Kordamisküsimused aines "Algoritmid ja andmestruktuurid"
Eksamil 1 komplekt katseid Moodles.
Enne enesetesti õpi ära asümptootiliste relatsioonide (hinnangute?) definitsioonid.
Lõppeksam koosneb teooriaküsimustest ning programmeerimisülesannetest. Eksam toimub
arvutiklassi arvutitel e-õppe keskkonnas ning kestab 150 minutit.
Meetod
Keskmine
Halvim
Insertion sort,
pistemeetod
О(n2)
O(n2)
Stabiilne
Binary search,
kahend
otsimine
O(log n)
O(log n)
Kahendpistemeetod,
binary insertion sort
Stabiilne.
Quicksort,
kiirmeetod
O(n logn)
O(n2)
Ei ole stabiilne.
Radix sort,
positsioonimeetod
O(n)
O(n)
Stabiilne.
Merge sort,
ühildusmeetod
O(n logn)
O(n logn)
On enamasti
stabiilne.
Paisktabel, hash
table
O(1)
O(1)
Heap sort,
kuhjameetod
O(n logn)
O(n logn)
1. Algoritmi omadused. Algoritmide asümptootiline analüüs: relatsioonid "suur-
O", "väike-o", teeta, "suur-oomega" ja "väike-oomega"; nende definitsioonid
ning põhiomadused. Mida miski täpselt tähendab.
Algoritm on täpne (üheselt mõistetav) juhis antud ülesande lahendamiseks. Algoritm
koosneb lõplikust arvust sammudest, millest igaüks on täidetav lõpliku aja jooksul lõplikke
ressursse kasutades. Algoritmi rakendatakse teatavale lähteandmete komplektile (sisend)
ning ta annab teatava resultaadi (väljund).
Kui algoritm lõpetab töö (peatub) mistahes sisendi korral, siis nim. seda
kõikjal määratud algoritmiks, vastasel juhul
osaliseks algoritmiks (võib jääda lõputusse tsüklisse).
Kui algoritmi mistahes sammu täitmise järel on üheselt määratud, milline on järgmine samm,
siis nim. algoritmi
determineeritud algoritmiks.5 tükki. Kõik iseloomustavad f ja g omavahelist suhet. f on hinnatav funktsioon, g on
etalonfunktsioon. Definitsioonid on keerukuse konspektis ära toodud. Eksamil on
definitsioonid ainuke asi, mida tahab tagasi saada.
Algoritmi iseloomustamiseks kasutatakse järgmisi mõisteid:
●
Korrektsus (algoritm lahendab "õiget" ülesannet, tulemus vastab spetsifikatsioonile).
●
Määratletus (sammud on lõplikud ja üheselt määratud).
●
Kirjelduse lõplikkus (algoritm on kirjeldatav lõpliku arvu sammudega).
●
Peatuvus. Töö lõpetamine mistahes sisendi korral - kõikjal määratud algoritm.
Osaline e. "poollahenduv" algoritm kas annab tulemuse või ei lõpeta tööd.
●
Determinism (samade algandmete korral vastus sama, lahenduskäik on korratav)
vs. mittedeterminism (näit. "tõeline" juhuarvude generaator).
●
Universaalsus (lahendab probleemide klassi: sisend -> väljund) sõltumata
algandmetest.
●
Keerukus (efektiivsus, kas lõpetamise aeg ja/või mälumaht on praktilised).
Algoritmid vastavad spetsifikatsioonine (teevad töö ära) aga käituvad väga erinevalt.
Ressurss võib olla aeg või mälumaht, mida saab kasutada.
Algoritmi hindamiseks kasutatakse algoritmi töökiirust - ülesande lahendamiseks vajalike
sammude arv ja nende sõltuvus algandmete mahust. Aega mõõdame tähtsate
operatsioonide arvus.
Asümptootiline hinnang - funktsioonide käitumine algandmete mahu piiramatul
kasvamisel. n - algandmete maht. Algoritmi asümptootilise keerukuse seisukohalt loeb ainult
see osa, mis on kõige keerukam. Terviku keerukus on osade keerukuste maksimum.
Polünomiaalse keerukusega algoritm - ajaline keerukus O(nd). Väga tähtis klass, kuna
ülejäänud (nendest ajaliselt keerukamad) algoritmid osutuvad vähegi mahukamate
algandmete puhul lootusetult aeglaseks. Iga polünoom kasvad tohutult aeglasemalt kui
eksponent (dn). Polünoomi ja eksponendi vahel on veelahe.
Raskelt lahenduvad ülesanded - ülesanded, mille jaoks ei ole teada polünomiaalse
keerukusega algoritmi. Võib olla ka ülesanne, mille kohta pole suudetud tõestada, et ta on
mittepolünomiaalne.
Θ (teeta)
Ω
ω
Ajaline keerukus. Asümptootilised hinnangud, "suure O", "väikese o", "suure oomega",
"väikese oomega" ja teeta-tähistused:
n - algandmete maht
f(n) > 0 - lahendamisaeg
g - etalonfunktsioon. Võrdleme hinnatavat funktsiooni f etalonfunktsiooni vastu.
Kasvu kiirust iseloomustavad suhted, funktsoonide vahel.
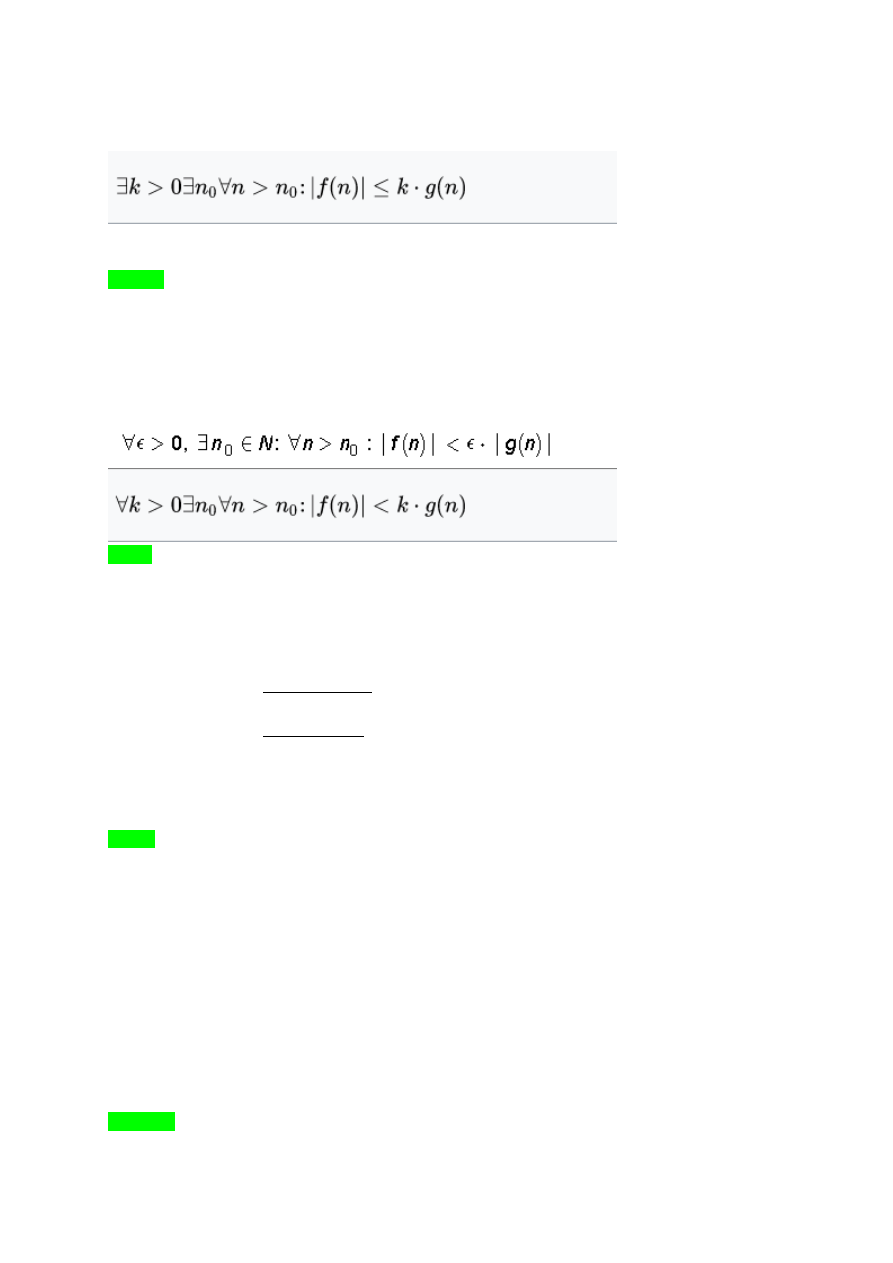
Öeldakse, et f on suur O g’st juhul kui kui leiduvad niisgune konstant c ja niisugune
naturaalarv N, et iga n-suurem-N’st korral...
"f kasvab mitte kiiremini kui g" ( f big-Oh g ) -
leiduvad konstant c>0 ja koht N nii, et iga
n>N korral
|f(n)| < c|g(n)|
f ja g suhe on ülalt tõkestatud.
"f kasvab aeglasemalt kui g" ( f little-oh g ) -
mistahes konstandi c>0 jaoks leidub koht N
nii, et iga n>N korral
|f(n)| < c|g(n)|
f ja g suhe pole alt tõkestatud.
"f kasvab niisama kiiresti kui g" ( f big-Theta g ) - leiduvad konstandid b, c>0 ja koht N nii,
et iga n>N korral
b|g(n)| < |f(n)| < c|g(n)|
f ja g suhe on nii ülalt kui ka alt tõkestatud.
"f kasvab mitte aeglasemalt kui g" ( f big-Omega g ) - "g kasvab mitte kiiremini kui f"
f ja g suhe on alt tõkestatud.
"f kasvab kiiremini kui g" ( f little-omega g ) - "g kasvab aeglasemalt kui f"
f ja g suhe pole ülalt tõkestatud.
