8
9 10 11
0
0
0
0
0
0
0
0
9.6.1 Näide kasutamisest Saab lahendada tööde järgnevuse planeerimise ülesannet. Kui tuleb arvestada sellega, et sorteerimise
tulemusi võib olla mitu, seega on võimalikud ka mitu erinevat tööde järjekorda.
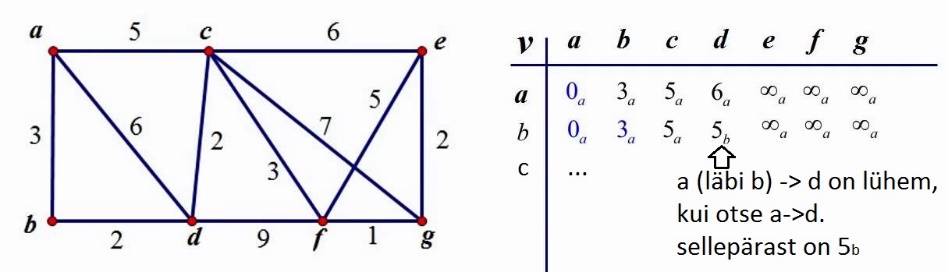
9.7 Lühim tee kaalutud graafis e Dijkstra algoritm •
Suunamata graafist tehakse suunatud graaf
• Graafis
ei tohi olla tsüklit, kus kaarte pikkuste summa tuleks negatiivne
• Töötab
ahne algoritmi põhimõttel, st igal sammul tehakse lokaalselt parim otsus, need otsused
viivad kogu probleemi lahenemiseni
• Tööks vajalik
tippude tabel, kuhu
kirjutatakse iga tipu jaoks tema kaugus lähtetipust ja tipu
number, kust antud tippu jõuti.
• Kaalutud graafis liidetakse kaalud ning
väljastatakse lühim tee • Rakendatakse while-tsükli, töötab seni, kuni kõigi graafi tippude naabrid on läbiuuritud.
•
Üldine idee on väga sarnane laiutiotsimisele, selle vahega, et juba leitud teepikkused võib muuta, juhul kui tuleb välja mõni lühem tee. 9.7.1 Näide kasutamisest Kõige lühema tee leidmine kaardil, kui on teada, et punktist A (Tartu) viib punkti B (Tallinn) mitu
erinevat teed.
• Kasutatakse kolme massiivi.
Massiivid peavad olema nii suured, et oleks ruumi kõigi graafi
tippude jaoks.
•
Node – tipu number koos märkega, kas tipp on "lõpuni" töödeldud
•
Label – tipu kaugus lähtetipust
Algoritmid ja andmestruktuurid 2015 23
•
Prev – eelmise tipu number (tipp, kust antud tippu satuti).
Algoritmid ja andmestruktuurid 2015 24
Dijakstra algoritmi lahendusMin kagusega tipp, mida tuleb võtta järgmisel
uurimisel aluseks
Teepikkuse parandus0. samm Node
A
B
C
D
E
F
G
H
Label
0
999 999 999 999 999 999 999
Prev
1. samm Node A*
B
C
D
E
F
G
H
Label
0
0+2 0+5 0+4 999 999 999 999
Prev
A
A
A
2. samm Node A*
B*
C
D
E
F
G
H
Label
0
2
2+24 2+12 2+7 999 999
Prev
A
BA
B
B
3. samm Node A*
B*
C*
D
E
F
G
H
Label
0
2
4
4
14
4+3 4+4 999
Prev
A
B
A
B
CC
4. samm Node A*
B*
C*
D*
E
F
G
H
Label
0
2
4
4
14
7
8
999
Prev
A
B
A
B
C
C
5. samm Node A*
B*
C*
D*
E
F*
G
H
Label
0
2
4
4
14
7
8
7+5
Prev
A
B
A
B
C
C
F
6. samm Node A*
B*
C*
D*
E
F*
G*
H
Label
0
2
4
4
14
7
8
12
Prev
A
B
A
B
C
C
F
7. samm Node A*
B*
C*
D*
E
F*
G*
H*
Label
0
2
4
4
14
7
8
12
Prev
A
B
A
B
C
C
F
8. samm Node A*
B*
C*
D*
E*
F*
G*
H*
Label
0
2
4
4
14
7
8
12
Prev
A
B
A
B
C
C
F
Lühim tee A-st H-sse: H > F > C >B > A12 = 5 + 3 + 2 + 2Algoritmid ja andmestruktuurid 2015 25
10. Kahendkuhi - mis teda iseloomustab, kuidas realiseeritakse, milliste ülesannete jaoks Selline kahendpuud, kus peaksid olemad täidetud järgmised tingimused:
1. Igas tipus olev väärtus ei tohi olla väiksem kui selle tipu järglastel
2. Lehtede sügavus ei tohi erineda rohkem kui 1 taseme võrra
3. Viimane tase täitub vasakult paremale
• Andmestruktuur on tavaliselt realiseeritud
massiivina ja puu juur on element
indeksiga 1, edasi
tulevad juure järglased 2 ja 3 jne
• Kahendkuhja kasutatakse
ka prioriteetidega järjekorra realiseerimiseks.