2. Kahendotsimine (binary search). O(log n)
"Lõigu poolitamine" matemaatikas. On rakendatav kahel eeltingimusel:
● vaadeldav struktuur on järjestatud
● elemendid on indekseeritavad
Binary insertion sort on stabiilne (järjestamise mõistes), kui jätab võrdsed elemendid
samasse järjekorda nagu nad alguse on.
3. Paisksalvestus, paisktabel (hash table). Lk 45.
Lisamine ja otsimine: O(1).
Võtmeruum - kõikide võimalike võtmete hulk. Täisarvude puhul kõikide täisarvude hulk.
Iga võtmega seatakse vastavusse mingi mõistlik reanumber, et tabel oleks mõistlike
suurustega.
Funktsioon annab välja tabeli rea, mitmendal selle võtmega väärtus paikneb.
Kui tabel on väiksem kui võtmeruum, siis võib juhtuda, et üks võti annab kaks erinevat
väärtust näiteks (põrge, kollisioon).
Hashi arvutamine toimub konstantses ajas. Ei sõltu võtmeruumi suurusest ega võtmete
arvust.
hash(k) -> i paiskfunktsioon
Kollisioon ehk põrge on see, kui key1 ≠ key2 aga h(k1) = h(k2). Tuleb ära
lahendada.
Põrgete vältimiseks välisahelate meetod, lahtise adresseerimise meetod ja topelt-
paiskamise meetod. Kõigi mõte on leida niisugustele võtmetele, mille puhul paiskfunktsioon
annab sama võtme väärtuse, leida niisugune asukoht tabelis, et konstantse keerukusega
otsimine ei läheks kaduma.
4. Järjestamine: pistemeetod (insertion sort) ja kiirmeetod (quicksort).
Lihtne pistemeetod - "aeglased" meetodid: O(n2). Jada jagatakse "järjestatud osaks"
(algselt tühi) ja "järjestamata osaks" (algselt kogu jada). Järjestatud osa pikkust
suurendatakse järjekordse elemendi paigutamisega õigele kohale järjestatud osas.
Kahendpistemeetod - "Õige" koht leitakse kahendotsimisega: O(nlogn), kui "pistmine"
oleks O(1). Pseudokiire meetod. Nihutamine on ikka aeglane.
Kiirmeetod, quicksort - O(
nlogn). (Osa)jada jagatakse kaheks lühemaks osajadaks nii, et
ükski element esimeses osas ei oleks suurem ühestki elemendist teises osas. Siis võib
kummagi osa sorteerida eraldi (nad on sõltumatud). "Jaga ja valitse". Halvima juhu keerukus
võib olla probleemiks. Ei ole stabiilne.
Iga kiire meetod on täpselt nlogn. Võrdlustel põhinevaid meetodid ei saa olla kiiremad.
5. Jaga ja valitse: ühildusmeetod (merge sort).
"Jaga ja valitse" : jagatakse kogu aeg pooleks (kuni pikkus < 2), pooled ühendatakse
lineaarse keerukusega ühildamise abil, kasutatakse lisamälu mahuga O(n).
MS paneb kaks hulka kokku nende järjestatud ühendiks lineaarse ajaga.
Poole võrra jääb all quicksortile aga alati saab hakkama
nlogn ajaga (st halvimat juhtu ei
ole). Puuduseks on see, et vajab lisamälu niisama palju kui on tavamälu. MS on enamasti
stabiilne.
Töötab alt üles.
6. Lineaarse keerukusega järjestamismeetodid: kimbumeetod (bucket sort),
positsioonimeetod (radix sort) ja loendamismeetod (counting sort).Erimeetodid. O(n) ehk lineaarne.
Loendamismeetod - eelduseks, et loendatavatel hulkadel on vähe võimalikke väärtuseid
(sikud, lambad). Kasutab lisamälu võimalike väärtuste hoidmiseks. Teed sõnastiku, et mitu
midagi on (ehk loed üle) -> teed indeksite sõnastiku -> laod järjest tagant poolt ette poole, et
oleks stabiilne.
Kimbumeetod (bucket sort) - A(n) = O(n), A(w) = O(n2). Stabiilne.
Positsioonimeetod (radix sort) - kasutab loendamist aga jagab järjestamise võtme
positsioonideks. Stabiilne.
7. Abstraktsed andmetüübid (ADT), staatilised ja dünaamilised
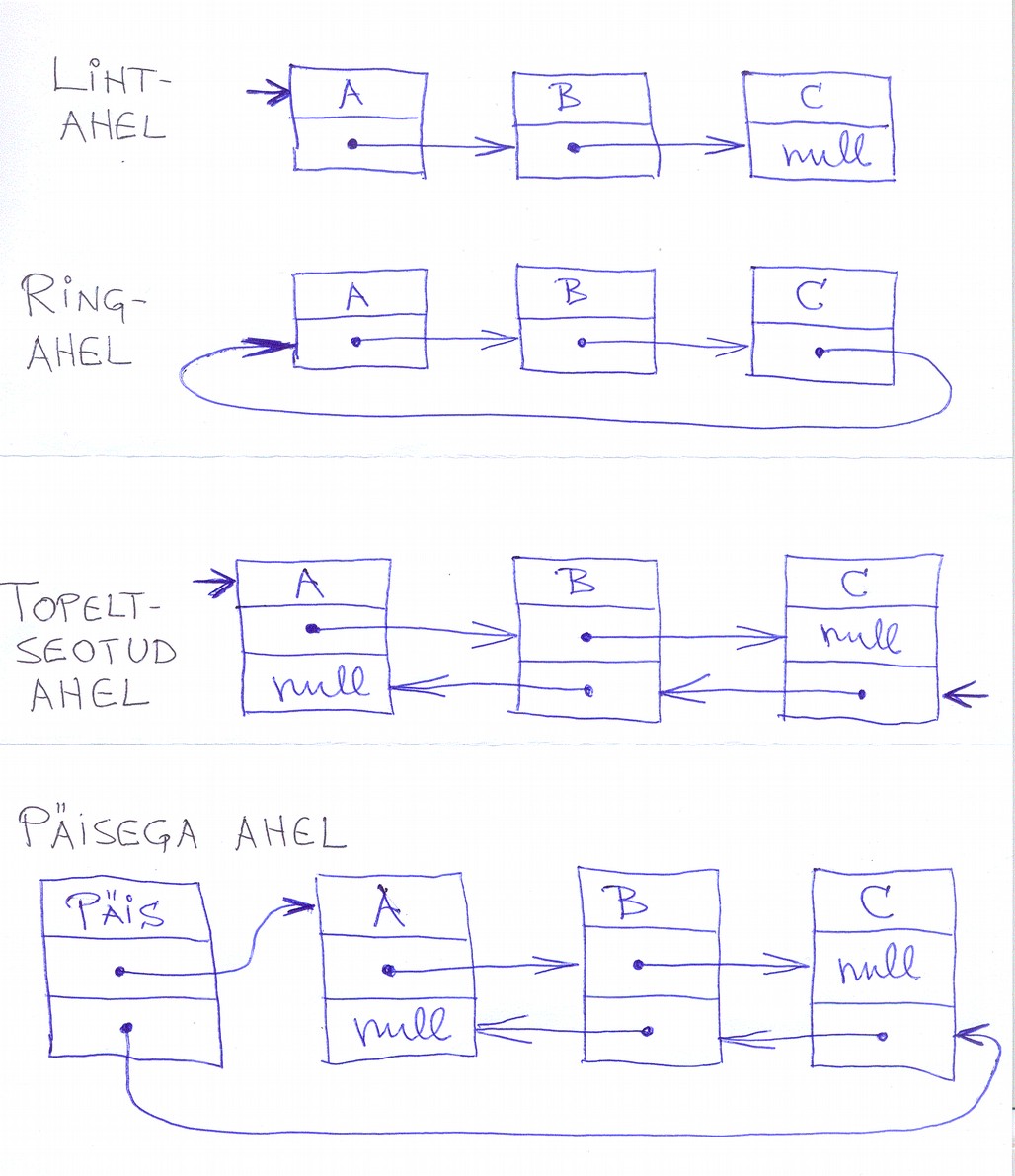
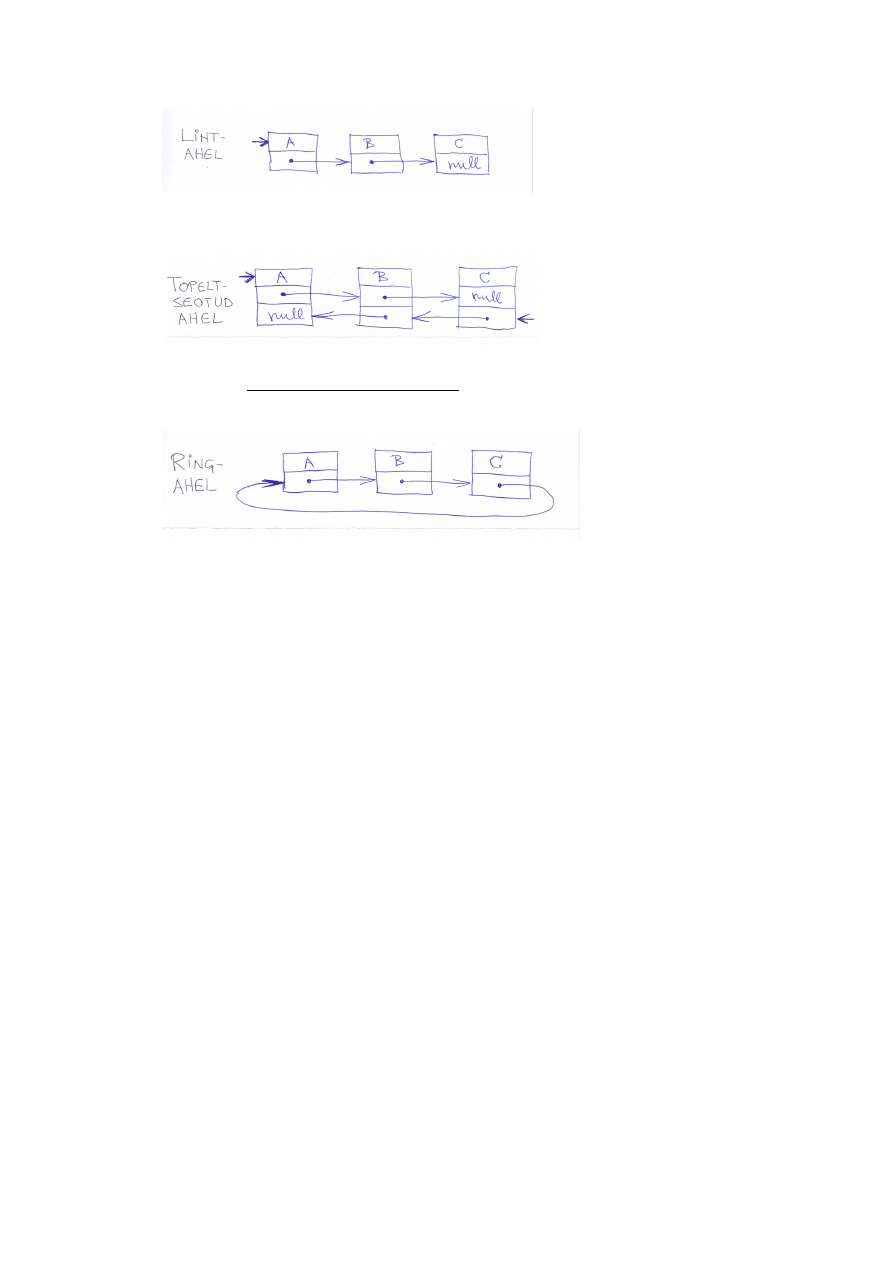
andmestruktuurid. Ahel (list), ahelate liigid.
"Varajane" OOP. Eesmärk: peita realisatsiooni detailid, anda rakenduse programmeerijale
probleemorienteeritud liides. ADT - Abstract Data Type
● Lubatud väärtuste hulk (väärtusvaru)
● Lubatud operatsioonide hulk
● (Notatsioon - tähistused väärtuste ja operatsioonide jaoks)
Andmestruktuurid võib jagada:
●
staatilised: komponentide arv ja tüübid fikseeritud: näiteks kompleksarv
●
dünaamilised: väärtuse komponentide arv on muutuv, komponendid ise tavaliselt
üht tüüpi: näiteks magasin, järjekord, graaf, ...
Ahelad
Ahel on tee, milles servad ei kordu. Ei jõua tagasi samasse punkti. Tsükli saab ühe kaare
lisamisega.
Lihtahel on ahel, milles ka tipud ei kordu.
Ahel koosneb muutuvast arvust elementidest, mis on omavahel seotud viitadega. Keeles
Java ei ole viidatüüpi operatsioone ilmutatud kujul olemas - iga objektitüüpi väärtus on
"tegelikult" viit.
Lisamine ja
kustutamine on lihtsalt kolm omistamist (viitade ümberlülitus) ja
nihutamist ei olegi vaja. Vaba mäluga tegeleb prügikoristus.
●
Lihtahel (linked list) - iga element sisaldab viita järgmisele (Java seisukohalt -
sisaldab järgmist elementi isendimuutujana), ahela lõpetab nullviit. Liikumine ainult
üht pidi.
●
Topeltseotud ahel - iga element sisaldab kaht viita: järgmisele elemendile ja
eelmisele elemendile
●
Ringahel - puudub ahelat lõpetav nullviit (Javas objekti puudumist tähistav null),
elemendid moodustavad "ringi". Nullpointerit ei ole.
●
Päisega ahel - ahelale on lisatud formaalne lüli, mis ei kuulu ahela koosseisu, aga
viitab esimesele (topeltseotud ahela korral ka viimasele) lülile. Vajalik selleks, et tühi
ahel kujutuks objektina (mitte nullviidana).
8. Magasin, pinu (stack).
LIFO - last in first out.
Magasini omadused:
● dünaamiline struktuur (elementide arv on muutuv)
● elemendid on sama tüüpi (üldjuhul)
● elementide järjestus on oluline
● juurdepääs on ainult viimasena lisatud elemendile (magasini tipp); "lisamine" lisab
lõppu ja "võtmine" eemaldab lõpust
● tavaliselt realiseeritavad operatsioonid: tühja magasini loomine, lisamine (push),
võtmine (pop), alatäitumise (underflow) kontroll (et vältida tühjast magasinist võtmist),
mõne realisatsiooni korral ka ületäitumise (overflow) kontroll (kas on "ruumi"
lisamiseks, sõltub mälust), tipu lugemine ilma eemaldamiseta (optim. kaalutlustel)
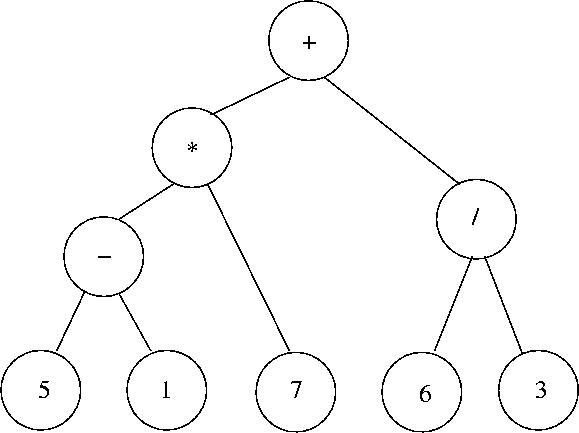
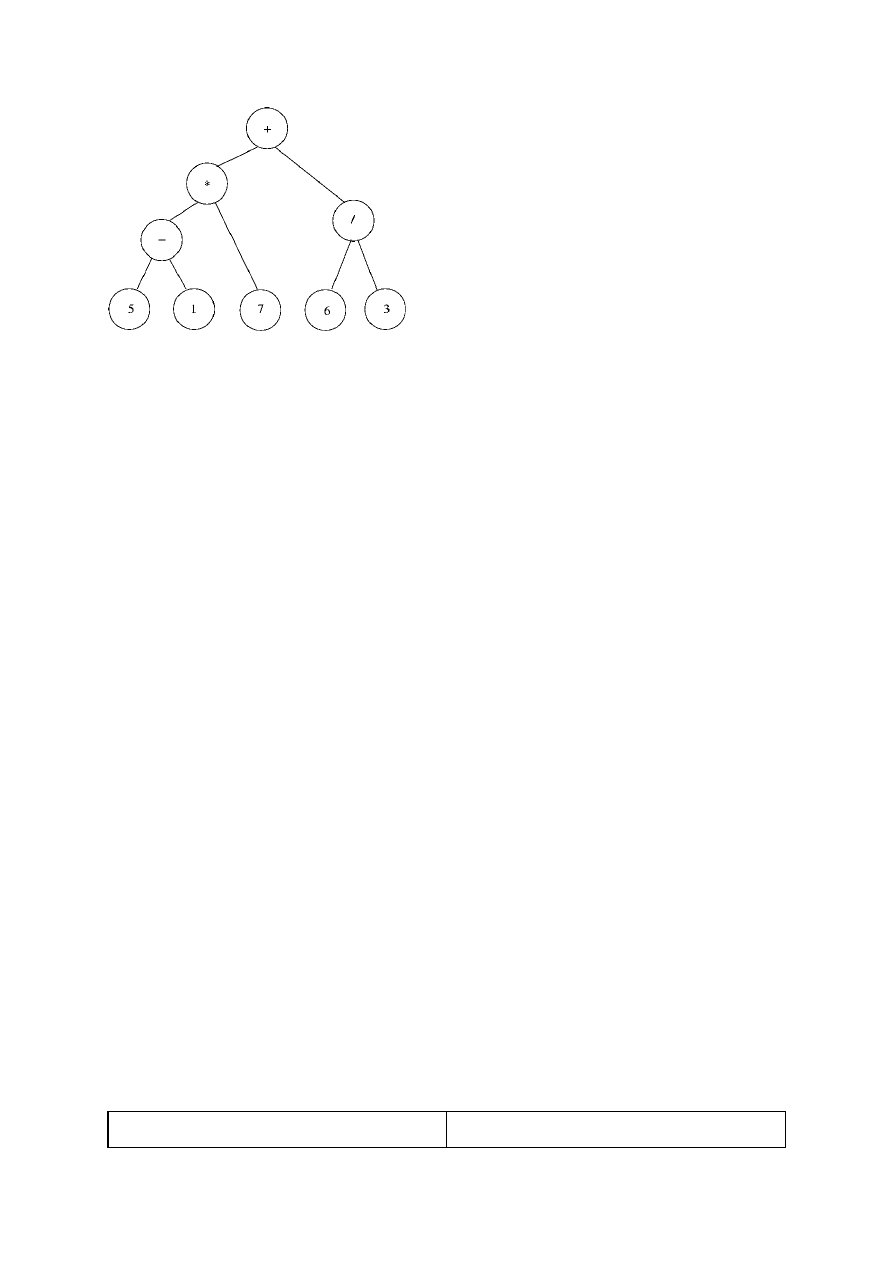
8.1. Avaldise pööratud poola kuju (RPN).Post order: 5 1 - 7 * 6 3 / +
In order: 5 - 1 * 7 + 6 / 3 (ilma prioriteedi sulgudeta ei ole üheselt taastatav puu)
"Tavaline" infikskuju: (5-1) * 7 + 6 / 3
Prefikskuju sulgudega: +( *( -( 5, 1), 7), /(6, 3))
Postfikskuju sulgudega: (((5, 1)-, 7)*, (6, 3)/ )+
Sulgudeta postfikskuju - nn.