• Sel juhul paikneb kõrgeima prioriteediga element
kuhja tipus (massiivi 1. lahtris) ja peale tema
eemaldamist tuleb
kuhi ringi ehitada
11. Sorteerimisülesanne. Sorteermine kuhjaga (Heaps.), lisamissorteerimine (Insertion s.), mestimisega sorteerimine (Merge s.), loendamissorteerimine ( Counting s.). Meetodite keerukus, tugevad ja nõrgad küljed. Mõtle ka näitele algoritmi töö selgitamiseks. 11.1 Sorteerimine kuhjaga (Heaps sort) • Meetod kasutab kahendkuhja
•
Suuremat vajadust lisamälu järele ei ole.
• Sorteerimine toimub kahes
etapis :
1. Arvudemassiivist moodustatakse väärtuste ümberpaigutamise teel kuhi.
2. Kuhi sorteeritakse vastava algoritmiga.
o Kui massiivist on sel viisil kuhi moodustatud, järgneb sorteerimine:
1. Tipmine element võetakse kuhjast ära (tema on kõige suurem), selleks vahetatakse 1. ja
viimane element ning kuhja suurust vähendatakse ühe võrra.
Algoritmid ja andmestruktuurid 2015 26
2. Kuhi moodustatakse uuesti sel teel, et tippu sattunud väike element viiakse vastava
protseduuriga oma õigele kohale.
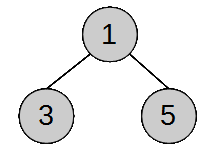
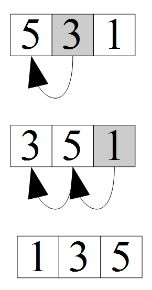
Sorteerida numbrid 351 kahanevas järjekorras. 1.
Panen arvud puusse.
2. Teen maksimaalse kahendkuhja nii, et järglased oleksid vanema
tipu väärtusest väiksemad.
3. Kuhi on moodustatud, hakkan sorteerima. Vahetan omavahel ära
viimase ja esimese indeksi olevad väärtused
4. Panen massiivi:
5
5. Teen uuesti maksimaalse kuhja.
6. Vahetan väärtused ja panen massiivi:
5 3
7. Kuna element on alles vaid 1, siis puu on maksimaalne ja
paneme viimase väärtuse massiivi:
5 3 1
Keerukus: Kahendpuu maksimaalne kõrgus on log n. Seega ajaline keerukus ei saa ületada log n. Siit tulenevalt saame kuhja abil sorteerimise keerukuseks O(n log n). Eripärad : Sorteeritud massiiv hakkab
tekkima massiivi lõpust.