"pööratud poola kuju": 5 1 - 7 * 6 3 / +
a+b infiks - peab teadma tehete prioriteete
+(a,b) prefiks
(a,b)+ postfix
ab+ RPN - eeldatud, et teame, mitu operandi mingi operatsioon tarvitab.
9. Järjekord (queue), järjekordade eriliigid.
FIFO - First In First Out
Staatiline eelistusjärjekord - priority queue
Järjekord, milles on olulised elementide (võtmete) väärtused. Prioriteetidega järjekord.
"Lisamine" on sisuliselt hulgateoreetiline lisamine ja "võtmine" on vähima (suurima)
võtmeväärtusega elemendi eemaldamine. Kui prioriteedid on staatilised (ei muutu elemendi
järjekorras olemise ajal), siis saab "lisamise" teha pistemeetodi abil "Õigesse kohta".
Prioriteedi tõstmine on halb idee. Ainuke võimalus reaalajasüsteemi manipuleerida, siis
ainuke tehe, mida tohib teha on prioriteedi vähendamine.
Muutuvate eelistustega järjekord - keegi muutub õppejõuks järjekorras seismise ajal
Kui elemendi prioriteet võib elemendi järjekorras olemise ajal dünaamiliselt muutuda
(niisugust järjekorda nim. muutuvate eelistustega järjekorraks), siis tuleb "võtmine"
realiseerida järjekorra läbivaatusena ("lisamine" on selle eest lihtne). Teine võimalus on
kajastada iga prioriteedimuutust kohe järjekorras, aga see ei pruugi olla hea lahendus
(näiteks kui muutusi on palju, aga võtmisi vähe).
STACK (magasin, pinu)
QUEUE (järjekord)LIFO - last in first out.
FIFO - First In First Out
dünaamiline struktuur (elementide arv on
muutuv)
dünaamiline struktuur (elementide arv on
muutuv)
elemendid on sama tüüpi
elemendid on sama tüüpi
elementide järjestus on oluline
elementide järjestus on oluline
juurdepääs on ainult
viimasena lisatud
elemendile (magasini tipp); "lisamine" lisab
lõppu ja "võtmine" eemaldab lõpust
juurdepääs on ainult
esimesena lisatud
elemendile (front); "lisamine" lisab lõppu ja
"võtmine" eemaldab algusest (järjekorra
metafoor)
tavaliselt realiseeritavad operatsioonid: tühja
magasini loomine, lisamine (push), võtmine
(pop), alatäitumise (underflow) kontroll (et
vältida tühjast magasinist võtmist), mõne
realisatsiooni korral ka ületäitumise (overflow)
kontroll (kas on "ruumi" lisamiseks), tipu
lugemine ilma eemaldamiseta (optim.
kaalutlustel)
tavaliselt realiseeritavad operatsioonid: tühja
järjekorra loomine, lisamine, võtmine,
alatäitumise (underflow) kontroll (et vältida
tühjast järjekorrast võtmist), mõne realisatsiooni
korral ka ületäitumise (overflow) kontroll (kas on
"ruumi" lisamiseks), vahendid järjekorra
läbivaatamiseks (näit. iteraatorid vms.)
10.
Puu, puu kujutamine. Suluesitused.
Puu põhiomadus - igal tipul on üks ülemus. Juutipul ei ole ülemust. Puu on ilma tsükliteta
graaf.
Node - vahetipp
Juurtipp ehk juur - root node, kogu hierarhia kõige kõrgem tipp (üleval)
Leht ehk terminaalne tipp - see tipp, millel ei ole enam alluvaid. Hierarhias kõige madalamal
positsioonil. Terminal node, leaf (all)
Kõik, mis pole lehed on
vahetipud (nonterminal
node, intermediate
node).
Kas sama tipu alluvate järjestus on oluline? Arvutis folderite puhul ei ole. Aga on olukordi,
kus see on hästi oluline - nt aritmeetilise avaldise puu, kus selles sõltub tehete järjekord.
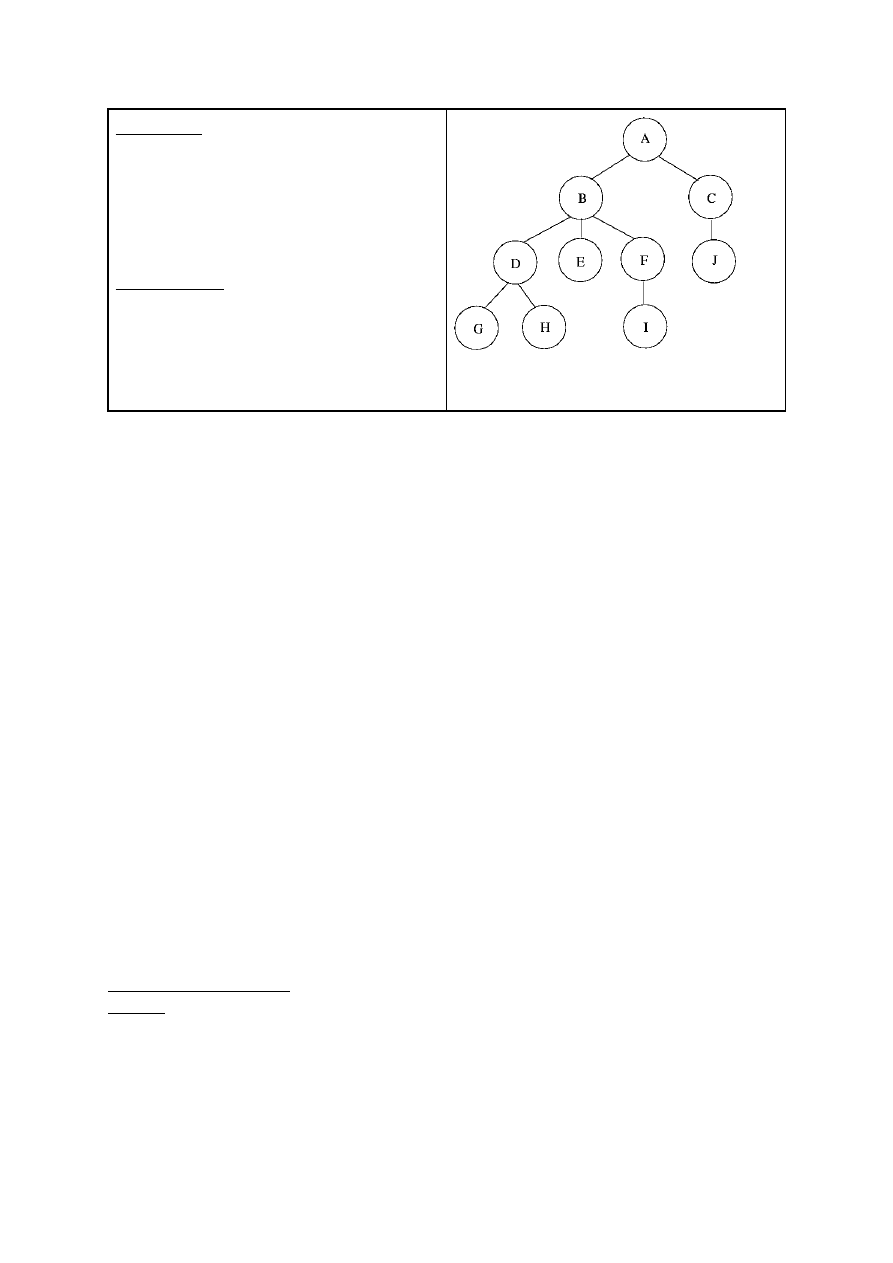
Esitusviisid:
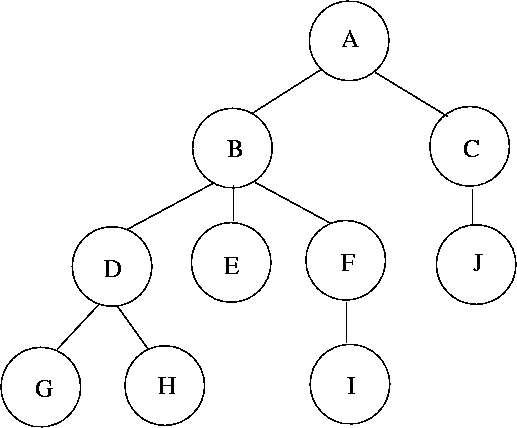
Vasakpoolne suluesitus
A(B(D(G,H),E,F(I)),C(J))
Parempoolne suluesitus
(((G,H)D,E,(I)F)B,(J)C)A
Läbimise viisid
Pre-order: A B D G H E F I C J
Post-order: G H D E I F B J C A
In-orderit ei saa teha, sest pole 2 alluvat
alati.
Puu kujutamine: graafiline (joonisena) nt vaba puu (nagu graaf), trepitud tekstina vms.