11.1.1 Tugevad küljed • Põhiline eelis: ta on efektiivne
•
Halvima puhul tõestatud keerukus: O(n log n)
•
Sorteerib kohapeal, seega nõuab vaid O(1) lisamälu (mälu efektiivsus)
• The
heap sort algorithm is not recursive
• In-place algorithm: an algorithm that transforms input using a data structure with a small,
constant amount of
storage space
Algoritmid ja andmestruktuurid 2015 27
•
Best at sorting huge
sets of items because it doesn’t use
recursion • If the
array is partially sorted, Heap Sort generally performs much better
than quick sort or merge
sort
11.1.2 Nõrgad küljed •
Aeglasem kui kiirsorteerimine ja mestimisega sorteerimine
• Raske realiseerida
• Ebastabiilne
• Peaaegu sorteeritud massiiviga töötab samakaua kui kaootiliselt sorteeritud
• Algoritmi rakendamine on probleematiline, kui soovitakse kasutada
cache mälu
• Ei toimi ahelaga (linked listiga), sest tahab momentaalset ligipääsu saada
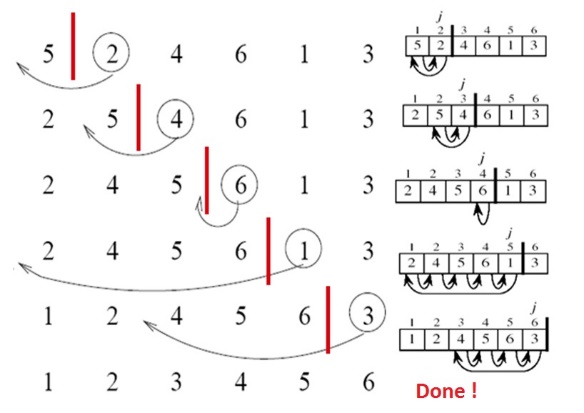
11.2 Lisamissorteerimine (Insertion s.) • Sorteeritud on vasakpoolne massiivi osa, kuid mitte lõplikult.
• Paremalt poolt võetakse järgmine element ja sobitatakse ta sorteeritud poolele õigesse
kohta vahele.
• Esimeseks arvuks tuleb massiivi lisada väga väike arv, millest väiksemat sorteeritavate
kirjete hulgas ei leidu. Seda on vaja, et töö käigus mitte üle minna massiivi algusest.
• Alustades 2. elemendist:
1. Võta kirje.
2. Leia talle sobiv kohta temast vasakul olevate
kirjete hulgas (selleks tuleb teda võrrelda
vasakule poole jäävate kirjetega, kuni
õigekoht on leitud ).
3. Nihuta
kirjed eest ära, et paigutada
vaatlusalune kirje oma kohale.
4. Korda tegevust kõigi kirjetega kuni massiivi
lõpuni.
•
Keerukus: Halvimal ja keskmisel juhul O(n2) ning parimal juhul O(n) (sõltuvalt massiivi eelnevast sorteeritusest). •
Eripärad: o Massiivi sorteerimisel tekitab rohkem raskusi vahelepanekuks ruumi tegemine - kui arv
lisatakse rea algusesse, tuleb nihutada kõiki ülejäänud kirjeid. Sobib paremini juhul, kui
üksik uus kirje on vaja õigesse kohta lisada.
o Või dünaamilise nimistu sorteerimiseks, kus kirjeid ei ole vaja füüsiliselt ümber paigutada
Algoritmid ja andmestruktuurid 2015 28
11.2.1 Tugevad küljed • Lihtne rakendada
• Efektiivne väiksemate andmekomplektide puhul
• Adaptiivne, see on efektiivne nende andmekomplektidega, mis on enam-vähem sorteeritud
• Stabiilne, ei muuda relatiivset järjekorda elementidel, millel on sama väärtus
• Online, st saab sorteerida listi samal ajal kui see suureneb/sisse
jookseb 11.2.2 Nõrgad küljed • Suurte andmestike puhul vähem efektiivne
• Kui elementide arv suureneb, siis programmi kiirus väheneb
• Nõuab palju elementide liigutamist
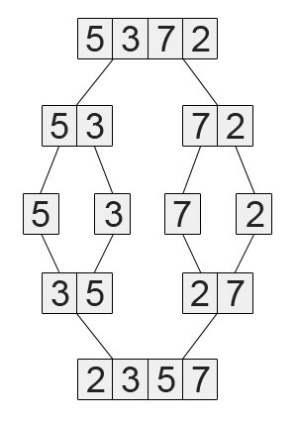
11.3 Mestimisega sorteerimine (Merge s.) • Algoritm koosneb kahest osast – massiivi jagamisest ning kahe osa
ühendamisest.
1. Jaga
algandmed kaheks enam vähem võrdseks osaks.
2. Sorteeri kumbki osa eraldi.
3. Kombineeri mõlemad osad kokku üheks sorteeritud massiiviks.
• Olemuselt on see algortim rekursiivne ja
toetub otseselt lähenemisele "Jaga
ja valitse” (divide et
impera ). Rekursioonist väljudes ühendatakse massiivi osi järjest omavahel,
saades nii üha
pikemad sorteeritud lõigud. Vajab täiendavat mälu ajutiste massiivide tegemiseks
(reaalselt sama palju kui on sorteeritavaid andmeid)
•
Keerukus: O(n log2n) nii halvimal kui ka keskmisel juhul. 11.3.1 Tugevad küljed • Stabiilne
• Toimib hästi koos virtuaalse ja cache mäluga
• Saab tööd jagada protsessorite vahel
• Ei oma “raskeid” sisendandmeid
• Hea sorteerida suurte andmete hulki, mis ei mahu mälus ära
• Hea aeglaselt ligipääsetavate andmete sorteerimiseks, nt
kõvaketas • Suurepärane nende andmete sorteerimiseks, mis jooksevad järjestikuliselt. Nt kõvaketas, linked
list
11.3.2 Nõrgad küljed • Peaaegu sorteeritud andmetega töötaba samakaua kui kaootiliste andmetega
• Nõuab lisamälu
Algoritmid ja andmestruktuurid 2015 29
11.4 Loendamissorteerimine (Counting s.) 1. sammandmed 1 2 1 0
11.4.1 Keerukus loendur 1 2 1
•
012 Kirjeldatud algoritm on ajaliselt keerukuselt lineaarne O(N). 2. sammloendur 1 3 4
012•
, where is the
size of the sorted array and is
3. samm j=3the size of the helper array (range of distinct
values ).
loendur 0 3 4
012massiiv
0
11.4.2 Tugevad küljed • Hea ajalise keerukusega
4. samm j=2 loendur 0 2 4
01211.4.3 Nõrgad küljed massiiv
0
1
• Algoritmi
kasutusvaldkond on piiratud - tema abil sobib
5. samm j=1 loendur 0 2 3
sorteerida
positiivseid täisarve, mis on kindlates piirides
012massiiv
0
1 2
• Algoritm
nõuab täiendavalt mälu kahe massiivi jagu:
loendamiseks ja uue sorteeritud massiivi moodustamiseks.
6. samm j=0 loendur 0 1 3
012Seega hea ajalise keerukusega kaasneb suur mäluline
massiiv
0 1 1 2
keerukus.
• Negatiivsete numbritega ei toimi
11.4.4 Näide algoritmi töö selgitamiseks 1. Loendurmassiivi algväärtustamine
2. Erinevate massiivis olevate väärtuste
loendamine 3. Igale arvule eelnevate arvude kokku lugemine
4. Arvude
paigutamine uude massiivi vastavalt leitud kohale
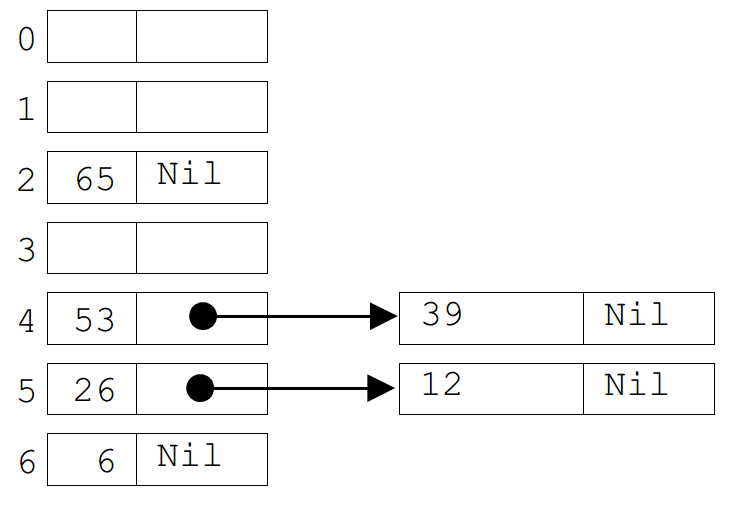
3 massiivi: andmete massiiv, loendurmassiiv ja uus massiiv: 12. Otsimisülesanne. Jadaotsimine. Kahendotsimine. Otsimisalgoritmide keerukus. 12.1 Otsimisülesanne • Otsimine tegeleb probleemida, kuidas koguda andmed arvuti mällu ja meetoditega, kuidas
konkreetseid andmeid sealt leida saab.
• Oluline on organiseerida materjal
selliselt , et ta oleks võimalikult kiiresti kättesaadav.
• Enamasti kasutatakse andmete otsimiseks mingit identifikaatorit nn
võtit K (mis on
unikaalne ).
•
Otsimisülesanne – on N kirjet ja nende hulgast on vaja leida üks konkreetne kirje, mille võti
vastab otsitavale võtmele K. Vastav kirje tagastatakse või antakse teada, et sellise võtmega kirjet
ei leitud.