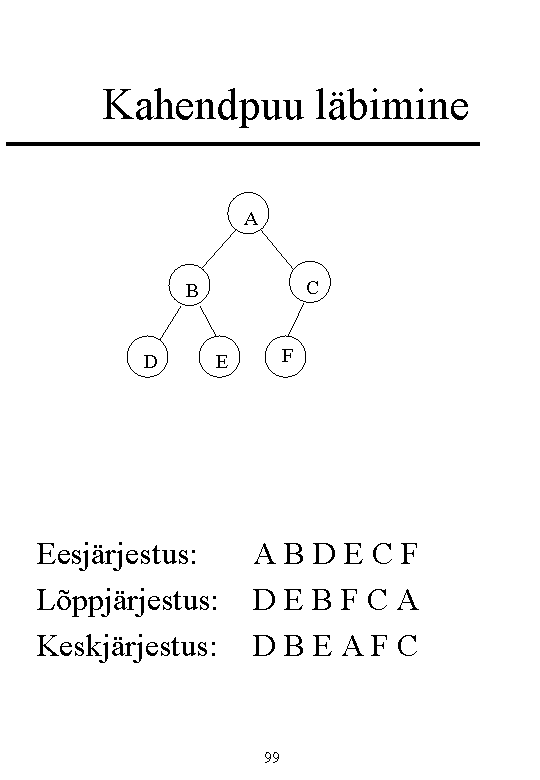
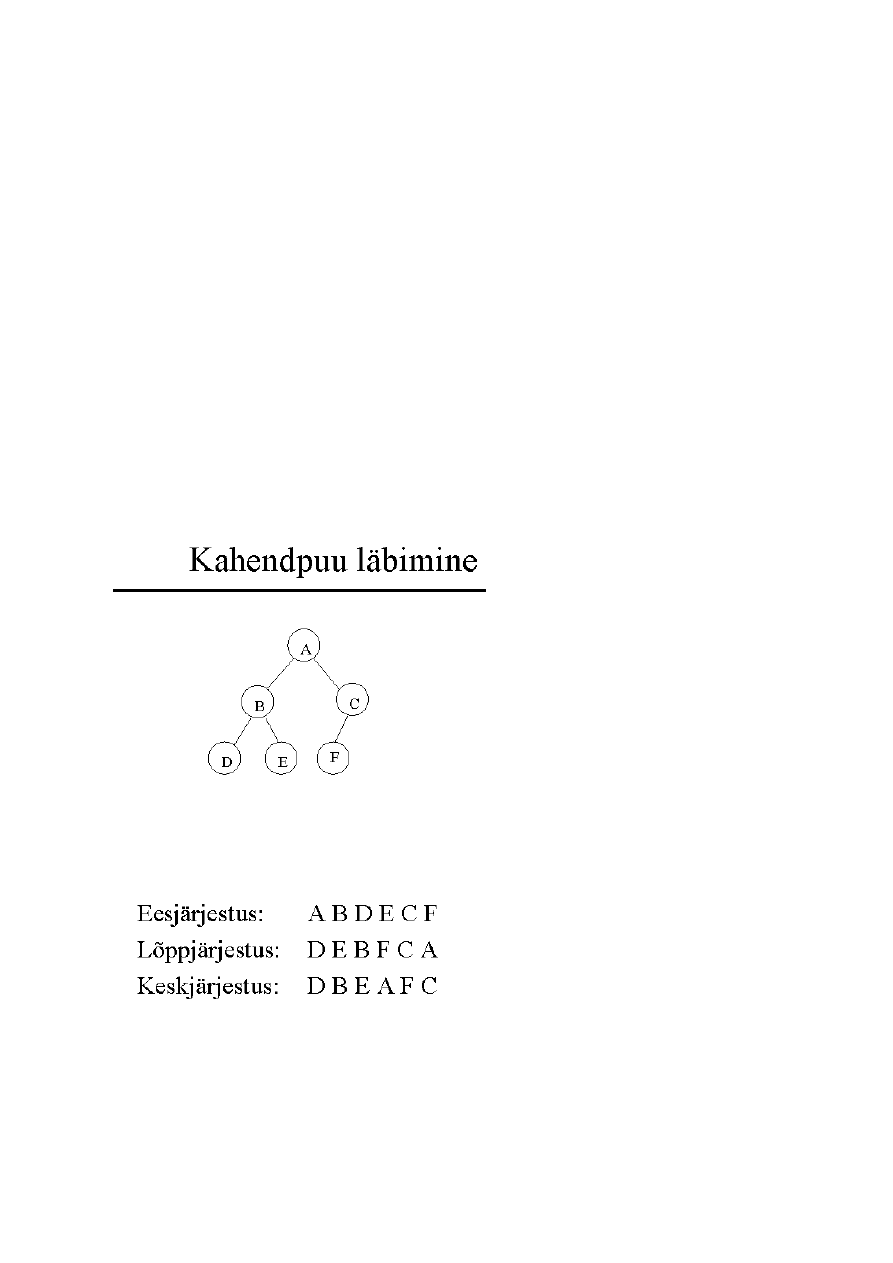
11. Puu läbimise viisid (3 tk) (põhialgoritmid).
Eesjärjestus (pre-order):
Töödelda juur
Töödelda juure alampuud järjestuses vasakult paremale
Lõppjärjestus (post-order, end-order):
Töödelda juure alampuud järjestuses vasakult paremale
Töödelda juur
Kahendpuu läbimine keskjärjestuses (in-order)
Töödelda vasak alampuu
Töödelda juur
Töödelda parem alampuu
Avaldise prefikskuju saadakse puu läbimisega eesjärjestuses, postfikskuju (ja pööratud
poola kuju) puu läbimisega lõppjärjestuses; läbimine keskjärjestuses ei anna praegusel juhul
üheselt taastatavat avaldist!
Post-order ehk end-order - kõigepealt töödelda alluvad. Tulemuseks pööratud Poola kuju
In-order - võimalik, kui igal vahetipul on täpselt 2 alluvat. In orderilt (ilma sulgudeta) ei saa
puud üheselt taastada.
Prefikskuju sulgudega: + (* (- (5, 1), 7), / (6, 3)) Pre order
Postfikskuju sulgudega: (((5, 1)-, 7)*, (6, 3)/ )+ Post order, end order
5-1 * 7 + 6 / 3 in- order pealt ei ole võimalik puud üheselt taastada ilma sulguteta. Saab.
Eksam. Joonistada variandid puudest, mis annavad ühesuguse in-orderi järjekorra. Nt 5 - 1 *
7 + 6 /3 on in-order, mis võib anda erinevaid puid.
Eksamil. Kui puu on antud, siis peab oskama Moodle’isse vastusena kirja panna orderid
(preorder, postorder, inorder).
Eksamiülesanne (6. Loeng 1:20). Programm, mis arvutab puu tippude arvu.
Globaalne loendur ja suurenda seda, kui tippu näed.
public int size()
return n;
}
https://enos.itcollege.ee/~jpoial/algoritmid/TreeNode.java
12. Graaf, graafiga seotud mõisted: orienteeritud ja orienteerimata graaf,
multigraaf, lihtgraaf, sidusus, alamgraaf. Mõisted küsib enda konspekti
järgi.
Graaf on hulk, mis koosneb tippude lõplikust hulgast V ja nende tippude vaheliste seoste
hulgast.
Orienteeritud graaf - kui on määratud tippude vahelise seose (ehk kaare) algus ja lõpp punkt
Orienteerimata graaf - kui ei ole määratud tippude vahelise seose (ehk serva) algus ja lõpp
punkt.
Multigraaf - kui kahe tipu vahel on mitu kaart (korduvad kaared on lubatud). Saab teha
tavaliseks graafiks, kui panna tippe vahele.
Lihtgraaf -
silmuste (kaar iseendasse) ja kordsete servadeta orienteerimata graaf
Sidusus:
● Orienteerimata graafi nim. sidusaks, (orienteeritud graafi tugevalt sidusaks) kui leidub
tee mistahes tipust mistahes teise tippu.
● Orienteeritud graaf on nõrgalt sidus, kui kaarte suundade ärajätmisel saadav
orienteerimata graaf on sidus.
Alamgraaf - väljavalitud tipud ja kõik ühendused nende tippude vahel. Kui V1 on hulga V
alamhulk ja E1 on E ühisosa hulgaga V1xV1
Täisgraaf - igast tipust pääseb otse igasse teise tippu
Tsüklit, mis läbib kõik graafi servad täpselt ühe korra, nim
Euleri tsükliks. Väga lihtne.
Königsbergi sildade ülesanne. Vaja on seda, et igas tipus sisenevate ja väljuvate servade
arv oleks võrdne (paarisarv servi).
Kõiki tippe täpselt üks kord läbivat tsüklit nim.
Hamiltoni tsükliks. Probleem, mille jaoks ei
ole teada polünomiaalse keerukusega algoritmi. Tegemist on hard keerukusega
probleemiga. Väga keerukas.
13. Graafi kujutamine, graafiga seotud maatriksid, tehted graafidega.
Adj(v) - kaarte hulk V, mille alguseks on sama tipp.
1. Joonis (huvipakkuv probleem selles valdkonnas - tasandilised graafid).
2. Kaarte loetelu (eeldades, et otstippude kohta käiv informatsioon on kaares olemas).
Sellise loetelu organiseerimiseks on palju võimalusi.
3.
Eksam. Külgnevusmaatriks (kaaslusmaatriks) jt. graafi ühest taastamist võimaldavad
maatriksid.
Tabel, kus on tippude arv ridu ja veerge. Igas lahtris on ühenduste arv nende tippudevahel.
4. Külgnevusstruktuur - tippude loetelu, milles iga tipuga on seotud sellest lähtuvate
(väljuvate) kaarte loetelu (iga kaare kohta on teada tipp, kuhu ta suubub).
Hakkame graafe korrutama ja liitma. Idee on teha nii, et kui on tehe kahe graafi vahel, siis
maatriks tulemusest on maatriks G1st ja maatriksite ruumis tehtud tehe selle teise graafi
maatriksiga.
Kui kaks graafi kokku liidad siis tulemuseks on graaf, mille tippude hulk on
liidetavate hulkade ühend ja kaarte/servade hulk on kõikide olemasolevate servade
hulgateoreetiline ühend. Korduvaid ei tekki.
Korrutis
- On vaja, et tippude hulgad oleks samad. Sisuliselt on tegemist
maatriksite korrutamisega. Esimeses liigume ühe sammu, teises teise sammu
→ Järelikult saame kolmandast tagasi esimesse. Suuremal graafil vaatad
kõik punktid nii läbi.
Süsteemne viis, kuidas seda tehakse, kannab nime Floyd-Washalli algoritm.
Leiab lühimad teepikkused kõigi tipupaaride vahel: Floyd-Warshalli algoritm
,
kuupkeerukusega O(n3) (NB! Ei leia teed ennast vaid ainult selle pikkuse!)
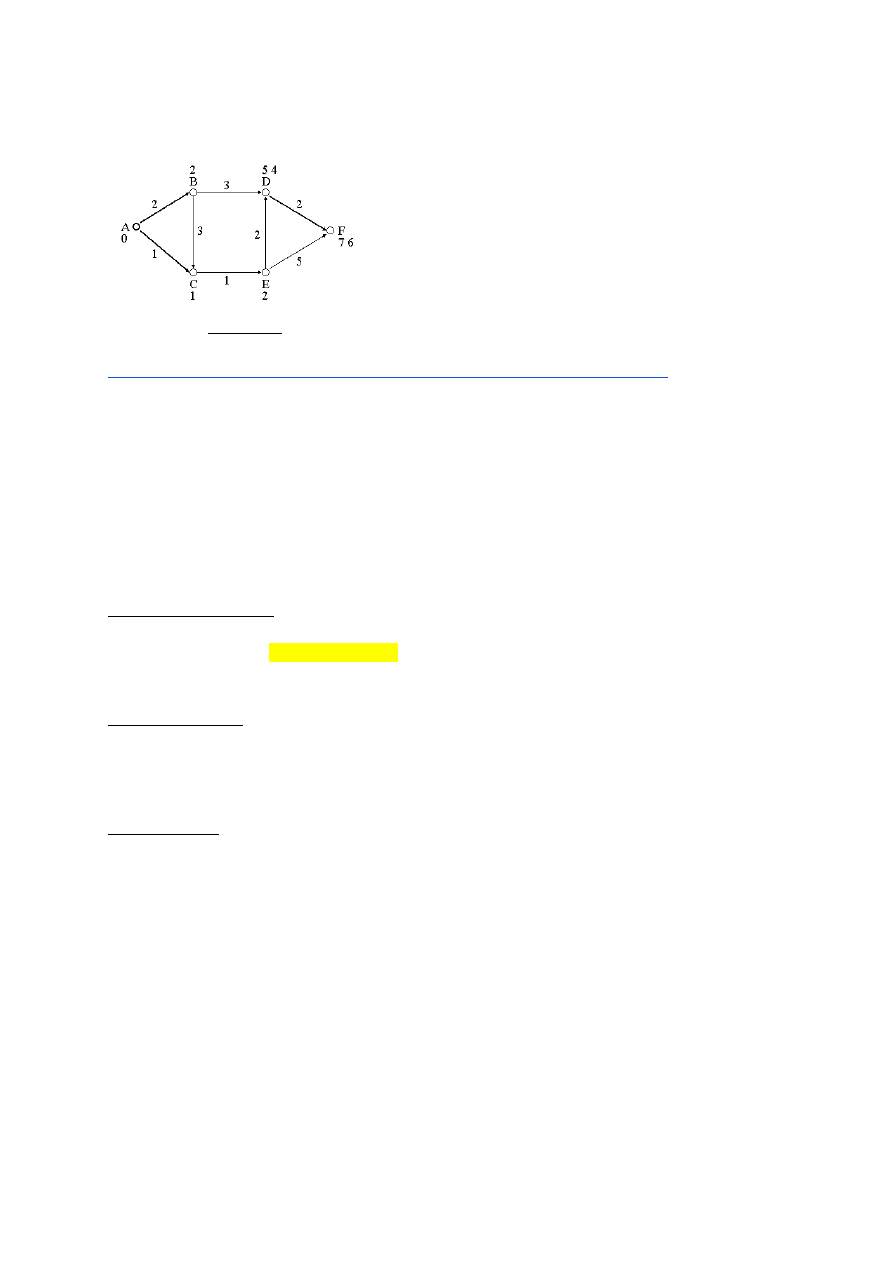
Lühim teepikkus lähtudes antud tipust: Dijkstra algoritm
Kaalude maatriks - element näitab toru jämendust. Mida suurem on arv, seda tugevam on
ühendus (laiem, mahutavam on ühendus).
Kauguste maatriks -
Graafide võrdlemine (equals meetod) on väga keeruline ülesanne. Puude isomorfism on
ülilihtne.
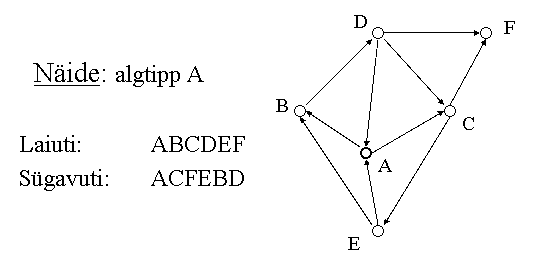
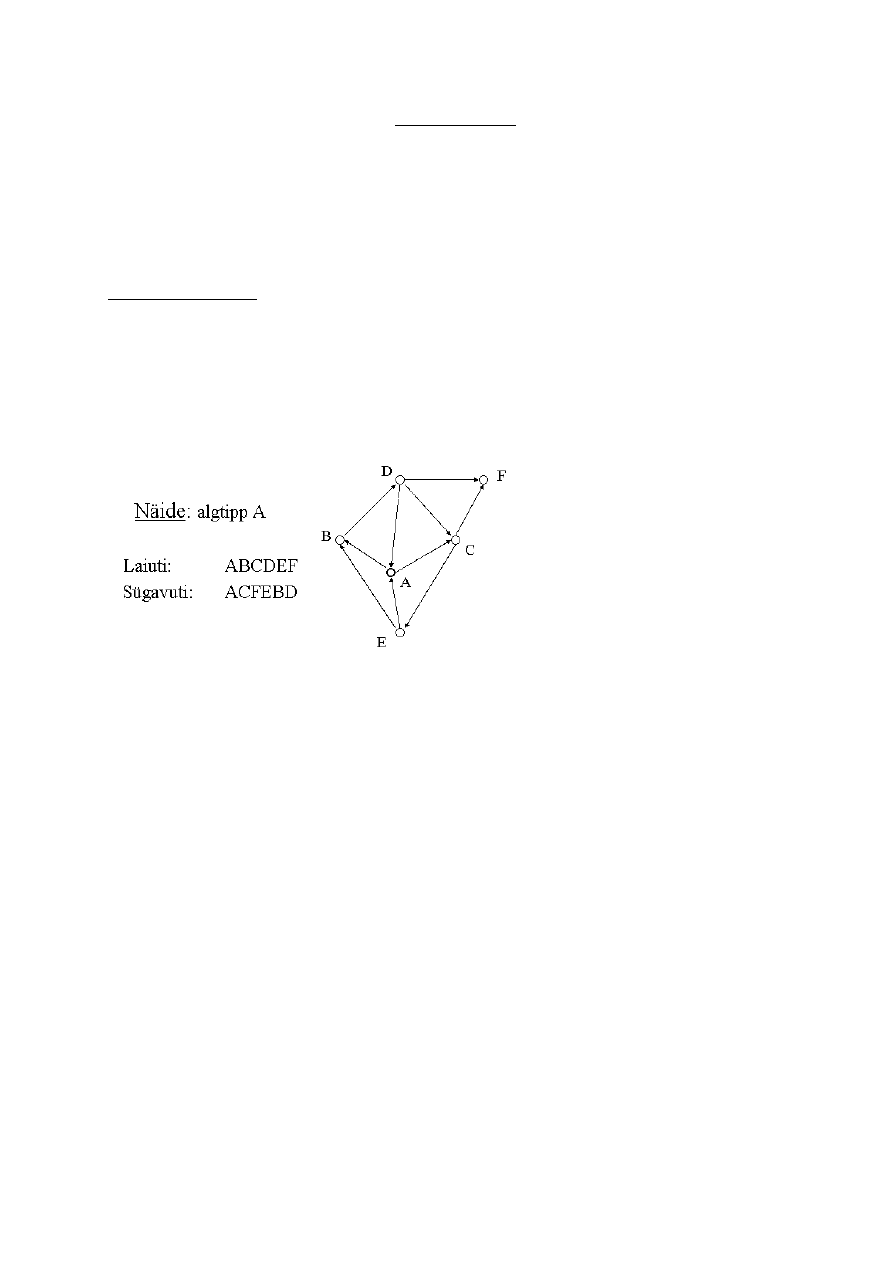
14. Graafi läbimise algoritmid: laiuti (breadth first) ja sügavuti (depth
first). Neid tuleb osata joonisel läbida.
BFS (breadth-first search) - laiuti läbimine. Ühegi tipu juurde ei jõua enne kui oled olnud
kõigi laste juures. Kaugele ei saa minna enne kui oled kõik lähemal olevad ringid ära käinud.
Ammendav strateegia. Sobib nende ülesannete jaoks, kus ongi kõiki variante vaja läbi
vaadata.
DFS (depth-first search) - sügavuti läbimine. Olen algpunktis source ja püüan mööda nooli
minna nii kaugele kui võimalik. Kogu aeg toimub liikumine edasi (lihtsalt lähedki järjest) ja
alternatiivid ei huvita. See on paha, kui lähed alguses vales suunas.
15. Algoritmid graafidel: sidususkomponentide leidmine.
10. loeng
Sidususkomponent - graafi sidus osa.
Graafi sidususkomponent on seega üksik tipp, mille aste on 0 (ehk selline tipp, mis pole
teistega ühendatud).
Loengus toodud näide on sügavuti läbimine, kui läheb läbi külgnevusstruktuuri nii kaugele
kui saab ja siis teeb backtrackingu.
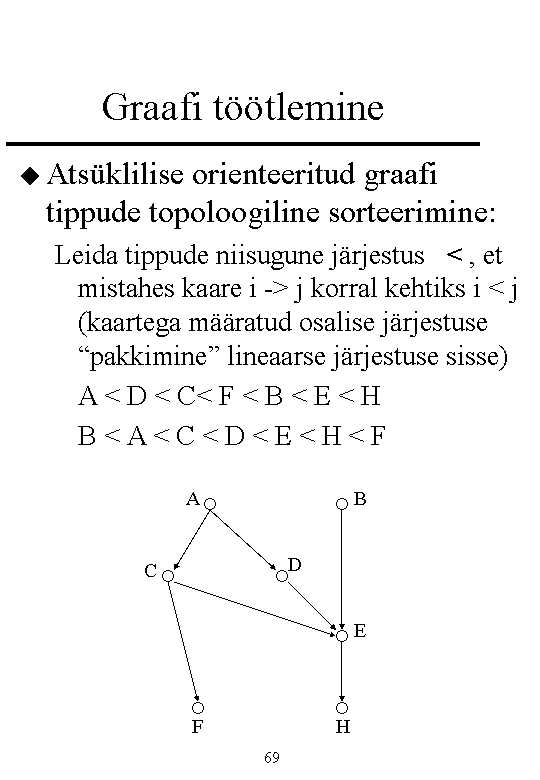
16. Algoritmid graafidel: tippude topoloogiline järjestamine. Kas järjestus
vastab või milline vastab.