Algoritmid ja andmestruktuurid 2015 30
12.2 Jadaotsimine/järjestikotsimine •
Idee – alusta algusest ja võrreldes iga kirje võtit otsitava võtmega jätka nii kaua, kuni on leitud
otsitav võti, seejärel peatu. Või jõua peale kõigi kirjete läbivaatamist arusaamisele, et sellise
võtmega kirje puudub.
• On kõige
lihtsam. Saab lõppeda edukalt kui ka edutult.
•
Keerukus on
lineaarne O(N). • Kui otsitav element on 1. lahtris, on ta käes esimese
sammuga , kui elementi pole, tuleb kogu
massiiv läbi vaadata, et selles veenduda.
•
Võtmete paiknemise kohta tabelis igasugune eeldus puudub.
• Toimib hästi massiiviga, kuid võib kasutada ka lineaarse nimistu korral.
12.3 Kahendotsimine • Eeldus: tabel peab olema
järjestatud.
•
Võtmed paiknevad nõnda: k0
























































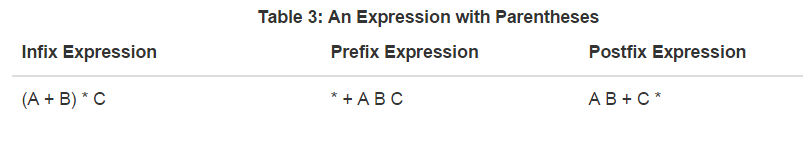





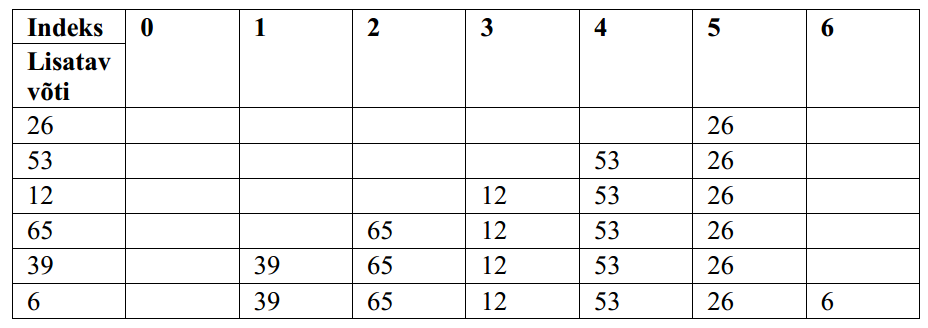
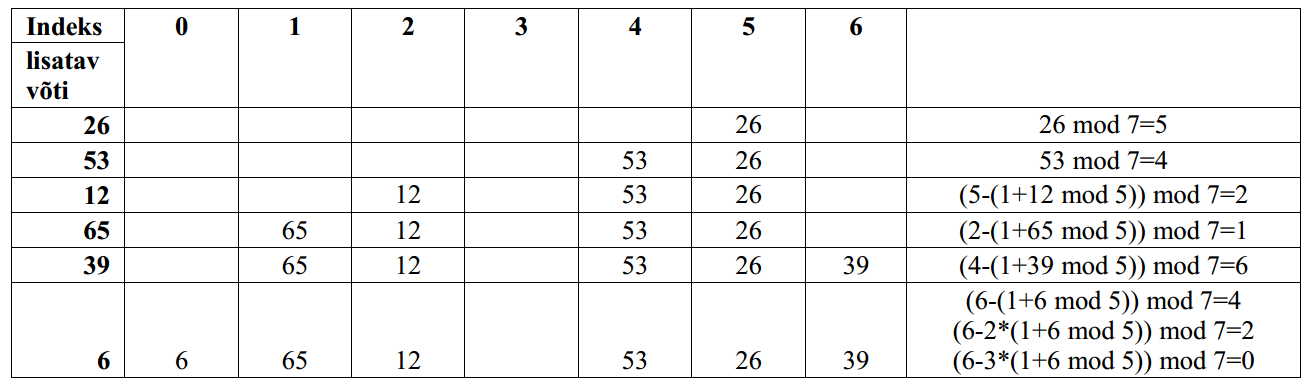





Kõik kommentaarid