Leida tippude niisugune järjestus < , et mistahes kaare i -> j korral kehtiks i < j (kaartega
määratud osalise järjestuse "pakkimine" lineaarse järjestuse sisse).
Loeme,
mitu kaart suubub igasse tippu. Teed start listi (järkude järgi, kus järg on 0), võtad
tipu ja kaare maha, vähendad numbreid jne.
Ülesande lahendamiseks on vaja
queue kasutamist. Põhiprotsess töötab kuni
queue on
tühi. Probleem, siis kui on tsükkel sees - st vigane graaf.
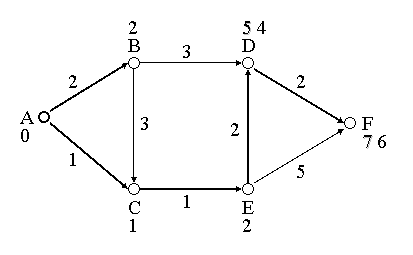
17. Algoritmid graafidel: kauguste arvutamine kõigi tipupaaride vahel.
Lühimad teepikkused kõigi tipupaaride vahel:
Floyd-Warshalli algoritm - O(|V|3) -
kuupkeerukus.
18. Algoritmid graafidel: kõigi lühimate teede leidmine antud tipust.
Dijkstra - sarnane laiuti läbimisele aga arvestab ka teepikkusi. O(|V|log|V| + |E|). Tegemist
on muutuvate eelistustega järjekorraga. Dynamic priority queue.
Keerukus sõltub sellest kas graaf on tihe või hõre. Kui graaf on hõre (kaarte arv väike), siis
keerukuse määrab tippude arv.
19. Algoritmid graafidel: toesepuu (spanning tree).
Sidusa lihtgraafi (V, E) toesepuuks e. toeseks (spanning tree) nim. sidusat atsüklilist graafi
(V, T), milles T on E alamhulk.
spanning tree (toesepuu) - atsükliline graaf (puu, mis on
sidus, sisaldab kõiki graafi tippe), mis on mingi parameetri mõttes parim. Seda leiame
orienteerimata graafile. Ühel graafil võib olla mitu toesepuud.
Toesepuu on atsükliline sidus graaf, mis sisaldab kõiki originaalgraafi tippe.
http://www.targotennisberg.com/eio/VP/voistlusprogrammeerimine_i_osa.pdf
Puu = sidus graaf, milles puuduvad tsüklid • Graafi aluspuu (ehk toesepuu) = alamgraaf, mis
on puu ja mis sisaldab kõiki selle graafi tippe
Kõik tipud on samad, servi on eemaldatud nii, et kaoksid tsüklid, aga sidusus säiliks. Toes ei
ole üldjuhul üheselt määratud.
Kui servadel on mittenegatiivsed kaalud, siis pakub huvi niisuguse toese leidmine, mille
kogukaal oleks minimaalne (kõigi toespuude hulgast).
Minimaalsest toesest saab rääkida siis, kui tegemist on kaalutud graafiga. Nimetame
toesepuu kaaluks kõigi tema servade kaalude summat. Minimaalse toese leidmiseks on
kaks tuntud algoritmi:
Kruskal ja Primi.
Kruskali algoritm: järjestada servad kaalude järgi mittekahanevalt ning valida selle alusel
järjekordne serv toesesse juba olemasolevate osapuude ühendamiseks (kui moodustub
tsükkel, siis seda serva ei võeta). Alt-üles (alguses on üksikud tipud, lõpuks peavad kõik
tipud esinema omas sidususkomponendis),
ahne strateegia (valitakse hetkel parim tee).
Primi algoritm: töötatakse antud lähtetipust laiuti sarnaselt Dijkstra algoritmiga (toesesse
valitakse hetkejätkudest minimaalse kaaluga serv, meeles peetakse kaalu ja eellast,
vajadusel parandatakse eellast teel allikast antud tipuni).
20. Rekursioon, näide: Hanoi tornid. Rekursiooni eemaldamine,
"sabarekursioon" (tail recursion).
Hanoi tower on 2n käiku. Alusta algseisust, sest mõned lubatud seisud ei ole algseisust
saavutatavad. Eksponentsiaalselt keeruline ülesanne. Ümber laduda nii, et suurem ketas ei
oleks väiksema peal. Lahenda baasjuht ja liigu sealt sammu kaupa edasi (induktsioon).
Rekursiivne algoritm sisaldab sellesama algoritmi poole pöördumist mingi "lihtsama juhu"
jaoks.
Fibonacci on ebaefektiivne rekursioonina, sest on palju duplikatsiooni.
Dünaamiline kavandamine - ülesande lahendamiseks tuleb alamülesannete vastused kuskil
meeles pidada ja kombineerida vastus kokku väiksemate ülesannete vastustest. Väiksemate
ülesannete meelespidamine.
Iga rekursiooni saab teisendada tsükliks kasutades Stacki, kui on post-tegevus.
Sabarekursioon - kui kõik tegevused toimuvad enne rekursiivset väljakutset, nimetatakse
rekursiooni sabarekursiooniks. Väga lihtne teisendada tavaliseks tsükliks ja vastupidi.
Eksam:
Mida tähendab sabarekursioon - funktsioonis on sabarekursioon siis, kui selle sama
funktsiooni väljakutse on viimane tegevus.
Eksam: Mingi kood on kirjutatud tsükliga, mida saab kirjutada sabarekursiooniga ja
vastupidi.
Vajadusel asendada tsükkel rekursiooniga ja rekursioon tsükliga, kui see on lihtsasti
teostatav. Küllalt lihtsad eksami ülesanded.
21. Ammendav otsing. Lippude paigutamise ülesanne (8 queens).
Ammendava otsingu ülesanne, kuidas paigutada lipud nii et ükski poleks tule all.
Ühemõõtmeline massiiv, sest kahemõõtmeline teeks keerukamaks.
“Proovimise meetod", s.t. kõigi võimalike lahendusvariantide süstemaatiline läbivaatus
(
ammendav otsing). Kuna lõplikul n-elemendilisel hulgal on 2n alamhulka, siis on
ammendava otsingu ülesanne üldjuhtumil
eksponentsiaalse keerukusega. Konkreetset
keerukust saab teatud juhtudel vähendada
otsinguruumi ahendamisega.
Esimese sobiva vastuse jaoks on parem sügavuti läbimine. Kui kõiki vastuseid, siis ei ole
vahet kas sügavuti või laiuti. Lõpmatute ülesannete puhul kasutada pigem laiuti läbimist.
22. Kahendpuu ja selle läbimine, kahendotsimise puu (binary search
tree).
Kahendpuu on puu, mille igal tipul on null kuni kaks alluvat, seejuures tehakse vahet
vasakpoolse ja parempoolse alluva vahel. Juurtipp ja kaks alampuud, mis võivad olla tühjad.
Andmete lisamine ja eemaldamine toimuvad logaritmilise ajaga. O(h) ja h on puu kõrgus.
Kahendpuu läbimineEesjärjestuses (pre-order):
Kui T ei ole tühi, siis:
1. töödelda juur
2. läbida vasak alampuu eesjärjestuses
3. läbida parem alampuu eesjärjestuses.
Taga- e. lõppjärjestuses (post-order, end-order):
Kui T ei ole tühi, siis:
1. läbida vasak alampuu lõppjärjestuses
2. läbida parem alampuu lõppjärjestuses
3. töödelda juur.
Keskjärjestuses (in-order):
Kui T ei ole tühi, siis:
1. läbida vasak alampuu keskjärjestuses
2. töödelda juur
3. läbida parem alampuu keskjärjestuses.
23. AVL-puu, binomiaalpuu ja värvitud kahendpuu (red-black tree).
AVL-puu - tasakaalustatud puu, kus alampuude tasemete erinevus on 1 ühik.
Punamust puu - kõgus on logaritmiline aga tasakaalustamise reeglid on mõnevõrra
keerukamad.
24. Kahendkuhi (binary heap) ja sorteerimine kuhjameetodil (heap sort).
Kahendkuhi - mõlemas alampuus olevad võtmed on väiksemad kui juurtipu võti. Lisanõue
struktuurile - peab olema kompaktne kahendpuu (ideaalne täielik kahendpuu, mille mõned
parempoolsed lehed on lubatud, et puuduvad). Lisamine ja eemaldamine on log
keerukusega, maksimumi leidmine on lausa tasuta (alati tipp).
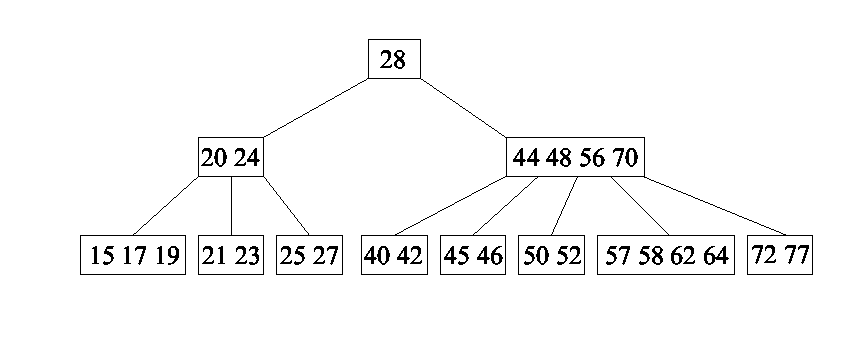
24.1 m-rajaline otsimispuu, B-puu.
Eksam: Kui miski ei vasta definitsioonile, siis peab aru saama, kus on viga
Nt alumise taseme tipp on ühe võtmega - sellist asja ei tohi olla.
Kuskil on 5 võtit ühes tipus - seda ei tohi olla (tohib olla 2-4 võtit 5. järku puu korral).
Alluvaid ei tohi rohkem olla kui järk on.
Puu järk – suurim võimalik sõlme järk (ühe sõlme alampuude arv) antud puus.
Kõigi manipulatsioonide keerukus on logaritmiline (toimub ühes harus enamasti).
https://enos.itcollege.ee/~jpoial/algoritmid/puustruktuurid.html
25. Sõnealgoritmid: Knuth-Morris-Pratt'i algoritm, Rabin-Karp'i algoritm.
Eksamil: milline idee kuulub millise nimede komplekti juurde. Suhteliselt formaalne
teadmine. Nt “prefiksfunktsioon ja suuremad hüpped” - Boyer Moore, keerukus täpse
otsimise ülesande lahendamiseks on…
Knuth-Morris-Pratt
Rabin-Karp
Boyer-Moore
Sisu
arvutatakse võimalikud
nihked ette välja ning
kantakse tabelisse, mida
siis nihutamisel
kasutatakse
Võrdlemise kiiruse
parandamine räside
abil.
Sobitamine toimub paremalt
vasakule, prefiksfunktsiooni
asemel arvutatakse
sufiksfunktsioon.
Keerukus
Knuth-Morris-Pratti
algoritmi ajaline keerukus
on O(m+n) koos
lisamäluga O(m)
prefiksfunktsiooni
ettearvutamiseks.
Keerukus on O(m)
Ideaaljuhul taandub keerukus
O(n/m)-ni, halvim keerukus on
O(mn).
Prefiksfunktsiooni väärtus arvutatakse
Küsimus on pikkade sõnede ja patternite puhul. Etteantud mustri leidmine, lihtne juht on
alamsõne leidmine (exact match).
Probleemid, millega tegeldakse: Etteantud mustri(te) otsimine tekstist: täpne vs. ligikaudne,
üks vs. mitu mustrit, lineaarne vs. mitmemõõtmeline…, Sõnedevaheline kaugus: kuidas
ühest sõnest saada teist, Ühise osasõne otsimine (dynamic programming),
Pakkimine,
Infootsing, indekseerimine, Seaduspärasuste avastamine...
Naiivne meetod O(nm) - sümboli kaupa võrdlemine, sellega väga midagi ei tee efektiivselt.
Knuth-Morris-Pratt'i algoritm - arvutatakse võimalikud nihked ette välja ning kantakse
tabelisse, mida siis nihutamisel kasutatakse. Prefiksfunktsiooni väärtus arvutatakse otsisõne
s iga positsiooni i jaoks ning see on pikima sellise s prefiksi pikkus, mis on positsioonis i-1
lõppeva s alamsõne sufiksiks. Knuth-Morris-Pratti algoritmi ajaline keerukus on O(m+n) koos
lisamäluga O(m) prefiksfunktsiooni ettearvutamiseks.
Rabin-Karpi algoritm - lähenemine on parandada otsisõne ja vastava tekstilõigu võrdlemise
kiirust (seni O(m)). Sõnede võrdlemise asemel võrdleme nende räsisid (potentsiaalse
valehäire hinnaga). Räsifunktsiooni väärtust arvutame järgneva tekstilõigu jaoks kasutades
eelmise lõigu räsi. Selline lähenemine töötab siis, kui m ei ole suur ja tähestiku võimsus ei
ole suur. Olgu näiteks tähestik { 0, 1, 2, ..., 9 }. Siis iga sõnet selles tähestikus esindab
täisarv, mille kümnendkujuks see sõne on. Selle arvu väljaarvutamise keerukus on O(m).
Samas saab mustri nihutamist paremale arvutada kiiremini (lahutame räsi väärtusest
suurima järgu, korrutame tähestiku võimsusega ning lisame uue vähima järgu). Valehäired
tekivad sellest, et me arvutame mingis jäägiklassiringis (ei ole otstarbekas arvutada väga
suurte täisarvudega). Seega tuleb räside kokkulangemisel alati kontrollida, kas ka sõned
tegelikult kokku langesid.
Selle asemel, et suurendada hüppe pikkust, teed võrdlemist kiiremaks.
26. Sõnealgoritmid: Boyer-Moore'i algoritm.
Boyer-Moore'i algoritm - Ka Boyer-Moore'i algoritm pühendub "paremale hüppamisele"
tekstis. Sobitamine toimub paremalt vasakule, prefiksfunktsiooni asemel arvutatakse
sufiksfunktsioon ning lisaks veel sümboli nn. viimase esinemise funktsioon (iga sümboli
viimase esinemise positsioon otsisõnes, mitteesinemisel null). Valitakse maksimaalne
erinevate hüppevõimaluste vahel.
Praktikas saavutatakse oluliselt pikemad hüpped, ideaaljuhul taandub keerukus O(n/m)-ni,
halvim keerukus on O(mn).
Kasutab ka ebasobiva tähe heuristikat (et kui see koht, sisaldab tähte, mida alamsõnes ei
ole, siis matchi ei saa olla).
27. Kodeerimine, kodeerimisskeemid, prefikskood. Shannon-Fano
pakkimismeetod.
Shannon-Fano meetodil prefikskoodi moodustamine: sümbolihulkade poolitamine.
28. Ahned (greedy) algoritmid. Pakkimine Huffmani puu abil.
Ahne algoritm - teeme mingi valiku, hetke pildist lähtuva, mis tundub kõige parem. Ja selgub,
et see on ka lõpptulemuse seisukohast kõige parem valik. Annab piiratud info tingimustes
optimaalse tulemuse (nt paned kõige lühemaid järjest kokku).
Huffmani puu antud teksti jaoks on niisugune koodipuu, mille abil kodeeritud teksti pikkus
on minimaalne (kõikvõimalike koodipuude hulgas).
29. Dünaamiline kavandamine (dynamic programming). Pikima ühise
osasõne leidmine.
Otstarbekas oleks alamülesannete vastused meeles pidada ja neid kasutada ülesande
lahendamiseks (vrd. Fibonacci arvude arvutamine). Niisugune lähenemine kattuvate
alamülesannetega algoritmile kannab nimetust
dünaamiline kavandamine.
30. Nõrgima eeltingimuse kasutamine algorimi osalise korrektsuse
tõestamiseks.
Eksamil: osata teha ilma tsüklita programm, kus on ainult if-id ja omistamised. Ilma tsüklita
programmi tingimusi arvutada. Kui on omistamine, siis tead, kuidas liigud järeltingimusest
eeltingimuse peale.
V := exp (omistamine)
Eeltingimus - tõene enne programmi täitmist
Järeltingimus - tõene pärast programmi täitmist
Kõige nõrgem eeltingimus kirjeldab kõige paremini programmi käitumist.
Nõrgima eeltingimuse leidmiseks kasutatakse algoritmi struktuuri - iga konstruktsiooni
jaoks algoritmis on teatud tuletusreegel.
Omistamine x := e : nõrgim eeltingimus saadakse, kui omistamislause järeltingimuses Q
asendada kõik muutuja x esinemised avaldisega e (ning eeldada, et e arvutamine toimub
kõrvalefektideta).
Eksamist. Al 36 min.
25% eksamist on keerukuse definitsioonid.
Programmi kirjutamine: praktikas ainult puude teema. 3 katset, ülesanne lihtne (u 10 rida) :)
2-6 teada halvim juht, keskmine juht, lisamälu kasutus
22.-25. Teada keerukusi, ära tunda vigu, teada mõisteid.
26.-29. Teada tööpõhimõtteid.
Enesetest
Kahendotsimise keskmine ajaline keerukus on O(log n).
Tõene
Väär
Ühildusmeetodi (merge sort) halvima juhu ajaline keerukus on O(n).
Tõene
Väär
Funktsiooni 10000n6+8nlogn+5n keerukusklass on
n5
5n
nlogn
n6
Millist seost funktsioonide f ja g vahel väljendab järgmine definitsioon
Leidub konstant c, mis on suurem nullist. Leidub n0, mis kuulub naturaalarvude hulka (on
elemendiks naturaalarvude hulgas). Iga n
f ~ o(g)
f ~ O(g)
f ~ Θ(g)
f ~ ω(g)
f ~ Ω(g)
Millist seost funktsioonide f ja g vahel väljendab järgmine definitsioon
f~o(g)
Leia vastavus tähistuste ja tähenduste vahel, f ja g on funktsioonid, mille
asümptootilist käitumist võrreldakse.
f~o(g) → f kasvab aeglasemalt kui g,
f~Θ(g) → f kasvab niisama kiiresti kui g,
f~O(g) → f kasvab mitte kiiremini kui g,
f~Ω(g) → f kasvab mitte aeglasemalt kui g
f~ω(g) → f kasvab kiiremini kui g,
Järjestamismeetod on kiire, kui selle keskmine ajaline keerukus on O(n log n).
Tõene
Milline loetletutest on alljärgneva programmi nõrgim eeltingimus:
a := a + 1;
b := a + 2;
kui järeltingimus on: { b == 6 }
Valige ü<<<



































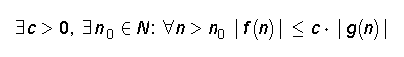
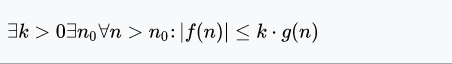
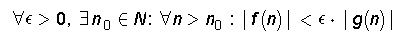
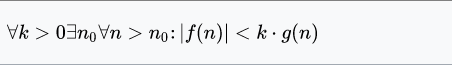
















Kõik kommentaarid